原文鏈接
?請你來說一下一個C++源文件從文本到可執行文件經歷的過程?
- 對于C++源文件,從文本到可執行文件一般需要四個過程:
- 預處理階段:對源代碼文件中文件包含關系(頭文件)、預編譯語句(宏定義)進行分析和替換,生成預編譯文件。
- 編譯階段:將經過預處理后的預編譯文件轉換成特定匯編代碼,生成匯編文件
- 匯編階段:將編譯階段生成的匯編文件轉化成機器碼,生成可重定位目標文件
- 鏈接階段:將多個目標文件及所需要的庫連接成最終的可執行目標文件
?請你來回答一下include頭文件的順序以及雙引號””和尖括號<>的區別?
- Include頭文件的順序:對于include的頭文件來說,如果在文件a.h中聲明一個在文件b.h中定義的變量,而不引用b.h。那么要在a.c文件中引用b.h文件,并且要先引用b.h,后引用a.h,否則會報變量類型未聲明錯誤。
- 雙引號和尖括號的區別:編譯器預處理階段查找頭文件的路徑不一樣。
- 對于使用雙引號包含的頭文件,查找頭文件路徑的順序為:1,當前頭文件目錄;2,編譯器設置的頭文件路徑(編譯器可使用-I顯式指定搜索路徑);3,系統變量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的頭文件路徑
- 對于使用尖括號包含的頭文件,查找頭文件的路徑順序為:1,編譯器設置的頭文件路徑(編譯器可使用-I顯式指定搜索路徑);2,系統變量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的頭文件路徑
請你回答一下malloc的原理,另外brk系統調用和mmap系統調用的作用分別是什么?
- malloc函數用于動態分配內存。為了減少內存碎片和系統調用的開銷,malloc其采用內存池的方式,先申請大塊內存作為堆區,然后將堆區分為多個內存塊,以塊作為內存管理的基本單位。當用戶申請內存時,直接從堆區分配一塊合適的空閑塊。malloc采用隱式鏈表結構將堆區分成連續的、大小不一的塊,包含已分配塊和未分配塊;同時malloc采用顯示鏈表結構來管理所有的空閑塊,即使用一個雙向鏈表將空閑塊連接起來,每一個空閑塊記錄了一個連續的、未分配的地址。
- 當進行內存分配時,malloc會通過隱式鏈表遍歷所有的空閑塊,選擇滿足要求的塊進行分配;
- 當進行內存合并時,malloc采用邊界標記法,根據每個塊的前后塊是否已經分配來決定是否進行塊合并。? ?操作系統? 文件管理
- malloc在申請內存時,一般會通過brk或者mmap系統調用進行申請。其中當申請內存小于128K時,會使用系統函數brk在堆區中分配;而當申請內存大于128K時,會使用系統函數mmap在映射區分配。
補充
- 下面示例中,字符數組a的容量是6個字符,其內容為hello。a的內容可以改變,如a[0]=?‘X’。指針p指向常量字符串“world”(位于靜態存儲區,內容為world),常量字符串的內容是不可以被修改的。從語法上看,編譯器并不覺得語句p[0]=?‘X’有什么不妥,但是該語句企圖修改常量字符串的內容而導致運行錯誤。
char a[] = “hello”;
a[0] = ‘X’;
cout << a << endl;
char *p = “world”; // 注意p指向常量字符串
p[0] = ‘X’; // 編譯器不能發現該錯誤
cout << p << endl;
- ?操作系統--brk()和mmap()詳解
- 認真分析mmap:是什么 為什么 怎么用
- 從內核文件系統看文件讀寫過程
參考鏈接
- C++---之動態內存申請new
- C/C++內存申請和釋放(二)
- C++內存管理(超長,例子很詳細,排版很好)
- c++四種分配內存的方法整理
- C/C++內存申請和釋放(一)
- 操作系統--brk()和mmap()詳解
?請你說一說C++的內存管理是怎樣的?
- 在C++中,虛擬內存分為代碼段、數據段、BSS段、堆區、文件映射區、棧區六部分。
- 代碼段:? ?包括只讀存儲區和文本區,其中只讀存儲區存儲字符串常量,文本區存儲程序的機器代碼。
- 數據段:存儲程序中已初始化的全局變量和靜態變量
- bss 段: 存儲未初始化的全局變量和靜態變量(局部+全局),以及所有被初始化為0的全局變量和靜態變量。
- 堆區:調用new/malloc函數時在堆區動態分配內存,同時需要調用delete/free來手動釋放申請的內存。
- 映射區:? 存儲動態鏈接庫以及調用mmap函數進行的文件映射
- 棧:使用棧空間存儲函數的返回地址、參數、局部變量、返回值
請你來說一下C++/C的內存分配
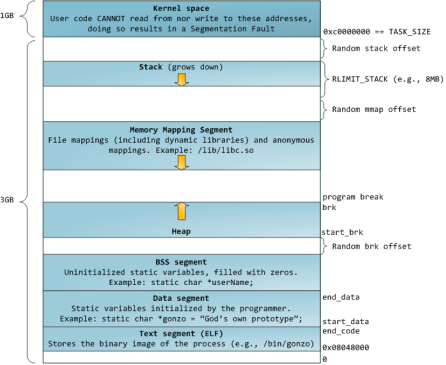
- 32bitCPU可尋址4G線性空間,每個進程都有各自獨立的4G邏輯地址,其中0~3G是用戶態空間,3~4G是內核空間,不同進程相同的邏輯地址會映射到不同的物理地址中。
- 其邏輯地址其劃分如下:
- 各個段說明如下:
- 3G用戶空間和1G內核空間
靜態區域:
- text segment(代碼段):包括只讀存儲區和文本區,其中只讀存儲區存儲字符串常量,文本區存儲程序的機器代碼。
- data segment(數據段):存儲程序中已初始化的全局變量和靜態變量
- bss segment:存儲未初始化的全局變量和靜態變量(局部+全局),以及所有被初始化為0的全局變量和靜態變量,對于未初始化的全局變量和靜態變量,程序運行main之前時會統一清零。即未初始化的全局變量編譯器會初始化為0
動態區域:
- heap(堆): 當進程未調用malloc時是沒有堆段的,只有調用malloc時采用分配一個堆,并且在程序運行過程中可以動態增加堆大小(移動break指針),從低地址向高地址增長。分配小內存時使用該區域。 ?堆的起始地址由mm_struct 結構體中的start_brk標識,結束地址由brk標識。
- memory mapping segment(映射區):存儲動態鏈接庫等文件映射、申請大內存(malloc時調用mmap函數)
- stack(棧):使用棧空間存儲函數的返回地址、參數、局部變量、返回值,從高地址向低地址增長。在創建進程時會有一個最大棧大小,Linux可以通過ulimit命令指定。
補充知識
- 在終端輸入wmic memphysical get maxcapacity,將其結果除以1024 再除以1024 (兩次),得到的結果就是電腦可以支持的最大內存
參考鏈接
?請你回答一下如何判斷內存泄漏?
- 原因:內存泄漏通常是由于調用了malloc/new等內存申請的操作,但是缺少了對應的free/delete。
- 內存泄漏(memory leak)是指由于疏忽或錯誤造成了程序未能釋放掉不再使用的內存情況。內存泄漏并非指內存在物理上的消失,而是應用程序分配某段內存后,由于設計錯誤,失去了對該段內存的控制,因而造成了內存的浪費。
內存泄漏的分類:
- 堆內存泄漏 (Heap leak)。對內存指的是程序運行中根據需要分配通過malloc,realloc new等從堆中分配的一塊內存,再是完成后必須通過調用對應的 free或者delete 刪掉。如果程序的設計的錯誤導致這部分內存沒有被釋放,那么此后這塊內存將不會被使用,就會產生Heap Leak.
- 系統資源泄露(Resource Leak)。主要指程序使用系統分配的資源比如 Bitmap,handle ,SOCKET等沒有使用相應的函數釋放掉,導致系統資源的浪費,嚴重可導致系統效能降低,系統運行不穩定。
- 沒有將基類的析構函數定義為虛函數。當基類指針指向子類對象時,如果基類的析構函數不是virtual,那么子類的析構函數將不會被調用,子類的資源沒有正確是釋放,因此造成內存泄露。
解決辦法:
- 1,為了判斷內存是否泄露,我們一方面可以使用linux環境下的內存泄漏檢查工具Valgrind
- 2,另一方面我們在寫代碼時可以添加內存申請和釋放的統計功能,統計當前申請和釋放的內存是否一致,以此來判斷內存是否泄露
- 3,使用mtrace來判斷內存是否泄漏
參考鏈接:
- 使用 Valgrind 檢測 C++ 內存泄漏
- Linux 性能分析valgrind(一)之memcheck使用
- bitmap
- 句柄是什么?
- C 什么是句柄?為什么會有句柄?HANDLE
- GCC編譯過程(預處理->編譯->匯編->鏈接)
- C/C++內存申請和釋放(一)
- C 庫函數 - fprintf()
- int main(int argc,char* argv[])詳解
- mtrace檢查內存泄露
- 聊聊同步、異步、阻塞與非阻塞
請你來說一下什么時候會發生段錯誤?Segmentation fault (core dumped)
- 段錯誤:段錯誤是指訪問的內存超出了系統給這個程序所設定的內存空間,例如訪問了不存在的內存地址、訪問了系統保護的內存地址、訪問了只讀的內存地址等等情況
- 段錯誤通常發生在訪問非法內存地址的時候,具體來說分為以下幾種情況:
- 使用野指針
- 試圖修改字符串常量的內容
補充知識
- ?gdb ./main_c 使用gdb調試程序
- (gdb) l? 查看程序源碼
- (gdb) b 8? 在程序第8行設置斷點
- (gdb) p i? 打印變量i的相關信息
- (gdb) r 程序運行,運行至斷點處
- (gdb) n 程序繼續執行
- (gdb) quit 退出程序
- man 7 signal | grep SEGV 查看對應的? Segmentation fault 錯誤信息
參考鏈接
- C/C++中的段錯誤(Segmentation fault)[轉]
- Linux dmesg命令介紹
- Linux環境下段錯誤的產生原因及調試方法小結
- C語言段錯誤調試
請你來回答一下什么是memory leak,也就是內存泄漏
- 內存泄漏(memory leak)是指由于疏忽或錯誤造成了程序未能釋放掉不再使用的內存的情況。內存泄漏并非指內存在物理上的消失,而是應用程序分配某段內存后,由于設計錯誤,失去了對該段內存的控制,因而造成了內存的浪費。
內存泄漏的分類:
- 1. 堆內存泄漏 (Heap leak)。對內存指的是程序運行中根據需要分配通過malloc,realloc new等從堆中分配的一塊內存,再是完成后必須通過調用對應的 free或者delete 刪掉。如果程序的設計的錯誤導致這部分內存沒有被釋放,那么此后這塊內存將不會被使用,就會產生Heap Leak.
- 2. 系統資源泄露(Resource Leak)。主要指程序使用系統分配的資源比如 Bitmap,handle ,SOCKET等沒有使用相應的函數釋放掉,導致系統資源的浪費,嚴重可導致系統效能降低,系統運行不穩定。
- 3. 沒有將基類的析構函數定義為虛函數。當基類指針指向子類對象時,如果基類的析構函數不是virtual,那么子類的析構函數將不會被調用,子類的資源沒有正確是釋放,因此造成內存泄露。(這個問題尤其體現在使用數組,每個數組的下標對應一個新分配的對象,需要子類使用 delete【 】 來刪除每一個對象分配的空間。如果,不對父類函數進行重載,使用父類的析構函數,會導致僅僅釋放一個資源)
請你來回答一下new和malloc的區別
- 1、new分配內存按照數據類型進行分配,malloc分配內存按照指定的大小分配;
- 2、new返回的是指定對象的指針,而malloc返回的是void*,因此malloc的返回值一般都需要進行類型轉化。
- 3、new不僅分配一段內存,而且會調用構造函數,malloc不會。
- 4、new分配的內存要用delete銷毀,malloc要用free來銷毀;delete銷毀的時候會調用對象的析構函數,而free則不會。
- 5、new是一個操作符可以重載,malloc是一個庫函數。
- 6、malloc分配的內存不夠的時候,可以用realloc擴容。new沒用這樣操作。
- 7、new如果分配失敗了會拋出bad_malloc的異常,而malloc失敗了會返回NULL。
- 8、申請數組時:?new[]一次分配所有內存,多次調用構造函數,搭配使用delete[],delete[]多次調用析構函數,銷毀數組中的每個對象。而malloc則只能sizeof(int) * n
?請你來說一下共享內存相關api
- Linux允許不同進程訪問同一個邏輯內存,提供了一組API,頭文件在sys/shm.h中。
參考鏈接
- Linux進程間通信(六):共享內存 shmget()、shmat()、shmdt()、shmctl()
1)新建共享內存shmget
- int shmget(key_t key,size_t size,int shmflg);
- key:共享內存鍵值,可以理解為共享內存的唯一性標記。
- size:共享內存大小
- shmflag:創建進程和其他進程的讀寫權限標識。
- 返回值:相應的共享內存標識符,失敗返回-1
2)連接共享內存到當前進程的地址空間shmat
- void *shmat(int shm_id,const void *shm_addr,int shmflg);
- shm_id:共享內存標識符
- shm_addr:指定共享內存連接到當前進程的地址,通常為0,表示由系統來選擇。
- shmflg:標志位
- 返回值:指向共享內存第一個字節的指針,失敗返回-1
3)當前進程分離共享內存shmdt
- int shmdt(const void *shmaddr);
4)控制共享內存shmctl
- 和信號量的semctl函數類似,控制共享內存
- int shmctl(int shm_id,int command,struct shmid_ds *buf);
- shm_id:共享內存標識符
- command: 有三個值
- IPC_STAT:獲取共享內存的狀態,把共享內存的shmid_ds結構復制到buf中。
- IPC_SET:設置共享內存的狀態,把buf復制到共享內存的shmid_ds結構。
- IPC_RMID:刪除共享內存
- buf:共享內存管理結構體。
請你來說一下reactor模型組成
- reactor模型要求主線程只負責監聽文件描述上是否有事件發生,有的話就立即將該事件通知工作線程,除此之外,主線程不做任何其他實質性的工作,讀寫數據、接受新的連接以及處理客戶請求均在工作線程中完成。其模型組成如下:
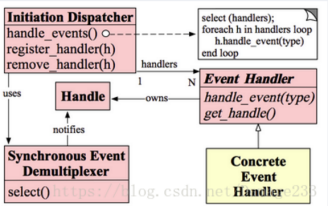
- 1)Handle:即操作系統中的句柄,是對資源在操作系統層面上的一種抽象,它可以是打開的文件、一個連接(Socket)、Timer等。由于Reactor模式一般使用在網絡編程中,因而這里一般指Socket Handle,即一個網絡連接。
- 2)Synchronous Event Demultiplexer(同步事件復用器):阻塞等待一系列的Handle中的事件到來,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的執行返回的事件類型。這個模塊一般使用操作系統的select來實現。
- 3)Initiation Dispatcher:用于管理Event Handler,即EventHandler的容器,用以注冊、移除EventHandler等;另外,它還作為Reactor模式的入口調用Synchronous Event Demultiplexer的select方法以阻塞等待事件返回,當阻塞等待返回時,根據事件發生的Handle將其分發給對應的Event Handler處理,即回調EventHandler中的handle_event()方法。
- 4)Event Handler:定義事件處理方法:handle_event(),以供InitiationDispatcher回調使用。
- 5)Concrete Event Handler:事件EventHandler接口,實現特定事件處理邏輯。
請自己設計一下如何采用單線程的方式處理高并發
- 在單線程模型中,可以采用I/O復用來提高單線程處理多個請求的能力,然后再采用事件驅動模型,基于異步回調來處理事件
參考鏈接
- Redis為什么是單線程,高并發快的3大原因詳解
- 詳解高并發與多線程的關系,高并發的技術解決方案
- 怎么理解分布式、高并發、多線程?(含面試題和答案解析)
高并發、任務執行時間短的業務怎樣使用線程池?
并發不高、任務執行時間長的業務怎樣使用線程池?
并發高、業務執行時間長的業務怎樣使用線程池?
- 1)高并發、任務執行時間短的業務,線程池線程數可以設置為CPU核數+1,減少線程上下文的切換
- 2)并發不高、任務執行時間長的業務要區分開看:
- a)假如是業務時間長集中在IO操作上,也就是IO密集型的任務,因為IO操作并不占用CPU,所以不要讓所有的CPU閑下來,可以加大線程池中的線程數目,讓CPU處理更多的業務
- b)假如是業務時間長集中在計算操作上,也就是計算密集型任務,這個就沒辦法了,和(1)一樣吧,線程池中的線程數設置得少一些,減少線程上下文的切換
- c)并發高、業務執行時間長,解決這種類型任務的關鍵不在于線程池而在于整體架構的設計,看看這些業務里面某些數據是否能做緩存是第一步,增加服務器是第二步,至于線程池的設置,設置參考其他有關線程池的文章。最后,業務執行時間長的問題,也可能需要分析一下,看看能不能使用中間件對任務進行拆分和解耦。
請你說一說C++ STL 的內存優化
1)二級配置器結構
1、第一級配置器
- 第一級配置器以malloc(),free(),realloc()等C函數執行實際的內存配置、釋放、重新配置等操作,并且能在內存需求不被滿足的時候,調用一個指定的函數。
- 一級空間配置器分配的是大于128字節的空間,如果分配不成功,調用句柄釋放一部分內存? 如果還不能分配成功,拋出異常
2、第二級配置器
- 在STL的第二級配置器中多了一些機制,避免太多小區塊造成的內存碎片,小額區塊帶來的不僅是內存碎片,配置時還有額外的負擔。區塊越小,額外負擔所占比例就越大。
3、分配原則
- 如果要分配的區塊大于128bytes,則移交給第一級配置器處理。
- 如果要分配的區塊小于128bytes,則以內存池管理(memory pool),又稱之次層配置(sub-allocation):每次配置一大塊內存,并維護對應的16個空閑鏈表(free-list)。下次若有相同大小的內存需求,則直接從free-list中取。如果有小額區塊被釋放,則由配置器回收到free-list中。
- 當用戶申請的空間小于128字節時,將字節數擴展到8的倍數,然后在自由鏈表中查找對應大小的子鏈表
- 如果在自由鏈表查找不到或者塊數不夠,則向內存池進行申請,一般一次申請20塊
- 如果內存池空間足夠,則取出內存
- 如果不夠分配20塊,則分配最多的塊數給自由鏈表,并且更新每次申請的塊數
- 如果一塊都無法提供,則把剩余的內存掛到自由鏈表,然后向系統heap申請空間,如果申請失敗,則看看自由鏈表還有沒有可用的塊,如果也沒有,則最后調用一級空間配置器
2)二級內存池
- 二級內存池采用了16個空閑鏈表,這里的16個空閑鏈表分別管理大小為8、16、24......120、128的數據塊。這里空閑鏈表節點的設計十分巧妙,這里用了一個聯合體既可以表示下一個空閑數據塊(存在于空閑鏈表中)的地址,也可以表示已經被用戶使用的數據塊(不存在空閑鏈表中)的地址。
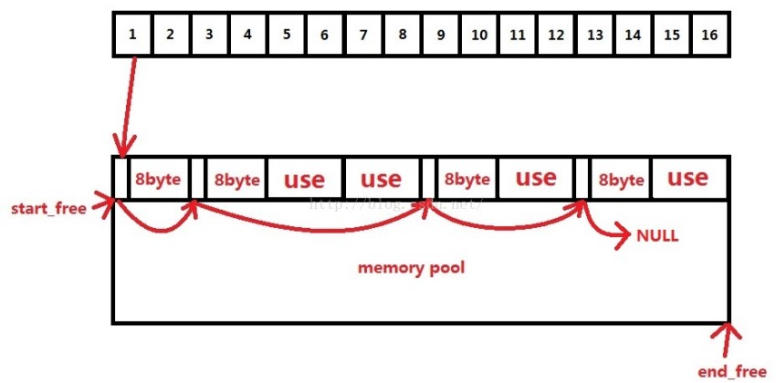
1、空間配置函數allocate
- 首先先要檢查申請空間的大小,如果大于128字節就調用第一級配置器,小于128字節就檢查對應的空閑鏈表,如果該空閑鏈表中有可用數據塊,則直接拿來用(拿取空閑鏈表中的第一個可用數據塊,然后把該空閑鏈表的地址設置為該數據塊指向的下一個地址),如果沒有可用數據塊,則調用refill重新填充空間。
2、空間釋放函數deallocate
- 首先先要檢查釋放數據塊的大小,如果大于128字節就調用第一級配置器,小于128字節則根據數據塊的大小來判斷回收后的空間會被插入到哪個空閑鏈表。
3、重新填充空閑鏈表refill
- 在用allocate配置空間時,如果空閑鏈表中沒有可用數據塊,就會調用refill來重新填充空間,新的空間取自內存池。缺省取20個數據塊,如果內存池空間不足,那么能取多少個節點就取多少個。
- 從內存池取空間給空閑鏈表用是chunk_alloc的工作,首先根據end_free-start_free來判斷內存池中的剩余空間是否足以調出nobjs個大小為size的數據塊出去,如果內存連一個數據塊的空間都無法供應,需要用malloc取堆中申請內存。
- 假如山窮水盡,整個系統的堆空間都不夠用了,malloc失敗,那么chunk_alloc會從空閑鏈表中找是否有大的數據塊,然后將該數據塊的空間分給內存池(這個數據塊會從鏈表中去除)。
3、總結:
- 1. 使用allocate向內存池請求size大小的內存空間,如果需要請求的內存大小大于128bytes,直接使用malloc。
- 2. 如果需要的內存大小小于128bytes,allocate根據size找到最適合的自由鏈表。
- a. 如果鏈表不為空,返回第一個node,鏈表頭改為第二個node。
- b. 如果鏈表為空,使用blockAlloc請求分配node。
- x. 如果內存池中有大于一個node的空間,分配竟可能多的node(但是最多20個),將一個node返回,其他的node添加到鏈表中。
- y. 如果內存池只有一個node的空間,直接返回給用戶。
- z. 若果如果連一個node都沒有,再次向操作系統請求分配內存。
- ①分配成功,再次進行b過程。
- ②分配失敗,循環各個自由鏈表,尋找空間。
- I. 找到空間,再次進行過程b。
- II. 找不到空間,拋出異常。
- 3. 用戶調用deallocate釋放內存空間,如果要求釋放的內存空間大于128bytes,直接調用free。
- 4. 否則按照其大小找到合適的自由鏈表,并將其插入。
請你說說select,epoll的區別,原理,性能,限制都說一說
1)IO多路復用
- IO復用模型在阻塞IO模型上多了一個select函數,select函數有一個參數是文件描述符集合,意思就是對這些的文件描述符進行循環監聽,當某個文件描述符就緒的時候,就對這個文件描述符進行處理。
- 這種IO模型是屬于阻塞的IO。但是由于它可以對多個文件描述符進行阻塞監聽,所以它的效率比阻塞IO模型高效。
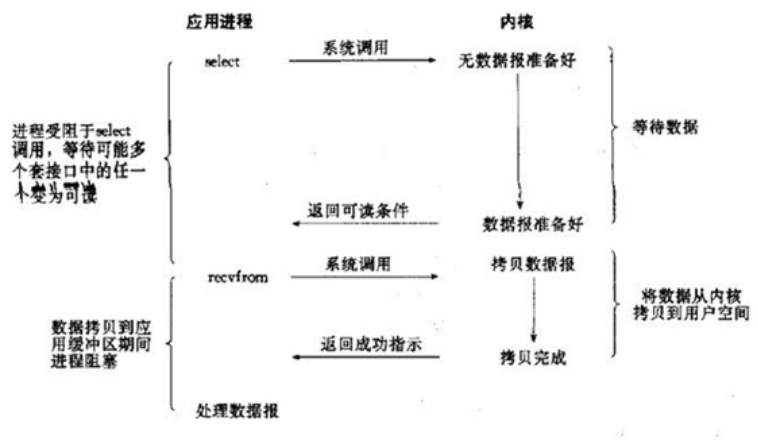
- IO多路復用就是我們說的select,poll,epoll。select/epoll的好處就在于單個process就可以同時處理多個網絡連接的IO。它的基本原理就是select,poll,epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。
- 當用戶進程調用了select,那么整個進程會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
- 所以,I/O 多路復用的特點是通過一種機制一個進程能同時等待多個文件描述符,而這些文件描述符(套接字描述符)其中的任意一個進入讀就緒狀態,select()函數就可以返回。
- I/O多路復用和阻塞I/O其實并沒有太大的不同,事實上,還更差一些。因為這里需要使用兩個system call (select 和 recvfrom),而blocking IO只調用了一個system call (recvfrom)。但是,用select的優勢在于它可以同時處理多個connection。
- 所以,如果處理的連接數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延遲還更大。select/epoll的優勢并不是對于單個連接能處理得更快,而是在于能處理更多的連接。)
- 在IO multiplexing Model中,實際中,對于每一個socket,一般都設置成為non-blocking,但是,如上圖所示,整個用戶的process其實是一直被block的。只不過process是被select這個函數block,而不是被socket IO給block。
2、select
- select:是最初解決IO阻塞問題的方法。用結構體fd_set來告訴內核監聽多個文件描述符,該結構體被稱為描述符集。由數組來維持哪些描述符被置位了。對結構體的操作封裝在三個宏定義中。通過輪尋來查找是否有描述符要被處理。
存在的問題:
- 1.?內置數組的形式使得select的最大文件數受限與FD_SIZE;
- 2.?每次調用select前都要重新初始化描述符集,將fd從用戶態拷貝到內核態,每次調用select后,都需要將fd從內核態拷貝到用戶態;
- 3.?輪尋排查當文件描述符個數很多時,效率很低;
3、poll
- poll:通過一個可變長度的數組解決了select文件描述符受限的問題。數組中元素是結構體,該結構體保存描述符的信息,每增加一個文件描述符就向數組中加入一個結構體,結構體只需要拷貝一次到內核態。poll解決了select重復初始化的問題。輪尋排查的問題未解決。
4、epoll
- epoll:輪尋排查所有文件描述符的效率不高,使服務器并發能力受限。因此,epoll采用只返回狀態發生變化的文件描述符,便解決了輪尋的瓶頸。
- epoll對文件描述符的操作有兩種模式:LT(level trigger)和ET(edge trigger)。LT模式是默認模式
1. LT模式
- LT(level triggered)是缺省的工作方式,并且同時支持block和no-block socket.在這種做法中,內核告訴你一個文件描述符是否就緒了,然后你可以對這個就緒的fd進行IO操作。如果你不作任何操作,內核還是會繼續通知你的。
2. ET模式
- ET(edge-triggered)是高速工作方式,只支持no-block socket。在這種模式下,當描述符從未就緒變為就緒時,內核通過epoll告訴你。然后它會假設你知道文件描述符已經就緒,并且不會再為那個文件描述符發送更多的就緒通知,直到你做了某些操作導致那個文件描述符不再為就緒狀態了(比如,你在發送,接收或者接收請求,或者發送接收的數據少于一定量時導致了一個EWOULDBLOCK 錯誤)。但是請注意,如果一直不對這個fd作IO操作(從而導致它再次變成未就緒),內核不會發送更多的通知(only once
- ET模式在很大程度上減少了epoll事件被重復觸發的次數,因此效率要比LT模式高。epoll工作在ET模式的時候,必須使用非阻塞套接口,以避免由于一個文件句柄的阻塞讀/阻塞寫操作把處理多個文件描述符的任務餓死。
3、LT模式與ET模式的區別如下:
- LT模式:當epoll_wait檢測到描述符事件發生并將此事件通知應用程序,應用程序可以不立即處理該事件。下次調用epoll_wait時,會再次響應應用程序并通知此事件。
- ET模式:當epoll_wait檢測到描述符事件發生并將此事件通知應用程序,應用程序必須立即處理該事件。如果不處理,下次調用epoll_wait時,不會再次響應應用程序并通知此事件。
![C語言 指針數組-字符指針數組整型指針數組 char*s[3] int*a[5] 數組指針int(*p)[4]](http://pic.xiahunao.cn/C語言 指針數組-字符指針數組整型指針數組 char*s[3] int*a[5] 數組指針int(*p)[4])





)


(int,int))

)

 int*p=malloc(5*sizeof(4)))



函數)

