文章來源: https://www.cnblogs.com/wangguchangqing/p/6297792.html?? , 寫的不錯,轉發出來。
2017年的第一篇博文。
本文主要有以下三部分內容:
- 介紹了Golomb編碼,及其兩個變種:Golomb-Rice和Exp-Golomb的基本原理
- C++實現了一個簡單的BitStream庫,能夠方便在bit流和byte數字之間進行轉換
- C++實現了Golomb-Rice和Exp-Golomb的編碼,并進行了測試。
在文章的最后提供了本文中的源代碼下載。
Golomb編碼的基本原理
Golomb編碼是一種無損的數據壓縮方法,由數學家Solomon W.Golomb在1960年代發明。Golomb編碼只能對非負整數進行編碼,符號表中的符號出現的概率符合幾何分布(Geometric Distribution)時,使用Golomb編碼可以取得最優效果,也就是說Golomb編碼比較適合小的數字比大的數字出現概率比較高的編碼。它使用較短的碼長編碼較小的數字,較長的碼長編碼較大的數字。
Golomb編碼是一種分組編碼,需要一個正整數參數m,然后以m為單位對待編碼的數字進行分組,如下圖:

對于任一待編碼的非負正整數N,Golomb編碼將其分為兩個部分:所在組的編號GroupID以及分組后余下的部分,GroupID實際是待編碼數字N和參數m的商,余下的部分則是其商的余數,具體計算如下:
?
q=N/mr=N%m
對于得到的組號q使用一元編碼(Unary code),余下部分r則使用固定長度的二進制編碼(binary encoding)。
一元編碼(Unary coding)是一種簡單的只能對非負整數進行編碼的方法,對于任意非負整數num,它的一元編碼就是num個1后面緊跟著一個0。例如:
| num | Unary coding |
|---|---|
| 0 | 0 |
| 1 | 10 |
| 2 | 110 |
| 3 | 1110 |
| 4 | 11110 |
| 5 | 111110 |
其編解碼的偽代碼如下:
UnaryEncode(n) {while (n > 0) {WriteBit(1);n--;}WriteBit(0);
}UnaryDecode() {n = 0;while (ReadBit(1) == 1) {n++;}return n;
}使用一元編碼編碼組號也就是商q后,對于余下的部分r則有根據編碼數字大小的不同有不同的處理方法。
- 如果參數m是2的次冪(這也是下面將要介紹的Golomb-Rice編碼),則使用取r的二進制表示的低log2(m)
- 位,作為r的碼字
- 如果參數m不是2的次冪,如果m不是2的次冪,設b=?log2(m)?
- 如果r<2b?m
- ,則使用b-1位的二進制編碼r。
- 如果r≧2b?m
- ,則使用b位二進制對r+2b?m
-
- 進行編碼
總結,設待編碼的非負整數為N,Golomb編碼流程如下:
- 初始化正整數參數m
- 取得組號q以及余下部分r,計算公式為:q=N/m,r=N%m
-
- ?
- 使用一元編碼的方式編碼q
- 使用二進制的方式編碼r,r所使用位數的如下:
- 如果參數m是2的次冪(這也是下面將要介紹的Golomb-Rice編碼),則使用取r的二進制表示的低log2(m)
- 位,作為r的碼字。
- 如果參數m不是2的次冪,如果m不是2的次冪,設b=?log2(m)?
- 如果r<2b?m
- ,則使用b-1位的二進制編碼r。
- 如果r≧2b?m
- ,則使用b位二進制對r+2b?m
-
-
- 進行編碼
-
說明:
- ?a?
-
- 大于a的最小整數 ceil運算
- ?a?
- 小于a的最大整數 floor運算
Golomb-Rice 編碼
Golomb-Rice是Golomb編碼的一個變種,它給Golomb編碼的參數m添加了個限制條件:m必須是2的次冪。這樣有兩個好處:
- 不需要做模運算即可得到余數r,
r = N & (m - 1) - 對余數r編碼更為簡單,只需要取r二進制的低log2(m)
- 位即可。
則Golomb-Rice的編碼過程更為簡潔:
- 初始化參數m,m必須為2的次冪
- 計算q和r,
q = N / m ; r = N & (m - 1) - 使用一元編碼編碼q
- 取r的二進制位的低log2(m)
- 位作為r的碼字。
解碼過程如下:
bool b;
uint64_t unary = 0;
b = bitStream.getBit();
while (b)
{unary++;b = bitStream.getBit();
}std::bitset<64> bits;
bits.reset();
for (int i = 0; i < k; i++)
{b = bitStream.getBit();bits.set(i, b);
}N = unary * m + bits.to_ulong();Exponential Golomb 指數哥倫布編碼
Rice的編碼方式和Golomb的方法是大同小異的,只是選擇m必須為2的次冪。而Exp-Golomb則有了一個很大的改進,不再使用固定大小的分組,而使組的大小呈指數增長。如下圖:

Exp-Golomb的碼元結構是:** [M zeros prefix] [1] [Offset] **,其中M是分組的編號GroupID,1可以看著是分隔符,Offset是組內的偏移量。
Exp-Golomb需要一個非負整數K作為參數,稱之為K階Exp-Golomb。其中當K = 0時,稱為0階Exp-Golomb,目前比較流行的H.264視頻編碼標準中使用的就是0階的Exp-Golomb,并且可以將任意的階數K轉為0階Exp-Golomb編碼。
首先來看下0階Exp-Golomb編碼,如下圖:
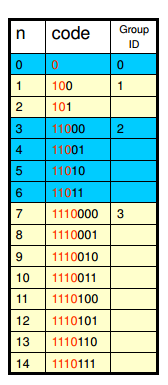
上圖是0階Exp-Golomb編碼的前幾個組的分組情況,可以看出編號為m的組,其組內的最小元素的值是2m?1
,也就是說對于非負整數N,其在編號為m的組內的充要條件是:2m?1≤N≤2m+1?1。所以可以由如下公式計算得到組號m以及組內的偏移量Offset
m=?log2(num+1)?Offset=num+1?2m
有了組號以及組內的偏移量后,其編碼就比較簡單了,具體過程如下:
- 首先使用公式計算組號m,m=?log2(num+1)?
- ?
- 對組號m進行編碼,連續寫入m個0,最后寫入一個1作為結束。
- 計算組內偏移量offset,Offset=num+1?2m
- ?
- 取offset二進制形式的低m位作為offset碼元
0階Exp-Golomb的編碼后的長度是:2?m+1
,其解碼過程和上面的Rice碼類似,讀入bit流,是0則繼續,1則停止,然后統計0的個數m;接著讀入m位的bit,就是offset,最后解碼后的數值是:N=2m?1+offset
。
k階Exp-Golomb
前面提到任意的k階Exp-Golomb可以轉換為0階Exp-Golomb進行求解,這是為何呢。Exp-Golomb的組的大小實際上是呈2的指數增長,不同的參數k,實際控制的是起始分組的大小,具體是什么意思呢。
- k = 0,其組的大小為1,2,4,8,16,32,...
- k = 1,其組的大小為2,4,8,16,32,64,...
- k = 2,其組的大小為4,8,16,32,64,...
- ...
- k = n,其組的大小為2n,2n+1,?
- ?
不同的k造成了其起始分組的大小不同,所以對于任意的k階Exp-Golomb編碼都可以轉化為0階,具體如下:
設待編碼數字為N,參數為k
- 使用0階Exp-Golomb編碼 N+2k?1
- ?
- 從第一步的結果中刪除掉高位的k個0
以上的算法描述來自: https://en.wikipedia.org/wiki/Exponential-Golomb_coding
在搜索得到中文資料中,對于K階Exp-Golomb的算法描述大多如下:
- 將num以二進制的形式表示(若不足k位,則在高位補0),去掉其低k位(若剛好是k位,則為0)得到數字n
- 計算n + 1的最低有效位數lsb,則M = lsb - 1。就是prefix中0的個數
- 將第1步中去掉的k位二進制串放到(n + 1)的低位,得到[1][INFO]
其實現以及描述都不如wikipedia,故在下面的實現部分使用的是Wikipedia的方法。
在資料搜集的過程中,對于Exp-Golomb算法描述不止上述的兩種,還有其他的形式,但都是殊途同歸,也許得到的編碼是不一樣的,但是其編碼的長度卻是一樣的,也就沒有過多的計較。
最后附上k = 0,1,2,3時前29個數字的編碼:
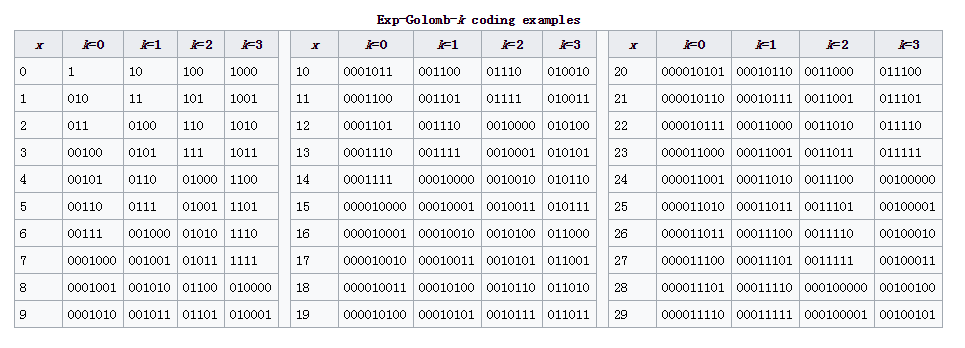
注意1之前的0的個數就是該數字所在的組的編號,同一組內的編碼長度是相同的。
實現
通過上面的描述可以發現,Golomb編碼的實現是很簡單的,唯一的難點在于bit的操作。編碼過程是將對bit進行操作,然后拼湊為byte,寫入buffer;解碼則是相反的過程,讀取byte轉化為bit stream,操作一個個的bit。具體來說就是以下兩個功能:
- 將bit流轉換為byte數組
- 將byte數組轉換為bit流
而在C/C++中最小的數據類型也是8位的byte,這就造成了對bit的進行操作有一定的難度,好在C++中std::bitset結構能夠在一定成都上簡化對bit的操作。
BitBuffer / ByteBuffer
首先實現一個底層的庫,實現bit流和byte之間的轉換。在Golomb編碼中,對bit和byte的操作只需要簡單的get/put操作,因此封裝了兩個結構體BitBuffer和ByteBuffer,具體的聲明如下:
//
//
// Bits buffer
// 將bytes轉化為bit stream時,在該buffer中緩存待處理的bit
//
/
struct BitBuffer
{std::bitset<bit_length> data; // 使用bitset緩存bitint pos; // 當前bit的指針int count;// bitset中bit的個數// 構造函數BitBuffer();// 從bitset中取出一個bitbool getBit();// 從bitset中取出一個byteuint8_t getByte();// 向bitset中寫入一個bitvoid putBit(bool b);// 向bitset中寫入一個bytevoid putByte(uint8_t b);
};//
// Bytes buffer
//
///
struct ByteBuffer
{uint8_t *data; // Byte數據指針uint64_t pos; // 當期byte的指針uint64_t length; // 數據長度uint64_t totalLength; // 總的放入到 byte buffer中的字節數// 構造函數ByteBuffer();// 取出一個byteuint8_t getByte();// 寫入一個bytevoid putByte(uint8_t b);// 設置byte數組void setData(uint8_t *buffer, int len);
};BitBuffer是一個bit的緩存,無論是將bit流轉換為byte還是將byte轉換為bit流,都將bit放在此結構體中進行緩存。ByteBuffer用來管理byte數組的緩存
這兩個結構體中只向上層提供簡單的get/put方法,不做任何的邏輯判斷。也就是說只要調用了get方法就一定會有數據返回,調用了put方法就一定有空間存放數據。
BitStream
在編碼時,需要將得到的bit流以byte的形式寫出;解碼則是將byte數組以bit流的形式讀入。這就需要兩種類型的bitstream:BitOutputStream和BitInputStream,其聲明如下:
//
// Bit Output Stream
// 將bit stream轉化為byte數組
// 這里也只提供功能,至于byte緩存滿的處理放到編碼器中處理
//class BitOutputStream
{;
public:// 寫入一個bitvoid putBit(bool b);// 寫入多個相同的bitvoid putBit(bool b, int num);// 設置數據數組void setBuffer(uint8_t *buffer, int len);void resetBuffer();/*判斷byte buffer中是可用的bit長度*/uint64_t freeLength();// Flush bit buffer to byte bufferbool flush();uint64_t getTotalCodeLength(){return bytes.pos;}private:BitBuffer bits;ByteBuffer bytes;
};class BitInputStream
{
public:// 讀取一個bitbool getBit();// 設置byte buffervoid setBuffer(uint8_t *buffer, int len);BufferState check();private:BitBuffer bits;ByteBuffer bytes;
};編碼時需要BitOutputStream將bit流轉換為byte數組,也就是個putBit的過程,需要注意的一點是在編碼結束的時候需要調用方法flush,該函數有兩個功能:
- 將BitBuffer中緩存的bit刷新到byte數組中
- 寫入編碼的編碼終止符。編碼終止符在解碼過程中是一個很重要的判斷標志,這里假定Golomb編碼后碼元的最大長度為64位,所以可設編碼終止符為:連續64bits的0。在解碼時,要判斷接下來的是不是編碼終止符。
- 將編碼后輸出的字節數填充為8(8 bytes,64 bits)的倍數,在解碼時以8 bytes為單位進行解碼,并且每次判斷是不是編碼終止符時也需要至少8 bytes。
編碼/解碼
有了BitStream的支持后,編解碼過程是很簡單的。
編碼
每次編碼前,首先計算編碼后碼元的長度,如果byte緩存空間不足以存放整個碼元,則將byte buffer填充滿后,剩余的部分,在bitset中緩存。返回false,指出緩存已滿,需要處理緩存中的數據后才能繼續編碼或者更換一個新的Byte buffer存放編碼后的數據.
bool GolombEncoder::encode(uint64_t num)
{uint64_t q = num >> k;uint64_t r = num & (m - 1);auto len = q + 1 + k; // 編碼后碼元的長度/*不會判斷緩存是否為滿,直接向里面放,不足的話緩存到bit buffer中*/bitStream.putBit(1, q);bitStream.putBit(0);for (int i = 0; i < k; i++){bitStream.putBit(static_cast<bool>(r & 0x01));r >>= 1;}return bitStream.freeLength() >= len; // 空間足夠,存放編碼后的碼元則返回true;否則返回false
}上述代碼以Golomb-Rice編碼為例。在putBit時候的不會判斷緩存是否夠用,直接存放,如果Byte Buffer不足以存放本次編碼的bits,則將Byte Buferr填充滿后,余下的bits在BitBuffer中緩存,然后返回false,告訴調用者byte buffer已經填滿,可以處理當前buffer的數據后調用resetBuffer后繼續編碼;也可以直接更換一個新的byte buffer。
解碼
在每次解碼前,先要調用check方法來判斷byte buffer的狀態,byte buffer中有以下幾種狀態
- 空,數據已讀取完
- 編碼終止符,buffer中的數據是編碼終止符,解碼結束
- 數據不足,buffer中的數據不足以完成本次解碼,需要讀取新的buffer
- 數據足夠,繼續解碼
check的實現如下:
enum BufferState
{BUFFER_EMPTY, // buffer emptyBUFFER_END_SYMBOL, // end_symbol 編碼的中止符,已經沒有編碼的數據BUFFER_LACK, // buffer數據不足以完成解碼,需要新的bufferBUFFER_ENGOUGH // 數據足夠,繼續解碼
};// 檢測buffer的狀態
// 在每次解碼開始前調用
BufferState BitInputStream::check()
{// buffer中已無數據if (bits.count <= 0 && bytes.pos >= bytes.length)return BufferState::BUFFER_EMPTY;// buffer中還有數據,分為兩種情況:不足64bits和有64bitsauto count = (bytes.length - bytes.pos) * 8 + bits.count;// buffer中的數據足夠64位if (count >= 64){// bit buffer中數據就有64bitsif (bits.count >= 64){if (bits.data.none()) // 64 bits 0return BufferState::BUFFER_END_SYMBOL; // 編碼中止符elsereturn BufferState::BUFFER_ENGOUGH; // 數據足夠繼續解碼}// bit buffer中的數據不足64bitelse{if (!bits.data.none())return BufferState::BUFFER_ENGOUGH;int count = ((64 - bits.count) / 8 + 1);int index = 0;while (index < count){auto b = bytes.data[bytes.pos + index];index++;if (b != 0)return BufferState::BUFFER_ENGOUGH;}return BUFFER_END_SYMBOL;}}// buffer中數據不足64位,不進行解碼,// 將byte buffer中的數據取出放在bit buffer后,返回BUFFER_LACKelse{while (bytes.pos < bytes.length){auto b = bytes.getByte();bits.putByte(b);}return BufferState::BUFFER_LACK;}
}check的過程有些復雜,但代碼中的注釋已足夠清晰,這里就不再詳述了。
Golomb-Rice的解碼過程如下:
/
//
// 解碼
// 在每次解碼前需要check buffer的狀態,根據不同的狀態決定解碼是否繼續
//
///
BufferState GolombDecoder::decode(uint64_t& num)
{auto state = bitStream.check();// buffer中數據足夠,進行解碼if (state == BufferState::BUFFER_ENGOUGH){bool b;uint64_t unary = 0;b = bitStream.getBit();while (b){unary++;b = bitStream.getBit();}std::bitset<64> bits;bits.reset();for (int i = 0; i < k; i++){b = bitStream.getBit();bits.set(i, b);}num = unary * m + bits.to_ulong();}return state;
}解碼完成后會返回當前byte buffer的狀態,
- 狀態是
BUFFER_END_SYMBOL,則解碼過程已經完成 - 狀態是
BUFFER_EMPTY,byte buffer沒有設置 - 狀態是
BUFFER_LACK,byte buffer中的數據不足以完成一次解碼,需要讀入新的數據 - 狀態是
BUFFER_ENGOUGH,byte buffer中的數據足夠,繼續下一次的解碼
測試
仍然以Golomb-Rice編碼為例,測試代碼如下
GolombEncoder encoder(m);encoder.setBuffer(buffer, 1024);ofstream ofs;ofs.open("golomb.gl", ios::binary);for (int i = 0; i < length; i++){auto b = encoder.encode(nums[i]);if (!b){cout << "Lack of buffer space,write the data to file" << endl;cout << "reset buffer" << endl;ofs.write((const char*)buffer, encoder.getToalCodeLength());encoder.resetBuffer();break;}}encoder.close();ofs.write((const char*)buffer, encoder.getToalCodeLength());ofs.close();cout << "Golomb finished coding" << endl;- 實例編碼器時,需要設定編碼的參數m和以及存放編碼后數據的buffer;
- 編碼時,判斷編碼的的返回值,如果為true則繼續編碼,為false則buffer已滿,將buffer寫入文件后,
resetBuffer繼續編碼。 - 編碼結束后,調用
close方法,寫入編碼終止符,并將整個編碼后的數據填充為8的倍數。
下面代碼Golomb-Rice的解碼調用過程
ifstream ifs;ifs.open("golomb.gl", ios::binary);memset(buffer, 0, 1024);ifs.read((char*)buffer, 664);ofstream encodeOfs;encodeOfs.open("encode.txt");GolombDecoder decoder(m);decoder.setBuffer(buffer, 1024);uint64_t num;auto state = decoder.decode(num);int index = 0;while (state != BufferState::BUFFER_END_SYMBOL){encodeOfs << num << endl;state = decoder.decode(num);index++;}ifs.close();encodeOfs.close();cout << "decode finished" << endl;編碼是也需要根據返回的狀態,來處理byte buffer,在上面已詳述。
總結
終于完成了這篇博文,本文主要對Golomb編碼進行了一個比較詳盡的描述,包括Golomb編碼的兩個變種:Golomb-Rice和Exp-Golomb。在編碼實現部分,難點有三個:
- byte數組和bit流之間的轉換
- 需要一個唯一的編碼終止符
- 解碼時,byte buffer中剩余數據不足以完成一次解碼
針對上述問題,做了如下工作:
- 實現了一個簡單的BitStream庫,能夠方便在bit流和byte數組之間進行轉換
- 對編碼后的碼元長度做了一個假設,其最長長度不會超過64位,這樣就使用64比特的0作為編碼的終止符
- 在編碼的時,會將編碼后的總字節數填充為8的倍數,解碼的過程中就以8字節為單位進行,當byte buffer中的數據不足8字節時,可以判定當前buffer中的數據并不是全部的數據,需要繼續讀入數據已完成解碼
本文所使用的源代碼,
- Github https://github.com/brookicv/GolombCode
- CSDN http://download.csdn.net/detail/brookicv/9740838
2017年的第一篇博文,完。










-----實操排雷)







整理時間線)
