根據網站資料,簡單地匯編一下CUDA與OpenCL的區別。如有錯誤請指出。
題外話: 美國Sandia國家實驗室一項模擬測試證明:由于存儲機制和內存帶寬的限制,16核、32核甚至64核處理器對于超級計算機來說,不僅不能帶來性能提升,甚至可能導致效率的大幅度下降。
什么是OpenCL?
是由蘋果(Apple)公司發起,業界眾多著名廠商共同制作的面向異構系統通用目的并行編程的開放式、免費標準,也是一個統一的編程環境。便于軟件開發人員為高性能計算服務器、桌面計算系統、手持設備編寫高效輕便的代碼,而且廣泛適用于多核心處理器(CPU)、圖形處理器(GPU)、Cell類型架構以及數字信號處理器(DSP)等其他并行處理器,在游戲、娛樂、科研、醫療等各種領域都有廣闊的發展前景。
什么是CUDA?
CUDA是一個基于Nvidia GPU的并行計算的架構。CUDA最主要的包含兩個方面:一個是ISA指令集架構;第二硬件計算引擎;實際上是硬件和指令集。 也就是說我們可以把CUDA看做是與X86或者cell類似的架構,但是是基于是GPU,而不是傳統的CPU。

OpenCL實際上是什么?
- OpenCL實際上是針對異構系統進行并行編程的一個全新的API,OpenCL可以利用GPU進行一些并行計算的工作。
- OpenGL是針對圖形的,而OpenCL則是針對并行計算的API。
- OpenCL開發的過程中,技術平臺均為NVIDIA的GPU,實際上OpenCL是基于NVIDIA GPU的平臺進行開發的。另外OpenCL的第一次演示也是運行在NVIDIA的GPU上。
- 從本質上來說,OpenCL就是一個相當于Windows平臺中DirectX那樣的技術。或者說,它是一個連接硬件和軟件的API接口。在這一點上,它和OpenGL類似,不過OpenCL的涉及范圍要比OpenGL大得多,它不僅是用來作用于3D圖形。如果用一句話描述,OpenCL的作用就是通過調用處理器和GPU的計算資源,釋放硬件潛力,讓程序運行得更快更好。
CUDA實際上是什么?
- CUDA架構是原生的,專門為計算接口而建造的這樣的一個架構,這種硬件架構包括指令集都是非常適合于這種并行計算,為異構計算而設計的一整套的架構。CUDA架構可以支持API,包括OpenCL或者DirectX,同時CUDA還支持C、C++語言,還包括Fortran、Java、Python等各種各樣的語言。
?

OpenCL與CUDA的關系是什么?
- CUDA和OpenCL的關系并不是沖突關系,而是包容關系。OpenCL是一個API,在第一個級別,CUDA架構是更高一個級別,在這個架構上不管是OpenCL還是DX11這樣的API,還是像C語言、Fortran、DX11計算,都可以支持。作為程序開發員來講,一般他們只懂這些語言或者API,可以采用多種語言開發自己的程序,不管他選擇什么語言,只要是希望調用GPU的計算能,在這個架構上都可以用CUDA來編程。
- 關于OpenCL與CUDA之間的技術區別,主要體現在實現方法上。基于C語言的CUDA被包裝成一種容易編寫的代碼,因此即使是不熟悉芯片構造的科研人員,也可能利用CUDA工具編寫出實用的程序。而OpenCL雖然句法上與CUDA接近,但是它更加強調底層操作,因此難度較高,但正因為如此,OpenCL才能跨平臺運行。
- CUDA是一個并行計算的架構,包含有一個指令集架構和相應的硬件引擎。OpenCL是一個并行計算的應用程序編程接口(API),在NVIDIA CUDA架構上OpenCL是除了C for CUDA外新增的一個CUDA程序開發途徑。
- 如果你想獲得更多的對硬件上的控制權的話,你可以使用OpenCL這個API來進行編程,如果對API不是太了解,也可以用CUDA C語言來編程,這是兩種不同編程的方式,他們有他們相同點和不同點。但是有一點OpenCL和CUDA C語言進行開發的時候,在并行計算這塊,他們的概念是差不多的,這兩種程序在程序上是有很大的相似度,所以程序之間的相互移植相對來說也是比較容易。

- CUDA C語言與OpenCL的定位不同,或者說是用人群不同。CUDA C是一種高級語言,那些對硬件了解不多的非專業人士也能輕松上手;而OpenCL則是針對硬件的應用程序開發接口,它能給程序員更多對硬件的控制權,相應的上手及開發會比較難一些。
- 程序員的使用習慣也是非常重要的一方面,那些在X86 CPU平臺使用C語言的人員,會很容易接受基于CUDA GPU平臺的C語言;而習慣于使用OpenGL圖形開發的人員,看到OpenCL會更加親切一些,在其基礎上開發與圖形、視頻有關的計算程序會非常容易。
給點實例看看?
- OpenCL 教學: http://www.kimicat.com/opencl-1/opencl-jiao-xue-yi
- 在 Windows 下使用 OpenCL: http://www.kimicat.com/opencl-1/zai-windows-xia-shi-yong-opencl
- 在 Xcode 中使用 OpenCL: http://www.kimicat.com/opencl-1/zai-xcode-zhong-shi-yong-opencl
- 在 Windows 下使用 OpenCL: http://www.kimicat.com/opencl-1/zai-windows-xia-shi-yong-opencl
- CUDA 教學: http://www2.kimicat.com/cuda%E7%B0%A1%E4%BB%8B
從很多方面來看,CUDA和OpenCL的關系都和DirectX與OpenGL的關系很相像。如同DirectX和OpenGL一樣,CUDA和OpenCL中,前者是配備完整工具包、針對單一供應商(NVIDIA)的成熟的開發平臺,后者是一個開放的標準。
雖然兩者抱著相同的目標:通用并行計算。但是CUDA僅僅能夠在NVIDIA的GPU硬件上運行,而OpenCL的目標是面向任何一種Massively Parallel Processor,期望能夠對不同種類的硬件給出一個相同的編程模型。由于這一根本區別,二者在很多方面都存在不同:
1)開發者友好程度。CUDA在這方面顯然受更多開發者青睞。原因在于其統一的開發套件(CUDA Toolkit, NVIDIA GPU Computing SDK以及NSight等等)、非常豐富的庫(cuFFT, cuBLAS, cuSPARSE, cuRAND, NPP, Thrust)以及NVCC(NVIDIA的CUDA編譯器)所具備的PTX(一種SSA中間表示,為不同的NVIDIA GPU設備提供一套統一的靜態ISA)代碼生成、離線編譯等更成熟的編譯器特性。相比之下,使用OpenCL進行開發,只有AMD對OpenCL的驅動相對成熟。
2)跨平臺性和通用性。這一點上OpenCL占有很大優勢(這也是很多National Laboratory使用OpenCL進行科學計算的最主要原因)。OpenCL支持包括ATI,NVIDIA,Intel,ARM在內的多類處理器,并能支持運行在CPU的并行代碼,同時還獨有Task-Parallel Execution Mode,能夠更好的支持Heterogeneous Computing。這一點是僅僅支持數據級并行并僅能在NVIDIA眾核處理器上運行的CUDA無法做到的。
3)市場占有率。作為一個開放標準,缺少背后公司的推動,OpenCL顯然沒有占據通用并行計算的主流市場。NVIDIA則憑借CUDA在科學計算、生物、金融等領域的推廣牢牢把握著主流市場。再次想到OpenGL和DirectX的對比,不難發現公司推廣的高效和非盈利機構/標準委員會的低效(抑或謹慎,想想C++0x)。
我接觸的很多開發者(包括我本人)都認為,由于目前獨立顯卡市場的萎縮、新一代處理器架構(AMD的Graphics Core Next (GCN)、Intel的Sandy Bridge以及Ivy Bridge)以及新的SIMD編程模型(Intel的ISPC等)的出現,未來的通用并行計算市場會有很多不確定因素,CUDA和OpenCL都不是終點,我期待未來會有更好的并行編程模型的出現(當然也包括CUDA和OpenCL,如果它們能夠持續發展下去)。
1. CUDA有遠好于OpenCL的生態系統,更易用,對程序員更友好。OpenCL的API設計怪異,缺乏一致性,功能亦不正交,很不直觀,遠未成熟。
2. OpenCL的portability被夸大了,事實上根據我的經驗,AMD和NV的OpenCL實現,組合行為是有差異的,并且有些十分隱蔽,難于調試。而且同樣的代碼在AMD和NV是有性能差異的,有時候差異非常大,為了一致的性能不得不寫兩套代碼。如果有更多的vendor呢?
3.OpenCL作為開放的標準,完全依賴于廠商的實現,不同廠商支持標準不同。如果NV放棄支持OpenCL,那它還是通用的開放的標準嗎?
4. 即使NV倒閉,會有OpenCUDA出現的。
現在AMD在推新的HSA,其IL類似NV的PTX,不知是何用意。Java會在未來(JAVA 9? 2015?)支持NV/AMD GPU 加速。OpenCL的美好只存在于未來,問題是這個未來有多遠。
CUDA助力OpenCL GPU并行計算無處不在
通用計算新銳OpenCL CUDA來助陣
通用計算新銳OpenCL CUDA來助陣
??????? GPU經過多年的發展,從功能單一的3D計算逐步擴充了視頻解碼、通用計算等,而且值得一提的是通用計算這個目前最璀璨的技術新星被科研單位及個人消費者普遍關注。
??????? 眾所周知,NVIDIA是GPU的通用計算技術先驅者,它的CUDA架構產品深入人心。而在通用計算的API層面不止NVIDIA一家獨秀,Apple(蘋果)公司主導的OpenCL也贏得了業界同行的大力支持,當然NVIDIA也是OpenCL的核心成員之一。

??????? 2008年12月9日,2008亞洲SIGGRAPH大會上,全球視覺計算技術的行業領袖NVIDIA公司于今日正式宣布,完全支持Khronos Group新近發布的OpenCL 1.0技術規范。OpenCL(開放式計算語言)是一種全新計算應用程序接口
(API),它讓開發人員能夠利用GPU內部巨大的并行計算動力。OpenCL的加入是GPU革命史上又一重大的里程碑,為NVIDIA開發人員提供了另一個功能強大的編程選擇。

??????? Khronos Group是一個非營利的,會員組織的行業協會;Khronos 致力于創造免授權費用的應用程序接口 API 及相關標準生態系統,并將其標準及相關技術應用于包括手持設備,控制臺以及嵌入式系統中的高級動態多媒體應用,以提供用以將這些多媒體技術轉化為現實生產力的基礎。例如OpenGL ES、OpenKODE、OpenMAX、OpenVG、OpenSL ES、COLLADA等,當然還有今天的主角OpenCL。

??????? OpenCL一經提出就得到了全球頂級軟硬件廠商的廣泛支持,尤其是已經走在通用計算前沿的NVIDIA公司更是大力支持,NVIDIA公司嵌入式內容副總裁Neil Trevett就在Khronos機構中擔任OpenCL工作組主席一職。
??????? Neil Trevett先生表示:“OpenCL技術規范是NVIDIA等行業領袖意識到這一機遇之后所取得的成果。憑借其開放式、跨平臺的標準,該技術規范將在整個異構并行計算市場中得到更多的認可。NVIDIA將繼續活躍于OpenCL工作組以便推動該技術規范的發展,并在所有NVIDIA平臺中提供對OpenCL的支持,從而為開發人員提供另外一種方式來利用我們GPU中的超強計算動力。”
OpenCL是什么?與CUDA關系如何?
OpenCL是什么?與CUDA關系如何?

??????? OpenCL實際上是針對異構系統進行并行編程的一個全新API,簡單來說OpenCL它可以利用GPU進行一些并行計算方面的工作。這是API應用程序的編程接口,圖形里面也有很多API,比如OpenGL、DirectX是針對圖形的,OpenCL是針對并行計算的API。
??????? OpenCL開發人員可以利用GPU和CPU的計算能力,把GPU和CPU異構的系統運用在很多并行計算的領域里面。Khronos就是這樣一個組織,它由很多廠商組成,并有非常多的成員,這個工作組同時也是OpenCL的一個協調機構,也就是Khronos這個工作組它來負責制定OpenCL的規格、架構等等各方面。業界最主要的和圖形或者和計算相關的廠商都是Khronos的成員。
??????? 值得一提的是OpenCL得到Khronos組織里很多成員的支持,同時也驗證大家對開發GPU并行計算的能力這個需求越來越多,也正是因為有這個需求成就了OpenCL。

??????? 那么NVIDIA和OpenCL是一個怎樣的關系呢?
??????? 實際上OpenCL對于業界來說是非常重要也是非常好的一個標準,它的出現令業界擁有了一個共同的標準利用GPU的強大計算能力,然后應用在圖形以外各種各樣的并行計算中。其中NVIDIA一直也參與OpenCL的工作,正如前文所提及的NVIDIA副總裁Neil Trevett先生,他現在就任OpenCL工作組的主席,引導很多OpenCL的開發,當然這個組織中還有很多其他開發公司。
??????? OpenCL最早是Apple公司提出來的,從OpenCL一開始NVIDIA就和Apple公司進行非常緊密的合作。OpenCL開發的過程中,它的技術平臺都是NVIDIA的GPU,實際上OpenCL是基于NVIDIA GPU的平臺進行開發的。另外OpenCL的第一次演示,也是在NVIDIA的GPU上演示的,可以說到目前為止NVIDIA GPU幾乎是進行OpenCL程序的唯一的平臺。
??????? 另外還有非常重要的一點,對于Apple公司來說,他們是把GPU計算當成一種未來的趨勢,他們非常重視OpenCL,他們將會在新一代的產品里面選擇最適合于OpenCL運行的平臺。所以說他們新一代蘋果的筆記本電腦全都采用了NVIDIA的平臺,不管是MacBook Pro、Mac OSX都是采用了NVIDIA公司的平臺。實際上這也是從另外一個方面證明NVIDIA的GPU對于OpenCL的支持,到目前為止是最好的一個硬件的平臺。
徹底了解CUDA架構/OpenCL存在意義
徹底了解CUDA架構/OpenCL存在意義

??????? CUDA是什么?很多人認為它是一個由NVIDIA設計的一種新軟件或者新API,不過筆者在此要告訴大家,CUDA是一種硬件架構,也就是說目前NVIDIA的GeForce產品全都基于CUDA架構設計。CUDA架構最主要的包含兩個方面:一個是ISA指令集架構;第二硬件計算引擎。實際上它就是硬件和指令集,這兩個方面是CUDA的架構。
??????? NVIDIA GPU的架構就是CUDA的架構,舉例來說,你可以把它看成是跟Intel的X86或者IBM的Cell,他們都是CPU架構,而CUDA架構是基于GPU的架構。
??????? CUDA的GPU架構和CPU架構很類似,比如X86是包含一套指令集和執行X86各種各樣的CPU,而對于CUDA也是一樣的,NVIDIA有一套指令集ISA,還有各種各樣執行指令集和各種各樣的硬件引擎。另外CUDA到目前為止,它包含了一個C語言的編譯器,就是在CUDA上面的C語言,CUDA這個架構還可以支持其他的API,包括OpenCL或者DirectX,同時以后NVIDIA的CPU還支持其他語言,包括Fortran、Java、Python等各種各樣的語言,可以說這種架構是原生的,專門為計算接口而建造的這樣的一個架構。CUDA硬件架構包括指令集都是非常適合于并行計算,為異構計算而設計的一整套架構。

??????? 也許會有人疑問,既然有了CUDA為何還需要OpenCL,或者類似OpenCL的API呢?
??????? 簡單來說,對于編程人員他可以選擇不同的方式來進行編程,他們可以選擇OpenCL API編程也可以選擇C for CUDA語言來編程。
??????? 而API和語言的編程、開發存在著本質的不同,API是一個編程接口,它的核心是函數庫和應用程序開發的一個硬件接口。用API來編程的話它有一個好處,那就是可以訪問比較低層次的硬件資源,但這樣的最大化控制硬件資源帶來了很多弊端,例如在內存管理上就必須靠編程人員手動控制,這就需要編程人員要擁有高超的編程技術和深厚的經驗積累。而就C for CUDA來說,編程人員在利用C for CUDA語言來編程的時候,無需考慮過多與自身編程目的以外的因素。再拿前文提及的內存管理來說,C for CUDA使用Runtime進行管理。
?????? 不過不管OpenCL還是C for CUDA語言來編程,最終它都是需要通過一個驅動程序來變成一個PTX的代碼,PTX相當于CUDA的指令集來進行執行,然后交給圖形處理其或者交給硬件來進行執行。這兩個最終達到都是使用PTX或者在我們GPU上進行執行。
?????? 簡單來說,如果你想獲得更多的對硬件上的控制權,你可以使用API來進行變成。而如果你對API不是十分了解,或者說無法很好的掌控API編程,這時你可以用CUDA C語言來編程。二者是兩種不同編程的方式,它們有相同點也有不同點,但是有一點OpenCL和CUDA C語言進行開發的時候,在并行計算方面它們的概念十分接近,這也就奠定了程序之間的相互移植會比較容易。

??????? 對C語言編程了解的讀者應該知道,C語言利用的驅動程序就是API,也許談及這個很抽象,實際上C for CUDA就是一種C語言的擴展,而針對擴展的主要方面就是并行運算編程,這些是通過C的擴展來獲得。基本上認為CUDA的程序也是一種標準的C語言的程序,然后你使用一些關鍵字然后來對并行這方面計算,然后做一些區分。C語言最終編譯會成為PTX的代碼,然后在GPU上執行。
??????? OpenCL是一個API,就是應用程序的編程接口,OpenCL和OpenGL很像,這種API你可以調用API里面的函數庫,通過程序開發調用各種各樣的函數,實現各種各樣的功能。對于API來說一般它對硬件設備有比較完整的訪問權,你可以訪問硬件設備,可以對內存進行管理,最后OpenCL通過編譯和驅動程序可以生成PTX代碼在GPU上進行執行。
OpenCL未來發展目標激進
OpenCL未來發展目標激進

??????? 通過OpenCL的路線圖我們能夠看出,目前OpenCL還處于Alpha版本,但NVIDIA的產品已經可以非常好的支持OpenCL。明年第一季度Khronos Group會發布OpenCL Beta版本,而OpenCL1.0正式版也可能在明年正式推出。不過OpenCL最開始可能出現在Mac OS上,不過隨著以后的逐漸擴展,例如Windows或者Linux等系統都將會得以支持。

??????? 對于CUDA C語言,NVIDIA一直不斷地對其進行更深層次的開發,同時也不斷的有新版本的出現,到目前為止已經是CUDA 2.0。CUDA C語言NVIDIA研發已經超過5年時間,基本上從2003年左右就開始開發這個語言開發。
??????? 并且到目前為止,開發人員的數量已經是超過25000人,應用程序超過100個,特別在科學計算的領域里CUDA的應用極為廣泛,幾乎涉及到各種各樣的HPC高性能計算的領域。甚至現在HPC進入排行榜前100的高性能計算機里面也有使用NVIDIA基于CUDA的Tesla系統,它的開發語言正是使用了CUDA C語言。目前GPU集群組成的高性能計算機集群數量已經達到了30個,在中國也有相關產品。
??????? CUDA C語言是一個跨操作系統的開發工具,現在支持Windows、Linux、Mac OS,幾乎把控了目前最主流的操作系統。NVIDIA的CUDA C語言提供了很多的庫,這些庫主要包括FFT、BLAS等,它們可以提供各種各樣現成的代碼讓編程人員使用。
?????? 也許有這樣的開發者,他可能對CUDA并不熟悉,但他又想要使用CUDA的高性能計算該怎么辦?很簡單,他就把現有的應用軟件,例如FFT,使用CUDA的FFT的代碼直接替換,就這樣他便可以獲得20倍以上的性能提升。也就是說,這些庫是CUDA C語言非常重要的資源,可以讓大家縮短研發周期、體驗CUDA帶來的高性能,例如一些數學軟件像Matlab、Mathematica、LabView都有CUDA的插件,可以使用C語言的插件讓他更容易的利用CUDA。
CUDA/OpenCL共進退 前途無量
CUDA/OpenCL共進退 前途無量

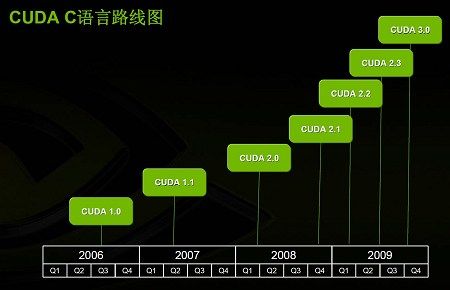
??????? 這是NVIDIA的CUDA C語言路線圖,現在CUDA正處于2.0版本,到今年年底NVIDIA可能會推出CUDA 2.1版本,到明年會有CUDA 2.2、CUDA2.3版本,最后迎來CUDA 3.0。隨著CUDA版本的升級,它的功能也在不斷地升級,比如最早的CUDA只能支持單精度的浮點計算,現在可以支持雙精度,還可以支持各種各樣的庫。

??????? 總結的來說,OpenCL無論對開發人員還是業界人員、消費者來說,都是一個非常好的API,一個應用程序的接口。它可以使開發者更容易的開發出跨平臺GPU計算程序,并將GPU強大的計算能力利用到各種各樣應用計算中。
??????? 對于NVIDIA來說,現在CUDA架構上除了C語言以外,現在新增加了OpenCL或者DX11這樣的API,對于開發人員來說也是提供了一種更好的GPU計算的開發環境。因為對API很熟悉的開發人員,他們肯定會很高興的看到OpenCL或者新的API的加入,對于這些人來說他們很容易利用這種API進行各種各樣GPU計算程序開發。對于NVIDIA來說還會繼續對C語言包括其他語言的支持,實際上對NVIDIA CUDA C語言來說Runtime C仍是目前唯一的語言環境。今后除了C語言外,NVIDIA還會推出更多的CUDA語言,這包括Fortran,還會有Java等。
性能與功能兼備 OpenCL和CUDA全解釋

Khronos組織最近規范了OpenCL 1.0, OpenCL實際上是針對異構系統進行并行編程的一個全新的API,簡單來說OpenCL它可以利用GPU,然后進行一些并行計算這方面的工作,這是API應用程序的編程接口,圖形里面也有很多API,比如OpenGL那是針對圖形的,OpenCL是針對并行計算的API。OpenCL開發人員可以利用GPU和CPU的計算能力,把GPU和CPU異構的系統運用在很多并行計算的領域里面。Khronos是一個組織,有很多廠商組成,有非常多的成員,這個工作組同時也是OpenCL的一個協調機構,也就是Khronos這個工作組他來負責制定OpenCL的規格、架構等等各方面。業界最主要的和圖形或者和計算相關的廠商都是Khronos的成員。

OpenCL里面有很多的成員,這就導致了有更多可以利用OpenCL來開發的程序、軟件以及各種各樣的應用。這從一方面肯定了OpenCL強大的聚合實力,但一方面也預示著這將會形成一個旺盛的需求。實際上,OpenCL對于業界來說是非常重要也是非常好的一個標準,NVIDIA看準了這一標準,利用GPU的強大計算能力應用在圖形以外各種各樣的并行計算方面,NVIDIA一直在參與OpenCL的工作。NVIDIA副總裁Neil Trevett,目前則是OpenCL工作組的主席,引導很多OpenCL的開發。這個組織里面當然還有很多其他開發公司。NVIDIA公司不少員工都在參與這項工作。

OpenCL最早是Apple公司提出來的,由于OpenCL一開始NVIDIA就和Apple公司進行非常緊密的合作。所以目前OpenCL也完全是基于NVIDIA GPU的平臺進行開發的。Apple十分重視OpenCL,不管是MacBook Pro、Mac OSX等新產品采用了NVIDIA的平臺。目前OpenCL路線圖目前還是屬于Alpha版本,明年第一季度可能是Beta的版本,09年時OpenCL1.0可能正式推出,OpenCL最開始可能出現在Mac OS上,以后逐漸的擴展到其他的操作系統,像Windows或者Linux。

NVIDIA一直還是不斷地對這個語言進行更深層次的開發,到目前為止已經是CUDA 2.0。開發人員的數量已經超過25000個,應用程序數量也已經超過100個,特別是很多的科學計算的領域等幾乎涉及到各種各樣的HPC高性能計算的領域都有CUDA的身影出現,甚至現在HPC進入排行榜前100的高性能計算機里面也有使用Tesla系統,Tesla系統就是一個GPU集群計算典范,現在支持Windows、Linux、Mac OS,幾乎最主流的操作系統NVIDIA都能支持。CUDA最主要的包含兩個方面:一個是ISA指令集架構;第二硬件計算引擎;實際上是硬件和指令集,這兩個方面是CUDA的架構。從這張圖片可以看到,當GPU變身成CUDA運算時候,NVIDIA的GPU的架構就全是CUDA的架構,你可以把它看成是跟X86或者cell,他們都是架構,這個也是CUDA架構,但是是基于GPU的架構。這個和CPU的架構很類似,比如X86是包含一套指令集和執行X86各種各樣的CPU,對于CUDA也是一樣的,NVIDIA自有一套指令集ISA,還有各種各樣執行指令集各種各樣的硬件引擎。另外CUDA到目前為止,它包含了一個C語言的編譯器,就是在CUDA上面的C語言,CUDA這個架構還可以支持其他的API,包括OpenCL或者DirectX,同時以后NVIDIA還有其他的語言,包括Fortran、Java、Python等各種各樣的語言,可以說這種架構是原生的,專門為計算接口而建造的這樣的一個架構,NVIDIA的硬件架構包括指令集都是非常適合于這種并行計算,這種異構計算而設計的一整套的架構。

CUDA和OpenCL的關系是不沖突的,OpenCL是一個API,在第一個級別,CUDA這個架構是更高一個級別,但是在這個架構上不管是OpenCL還是DX11這樣的API,還是像C語言、Fortran、DX11計算,NVIDIA都可以支持。作為程序開發員來講,一般他只懂這些語言或者API,他可以選擇我用什么樣的語言來開發我的程序,不管他選擇什么語言,他希望調用GPU的計算能,在這個架構上都可以用CUDA來編程,對于編程人員來講這個很容易,他不需要對OpenCL的架構有非常深的了解,他就可以做到。這個方面上面實際上是一些開發工具,這個道理和CPU的編程實際上還是很類似的,比如你有X86的指令集,又有X86各種各樣的CPU,然后你只需要對這個指令集編輯,X86架構上有各種各樣的開發工具,當然也有C語言,Fortran語言有Python語言,或者是其他的像Java或者以前的Pascal語言,你用不同的語言進行開發,最后你的執行還是在X86的架構上執行。NVIDIA的CUDA也是一樣,有CUDA這一套指令集,有這樣的硬件,也就是說有不同的途徑來進行開發,你可以用OpenCL或者DirectX這樣的API來進行計算的開發,也可以用C語言或者Fortran或者Java開發,這個道理是一模一樣的,可以做這方面的類比。OpenCL和C語言的一些異同點。對于編程人員來說他可以選擇不同的東西來進行編程,就像之前說的可以選擇OpenCL編程也可以選擇CUDA上面的C語言來編程,或者API的語言來編程。API和C語言進行開發是有一些不同的,API是一個編程接口,它的核心是函數庫和應用程序開發的一個硬件接口,對于API來編程的話,它有一個好處,那就是可以訪問比較低層次的硬件,但是他也有一點,就是很多的東西特別是像內存的管理,這個是需要程序員自己來進行管理的。而C語言相對來說NVIDIA在利用CUDA C語言來編程的時候,很多東西是由開發環境來進行管理的,比如內存他是用runtime進行管理的,runtime實際上就是運行時的一些支持程序來進行這方面的管理。不管OpenCL或者CUDA C語言來編程,最終它都是需要通過一個驅動程序來變成一個PTX的代碼,PTX相當于CUDA的指令集來進行執行,然后交給圖形處理其或者交給硬件來進行執行。這兩個最終達到都是使用PTX或者在GPU上進行執行。基本上大家可以理解為如果你想獲得更多的對硬件上的控制權的話,你可以使用API來進行編程,比如我是一個科學家我對API不是太了解,你也可以用CUDA C語言來編程,這是兩種不同編程的方式,他們有他們相同點和不同點。但是有一點OpenCL和CUDA C語言進行開發的時候,在并行計算這塊,他們的概念是差不多的,這兩種程序在程序上是有很大的相似度,所以程序之間的相互移植相對來說也是比較容易。

大家如果使用了C語言的話都知道C語言使用驅動程序就是API,實際上是一種抽象,這個抽象主要是指和硬件相關的抽象。實際上CUDA C語言是一種C語言的擴展,這擴展的一部分主要是進行并行運算編程的一方面,這些是通過C的擴展來獲得的。基本上認為CUDA的程序也是一種標準的C語言的程序,然后你使用一些關鍵字然后來對并行這方面計算,然后做一些區分。C語言最終編譯會成為PTX的代碼,然后在GPU上執行。OpenCL是一個API,就是應用程序的編程接口,OpenCL和OpenGL很像,這種API的話你可以調用API里面,通過程序開發調用各種各樣的函數,實現各種各樣的功能。對于API來說一般它對硬件設備有比較完整的訪問權,你可以訪問硬件的設備,可以對內存進行管理,這是由開發人員通過編程來做的這些事情。最后完了OpenCL通過編譯、通過驅動程序可以生成PTX代碼在GPU上進行執行。鄧老師講的這個目的是如果你作為編程人員要利用GPU的計算能力開發你的應用的時候,有兩種模式——根據你不同的需求:如果你需要對硬件有更多的控制,你可以通過OpenCL來編你的API和你的程序,那么它可以在CPU上運行;如果你不需要這個,同時對硬件有控制權,而且你又不太懂API這些東西,只要用C就可以編程了,或者CUDA來編程,編完程序以后也可以在CPU的硬件上跑,這個東西不需要在CUDA支持GPU上跑。講這個的目的是不同的編程模式可以選擇不同的方法,就是用OpenCL還是用CUDA C語言。
OpenCL和OpenGL在很多方面都很類似,實際上他們也是一個共同的組織來進行管理的。對OpenGL圖形開發比較熟悉的人他使用OpenCL計算這方面的開發,他們就會非常熟悉它里面所涉及的很多方面,這是OpenCL的一個非常明顯的特點。如果你對圖形編程很熟悉的話,使用DX11編程,可能比較容易,這是API的一個好處。但是對于大部分的科學家來說,可能對API,OpenCL這種東西可能完全不熟悉,他需要的是我就像在CPU上編程一樣,對CPU的計算編程,他可以使用CUDA C語言,在CUDA C語言里面把CPU看成專門做計算的協處理器來進行編程的。這是兩個之間不同的模式。
總結:
OpenCL不管對開發人員還是業界人員來說還是消費者來說都是一個非常好的API,一個應用程序的接口。它可以使得開發者很容易的開發出跨平臺的GPU計算的程序,充分利用GPU強大的計算能力然后應用在各種各樣計算的方面。
對于NVIDIA來說,在CUDA的架構上除了C語言以外,現在新增加了OpenCL或者DX11這樣的API,對于開發人員來說也提供了一種更多的GPU計算的開發環境的一種選擇。他們如果對API很熟悉的一批人,他們肯定會很高興的看到OpenCL或者新的API的加入,對于這些人來說他們很容易利用這種計算的API然后開發各種各樣GPU計算的程序。對于NVIDIA來說還會繼續對C語言包括其他語言的支持,實際上對NVIDIA CUDA C語言來說目前還是唯一的針對GPU的runtime C的語言環境,runtime C的語言環境意思是GPU直接執行這個C語言。
現在已經有非常多的用戶已經在使用CUDA C語言,剛才介紹有25000名這樣的開發者,應用程序也有很多,而且這種應用程序每一刻都在不斷地增加數量。CUDA C語言還會進一步的發展,就像剛才所說的還會有新的版本推出,而且會和像OpenCL和DX11這種計算API會共存,今后也是這樣。除了C語言以外NVIDIA還會推出更多的其他CUDA的語言,包括Fortran,還會有Java等。
性能與功能兼備 OpenCL和CUDA全解釋
編者按:Apple是OpenCL創始人,NVIDIA支持DirectX以及OpenGL,這會形成一個對立還是和諧的合作?從Apple最新的Macbook中可以看到兩者已經很好地融合在一起。究竟這種關系是怎樣融合起來的?今天我們籍著這個話題為你一一解答:
最近NVIDIA的CUDA技術成功地讓GPU分擔了CPU任務,成功地讓GPU擁有了CPU計算能力,隨著CUDA以及GeForce深入到PC,更多的應用將會被提出。Apple最新產品Macbook也應用了NVIDIA的MCP7A芯片組以實現多媒體更高速運算。眾所周知,NVIDIA是DirectX以及OpenGL的忠實支持者以及這兩個規范下的重要擁護者,而Apple則是OpenCL的重要擁護者。究竟他們之間是一種怎樣的關系?(下面是CUDA應用的各種例子:)

《GPU新里程 NV物理加速Demo體驗測》

《發自內在的誘惑 9400M游戲及PS體驗》

《開始說畫 訊景9600GSO體驗NV新技術》
在這些精彩的應用背后,究竟隱藏著一個怎樣的開發項目?NVIDIA未來對于CUDA以及其項目有無進一步的消息?究竟,CUDA與CopnCL是怎樣的一個融合體?
關于OpenCL與CUDA的一些問題:
問:
AMD是OpenCL里面的嗎?
答:
對。OpenCL是包含很多家公司的,主要業界的公司都包含在里面,包括IBM、戴爾這些公司包括HP。OpenCL是一個非常開放的行業組織,所有的公司都在里面,他們和NVIDIA是沒有沖突的,NVIDIA也是很積極地參與技術。
Stream基本上還是基于一種傳統CPU的一種方式,AMD當然他會說他會有CAL,CAL實際上是套指令集,可以用匯編語言的方式來開發軟件,但是匯編方式開發軟件的話,對搞計算的人來說不大現實,你要讓他用匯編語言來說的話可能確實是一個折磨。還有一個Brook,這個是斯坦福大學開發的,它是類似于C的東西,他是把底層GPGPU的計算方式類似于C的這種語言,他不是C語言而是類C語言,語法和C語言比較類似,他內部做的還是使用頂點這樣的數據。
另外Stream的方式還有一個很大的問題,他主要是基于本地的板載內存,板載內存存入數據,然后換算完了再寫到板載內存。這樣對GPU非常強大的計算能力來說,帶寬是一個非常大的障礙,你想想每秒種進行1P的數字計算的話,你需要多少的帶寬?32位浮點的話這是4個字節,如果你1P的話,NVIDIA把他承加這部分也算上就相當于再乘以2,至少需要每秒2P的吞吐量然后才能夠滿足它,板載內存的話每秒需要幾十P,這實際上是Stream的方式,從效率上是一個比較低的計算。而對于開發者來說也會碰到很多的問題,對于NVIDIA來說支持C,這是真正GPU上運行的C語言。C語言有一個很重要的特點,需要有存儲體系,對于NVIDIA GPU來說是有存儲體系的,內部有share memory,然后大部分的數據,編譯器會把大部分的數據盡可能的讓它在share memory上進行計算,share memory帶寬非常高,因為它在芯片內部,它的速度接近于寄存器的速度,他在share memory上跑的話,然后再把這個數據再輸出,這樣的話他真正地可以利用到絕大部分的計算機。實際上CUDA的效率,在應用軟件上可以看出來,像傳統的高性能計算領域的話,NVIDIA的峰值速度比如像G80是300多G浮點計算能力,效率是非常高的。這也是為什么這么多人在使用CUDA C語言來進行開發,這是一個很重要的原因。
實際上你說要使用Stream來開發的應用軟件,我知道的只有一個是folding@home,ATI比NVIDIA進入早兩年,但是NVIDIA進入以后使用CUDA的語言來寫folding@home客戶端的軟件,性能立刻比它高好幾倍,folding@home你可以看到一個很特別的——他原來一個版本是可以跑在它上一代的架構應該是3850或者3870的GPU上,但是如果它4850和4870出來以后,從原點上來說他的計算能力比3850、3870要高2.5倍,但是它的folding@home的性能反而下降了,原來他是200左右,就是3870,他是每天可以模擬200萬秒的性能等級,4870出來以后每天只能模擬170萬秒。這是為什么?這個軟件不是使用Brook開發的,直接使用匯編的方式開發的,這樣的話你需要對每一個新的GPU,你都要對他進行編程,每個架構都需要對它重新進行編程,然后才可以得到一個最好的效率。中間有很長時間4870的性能都比3870在folding@home上低,后來他確實重新編程了,過了好幾個月,有些新的版本出來了,4870比3870高了。這就是說使用匯編方式的話會帶來一個非常大的問題,你任何一個應用軟件里面都需要重新優化、重新編程。
匯編語言實際上就是機器碼來進行編程,這個是屬于體力比較好的人才能干的了,就是記憶也比較好的人才能干的了。高級語言相對來說確實要簡單太多了,就像剛才我說的有些人甚至對編程都不是很熟悉的,他只要基本上知道源代碼里面哪些代碼是在做什么東西,然后他就可以使用CUDA,他不見得核心部分計算部分一定要自己編,就像剛才說的NVIDIA有很多現成的庫,都是直接寫好的函數,這個函數把原來的函數替代掉,就可以取得很好的性能。NVIDIA提供很多函數庫,這些函數庫有一些是NVIDIA公司開發的,像FFT、線性代數或者是快速傅里葉變換等,但是有一些庫是第三方幫NVIDIA開發的。NVIDIA實際上形成一個非常好的環境,不斷的有人針對CUDA來開發,不管是應用軟件或者是中間件,這些中間件的話就包含各種各樣的庫。
對于CUDA來說,說老實話和Stream相比的話,幾乎現在沒什么可比性。確實對OpenCL、DirectX這樣應用的話,我相信在CUDA的架構上運行這個程序也比在Stream上運行程序好的多。因為NVIDIA使用的架構實際上你開發的時候,NVIDIA就考慮到計算方面的應用。別的方案的話,他有可能計算僅僅是圖形的一個副產品。NVIDIA在開發的時候圖形和計算這兩部分幾乎作為同等重要的,兩個都必須要滿足的東西來做架構方面的設計。
問:
OpenCL它的特點一個是開放,OpenGL也很開放,但是它的更新實際上非常、非常的慢,OpenCL會有這種情況嗎?
答:更新的話,這是由一個專門的組織Khronos,這個組織是有很多廠商來組成的,每個廠商派一些人然后進來在組織里面,然后每個公司互相協商,然后制定各種各樣的標準,比如你推出一個新的版本要達到什么功能,價格是怎么樣的?這些廠商來進行協商的,廠商不太一樣,比如Microsoft我自己的東西,我說的算,這是完全不一樣的。但是我相信OpenCL從目前來看的話,它還是挺快的,你看它現在的α版本明年一季度就進入β版本,明年終第一版就會推出。
問:
OpenGL和DirectX的關系一樣,我現在看到CUDA這邊更新的頻率明顯比OpenCL快很多,NVIDIA想把這個東西打造成一個GPU通用計算上的DirecX嗎?
答: 我覺得應該是沒有什么可比性的。剛剛強調DirectX是API,CUDA不是API,CUDA是一個硬件架構。剛才說的很多版本是CUDA C語言的版本,這是CUDA C語言版本的路線圖,(PPT)C是語言,CUDA是一個硬件架構,GPU的架構。大家很容易會把C和CUDA融在一塊兒,不是這樣的。CUDA架構類似與X86的架構。 實際上CUDA的C語言和OpenCL在并行計算這塊,它的一些觀念都挺類似的,包括它計算的數據組織方式都很類似。我相信NVIDIA在OpenCL的規格、開發方面聯系一直是非常緊密的,包括Apple也參與到其中。NVIDIA在這方面的很多經驗,也會得到一些體現。這兩個程序之間的移植也是很容易的,現在他使用CUDA C語言來寫,OpenCL出來以后,如果他想移植OpenCL的程序,相對來說不用全部重頭寫。
問:
這個東西能否用在微軟上?
答:
可以,像OpenGL也不是微軟的,但是一樣可以在微軟上跑。
問:
現在一般都是OpenCL?
答:
這個是程序模型的原因,而且現在看起來在OpenCL在Vista下,目前看起來沒有太大的問題。原來大家都一直以為在Vista下面OpenCL不會有ICD,實際上最后還是有ICD。這個東西的話現在OpenGL的軟件,我經常跑各種各樣的專業軟件,很多在OpenGL下來以后都沒有問題,非常典型的OpenGL的應用程序跑地都挺好的。對于OpenCL或者OpenGL在微軟下,你可以看成是一個API,這個API你是可以安裝的,比起微軟自己原來帶有的這個東西。這算是一種應用程序吧。
問:
OpenCL看似更趨向于底層開發的API,那相對于CUDA C來說,OpenCL開發的程序執行效率會不會比CUDA C效率更高一些?
答:
完全不存在這個問題。說老實話效率高不高,并不取決于你用的什么語言,什么樣的API,更大程度上取決于你的代碼,你代碼的優化程度是怎樣的?這個才是影響他代碼的效率。
問:
在OpenCL出來之前,CUDA并行計算的優勢已經很大了,現在為什么還非要出一個OpenCL通過中間的東西來調用,我感覺不是費一道事嗎?
答:
OpenCL是一個跨平臺的一種API,這個API就像OpenGL一樣,它也是希望跨平臺,就是跨軟件和硬件的API,OpenCL也是一樣也是跨軟件和硬件平臺的API,算是一個業界的標準,不管是哪一家的,原則上都可以支持OpenCL這個平臺,支持API。OpenCL不是NVIDIA推出來的,OpenCL最開始是Apple提出來的,但是NVIDIA確實是在這個標準的制定當中,NVIDIA和Apple進行了很緊密的合作,然后NVIDIA提供了很多支持包括硬件方面的支持。 模式不一樣適用的人群也不一樣。適用的人群也不一樣,我的理解是OpenCL和OpenGL他們在很多方面都非常的接近,如果習慣使用OpenGL他如果用OpenCL來開發的話會感覺到輕車熟路,就像是Computer shader也一樣,如果你是多媒體這方面的應用,你又想使用圖形又想使用GPU的來計算,你用Computer shader來做很容易。但是對CUDA C來說,它是用的人群是你能夠使用C語言的人你都可以使用CUDA C來開發。使用人群完全是不一樣的,我想可能也有一些人雖然他也會C語言,但是他還是希望用OpenCL來進行開發,用他跨平臺的特性。另外或者因為其他的一些原因,包括他希望更多對硬件方面的控制,然后他應用軟件里面他可能希望對內存進行完全的控制,這些用戶的話他可能就會選用OpenCL來進行開發。這是兩個不同的東西。我相信即使OpenCL出來以后,CUDA C語言的使用者還是會越來越多的。
如果認為一種開發環境就可以取代其他的開發環境,這個是不現實的。我舉個例子來說在X86的架構上,除了C語言以外還有Java、Fortran還有Pascal語言,這些不可能互相取代的,每種語言、每種API都有它使用的人群,都有喜歡用的人。不同的語言、不同的API都會滿足不同人群的。我覺得現在不是太多,GPU計算和API語言不是太多,現在還比較少,NVIDIA還會不斷地推出Java、Pascal或者C++也會支持。如果以前沒有Fortran,那些老年人你要讓他們學習C語言的話,他們可能用Fortran用了幾十年,所以說讓他開發的話他就比較痛苦,現在有了Fortran,他就可以直接用Fortran來寫CUDA的程序,說不同開發的途徑有不同的用戶,這個是肯定的。
問:
Havok現在怎么樣了?
答:
Havok目前為止基本上只能使用CPU做物理計算,而PhysX可以使用GPU、可以使用CPU也可以使用PPU來做物理方面的計算。當然這三種里面GPU的效率是最高的,PPU的話估計現在也沒什么人買,GPU的效率是最高的,而且他真的是可以帶來10倍的性能提升,這個性能提升在物理計算方面,CPU和GPU相比的話性能提升10倍,這是很常見的。而且PhysX它是可以作為一種最基本的平臺,還有很多第三方的中間件在上面,基于PhysX。它實際上是利用PhysX的平臺可以實現別的東西,比如類似于人工智能。NVIDIA曾經給大家提供過一個美式橄欖球的游戲視頻,那個游戲真的是很酷,但是我不能放給大家看,那家公司要求NVIDIA只能提供視頻給大家,不能把游戲給大家看。真的是很酷,非常大的場面,那個場面里面每個觀眾都是一個不同的人,有一個體育場9000人,每個觀眾都是一個實際的人,而且每個觀眾都是不太一樣的。最主要他真正的把人的動作模擬的非常逼真,你撞擊撞到什么位置,比如說你看到撞過來的你會下意識的做一些防守的動作。這些防守的動作人跑過來不同的方向,動作也不一樣的。比如你跌倒,跌倒空中你可能會有下意識的支撐動作,這些都會有,以后游戲真的是會越來越逼真。NVIDIA所謂靜態逼真和動態逼真就是這樣。靜態逼真像這個,Crysis已經做的很逼真了,但是真正動起來還是感覺比較僵硬,就是整個場景里面不管人物的動作或者其他的運動都是事先設置好的,就像放的錄像一樣,而不是真正時時運算出來的。如果你使用大量物理計算的話,真的可以獲得很好的動態逼真度。如果要實時計算對硬件的要是就會很高,如果持有CPU加速的話它的動態架構和NVIDIA的動態架構就有區別,就會影響速度不一樣。Havok用CPU來做物理計算,它計算能力只能那么高,你里面設置的物理效果相對來說就會很有限。而且CPU還有很重要的任務在人工智能或者場景管理的方面,所以說使用GPU來做物理方面的加速是非常有效的。另外還有一點新的180驅動支持更多的GPU PhysX的配置,你可以使用2片的顯卡,一片用來渲染,一片用來做物理加速,這是效率最高的一種方式。你用一片來做同時做渲染同時做物理計算,這也是可以的,和純粹使用CPU做物理計算的話性能會高很多,但是并行計算和渲染都是需要GPU的計算資源,所以如果你用單獨的一片顯卡的話,用來做物理加速的話,性能又會得到一個很大的提升。大家最好可以測試一下這方面的效果。
問:
比如像EA的100多款游戲,它那個PhysX主要是用GPU運算還是CPU運算?
答:
只要是PhysX支持的游戲當然是GPU了。每一款游戲都可以采用不同的策略,我相信這些游戲開發商的話也會采用不同的策略來處理這些事情,當然他最好的效果肯定是使用GPU來做物理這方面的計算,然后游戲里面放大量的物理效果,這是最好的方式。當然也會有一些比較簡化的模式,就是說你沒有NVIDIA的顯卡,然后給你提供一個比較簡單,物理效果比較少的模式。你還可以運行,但是物理效果帶來的各種各樣的好處相對就比較少。這也是為什么跟大家強調的,NVIDIA現在叫GeForce + CUDA,里面有很多的新功能,PhysX是NVIDIA獨有的,這是別人沒有辦法做到的。你要想作為一個玩家,你想享受更好的效果當然要在NVIDIA的顯卡上運行,才會有更好的效果。這個市場是開放的,誰都可以去,但是看誰能夠跑在前面。
問:
PhysX是跨平臺的嗎?PhysX主要是用于游戲嗎?現在大部分的游戲基本上都是DirecX的。
答:
游戲機也可以支持。OpenGL和DirecX的API是獨立的,現在OpenGL游戲確實越來越少,所以大部分的游戲都是DirecX的。
問:
PhysX不是跑在CPU上的?
答:
他是跑在GPU上。對于PhysX來說CPU也可以跑。
Badaboom 1.1介紹:
Elemental公司會提供Badaboom 1.1版的。Badaboom輸出形式還是在H.264,這個已經成為業界的標準了。所有的手持設備都支持H.264,因為H264編碼效率確實比較高,但是輸入的形式情況千差萬別,輸入現在有很多用不同的編碼格式,不同的封裝格式。編碼格式比如像WMA、Mpeg2、VC1等來自各種各樣的渠道。還有封裝格式比如像AVI、MKV等。不同的編碼格式和封裝格式現在Badaboom 1.1都可以支持,這是一個方面。另外一個方面增加了更多的預設式的東西,原來主要提供的是Apple的iphone、ipod或者iTV這種的支持,新的提供更多的支持包括像youtube,youtube這在國外用的很多,另外還有Black Berry 9000的支持,另外對微軟播放器rom的支持。當然我還可以提供用戶自定義的輸出格式,如果你想自定義,分辨率自定義影片的細節你也可以自己定義,包括碼率等。第三非常重要的一點Badaboom 1.1可以支持Main Profile的H.264。過去都是Baseline的編碼器,Baseline和Main Profile最重要的區別是Main Profile可以使用基于二進制的可編程的雙編碼。它就是說在相同的碼率下,它的畫質就更好。Main Profile一個非常重要的特點,幾乎所有的像藍光的影片H.246的影片幾乎都是采用Main Profile,因為Main Profile可以提供更好的畫質。現在像快速的編碼器現在只有Elemental的Badaboom 1.1可以支持Main Profile。另外一個是支持全高清的輸出,1080P的輸出,現在的版本支持到720P,以后可以支持到1018P的輸出。還有一點是非常重要的,可以支持多GPU。如果你有兩個GPU的話可以獲得性能翻番,即是有兩個GPU來進行編碼。這是它的一些基本情況。
實際上對于Badaboom來說,有一點非常重要Badaboom確實是非常容易使用,而且真正是解放CPU的一種轉碼工具。Badaboom特別是在像H.264進行轉碼的時候,H.264的影片比如藍光的影片你把他轉成ipod的影片,CPU的占有率非常低,所有的視頻編碼和解碼全在GPU上完成。而且你在轉碼的過程中畢竟還需要二三十分鐘,轉碼過程中可以做別的沒有任何問題。NVIDIA不像別的公司宣稱什么同時利用CPU和GPU,我都不太清楚他究竟用的是CPU還是GPU?大家可以測試一下,你看看它GPU的功耗有沒有增加?這是最簡單的一個方法,看看GPU有沒有負載?因為從原理上來說一個視頻流,除非你不怕數據在CPU和GPU來回倒,要不然的話一個視頻流很難把負載分到CPU和GPU上,這兩個數據處理的方式完全不一樣的。
從另外一個角度,就是畫質,這是非常重要的。編碼的效率和畫質是嚴重相關,我可以這樣說,NVIDIA甚至可以做出一個可以損失一點畫質,然后我可以獲得好幾倍性能提升的編碼,因為H.264的編碼太多了,比如你幀間預測的時候,你可以少拿幾個關鍵幀,或者你完全不要幀間預測,只有幀隊預測你也可以進行編碼,但是效果怎么樣,那是另外一回事。最終所有運動視頻的編碼,最重要的一點是運動預測。如果多幀之間有運動的關系,不用保存所有的圖形,你只要保存運動的適量就可以了,所以大大降低文件的尺寸。如果你沒有預測的話,意味著每一張畫面都要進行壓縮,你要達到比較小的分率的話,壓縮質量慘不忍睹。過去最早的Mpeg 2也可以使用CPU來做時時的壓縮,當然也可以買一個1萬塊錢的壓縮卡,1萬塊錢的壓縮卡這和CPU壓縮有什么區別?CPU壓縮的幾乎沒法看。我可以做到速度很高但是畫質很差。NVIDIA希望在最好畫質的情況下獲得盡可能快的性能,這也是Elemental這家公司想的。現在看起來Badaboom的畫質和頂級的非常專業的編碼工具得到的畫質幾乎是一樣的,但是它的性能比這些編碼工具快很多。
我覺得好像預測然后“這個很快,這個真的很快,快了以后當然畫質不太好,這算是一個小缺點。”畫質不太好這是一個大缺點,不是一個小缺點,NVIDIA轉碼的話是最好的畫質,當然是越快越好,但是畫質是絕對不能妥協的。就像3D游戲一樣,大家看一眼畫質,全世界都再說這個畫質是不是有問題,NVIDIA就是追求最好的畫質然后盡可能提升性能。
問:
像現在掌上設備不支持Cabac解碼嗎?
答:
掌上設備我還不太清楚是不是所有的不支持,但是大部分的都支持Baseline,但是還有一個Main Profile編碼方式還是有一個非常大的好處,比如你要想把一個1080P的視頻轉成720P,碼率小一點,然后放在網絡上,讓大家下載。
問:
有些人在國外破解的BD都是原版的,下載做成720P的。
答:
以后可以用Badaboom,比如Badaboom它可以自己定義輸出的,包括碼率可以自己定義,還是很方便,現有的還是用H.264。
問:
像純做編碼,這塊像Badaboom做這個?它不是有編碼加速嗎?
答:
在這個過程中,其他公司再做的時候NVIDIA也不能透露,但是這肯定是他們的第一步,后續的還會有做。在BD方面相對來說比較的快一點,因為你要做核心來重新編寫的話,這個可能開發的周期也比較長。而且CUDA看起來做濾鏡這方面還是特別實用的,現在CUDA程序還有好幾種。
誰主沉浮 OpenCL與CUDA架構深入解析!
前言
最近,Khronos公布了OpenCL(Open Computing Language)的第一個測試版本,一經發布便在通用計算領域掀起來軒然大波!OpenCL是由蘋果公司發起,業界眾多著名廠商共同制作的面向異構系統通用目的并行編程的開放式、免費標準,也是一個統一的編程環境。便于軟件開發人員為高性能計算服務器、桌面計算系統、手持設備編寫高效輕便的代碼,而且廣泛適用于多核心處理器(CPU)、圖形處理器(GPU)、Cell類型架構以及數字信號處理器(DSP)等其他并行處理器,在游戲、娛樂、科研、醫療等各種領域都有廣闊的發展前景。

那么OpenCL與NVIDIA的CUDA架構是什么關系,是否是外界認為的競爭關系?目前眾多的通用計算標準中,比如NVIDIA的CUDA、Khronos的OpenCL、AMD的Stream,CAL、Brook+、微軟下一代的Computer shader等,他們之間有什么異同,看完這篇文章,相信你就會有一個大概的了解……
OpenCL來了!
Khronos是一個開發組織,著名的OpenGL就是出自Khronos之手,Khronos有很多廠商組成,OpenCL工作組同時也是OpenCL的一個協調機構,來負責制定OpenCL的規格、架構等等各方面。業界最主要的和圖形或者和計算相關的廠商都是Khronos的成員。
OpenCL實際上是針對異構系統進行并行編程的一個全新的API,OpenCL可以利用GPU進行一些并行計算的工作。我們知道,圖形里面有很多API,比如OpenGL是針對圖形的,而OpenCL則是針對并行計算的API。 OpenCL開發人員可以利用GPU和CPU的計算能力,把GPU和CPU異構的系統運用在很多并行計算的領域。

OpenCL對于業界來說是非常重要也是非常好的一個標準,這樣業界有一個共同的標準可以利用GPU的強大計算能力,然后應用在圖形以外各種各樣的并行計算方面。NVIDIA公司的副總裁Neil Trevett是OpenCL工作組的主席,引導很多OpenCL的開發,NVIDIA公司很多員工都在參與這項工作。
OpenCL最早由Apple公司提出的,OpenCL發起NVIDIA就和Apple公司進行非常緊密的合作。OpenCL開發的過程中,技術平臺均為NVIDIA的GPU,實際上OpenCL是基于NVIDIA GPU的平臺進行開發的。另外OpenCL在大概兩個多月以前進行了第一次演示,也是運行在NVIDIA的GPU上。

對于Apple公司來說是把GPU計算當成一種未來的趨勢,他們非常重視OpenCL,在新一代的產品里面選擇了最適合于OpenCL運行的平臺。所以新一代蘋果的筆記本電腦全都采用了NVIDIA的平臺,不管是MacBook Pro還是MaBook。實際上這也是從另外一個方面證明NVIDIA的GPU對于OpenCL的支持。
OpenCL與CUDA并非敵對關系
很多人對什么是CUDA可能還有一些疑慮,并沒有搞清楚CUDA到底是什么。實際上CUDA最主要的包含兩個方面:一個是ISA指令集架構;第二硬件計算引擎;實際上是硬件和指令集。 也就是說我們可以把CUDA看做是與X86或者cell類似的架構,但是是基于是GPU,而不是傳統的CPU。
這個其實很好理解,把它和傳統的和CPU的架構比較下相信就更容易理解,傳統X86是包含一套指令集和執行X86各種各樣的CPU,對于CUDA也是一樣,CUDA有一套指令集ISA,還有執行指令集各種各樣的硬件引擎。CUDA到目前為止包含了一個C語言的編譯器,當然CUDA架構還可以支持其他的API,包括OpenCL或者DirectX,同時CUDA還會有其他的語言,包括Fortran、Java、Python等各種各樣的語言,可以說CUDA架構是原生的,專門為計算接口而建造的這樣的一個架構,這種硬件架構包括指令集都是非常適合于這種并行計算,為異構計算而設計的一整套的架構。

上圖很好的解釋CUDA和OpenCL的關系,他們并不是沖突關系,而是包容關系。OpenCL是一個API,在第一個級別,CUDA架構是更高一個級別,在這個架構上不管是OpenCL還是DX11這樣的API,還是像C語言、Fortran、DX11計算,都可以支持。作為程序開發員來講,一般他們只懂這些語言或者API,可以采用多種語言開發自己的程序,不管他選擇什么語言,只要是希望調用GPU的計算能,在這個架構上都可以用CUDA來編程。
CUDA編程的道理和CPU的編程很類似,比如有了X86的指令集,又有X86各種各樣的CPU,那么我們只需要對這個指令集編程即可。X86架構上有各種各樣的開發工具,當然也有C語言,Fortran語言,Python語言,Java或者以前的Pascal語言,不論你使用什么語言進行開發,最后還是在X86的架構上執行。CUDA也是一樣,有了CUDA的指令集,有了支持CUDA的硬件,我們就可以采用不同的途徑來進行開發,比如可以采用OpenCL或者DirectX這樣的API,也可以用C語言或者Fortran或者Java開發,最終都可以在CUDA架構上運行。
OpenCL與CUDA C語言的異同
前文已經說過,CUDA架構與OpenCL是包容關系,我們把他們放在同一級別進行討論本來就是錯誤的,與OpenCL在同一級別不是CUDA架構,而是CUDA的C語言包,也就是我們常說的CUDA版本,比如,CUDA 1.0、CUDA 2.0等等,下面來介紹一下OpenCL和CUDA C語言的一些異同。

對于編程人員來說可以選擇不同的開發環境來進行編程,例如我們可以選擇OpenCL編程也可以選擇CUDA上面的C語言來編程,或者API的語言來編程。API和C語言進行開發是有一些不同的,API是一個編程接口,它的核心是函數庫和應用程序開發的一個硬件接口,對于API來編程的話,好處在于可以訪問比較低層次的硬件,單弊端也是顯而易見的,那就是很多程序特別是像內存的管理,需要程序員自己來進行管理。而我們在利用CUDA C語言來編程的時候,底層的硬件管理是由CUDA開發包來進行管理,比如內存是用runtime進行管理(runtime實際上就是運行時的一些支持程序來進行底層硬件的管理),而不需要開發者考慮底層的硬件效率。不管OpenCL或者CUDA C語言來編程,最終都是需要通過一個驅動程序來變成一個PTX的代碼,PTX相當于CUDA的指令集來進行執行,然后交給圖形處理其或者交給CPU來進行執行。
也就是說,如果開發人員想獲得更多的對硬件上的控制權的話,可以使用API來進行編程,而如果類似科學家如果對API不是太了解,那么就可以用CUDA C語言來編程,這是兩種不同編程的方式,他們有他們相同點和不同點。OpenCL和CUDA C語言進行開發的時候,在并行計算上的概念很相似,在程序上是也有很大的相似度,所以程序之間的相互移植相對來說也比較容易。
當然我們也許會有疑問,那就是OpenCL看似更趨向于底層開發的API,那相對于CUDA C來說,OpenCL開發的程序執行效率會不會比CUDA C效率更高一些?實際上這個問題是不用擔心的,執行效率高不高,并不取決于采用的什么語言,什么樣的API,更大程度上取決于的代碼的優化程度!
不同編程模式解讀
下面我們來深入解讀一下CUDA與C語言編程模式的異同。對C語言進行編程的人員都知道,C語言使用驅動程序就是API,實際上是一種抽象,這個抽象主要是指和硬件相關的抽象。實際上CUDA C語言是一種C語言的擴展,這擴展的一部分主要是進行并行運算編程的方面,這些是通過C的擴展來獲得的。基本上認為CUDA的程序也是一種標準的C語言的程序,然后使用一些關鍵字然后來對并行這方面計算,最后做一些區分。C語言最終編譯會成為PTX的代碼,然后在GPU上執行。OpenCL是一個API,就是應用程序的編程接口,OpenCL和OpenGL很像,這種API可以調用API最底層的數據,通過程序開發調用各種各樣的函數,實現各種各樣的功能。對于API來說一般它對硬件設備有比較完整的訪問權,以訪問硬件的設備,可以對內存進行管理,這是由開發人員通過編程來做的這些事情。最后OpenCL通過編譯、通過驅動程序可以生成PTX代碼在GPU上進行執行。

編程人員要利用GPU的計算能力開發你的應用的時候,有兩種模式:如果你需要對硬件有更多的控制,可以通過OpenCL來編你的API和你的程序,那么它可以在CPU上運行;如果不需要底層的硬件管理,同時對硬件有控制權,而且又不太懂API這些程序,只要用C語言就可以編程了,或者CUDA C語言來編程,編完程序以后也可以在CPU的硬件上運行。
OpenCL和OpenGL在很多方面都很類似,他們也是一個共同的組織Khronos來進行管理的。對OpenGL圖形開發比較熟悉的人使用OpenCL計算這方面的開發,他們就會非常熟悉它里面所涉及的很多方面,這是OpenCL的一個非常明顯的特點。如果你對圖形編程很熟悉的話,就像是Computer shader,如果是多媒體等方面的應用,又想使用圖形又想使用GPU的來計算,用Computer shader的DX11編程,可能比較容易。但是對于大部分的科學家來說,可能對API,OpenCL可能完全不熟悉,他需要的就像在CPU上編程一樣,對CPU的計算編程,可以使用CUDA C語言,在CUDA C語言里面我們把CPU看成專門做計算的協處理器來進行編程,這是兩個之間不同的模式。
如果認為一種開發環境就可以取代其他的開發環境,這個是不現實的。舉個例子,在X86的架構上,除了C語言以外還有Java、Fortran還有Pascal語言,這些不可能互相取代的,每種語言、每種API都有它使用的人群。不同的語言、不同的API都會滿足不同人群的。GPU計算和API語言不是太多,目前還比較少,NVIDIA還會不斷地推出Java、Pascal或者C++也會支持。如果以前沒有Fortran,那些“老古董”程序員要讓他們學習C語言的話基本不可行,他們可能用Fortran用了幾十年,讓他們使用C語言開發的話他就比較痛苦,所以OpenCL與CUDA C語言并不存在誰將取代誰的問題。
CUDA與ATI Stream異同
我們知道,ATI方面也有自己的通用計算編程接口,叫做Stream。那么他與CUDA架構又有什么不同呢?
Stream基本上還是基于一種傳統CPU的一種方式,Stream主要包括CAL與Brook+。CAL是一套指令集,可以用匯編語言的方式來開發軟件,然而我們匯編方式開發軟件的話,對搞計算的人來說不大現實,讓他們用匯編語言來說的話可能確實是一個折磨。Brook+是斯坦福大學開發的,它是類似于C語言的東西,是把底層GPGPU的計算方式類似于C的這種語言,這里要說明的是Brook+不是C語言而是類C語言,語法和C語言比較類似,但內部做的還是使用頂點這樣的數據。

另外Stream的方式還有一個很大的問題,那就是主要是基于本地的板載內存存入數據,換算完成再寫到板載內存。這樣對GPU非常強大的計算能力來說,帶寬是一個非常大的障礙。例如每秒種進行1P的數字計算的話,需要多少的帶寬?32位浮點4個字節,如果是1P的話,我們把乘加這部分也計算在內就相當于再乘以2,至少需要每秒2P的吞吐量然后才能夠滿足,板載內存每秒需要幾十P。可見Stream的方式從效率上是一個比較低的計算,而對于開發者來說也會碰到很多的問題。
對于CUDA來說我們支持的C語言,是真正GPU上運行的C語言。C語言有一個很重要的特點,需要有存儲體系,而NVIDIA GPU在設計之初就考慮到了這點,內部有擁有share memory,編譯器會把大部分的數據盡可能的在share memory上進行計算。share memory帶寬非常高,因為它在芯片內部,速度接近于寄存器。數據在share memory上運行,然后再把這個數據再輸出,這樣的話真正地可以利用到絕大部分的GPU性能。
匯編語言的弊端
基于Stream來開發的應用軟件,我們知道的只有一個是folding@home,ATI比NVIDIA進入早兩年,但是NVIDIA進入以后使用CUDA的語言來寫folding@home客戶端的軟件,性能比ATI的GPU要高好幾倍。folding@home的一個版本可以運行在在上一代的架HD3(報價參數 圖片 評測)850或者HD3870的GPU上,但是HD4850和HD4870發布后,從浮點性能上來說計算能力比HD3850、HD3870要高2.5倍,但是folding@home的性能反而下降了?原來HD3870是200ns/day左右,每天可以模擬200萬秒的性能等級,但是HD4870發布后每天只能模擬170ns/day,這又是為什么?其原因是軟件不是使用Brook+開發的,而直接使用匯編的方式,這就需要對每一個新的GPU進行編程,每個架構都需要對它重新進行編程,然后才可以得到一個最好的效率,這就是說使用匯編方式的話會帶來一個非常大的問題,任何一個應用軟件里面都需要重新優化、重新編程。

匯編語言實際上就是機械碼來進行編程,屬于體力比較好、記憶也比較好的人才能勝任的工作。高級語言相對來說確實要簡單太多了,例如有些人甚至對編程都不是很熟悉,他只要基本上知道源代碼里面哪些代碼是在做什么東西,然后他就可以使用CUDA,核心部分計算部分一定要自己編寫,因為CUDA有很多現成的庫,都是直接寫好的函數,這個函數把原來的函數替代掉,就可以取得很好的性能。NVIDIA提供很多函數庫,這些函數庫有一些是NVIDIA公司開發的,像FFT、線性代數或者是快速傅里葉變換等,但是有一些庫是第三方幫NVIDIA開發的。CUDA實際上形成一個非常好的環境,不斷的有人針對CUDA來開發,不管是應用軟件或者是中間件,這些中間件的話就包含各種各樣的庫。
因此對于CUDA來說,與Stream相比幾乎現在沒什么可比性。對OpenCL、DirectX這樣應用在CUDA的架構上運行程序也比在Stream上運行程序好的多。因為NVIDIA在使用的CUDA架構實際上字開發的時候,就考慮到通用計算方面的應用。而ATI方面,可能通用計算僅僅是圖形的一個副產品。
OpenCL與CUDA C語言路線圖
目前OpenCL路線圖目前還是屬于Alpha版本。明年第一季度可能是Beta的版本,09年OpenCL1.0可能會正式推出,OpenCL最早會出現在Mac OS上,以后逐漸的擴展到其他的操作系統,像Windows或者Linux。

下面來介紹一下CUDA C語言的情況,NVIDIA一直還是不斷地對這個語言進行更深層次的開發,也不斷的有新版本的出現,到目前為止已經是CUDA 2.0。CUDA C語言研發已經超過5年時間,NVIDIA從03年左右就開始開發C語言。到目前為止,開發人員的數量已經是超過25000個,而且現在應用程序已經超過100個,特別是很多的科學計算的領域,幾乎涉及到各種各樣的HPC高性能計算的領域都有CUDA的身影出現,甚至現在HPC進入排行榜前100的高性能計算機里面也有使用NVIDIA的Tesla系統,GPU集群就是配置成高性能計算機的集群數量已經達到了30個,我國大陸也有采用。
CUDA C語言是一個跨操作系統的開發工具,現在支持Windows、Linux、Mac OS,幾乎最主流的操作系統都支持,SUN公司的Solaris系統也會支持。一些數學軟件像Matlab、Mathematica、LabView都有CUDA的插件,可以使用C語言的插件讓他更容易的利用CUDA。

上面是C語言的路線圖,目前的版本是CUDA 2.0,到今年年底CUDA 2.1會與我們見面,到明年會有2.2、2.3版本,到明年年底會到CUDA 3.0版本。隨著CUDA版本的升級,它的功能也在不斷地升級,比如最早的CUDA只能支持單精度的浮點計算,現在可以支持雙精度,可以支持各種各樣的庫,各種各樣的功能也是越來越多。
并行計算時代已經到來……
OpenCL的面世,不管對開發人員還是業界人員來說還是消費者來說都是一個非常好的API,它可以使得開發者很容易的開發出跨平臺的GPU計算的程序,充分利用GPU強大的計算能力然后應用在各種各樣計算的方面。 除了CUDA的架構上除了C語言以外,現在新增加了OpenCL或者DX11這樣的API,對于開發人員來說也提供了一種更多的GPU計算的開發環境的一種選擇。如果對API很熟悉的程序員,肯定會很高興的看到OpenCL或者新的API的加入,對于這些人來說他們很容易利用這種計算的API然后開發各種各樣GPU計算的程序。

NVIDIA也會繼續對C語言包括其他語言的支持,實對NVIDIA CUDA C語言來說目前還是唯一的針對GPU的runtime C的語言環境(runtime C的語言環境是指GPU直接執行這個C語言)。CUDA C語言還會進一步的發展,不斷會有新的版本推出。CUDA C語言會和OpenCL和DX11這種計算API會共存。

除了C語言以外NVIDIA還會推出更多的其他CUDA的語言,包括Fortran,還會有Java等。不管C語言還是Fortran,與OpenCL、Computer shader這種API是一種長期共存的關系。 GPU通用計算時代已經到來了,你已經準備好了嗎……
OpenCL和CUDA的使用比較
OpenCL和CUDA雖然不是同一個平級的東西,但是也可以橫向比較!
對OpenCL和CUDA的異同做比較:
- ??????? 指針遍歷
OpenCL不支持CUDA那樣的指針遍歷方式, 你只能用下標方式間接實現指針遍歷. 例子代碼如下:
// CUDA
struct Node { Node* next; }
n = n->next;
?// OpenCL
struct Node { unsigned int next; }
n = bufBase + n;
- Kernel 程序異同
CUDA的代碼最終編譯成顯卡上的二進制格式,最后由cudart.dll(個人猜測)裝載到GPU并且執行。OpenCL中運行時庫中包含編譯器,
使用偽代碼,程序運行時即時編譯和裝載。這個類似JAVA, .net 程序,道理也一樣,為了支持跨平臺的兼容。kernel程序的語法也
有略微不同,如下:
- __global__?void?vectorAdd(const?float?*?a,?const?float?*?b,?float?*?c)??
- {?//?CUDA??
- ????int?nIndex?=?blockIdx.x?*?blockDim.x?+?threadIdx.x;??
- ????c[nIndex]?=?a[nIndex]?+?b[nIndex];??
- }??
- __kernel?void?vectorAdd(__global?const?float?*?a,?__global?const?float?*?b,?__global?float?*?c)??
- {?//?OpenCL??
- ????int?nIndex?=?get_global_id(0);??
- ????c[nIndex]?=?a[nIndex]?+?b[nIndex];??
- }??
可以看出大部分都相同。只是細節有差異:
1)CUDA?的kernel函數使用“__global__”申明而OpenCL的kernel函數使用“__kernel”作為申明。
2)OpenCL的所有參數都有“__global”修飾符,代表這個參數所指地址是在全局內存。
3)眾所周知,CUDA采用threadIdx.{x|y|z}, blockIdx.{x|y|z}來獲得當前線程的索引號,而OpenCL
???? 通過一個特定的get_global_id()函數來獲得在kernel中的全局索引號。OpenCL中如果要獲得在當前工作
???? 組(對等于CUDA中的block)中的局部索引號,可以使用get_local_id()
- Host代碼的異同
把上面的kernel代碼編譯成“vectorAdd.cubin”,CUDA調用方法如下:
- const?unsigned?int?cnBlockSize?=?512;??
- const?unsigned?int?cnBlocks?=?3;??
- const?unsigned?int?cnDimension?=?cnBlocks?*?cnBlockSize;??
- CUdevice?hDevice;??
- CUcontext?hContext;??
- CUmodule?hModule;??
- CUfunction?hFunction;??
- //?create?CUDA?device?&?context??
- cuInit(0);??
- cuDeviceGet(&hContext,?0);?//?pick?first?device??
- cuCtxCreate(&hContext,?0,?hDevice));??
- cuModuleLoad(&hModule,?“vectorAdd.cubin”);??
- cuModuleGetFunction(&hFunction,?hModule,?"vectorAdd");??
- //?allocate?host?vectors??
- float?*?pA?=?new?float[cnDimension];??
- float?*?pB?=?new?float[cnDimension];??
- float?*?pC?=?new?float[cnDimension];??
- //?initialize?host?memory??
- randomInit(pA,?cnDimension);??
- randomInit(pB,?cnDimension);??
- //?allocate?memory?on?the?device??
- CUdeviceptr?pDeviceMemA,?pDeviceMemB,?pDeviceMemC;??
- cuMemAlloc(&pDeviceMemA,?cnDimension?*?sizeof(float));??
- cuMemAlloc(&pDeviceMemB,?cnDimension?*?sizeof(float));??
- cuMemAlloc(&pDeviceMemC,?cnDimension?*?sizeof(float));??
- //?copy?host?vectors?to?device??
- cuMemcpyHtoD(pDeviceMemA,?pA,?cnDimension?*?sizeof(float));??
- cuMemcpyHtoD(pDeviceMemB,?pB,?cnDimension?*?sizeof(float));??
- //?setup?parameter?values??
- cuFuncSetBlockShape(cuFunction,?cnBlockSize,?1,?1);??
- cuParamSeti(cuFunction,?0,?pDeviceMemA);??
- cuParamSeti(cuFunction,?4,?pDeviceMemB);??
- cuParamSeti(cuFunction,?8,?pDeviceMemC);??
- cuParamSetSize(cuFunction,?12);??
- //?execute?kernel??
- cuLaunchGrid(cuFunction,?cnBlocks,?1);??
- //?copy?the?result?from?device?back?to?host??
- cuMemcpyDtoH((void?*)?pC,?pDeviceMemC,?cnDimension?*?sizeof(float));??
- delete[]?pA;??
- delete[]?pB;??
- delete[]?pC;??
- cuMemFree(pDeviceMemA);??
- cuMemFree(pDeviceMemB);??
- cuMemFree(pDeviceMemC);??
OpenCL的代碼以文本方式存放在“sProgramSource”。 調用方式如下:
- const?unsigned?int?cnBlockSize?=?512;??
- const?unsigned?int?cnBlocks?=?3;??
- const?unsigned?int?cnDimension?=?cnBlocks?*?cnBlockSize;??
- //?create?OpenCL?device?&?context??
- cl_context?hContext;??
- hContext?=?clCreateContextFromType(0,?CL_DEVICE_TYPE_GPU,?0,?0,?0);??
- //?query?all?devices?available?to?the?context??
- size_t?nContextDescriptorSize;??
- clGetContextInfo(hContext,?CL_CONTEXT_DEVICES,?0,?0,?&nContextDescriptorSize);??
- cl_device_id?*?aDevices?=?malloc(nContextDescriptorSize);??
- clGetContextInfo(hContext,?CL_CONTEXT_DEVICES,?nContextDescriptorSize,?aDevices,?0);??
- //?create?a?command?queue?for?first?device?the?context?reported??
- cl_command_queue?hCmdQueue;??
- hCmdQueue?=?clCreateCommandQueue(hContext,?aDevices[0],?0,?0);??
- //?create?&?compile?program??
- cl_program?hProgram;??
- hProgram?=?clCreateProgramWithSource(hContext,?1,?sProgramSource,?0,?0);??
- clBuildProgram(hProgram,?0,?0,?0,?0,?0);//?create?kernel??
- cl_kernel?hKernel;??
- hKernel?=?clCreateKernel(hProgram,?“vectorAdd”,?0);??
- //?allocate?host?vectors??
- float?*?pA?=?new?float[cnDimension];??
- float?*?pB?=?new?float[cnDimension];??
- float?*?pC?=?new?float[cnDimension];??
- //?initialize?host?memory??
- randomInit(pA,?cnDimension);??
- randomInit(pB,?cnDimension);??
- //?allocate?device?memory??
- cl_mem?hDeviceMemA,?hDeviceMemB,?hDeviceMemC;??
- hDeviceMemA?=?clCreateBuffer(hContext,?CL_MEM_READ_ONLY?|?CL_MEM_COPY_HOST_PTR,?cnDimension?*?sizeof(cl_float),?pA,?0);??
- hDeviceMemB?=?clCreateBuffer(hContext,?CL_MEM_READ_ONLY?|?CL_MEM_COPY_HOST_PTR,?cnDimension?*?sizeof(cl_float),?pA,?0);??
- hDeviceMemC?=?clCreateBuffer(hContext,??
- CL_MEM_WRITE_ONLY,??
- cnDimension?*?sizeof(cl_float),?0,?0);??
- //?setup?parameter?values??
- clSetKernelArg(hKernel,?0,?sizeof(cl_mem),?(void?*)&hDeviceMemA);??
- clSetKernelArg(hKernel,?1,?sizeof(cl_mem),?(void?*)&hDeviceMemB);??
- clSetKernelArg(hKernel,?2,?sizeof(cl_mem),?(void?*)&hDeviceMemC);??
- //?execute?kernel??
- clEnqueueNDRangeKernel(hCmdQueue,?hKernel,?1,?0,?&cnDimension,?0,?0,?0,?0);??
- //?copy?results?from?device?back?to?host??
- clEnqueueReadBuffer(hContext,?hDeviceMemC,?CL_TRUE,?0,?cnDimension?*?sizeof(cl_float),??
- pC,?0,?0,?0);??
- delete[]?pA;??
- delete[]?pB;??
- delete[]?pC;??
- clReleaseMemObj(hDeviceMemA);??
- clReleaseMemObj(hDeviceMemB);??
- clReleaseMemObj(hDeviceMemC);??
- 初始化部分的異同?
CUDA 在使用任何API之前必須調用cuInit(0),然后是獲得當前系統的可用設備并獲得Context。
cuInit(0);
cuDeviceGet(&hContext, 0);
cuCtxCreate(&hContext, 0, hDevice));
OpenCL不用全局的初始化,直接指定設備獲得句柄就可以了
cl_context hContext;
hContext = clCreateContextFromType(0, CL_DEVICE_TYPE_GPU, 0, 0, 0);
設備創建完畢后,可以通過下面的方法獲得設備信息和上下文:
size_t nContextDescriptorSize;
clGetContextInfo(hContext, CL_CONTEXT_DEVICES, 0, 0, &nContextDescriptorSize);
cl_device_id * aDevices = malloc(nContextDescriptorSize);
clGetContextInfo(hContext, CL_CONTEXT_DEVICES, nContextDescriptorSize, aDevices, 0);
OpenCL introduces an additional concept: Command Queues. Commands launching kernels and
reading or writing memory are always issued for a specific command queue. A command queue is
created on a specific device in a context. The following code creates a command queue for the
device and context created so far:
cl_command_queue hCmdQueue;
hCmdQueue = clCreateCommandQueue(hContext, aDevices[0], 0, 0);
With this the program has progressed to the point where data can be uploaded to the device’s
memory and processed by launching compute kernels on the device.
- Kernel Creation
CUDA kernel 以二進制格式存放與CUBIN文件中間,其調用格式和DLL的用法比較類似,先裝載二進制庫,然后通過函數名查找
函數地址,最后用將函數裝載到GPU運行。示例代碼如下:
CUmodule hModule;
cuModuleLoad(&hModule, “vectorAdd.cubin”);
cuModuleGetFunction(&hFunction, hModule, "vectorAdd");
OpenCL 為了支持多平臺,所以不使用編譯后的代碼,采用類似JAVA的方式,裝載文本格式的代碼文件,然后即時編譯并運行。
需要注意的是,OpenCL也提供API訪問kernel的二進制程序,前提是這個kernel已經被編譯并且放在某個特定的緩存中了。
// 裝載代碼,即時編譯
cl_program hProgram;
hProgram = clCreateProgramWithSource(hContext, 1, “vectorAdd.c", 0, 0);
clBuildProgram(hProgram, 0, 0, 0, 0, 0);
// 獲得kernel函數句柄
cl_kernel hKernel;
hKernel = clCreateKernel(hProgram, “vectorAdd”, 0);
?
- 設備內存分配
內存分配沒有什么大區別,OpenCL提供兩組特殊的標志,CL_MEM_READ_ONLY? 和 CL_MEM_WRITE_ONLY 用來控制內存
的讀寫權限。另外一個標志比較有用:CL_MEM_COPY_HOST_PTR 表示這個內存在主機分配,但是GPU可以使用,運行時會自動
將主機內存內容拷貝到GPU,主機內存分配,設備內存分配,主機拷貝數據到設備,3個步驟一氣呵成。
// CUDA
CUdeviceptr pDeviceMemA, pDeviceMemB, pDeviceMemC;
cuMemAlloc(&pDeviceMemA, cnDimension * sizeof(float));
cuMemAlloc(&pDeviceMemB, cnDimension * sizeof(float));
cuMemAlloc(&pDeviceMemC, cnDimension * sizeof(float));
cuMemcpyHtoD(pDeviceMemA, pA, cnDimension * sizeof(float));
cuMemcpyHtoD(pDeviceMemB, pB, cnDimension * sizeof(float));
// OpenCL
hDeviceMemA = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
hDeviceMemB = clCreateBuffer(hContext, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, cnDimension * sizeof(cl_float), pA, 0);
hDeviceMemC = clCreateBuffer(hContext, CL_MEM_WRITE_ONLY, cnDimension * sizeof(cl_float), 0, 0);
- Kernel Parameter Specification
The next step in preparing the kernels for launch is to establish a mapping between the kernels’
parameters, essentially pointers to the three vectors A, B and C, to the three device memory regions,
which were allocated in the previous section.
Parameter setting in both APIs is a pretty low-level affair. It requires knowledge of the total number
, order, and types of a given kernel’s parameters. The order and types of the parameters are used to
determine a specific parameters offset inside the data block made up of all parameters. The offset in
bytes for the n-th parameter is essentially the sum of the sizes of all (n-1) preceding parameters.
Using the CUDA Driver API:
In CUDA device pointers are represented as unsigned int and the CUDA Driver API has a
dedicated method for setting that type. Here’s the code for setting the three parameters. Note how
the offset is incrementally computed as the sum of the previous parameters’ sizes.
cuParamSeti(cuFunction, 0, pDeviceMemA);
cuParamSeti(cuFunction, 4, pDeviceMemB);
cuParamSeti(cuFunction, 8, pDeviceMemC);
cuParamSetSize(cuFunction, 12);
Using OpenCL:
In OpenCL parameter setting is done via a single function that takes a pointer to the location of the
parameter to be set.
clSetKernelArg(hKernel, 0, sizeof(cl_mem), (void *)&hDeviceMemA);
clSetKernelArg(hKernel, 1, sizeof(cl_mem), (void *)&hDeviceMemB);
clSetKernelArg(hKernel, 2, sizeof(cl_mem), (void *)&hDeviceMemC);
攜手OPENCL CUDA架構能否成惟一領袖
如果你是蘋果的粉絲,你一定會結識一個新朋友——NVIDIA;如果你是NVIDIA的粉絲,那你一定欣喜自己與萬人迷“蘋果”走的更近。在今年10月24日,老喬津津有味的拿著一串數據來宣布旗下MacBook全系列產品以及今后相關眾多Mac產品將采用NVIDIA相關方案,蘋果的粉絲被教父的Keynote所打動,開始學習只有DIY發燒友才關注的一些技術名詞,他們在論壇里熱情高漲,討論著“HybridSLI”、“CUDA”、“PureVideo”等等。
| ||
| 視覺革命與計算革命 |

??? 蘋果與NVIDIA本月又聯手上演好戲,本月,蘋果又向大家宣布的OPENCL標準,它將在蘋果明年初推出的新一代操作系統Snow Leopard上開始支持,雖然我們看到支持的成員幾乎涵蓋了業內所有的知名企業,但大家應該清楚,在孕育OPENCL的過程中,能夠提供硬件平臺的只有NVIDIA,當然OPENCL標準工作組Khronos也首次將如此多的業內精英撮合到一起為了一個“并行計算”的新API。
|

??? 大家為什么要支持OPENCL?首先簡單了解一下OPENCL和異構系統?OPENCL英文全稱Open Computing Language,是基于異構系統并行編程的一個全新API,命名上雖然與OPENGL(Open Graphics Library)類似但方向上有很大不同,但開發上又存在一些聯系。在未來計算領域,異構系統已經被公認為發展趨勢,即CPU與平行處理器的異構形式,這也是未來Intel的發展方向。而我們目前能看到的能夠提供異構系統,并有成熟軟件平臺支持的僅有NVIDIA的CUDA架構。
??? 在OPENCL標準組織中,由于Intel和AMD的加入,讓大家對CUDA與OPENCL的關系產生很多疑問,本來已經成熟的CUDA平臺,為什么還需要一個新API的加入?Intel和AMD如何和OPENCL兼容?OPENCL和CUDA誰更好?這都是非常集中的問題。
??? 我們來看看Khronos OPENCL組織是如何組成的。我們知道,在OPENGL時期,該標準也是由Khronos這樣一個協調機構來運作的。而你會發現,這次OPENCL由蘋果作為代表發布,也正是蘋果選擇NVIDIA戰略中的重要一環,與其說OPENCL是蘋果發起的,還不如說是NVIDIA策劃的。而事實的確如此,NVIDIA副總裁Neil Trevett正是現在Khronos OPENCL工作的主席,OPENCL的標準的創立也是NVIDIA技術為基礎的,其中骨干員工也大半來自NVIDIA。其實這也不難理解,要做一個異構并行計算的系統和標準API,除了NVIDIA,你還能找誰呢?
|

??? 而下面這張圖也許是在此次OPENCL發布后較為常見的一個,不過其中意義大家不一定能夠完全領會,我們在這里做一個說明。這是一張能夠解釋大家對OPENCL與CUDA關系疑問的重要“結構”圖。NVIDIA第一次明確了兩個重要名詞“CUDA架構”與“CUDA C語言”。在以往理解中,我們常默認CUDA就是指基于NVIDIA GPU或并行處理器的編譯器、C語言、庫和相關軟件開發環境;而硬件方面,則是指所有支持CUDA的GPU。今天,NVIDIA明確了包括硬件支持和軟件環境一起,我們稱之為CUDA架構,而常用的基于C語言的開發環境則是CUDA C,或者CUDA Fortran,CUDA C++,以及今后的CUDA JAVA等等。而OPENCL,也與之并列。
|

??? 具體來說,NVIDIA將CUDA架構看作是一個異構計算中并行計算部分的核心,無論你使用怎樣的高級語言或者是怎樣的API的形式進行開發,在硬件上均符合CUDA架構(即NVIDIA GPU/并行處理器)。這有點類似于傳統CPU領域,無論你使用何種高級語言、匯編語言、API進行軟件開發,但是都為X86架構服務。
??? 解決了OPENCL與CUDA,確切的說是與CUDA C的爭論的問題,大家仍心存疑問。NVIDIA在初期宣傳CUDA C時,其優勢就在于高級語言對軟件開發的便利和普遍性,而OPENCL API級別的編程相對C語言來說又有什么優勢和必要?我們認為,此時NVIDIA宣傳CUDA與1年前初期階段已經有所不同,高級語言的支持是CUDA努力的主要方向,而如何全方位的吸引開發人員的加入,這對CUDA來說同樣重要。
| ||
| CUDA C擅長與服務的對象 |
| ||
| OPENCL的特點與服務對象 |

??? 我們從圖中看到,API和C語言在開發技術上有所不同,NVIDIA表示對原有OPENGL開發人員來說一定會喜歡OPENCL,因為其中有很多類似之處;同時,NVIDIA也表示,由于都是基于CUDA架構,所以OPENCL與CUDA C之間如果真需要遷移也是相對方便的(似乎沒有太大必要,總之都是基于同樣硬件架構的)。NVIDIA認為,目前對于并行計算而言,開發語言和API并不是太多,而是太少,未來DirectX11 Compute Shader同樣是基于CUDA架構的。
??? OPENCL的發布僅僅是一個開始,從路線圖來看要到2009年中,OPENC 1.0正式版才將發布,這個時間似乎要比蘋果Snow Leopard操作系統發布時間還稍晚些,但基于NVIDIA CUDA架構的OPENCL開發的軟件在新一代MacOS上有怎樣的表現,卻非常值得期待。
| ||
| OPENCL的發展藍圖 |

| ||
| CUDA C語言的路線圖 |
??? CUDA C語言路線圖則非常細致,但在這里NVIDIA沒有公布每個版本帶來的變化。但縱觀半年來CUDA2.0發布后的變化,在初期第三方和NVIDIA開發的一些算法已經被CUDA 2.0加入到庫中,例如FFT高速傅立葉變換,FIR濾波等等。對于需要這些數學計算的使用者來說,不需要懂得C語言、CUDA編程,只要替換庫中的相關語句和參數,便可以讓它的計算提速幾十倍。
??? OPENCL與CUDA的關系大家應該非常清楚了,但我們最為好奇的是,在中國市場一個看上去僅僅MacOS支持的API會得到如此大關注,這有些令人不能理解。雖然蘋果的IPOD和IPHONE在中國市場的歡迎程度相當高,但MacOS的占有率是相當低,即便MacBook的用戶也有大半人數和大半時間在使用著Windows操作系統,蘋果發布OPENCL,將在下一代操作系統Snow Leopard中使用,竟然有人關心這種邊緣新聞?
| ||
| 喬布斯為什么會喜歡NVIDIA? |

??? 經過前文一大串的講述,我們對OPENCL應該有了大概的了解。而我們的身份似乎不經意間變成了蘋果和NVIDIA的擁護者,大家主動的對OPENCL和CUDA提出各種各樣的問題,其熱情完全不亞于對待3G IPHONE和Macbook Air的發布上市,將對待品牌的熱情延續到技術品牌與技術本身,實在是一件神奇的事情。這不由讓我們想起了神奇的喬布斯,老喬。
??? 曾經有朋友評價,蘋果選擇NVIDIA非常符合老喬的性格,理由很簡單,老喬喜歡有個性的東西,同時也具有對未來敏銳的前瞻性,Macbook系列使用NVIDIA GPU產品,其實只是一個開始。而我更加同意另一個有趣的觀點,他們認為老喬這次是被NVIDIA 黃仁勛感動了,這也同樣很容易理解。當OPENCL在MacOS上得以應用,讓Macbook因此受益時,這才僅僅是NVIDIA CUDA架構與并行計算革命中的一部分,CUDA架構的作為不僅僅是OPENCL如此簡單,CUDA架構目前已經成為并行計算革命的惟一領導者。
從CUDA開始讀OpenCL
就像大一學C++,大二學匯編一樣,我也寫弄了些個月的CUDA,然后,想想,應該開始刨根問底地,去學點在CUDA之下層的東西,可能會對異構這個編程了解的多。
1 簡介
OpenCL全稱:開發計算語言,是并行程序的開發標準,使用與任何異構平臺——包括多CPU、GPU、CPU與GPU結合等。OpenCL由Khronos Group維護。
OpenCL是一個用于異構平臺上編程的開放性行業標準。這個平臺可以包括 CPU GPU和其他各類計算設備,例如 DSP和Cell/B.E.等等。
OpenCL和CUDA的關系很和諧,前者是異構編程規范標準,后者是英偉達基于OpenCL之上開發的一個更面向程序員的GPUAPI。所以,OpenCL適合于包括英偉達和AMD等的顯卡
程序開發。
2 認識OpenCL的框架
2.1 平臺模型
[1個host]-[1..N個device] (主機:host;設備:device)
[1個device]-[1..N個CU] (計算單元:CU)
[1個CU]-[1..N個PE] (處理單元:PU)
host端管理者整個平臺的所有計算資源,應用程序會從host端向各個 OpenCL設備的處理單元發送計算命令。在一個計算單元內的所有處理單元會執行完全相同的一套指令
流程。指令流可以是 SIMD模式或者SPMD模式。所有由OpenCL編寫的應用程序都是從Host啟動并結束,最終的計算都發生在PE中。
2.2 內存模型
內存介紹:
全局內存 (global memory):工作空間內所有的工作節點都可以讀寫此類內存中的任意元素。OpenCL C提供了緩存global buer的內建函數。
常量內存 (constant memory):工作空間內所有的工作節點可以只讀此類內存中的任意元素。 host負責分配和初始化 constant buer,在內核執行過程中保持不變。
局部內存 (local memory):從屬于一個工作組的內存,同一個工作組中所有的工作節點都可以共享使用該類內存。其實現既可以為 OpenCL執行為其分配一塊專有內存空間,
也有可能直接將其映射到一塊global buer上。
私有內存 (private memory):只從屬于當前的工作節點。一個工作節點內部的private buer其他節點是完全不可見的。
在這點上,基本上和CUDA介紹的內存是一樣的。這里的局部內存和CUDA的私有變量差不多一個概念。
內存使用:
在內存的使用上,有兩種方式:內存拷貝和內存映射。
拷貝數據是指host通過相應的OpenCL API將數據從host寫入到OpenCL設備的內存中或者從 OpenCL設備內存讀出數據到 host內存中。
內存映射方法允許用戶通過相應 OpenCLAPI將OpenCL的內存對象映射到 host端可見的內存地址空間中。映射之后用戶就可以在 host端的映
射地址讀寫該內存了,在讀寫完成之后用戶必須使用對應 API解除這種映射關系。同拷貝內存方式一樣,映射內存也分block和non-block模式。
2.3 執行模型
OpenCL的執行模型可以分為兩部分,一部分是在 host上執行的主程序(host program),另一部分是在 OpenCL設備上執行的內核程序(kernels),OpenCL通過主程序來
定義上下文并管理內核程序在OpenCL設備的執行。
執行模式最重要的是分配線程網絡,這點和CUDA是一回事,可以引用。
2.4 編程模型
OpenCL支持按數據并行的編程模型和按任務并行的編程模型。
數據并行模型是指同一系的列指令會作用在內存對象的不同元素上,即在不同內存元素上按這個指令序列定義了統一的運算。
在任務并行編程模型是指工作空間內的每個工作節點在執行 kernel程序時相對于其他節點是絕對獨立的。在這種模式下對每個工作節點都相當于工作在一個單一的計算單
元內,該單元內只有單一工作組,該工作組中只有該節點本身在執行。用戶可以通過如下方法實現按任務并行:
-使用OpenCL設備支持的向量類型數據結構
-同時執行或選擇性執行多個kernels
-在執行kernels同時交叉性執行一些native kernels程序
OpenCL提供了兩個領域的同步:
-在同一個工作組中所有的工作節點之間的同步
-同一個上下文中不同的 command queues之間和同一個 command queue的不同commands之間的同步
從CUDA了解openCL是在閱讀和理解相關CUDA編程知識后,在讀《OpenCL中文教程》的一個第一章和第二章的知識匯總,去掉了CUDA編程指南中講解的雷同知識。在了解和
明白OpenCL是怎么一回事兒后,我將開始openCL的Hello world了,雖然,僅僅一個helloword可能沒什么意義,但是,象征性的程序必須寫起來。
 是什么)





)

)









 - 4.28)
