前些天發現了一個巨牛的人工智能學習網站,通俗易懂,風趣幽默,忍不住分享一下給大家。點擊跳轉到教程。
Quartz API核心接口有:
- Scheduler – 與scheduler交互的主要API;
- Job – 你通過scheduler執行任務,你的任務類需要實現的接口;
- JobDetail – 定義Job的實例;
- Trigger – 觸發Job的執行;
- JobBuilder – 定義和創建JobDetail實例的接口;
- TriggerBuilder – 定義和創建Trigger實例的接口;
- ?
本文工程免費下載
一、Job
?
??????? 在上一節中,Job中定義了實際的業務邏輯,而JobDetail包含Job相關的配置信息。在Quartz中,每次Scheduler執行Job時,在調用其execute()方法之前,它需要先根據JobDetail提供的Job類型創建一個Job class的實例,在任務執行完以后,Job class的實例會被丟棄,Jvm的垃圾回收器會將它們回收。因此編寫Job的具體實現時,需要注意:
(1) 它必須具有一個無參數的構造函數;
(2) 它不應該有靜態數據類型,因為每次Job執行完以后便被回收,因此在多次執行時靜態數據沒法被維護。
??????? 在JobDetail中有這么一個成員JobDataMap,JobDataMap是Java Map接口的具體實現,并添加了一些便利的方法用于存儲與讀取原生類型數據,里面包含了當Job實例運行時,你希望提供給它的所有數據對象。
???????? 可以借助JobDataMap為Job實例提供屬性/配置,可以通過它來追蹤Job的執行狀態等等。對于第一種情況,可以在創建Job時,添加JobDataMap數據,在Job的execute()中獲取數據,第二種,則可以在Listener中通過獲取JobDataMap中存儲的狀態數據追蹤Job的執行狀態。
一個實現了Job接口的Java類就能夠被調度器執行。接口如下:
?
- packageorg.quartz;
-
- publicinterface Job {
-
- public void execute(JobExecutionContext context) throwsJobExecutionException;
-
- }
??????? 很簡的,當Job的trigger觸發時,Job的execute(..)方法就會被調度器調用。被傳遞到這個方法里來的JobExecutionContext對象提供了帶有job運行時的信息:執行它的調度器句柄、觸發它的觸發器句柄、job的JobDetail對象和一些其他的項。JobDetail對象是Job在被加到調度器里時所創建的,它包含有很多的Job屬性設置,和JobDataMap一樣,可以用來存儲job實例時的一些狀態信息。
?
比如如下任務類
?
?
?
- <code?class="language-java">package?com.mucfc;??
- ??
- import?java.util.Date;??
- ??
- import?org.apache.commons.logging.Log;??
- import?org.apache.commons.logging.LogFactory;??
- import?org.quartz.Job;??
- import?org.quartz.JobDetail;??
- import?org.quartz.JobExecutionContext;??
- import?org.quartz.JobExecutionException;??
- ??
- public?class?NewJob?implements?Job{??
- ?????static?Log?logger?=?LogFactory.getLog(NewJob.class);?????
- ????@Override??
- ????public?void?execute(JobExecutionContext?context)?throws?JobExecutionException?{??
- ?????????System.err.println("Hello!??NewJob?is?executing."+new?Date()?);??
- ????//取得job詳情??
- ?????????JobDetail?jobDetail?=?context.getJobDetail();?????
- ?????????//?取得job名稱??
- ?????????String?jobName?=?jobDetail.getClass().getName();??
- ?????????logger.info("Name:?"?+?jobDetail.getClass().getSimpleName());?????
- ?????????//取得job的類??
- ?????????logger.info("Job?Class:?"?+?jobDetail.getJobClass());?????
- ?????????//取得job開始時間??
- ?????????logger.info(jobName?+?"?fired?at?"?+?context.getFireTime());?????
- ????????logger.info("Next?fire?time?"?+?context.getNextFireTime());???
- ????}??
- ??
- }??
- </code>??
?
??????? 當 Scheduler 調用一個 Job,一個 JobexecutionContext 傳遞給 execute() 方法。JobExecutionContext 對象讓 Job 能訪問 Quartz 運行時候環境和 Job 本身的明細數據。這就類似于在 Java Web 應用中的 servlet 訪問 ServletContext 那樣。通過 JobExecutionContext,Job 可訪問到所處環境的所有信息,包括注冊到 Scheduler 上與該 Job 相關聯的 JobDetail 和 Triiger。
?
?
?
?
二、JobDetail?
?
JobDetail實例是通過JobBuilder類創建的
可以通過導入該類下的所有靜態方法
import static org.quartz.JobBuilder.*;然后是創建:
- 創建一個JobDetail實例
- JobDetail jobDetail = newJob(NewJob.class).withIdentity("job1_1", "jGroup1").build();
如果不導入靜態包:
那么就要用:
- 創建一個JobDetail實例
- obDetail jobDetail = JobBuilder.newJob(NewJob.class).withIdentity("job1_1", "jGroup1").build();
?
對于部署在 Scheduler 上的每一個 Job 只創建了一個 JobDetail 實例。JobDetail 是作為 Job 實例進行定義的。注意到在代碼 中不是把 Job 對象注冊到 Scheduler;實際注冊的是一個 JobDetail 實例。
?
- public void startSchedule() {
- try {
- // 1、創建一個JobDetail實例,指定Quartz
- JobDetail jobDetail = JobBuilder.newJob(NewJob.class) // 任務執行類
- .withIdentity("job1_1", "jGroup1")// 任務名,任務組
- .build();
- //2、創建Trigger
- SimpleScheduleBuilder builder=SimpleScheduleBuilder.simpleSchedule()
- .withIntervalInSeconds(5) //設置間隔執行時間
- .repeatSecondlyForTotalCount(5);//設置執行次數
-
- Trigger trigger=TriggerBuilder.newTrigger().withIdentity(
- "trigger1_1","tGroup1").startNow().withSchedule(builder).build();
- //3、創建Scheduler
- Scheduler scheduler=StdSchedulerFactory.getDefaultScheduler();
- //4、調度執行
- scheduler.scheduleJob(jobDetail, trigger);
- scheduler.start();
- } catch (SchedulerException e) {
- e.printStackTrace();
- }
-
- }
結果:
?
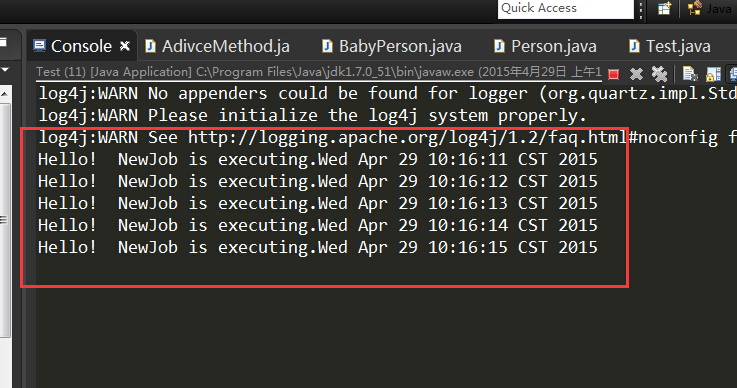
從上面的代碼中可以看JobDetail 被加到 Scheduler 中了,而不是 job。Job 類是作為 JobDetail 的一部份,但是它直到 Scheduler 準備要執行它的時候才會被實例化的。
?
| 直到執行時才會創建 Job 實例? Job 的實例要到該執行它們的時候才會實例化出來。每次 Job 被執行,一個新的 Job 實例會被創建。其中暗含的意思就是你的 Job 不必擔心線程安全性,因為同一時刻僅有一個線程去執行給定 Job 類的實例,甚至是并發執行同一 Job 也是如此。 |
?
?
?
?????? 可以看到,我們傳給scheduler一個JobDetail實例,因為我們在創建JobDetail時,將要執行的job的類名傳給了JobDetail,所以scheduler就知道了要執行何種類型的job;每次當scheduler執行job時,在調用其execute(…)方法之前會創建該類的一個新的實例;執行完畢,對該實例的引用就被丟棄了,實例會被垃圾回收;這種執行策略帶來的一個后果是,job必須有一個無參的構造函數(當使用默認的JobFactory時);另一個后果是,在job類中,不應該定義有狀態的數據屬性,因為在job的多次執行中,這些屬性的值不會保留。
??????? 那么如何給job實例增加屬性或配置呢?如何在job的多次執行中,跟蹤job的狀態呢?答案就是:JobDataMap,JobDetail對象的一部分。
?
三、JobDataMap
???????? JobDataMap中可以包含不限量的(序列化的)數據對象,在job實例執行的時候,可以使用其中的數據;JobDataMap是Java Map接口的一個實現,額外增加了一些便于存取基本類型的數據的方法。
將job加入到scheduler之前,在構建JobDetail時,可以將數據放入JobDataMap,如下示例:
?
?
- package com.mucfc;
- import org.quartz.Job;
- import org.quartz.JobDataMap;
- import org.quartz.JobExecutionContext;
- import org.quartz.JobExecutionException;
- import org.quartz.JobKey;
- public class NewJob2 implements Job{
-
- @Override
- public void execute(JobExecutionContext context) throws JobExecutionException {
- JobKey key = context.getJobDetail().getKey();
- JobDataMap dataMap = context.getJobDetail().getJobDataMap();
- String jobSays = dataMap.getString("jobSays");
- float myFloatValue = dataMap.getFloat("myFloatValue");
- System.out.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);
-
- }
-
- }
?
在job的執行過程中,可以從JobDataMap中取出數據,如下示例:
?
- package com.mucfc;
-
- import org.quartz.JobBuilder;
- import org.quartz.JobDetail;
- import org.quartz.Scheduler;
- import org.quartz.SchedulerException;
- import org.quartz.SimpleScheduleBuilder;
- import org.quartz.Trigger;
- import org.quartz.TriggerBuilder;
- import org.quartz.impl.StdSchedulerFactory;
- public class Test {
- public void startSchedule() {
- try {
-
-
- // 1、創建一個JobDetail實例,指定Quartz
- JobDetail jobDetail = JobBuilder.newJob(NewJob.class) // 任務執行類
- .withIdentity("job1_1", "jGroup1")// 任務名,任務組
- .build();
-
- JobDetail jobDetail2 = JobBuilder.newJob(NewJob2.class)
- .withIdentity("job1_2", "jGroup1")
- .usingJobData("jobSays", "Hello World!")
- .usingJobData("myFloatValue", 3.141f)
- .build();
-
-
-
- //2、創建Trigger
- SimpleScheduleBuilder builder=SimpleScheduleBuilder.simpleSchedule()
- .withIntervalInSeconds(5) //設置間隔執行時間
- .repeatSecondlyForTotalCount(5);//設置執行次數
-
- Trigger trigger=TriggerBuilder.newTrigger().withIdentity(
- "trigger1_1","tGroup1").startNow().withSchedule(builder).build();
- //3、創建Scheduler
- Scheduler scheduler=StdSchedulerFactory.getDefaultScheduler();
- //4、調度執行
- scheduler.scheduleJob(jobDetail2, trigger);
- scheduler.start();
- } catch (SchedulerException e) {
- e.printStackTrace();
- }
-
- }
- public static void main(String[] args) {
-
- Test test=new Test();
- test.startSchedule();
- }
-
- }
結果:
?
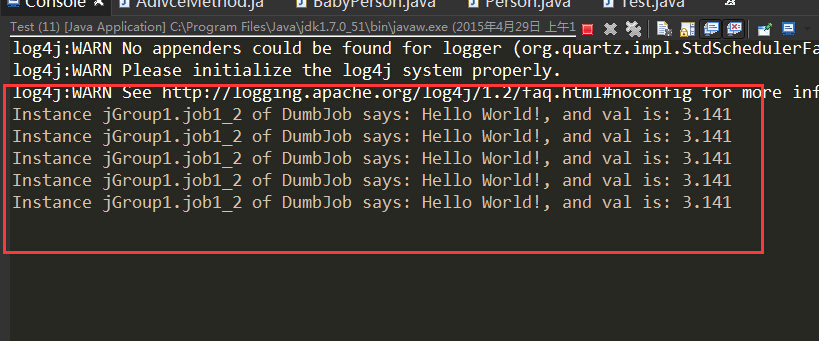
?
四、 Trigger
??????? Trigger對象是用來觸發執行Job的。當調度一個job時,我們實例一個觸發器然后調整它的屬性來滿足job執行的條件。觸發器也有一個和它相關的JobDataMap,它是用來給被觸發器觸發的job傳參數的。Quartz有一些不同的觸發器類型,不過,用得最多的是SimpleTrigger和CronTrigger。
??????? 如果我們需要在給定時刻執行一次job或者在給定時刻觸發job隨后間斷一定時間不停的執行的話,SimpleTrigger是個簡單的解決辦法;如果我們想基于類似日歷調度的觸發job的話,比如說,在每個星期五的中午或者在每個月第10天的10:15觸發job時,CronTrigger是很有用的。
???????? 為什么用jobs和triggers呢?很多任務調度器并沒有任務和觸發器的概念,一些任務調度器簡單定義一個“job”為在一個執行時間伴隨一些小任務標示,其他的更像Quartz里job和trigger對象的聯合體。在開發Quartz時,開發者們決定,在調度時間表和在這上面運行的工作應該分開。這是很有用的。
??????? 例如,job能夠獨立于觸發器被創建和儲存在任務調度器里,并且,很多的觸發器能夠與同一個job關聯起來。這個松耦合的另一個好處就是在與jobs關聯的觸發器終止后,我們能夠再次配置保留在調度器里的jobs,這樣的話,我們能夠再次調度這些jobs而不需要重新定義他們。我們也可以在不重新定義一個關聯到job的觸發器的情況下,修改或替代它。
???????? 當Jobs和triggers被注冊到Quartz的調度器里時,他們就有了唯一標示符。他們也可以被放到“groups”里,Groups是用來組織分類jobs和triggers的,以便今后的維護。在一個組里的job和trigger的名字必須是唯一的,換句話說,一個job和trigger的全名為他們的名字加上組名。如果把組名置為”null”,系統會自動給它置為Scheduler.DEFAULT_GROUP
?
Scheduler在使用之前需要實例化。一般通過SchedulerFactory來創建一個實例。有些用戶將factory的實例保存在JNDI中,但直接初始化,然后使用該實例也許更簡單(見下面的示例)。
scheduler實例化后,可以啟動(start)、暫停(stand-by)、停止(shutdown)。注意:scheduler被停止后,除非重新實例化,否則不能重新啟動;只有當scheduler啟動后,即使處于暫停狀態也不行,trigger才會被觸發(job才會被執行)。
?
五、SimpleTrigger的介紹
正如其名所示,SimpleTrigger對于設置和使用是最為簡單的一種 QuartzTrigger。它是為那種需要在特定的日期/時間啟動,且以一個可能的間隔時間重復執行 n 次的 Job 所設計的。
我們前面已經在一個簡單的Quartz的例子里使用過了SimpleTrigger,我們通過
- SimpleScheduleBuilder builder=SimpleScheduleBuilder.simpleSchedule()
- //設置間隔執行時間
- .withIntervalInSeconds(5)
- //設置執行次數
- .withRepeatCount(4);
- Trigger trigger=TriggerBuilder.newTrigger().withIdentity(
- "trigger1_1","tGroup1").startNow().withSchedule(builder).build();
或者無限執行
?
?
- SimpleScheduleBuilder builder=SimpleScheduleBuilder.simpleSchedule()
- //設置間隔執行時間
- .withIntervalInSeconds(5)
- //設置執行次數
- .repeatForever();
- Trigger trigger=TriggerBuilder.newTrigger().withIdentity(
- "trigger1_1","tGroup1").startNow().withSchedule(builder).build();
對于Quartz而言,它還不能滿足我們的觸發情況,所以它僅僅是用于一些簡單的觸發情況;
?
?
?
六、CronTrigger
??????? CronTrigger 允許設定非常復雜的觸發時間表。然而有時也許不得不使用兩個或多個 SimpleTrigger來滿足你的觸發需求,這時候,你僅僅需要一個 CronTrigger 實例就夠了。顧名思義,CronTrigger 是基于 Unix類似于 cron 的表達式。例如,你也許有一個 Job,要它在星期一和星期五的上午 8:00-9:00間每五分鐘執行一次。假如你試圖用 SimpleTrigger 來實現,你或許要為這個 Job 配置多個Trigger。然而,你可以使用如下的表達式來產生一個遵照這個時間表觸發的 Trigger;
比如:
?
?
- // 創建Trigger
- CronScheduleBuilder builder2 = CronScheduleBuilder.cronSchedule("0 0/5 8 * * *");//8:00-8:55,每隔5分鐘執行
- /**
- builder2 = CronScheduleBuilder.dailyAtHourAndMinute(12, 30);
- **/
- Trigger trigger=TriggerBuilder.newTrigger().withIdentity("trigger1_1","tGroup1").startNow().withSchedule(builder2).build();
?
?
??????? 因為 CronTrigger內建的如此強的靈活性,也與生俱來可用于創建幾乎無所限制的表達式,且因為支持unix的cron表達式,則做為企業應用,我們的操作系統一般也都以unxi操作系統為主,所以掌握CronTrigger的使用費用有必要,我們將在后面對CronTrigger 進行詳細的介紹。cron 表達式的格式見下一節。
七、Job與Trigger的關系
??????? 大家都知道,一個作業,比較重要的三個要素就是Schduler,jobDetail,Trigger;而Trigger對于job而言就好比一個驅動器;沒有觸發器來定時驅動作業,作業就無法運行;對于Job而言,一個job可以對應多個Trigger,但對于Trigger而言,一個Trigger只能對應一個job;所以一個Trigger 只能被指派給一個 Job;如果你需要一個更復雜的觸發計劃,你可以創建多個 Trigger 并指派它們給同一個 Job。Scheduler 是基于配置在 Job上的 Trigger 來決定正確的執行計劃的,下面就是為同一個 JobDetail 使用多個Trigger;
?
轉自:http://blog.csdn.net/evankaka
本文工程免費下載




、母版的使用)

 deform引入的額外開銷)



)


![CSS3最顛覆性的動畫效果,基本屬性[3D]](http://pic.xiahunao.cn/CSS3最顛覆性的動畫效果,基本屬性[3D])





