參考博客
Class 5: 序列模型Sequence Models
Week 1: 循環神經網絡RNN (Recurrent)
文章目錄
- Class 5: 序列模型Sequence Models
- Week 1: 循環神經網絡RNN (Recurrent)
- 目錄
- 序列模型-循環神經網絡
- 1.序列模型的應用
- 2.數學符號
- 3.循環神經網絡模型
- 傳統標準的神經網絡
- 循環神經網絡的前向傳播
- 4.穿越時間的反向傳播
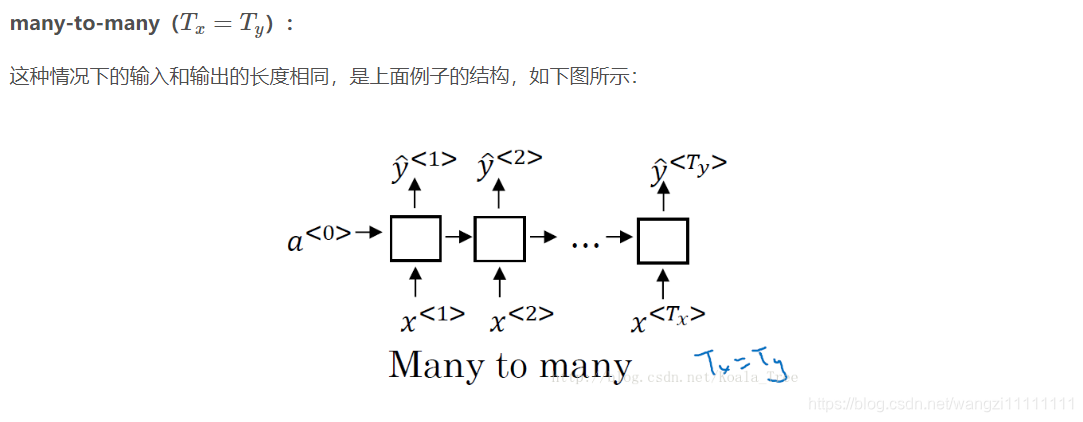
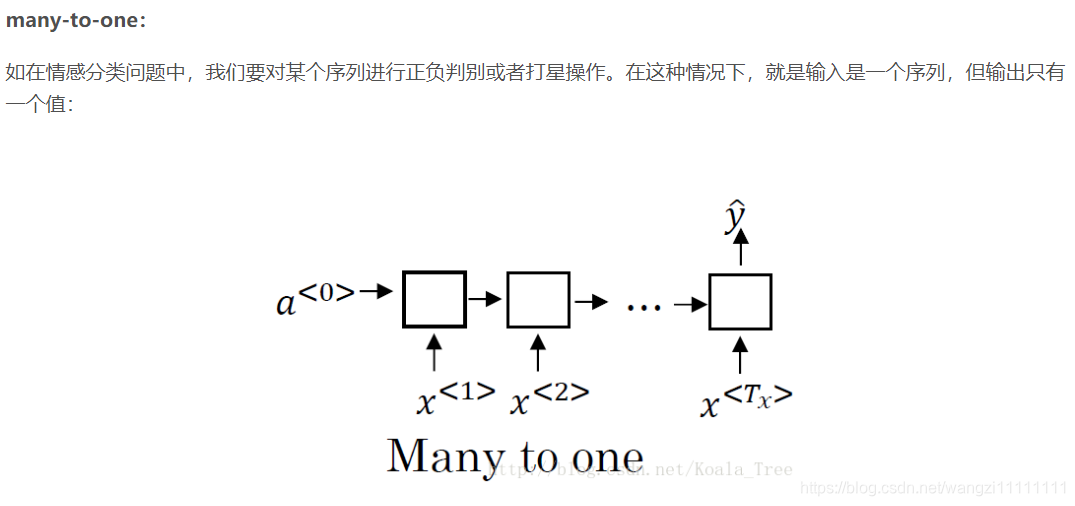
- 5.不同類型的RNN
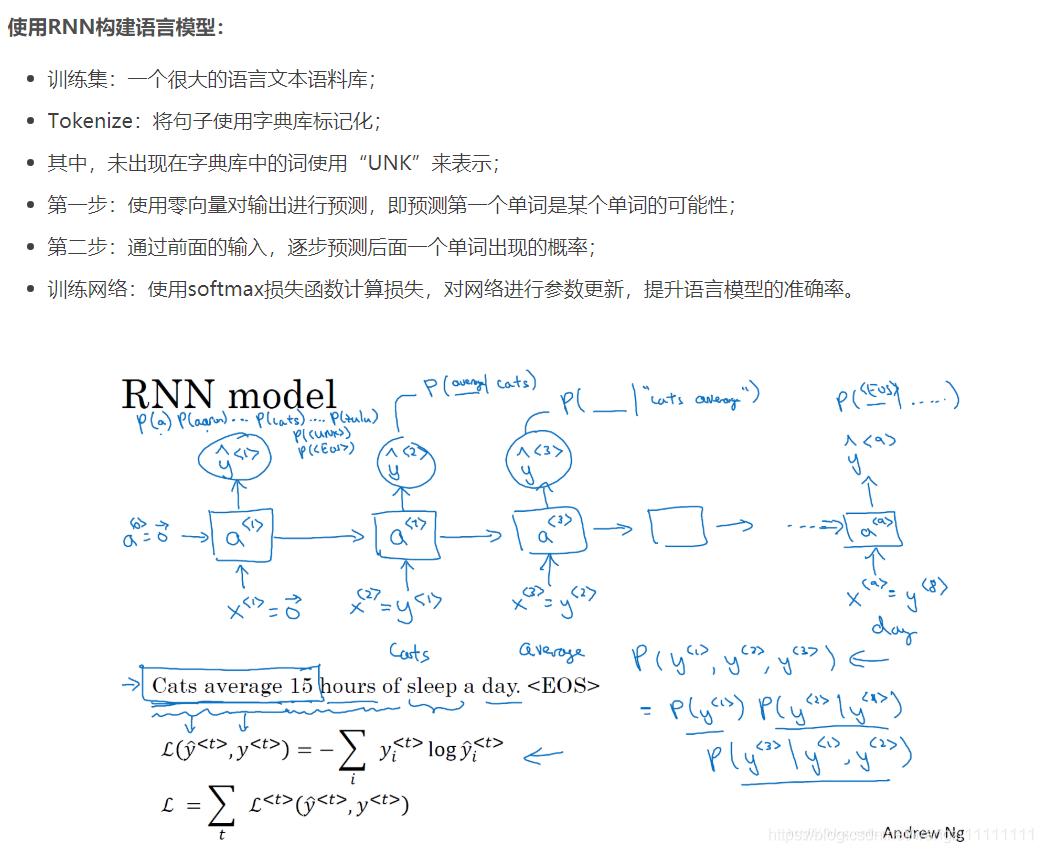
- 6.語言模型和序列生成
- 什么是語言模型
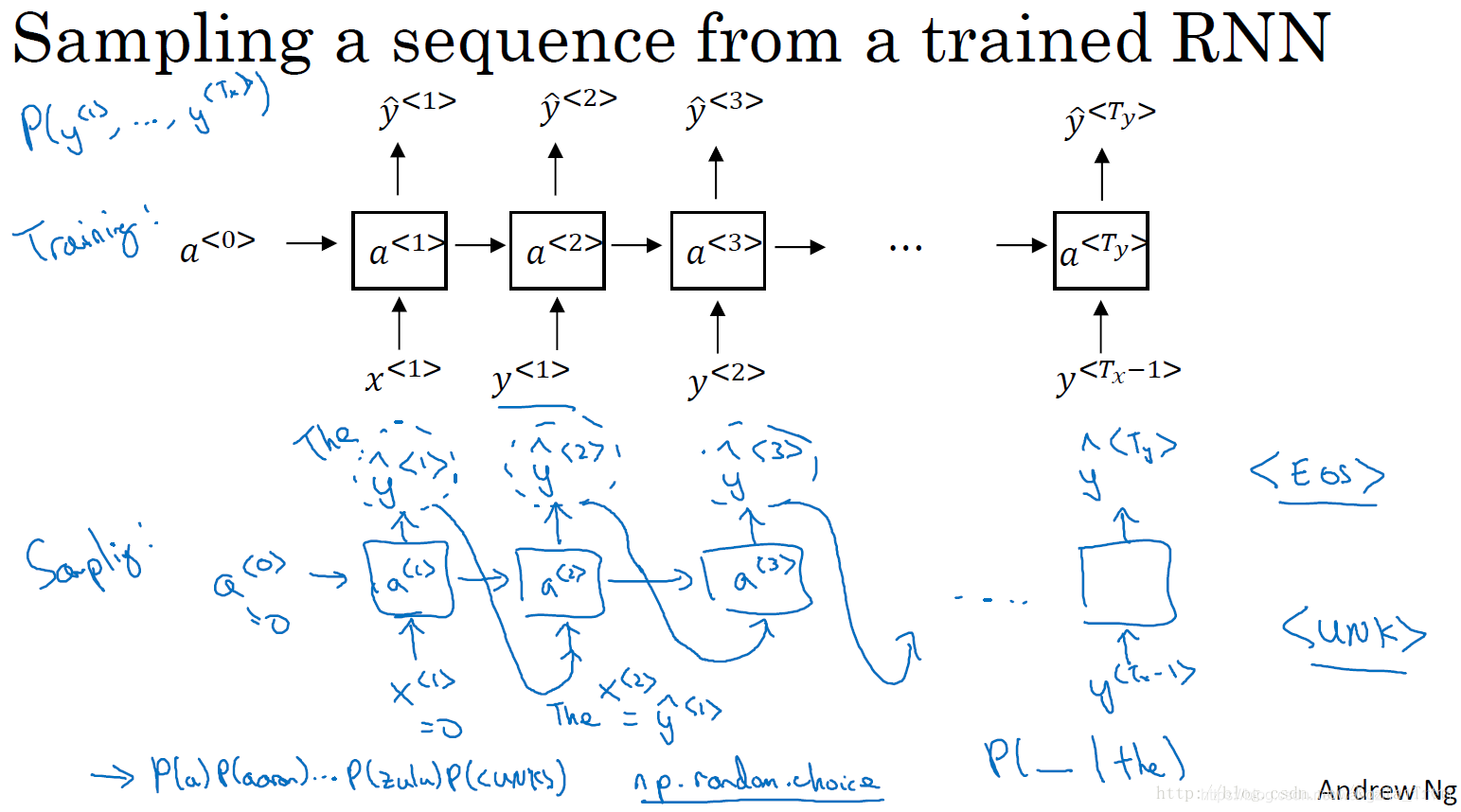
- 7.新序列采樣
- 8.RNN的梯度消失
- 9.GRU單元
- 10.LSTM
- 11. 雙向RNN
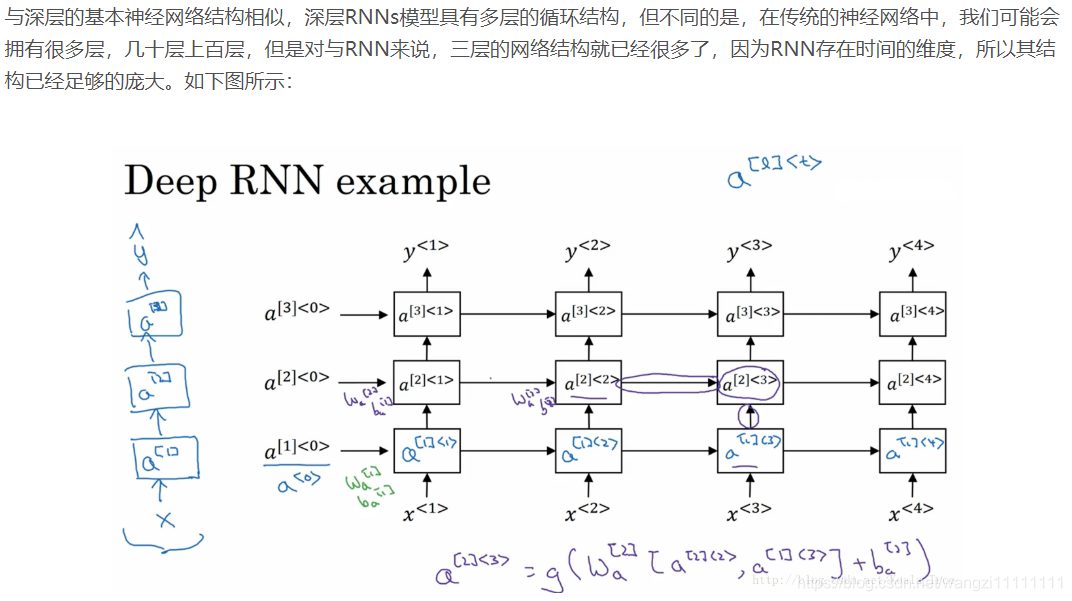
- 12.深層RNN
目錄
本課程將教你如何建立自然語言,音頻和其他序列數據的模型。 由于深入的學習,序列算法的運行速度遠遠超過兩年前,這使得語音識別,音樂合成,聊天機器人,機器翻譯,自然語言理解等許多令人興奮的應用成為可能。
通過本課程你將學到
- 了解常見的序列模型是如何創建的
- 能夠知道如何選擇常見的序列模型,并知道如何訓練他們
- 知道如何將序列模型應用在常見的應用上,如:文本的翻譯,自然語言處理,文本的合成等等
序列模型-循環神經網絡
1.序列模型的應用
循環神經網絡(RNN)之類的模型在語音識別、自然語言處理和其他領域中引起變革。
- 語音識別:將輸入的語音信號直接輸出相應的語音文本信息。無論是語音信號還是文本信息均是序列數據。
- 音樂生成:生成音樂樂譜。只有輸出的音樂樂譜是序列數據,輸入可以是空或者一個整數。
- 情感分類:將輸入的評論句子轉換為相應的等級或評分。輸入是一個序列,輸出則是一個單獨的類別。
- DNA序列分析:找到輸入的DNA序列的蛋白質表達的子序列。
- 機器翻譯:兩種不同語言之間的想換轉換。輸入和輸出均為序列數據。
- 視頻行為識別:識別輸入的視頻幀序列中的人物行為。
- 命名實體識別:從輸入的句子中識別實體的名字
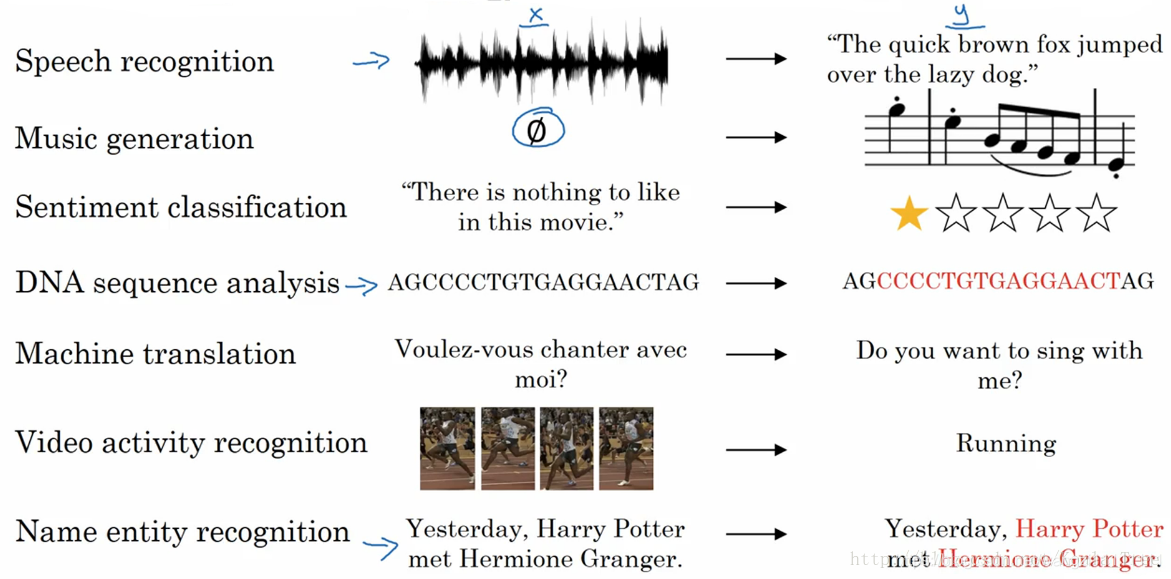
- 在進行語音識別時,給定了一個輸入音頻片段 ,并要求輸出對應的文字記錄 。這個例子里輸入和輸出數據都是序列模型,因為 是一個按時播放的音頻片段,輸出 是一系列單詞。所以之后將要學到的一些序列模型,如循環神經網絡等等在語音識別方面是非常有用的。
- 音樂生成問題是使用序列數據的另一個例子,在這個例子中,只有輸出數據 是序列,而輸入數據可以是空集,也可以是個單一的整數,這個數可能指代你想要生成的音樂風格,也可能是你想要生成的那首曲子的頭幾個音符。輸入的 可以是空的,或者就是個數字,然后輸出序列 。
- 在處理情感分類時,輸入數據 是序列,你會得到類似這樣的輸入:“There is nothing to like in this movie.”,你認為這句評論對應幾星?
- 序列模型在DNA序列分析中也十分有用,你的DNA可以用A、C、G、T四個字母來表示。所以給定一段DNA序列,你能夠標記出哪部分是匹配某種蛋白質的嗎?
- 在機器翻譯過程中,你會得到這樣的輸入句:“Voulez-vou chante avecmoi?”(法語:要和我一起唱么?),然后要求你輸出另一種語言的翻譯結果。
- 在進行視頻行為識別時,你可能會得到一系列視頻幀,然后要求你識別其中的行為。
- 在進行命名實體識別時,可能會給定一個句子要你識別出句中的人名。
所以這些問題都可以被稱作使用標簽數據 作為訓練集的監督學習。但從這一系列例子中你可以看出序列問題有很多不同類型。有些問題里,輸入數據 和輸出數據都是序列,但就算在那種情況下,和有時也會不一樣長。或者像上圖編號1所示和上圖編號2的和有相同的數據長度。在另一些問題里,只有 或者只有是序列。
2.數學符號
本節先從定義符號開始一步步構建序列模型。

比如說你想要建立一個序列模型,它的輸入語句是這樣的:“Harry Potter and Herminoe Granger invented a new spell.”,(這些人名都是出自于J.K.Rowling筆下的系列小說Harry Potter)。假如你想要建立一個能夠自動識別句中人名位置的序列模型,那么這就是一個命名實體識別問題,這常用于搜索引擎,比如說索引過去24小時內所有新聞報道提及的人名,用這種方式就能夠恰當地進行索引。命名實體識別系統可以用來查找不同類型的文本中的人名、公司名、時間、地點、國家名和貨幣名等等。

現在給定這樣的輸入數據,假如你想要一個序列模型輸出,使得輸入的每個單詞都對應一個輸出值,同時這個能夠表明輸入的單詞是否是人名的一部分。技術上來說這也許不是最好的輸出形式,還有更加復雜的輸出形式,它不僅能夠表明輸入詞是否是人名的一部分,它還能夠告訴你這個人名在這個句子里從哪里開始到哪里結束。比如Harry Potter(上圖編號1所示)、Hermione Granger(上圖標號2所示)。
更簡單的那種輸出形式:
這個輸入數據是9個單詞組成的序列,所以最終我們會有9個特征集和來表示這9個單詞,并按序列中的位置進行索引,、、等等一直到來索引不同的位置,我將用來索引這個序列的中間位置。意味著它們是時序序列,但不論是否是時序序列,我們都將用來索引序列中的位置。
輸出數據也是一樣,我們還是用、、等等一直到來表示輸出數據。同時我們用來表示輸入序列的長度,這個例子中輸入是9個單詞,所以。我們用來表示輸出序列的長度。在這個例子里,上個視頻里你知道和可以有不同的值。
你應該記得我們之前用的符號,我們用來表示第個訓練樣本,所以為了指代第個元素,或者說是訓練樣本i的序列中第個元素用這個符號來表示。如果是序列長度,那么你的訓練集里不同的訓練樣本就會有不同的長度,所以就代表第個訓練樣本的輸入序列長度。同樣代表第個訓練樣本中第個元素,就是第個訓練樣本的輸出序列的長度。
所以在這個例子中,,但如果另一個樣本是由15個單詞組成的句子,那么對于這個訓練樣本,。
既然我們這個例子是NLP,也就是自然語言處理,這是我們初次涉足自然語言處理,一件我們需要事先決定的事是怎樣表示一個序列里單獨的單詞,你會怎樣表示像Harry這樣的單詞,實際應該是什么?
接下來我們討論一下怎樣表示一個句子里單個的詞。想要表示一個句子里的單詞,第一件事是做一張詞表,有時也稱為詞典,意思是列一列你的表示方法中用到的單詞。這個詞表(下圖所示)中的第一個詞是a,也就是說詞典中的第一個單詞是a,第二個單詞是Aaron,然后更下面一些是單詞and,再后面你會找到Harry,然后找到Potter,這樣一直到最后,詞典里最后一個單詞可能是Zulu。
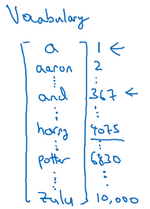
因此a是第一個單詞,Aaron是第二個單詞,在這個詞典里,and出現在367這個位置上,Harry是在4075這個位置,Potter在6830,詞典里的最后一個單詞Zulu可能是第10,000個單詞。所以在這個例子中我用了10,000個單詞大小的詞典,這對現代自然語言處理應用來說太小了。對于商業應用來說,或者對于一般規模的商業應用來說30,000到50,000詞大小的詞典比較常見,但是100,000詞的也不是沒有,而且有些大型互聯網公司會用百萬詞,甚至更大的詞典。許多商業應用用的詞典可能是30,000詞,也可能是50,000詞。不過我將用10,000詞大小的詞典做說明,因為這是一個很好用的整數。
如果你選定了10,000詞的詞典,構建這個詞典的一個方法是遍歷你的訓練集,并且找到前10,000個常用詞,你也可以去瀏覽一些網絡詞典,它能告訴你英語里最常用的10,000個單詞,接下來你可以用one-hot表示法來表示詞典里的每個單詞。
舉個例子,在這里表示Harry這個單詞,它就是一個第4075行是1,其余值都是0的向量(上圖編號1所示),因為那是Harry在這個詞典里的位置。
同樣是個第6830行是1,其余位置都是0的向量(上圖編號2所示)。
and在詞典里排第367,所以就是第367行是1,其余值都是0的向量(上圖編號3所示)。如果你的詞典大小是10,000的話,那么這里的每個向量都是10,000維的。
因為a是字典第一個單詞,對應a,那么這個向量的第一個位置為1,其余位置都是0的向量(上圖編號4所示)。
所以這種表示方法中,指代句子里的任意詞,它就是個one-hot向量,因為它只有一個值是1,其余值都是0,所以你會有9個one-hot向量來表示這個句中的9個單詞,目的是用這樣的表示方式表示,用序列模型在和目標輸出之間學習建立一個映射。我會把它當作監督學習的問題,我確信會給定帶有標簽的數據。
那么還剩下最后一件事,我們將在之后的視頻討論,如果你遇到了一個不在你詞表中的單詞,答案就是創建一個新的標記,也就是一個叫做Unknow Word的偽造單詞,用作為標記,來表示不在詞表中的單詞,我們之后會討論更多有關這個的內容。
總結一下本節課的內容,我們描述了一套符號用來表述你的訓練集里的序列數據和,在下節課我們開始講述循環神經網絡中如何構建到的映射。
3.循環神經網絡模型
傳統標準的神經網絡
對于學習X和Y的映射,我們可以很直接的想到一種方法就是使用傳統的標準神經網絡。也許我們可以將輸入的序列X以某種方式進行字典編碼以后,如one-hot編碼,輸入到一個多層的深度神經網絡中,最后得到對應的輸出Y。如下圖所示:
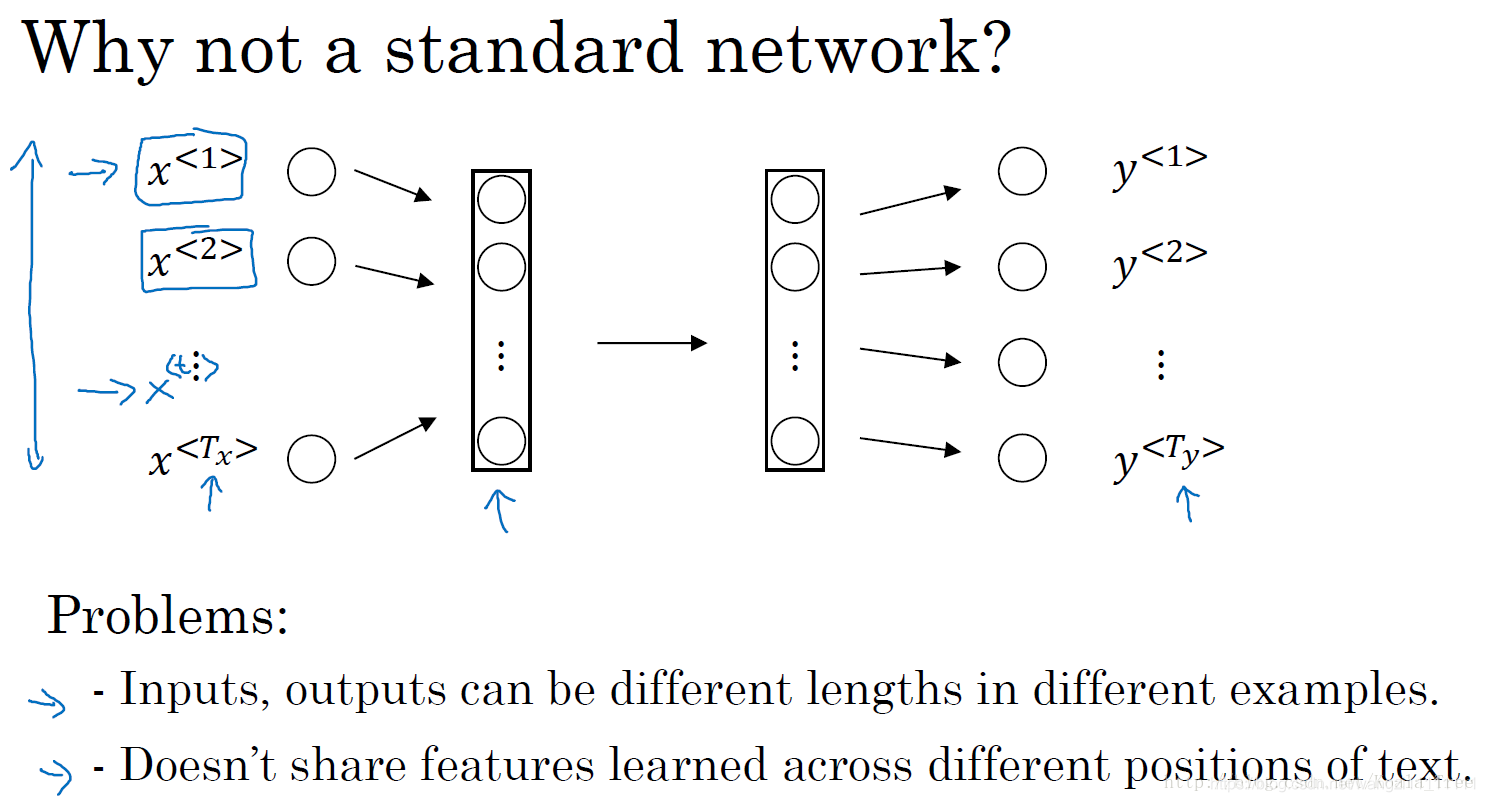
但是,結果表明這種方法并不好,主要是存在下面兩個問題:
一、是輸入和輸出數據在不同例子中可以有不同的長度,不是所有的例子都有著同樣輸入長度或是同樣輸出長度的。即使每個句子都有最大長度,也許你能夠填充(pad)或零填充(zero pad)使每個輸入語句都達到最大長度,但仍然看起來不是一個好的表達方式。
二、一個像這樣單純的神經網絡結構,它并不共享從文本的不同位置上學到的特征。具體來說,如果神經網絡已經學習到了在位置1出現的Harry可能是人名的一部分,那么如果Harry出現在其他位置,比如時,它也能夠自動識別其為人名的一部分的話,這就很棒了。這可能類似于你在卷積神經網絡中看到的,你希望將部分圖片里學到的內容快速推廣到圖片的其他部分,而我們希望對序列數據也有相似的效果。和你在卷積網絡中學到的類似,用一個更好的表達方式也能夠讓你減少模型中參數的數量。
之前我們提到過這些(上圖編號1所示的…………)都是10,000維的one-hot向量,因此這會是十分龐大的輸入層。如果總的輸入大小是最大單詞數乘以10,000,那么第一層的權重矩陣就會有著巨量的參數。但循環神經網絡就沒有上述的兩個問題。
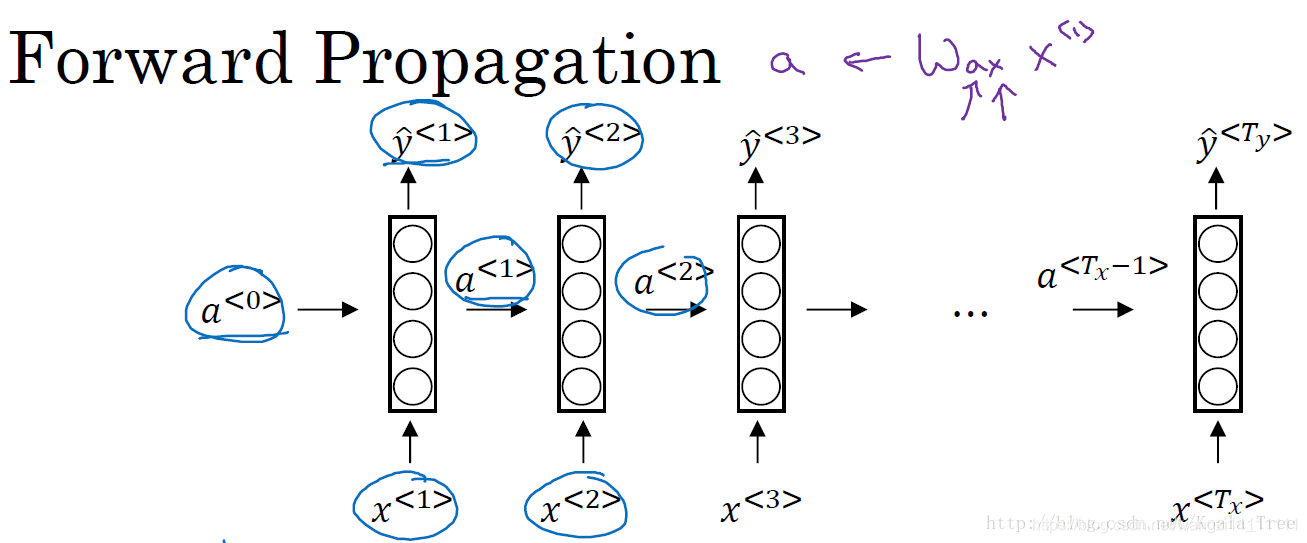
循環神經網絡作為一種新型的網絡結構,在處理序列數據問題上則不存在上面的兩個缺點。在每一個時間步中,循環神經網絡會傳遞一個激活值到下一個時間步中,用于下一時間步的計算。如下圖所示:
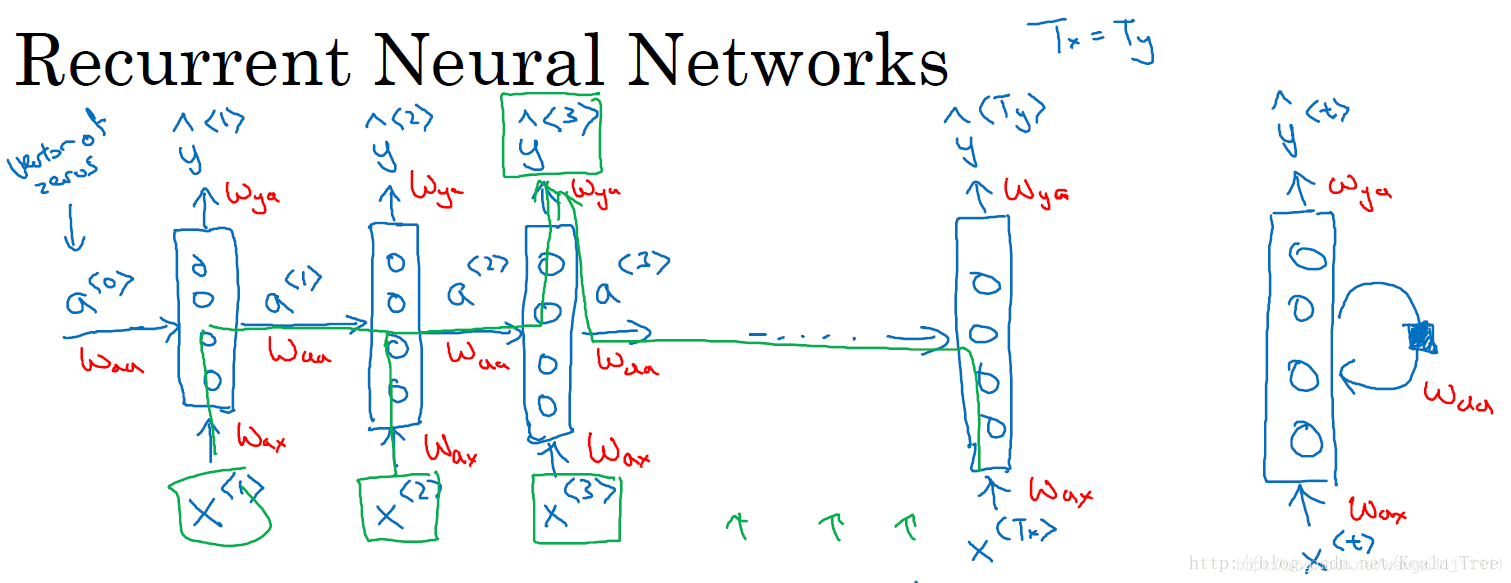
這里需要注意在零時刻,我們需要編造一個激活值,通常輸入一個零向量,有的研究人員會使用隨機的方法對該初始激活向量進行初始化。同時,上圖中右邊的循環神經網絡的繪制結構與左邊是等價的。
循環神經網絡是從左到右掃描數據的,同時共享每個時間步的參數。

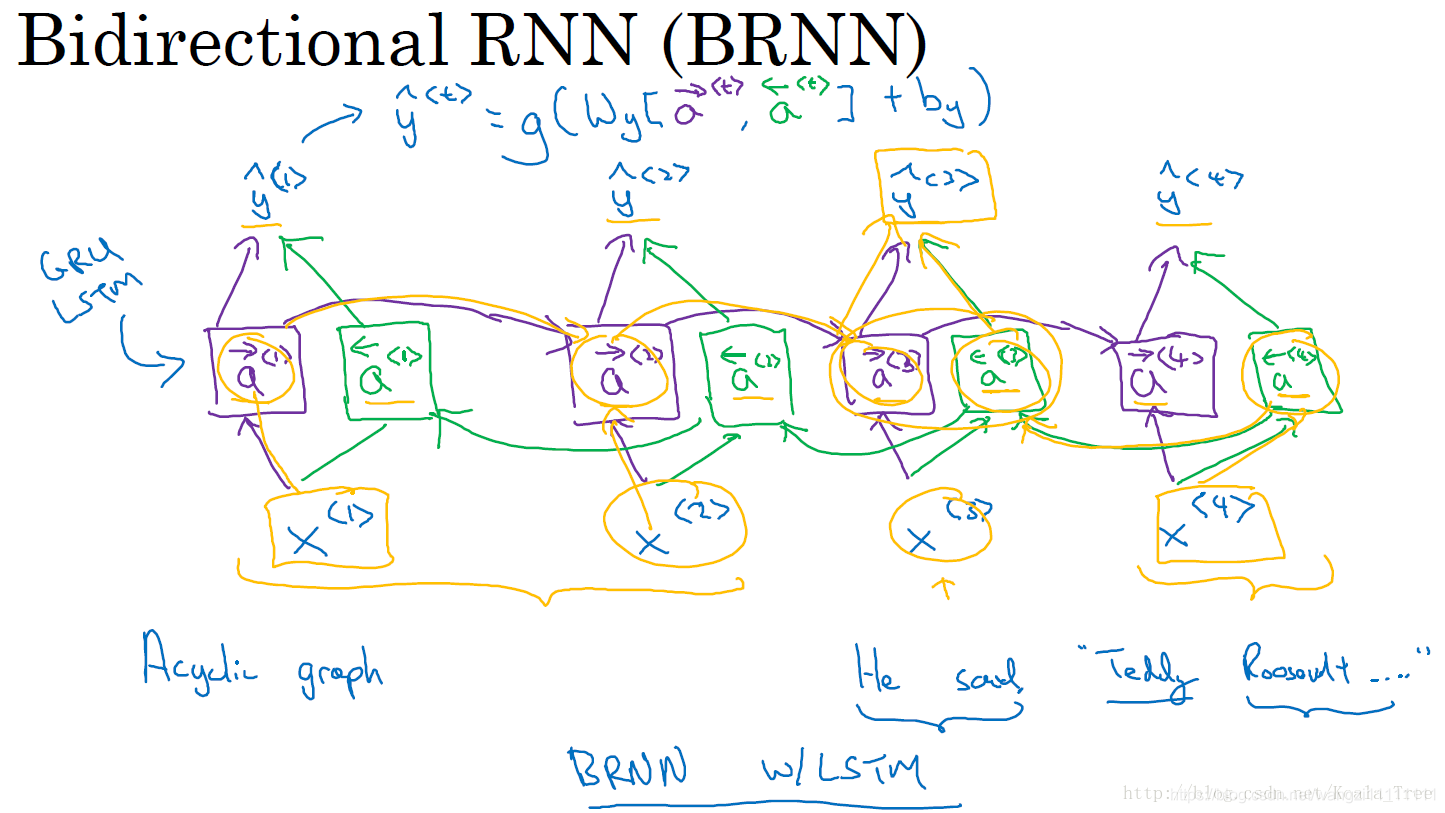
上述循環神經網絡結構的缺點:每個預測輸出y^t僅使用了前面的輸入信息,而沒有使用后面的信息。Bidirectional RNN(雙向循環神經網絡)可以解決這種存在的缺點。
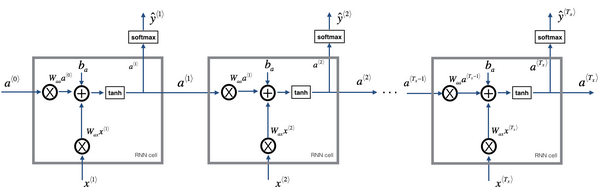
循環神經網絡的前向傳播


RNN前向傳播示意圖:
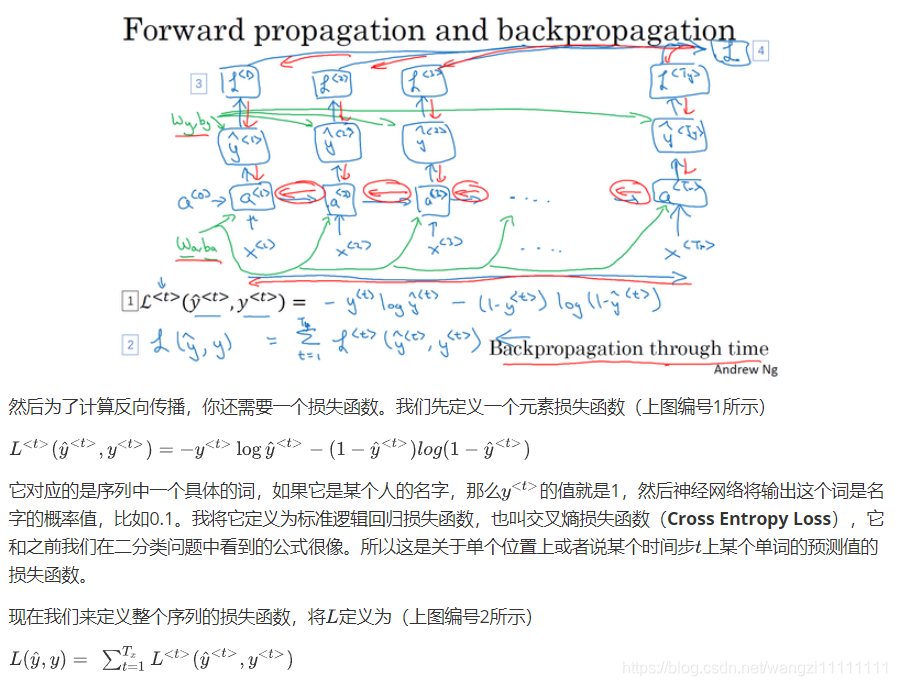
4.穿越時間的反向傳播
之前我們已經學過了循環神經網絡的基礎結構,在本節視頻中我們將來了解反向傳播是怎樣在循環神經網絡中運行的。和之前一樣,當你在編程框架中實現循環神經網絡時,編程框架通常會自動處理反向傳播。但我認為,在循環神經網絡中,對反向傳播的運行有一個粗略的認識還是非常有用的,讓我們來一探究竟


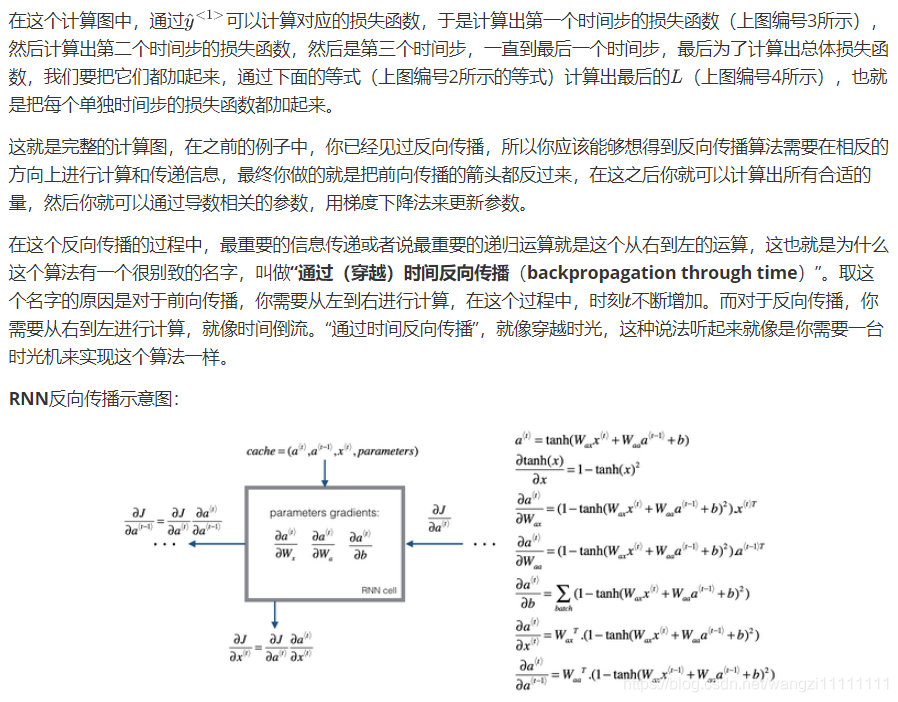
5.不同類型的RNN
對于RNN,不同的問題需要不同的輸入輸出結構。



6.語言模型和序列生成
在自然語言處理中,構建語言模型是最基礎的也是最重要的工作之一,并且能用RNN很好地實現。
什么是語言模型
對于下面的例子,兩句話有相似的發音,但是想表達的意義和正確性卻不相同,如何讓我們的構建的語音識別系統能夠輸出正確地給出想要的輸出。也就是對于語言模型來說,從輸入的句子中,評估各個句子中各個單詞出現的可能性,進而給出整個句子出現的可能性。


7.新序列采樣



8.RNN的梯度消失

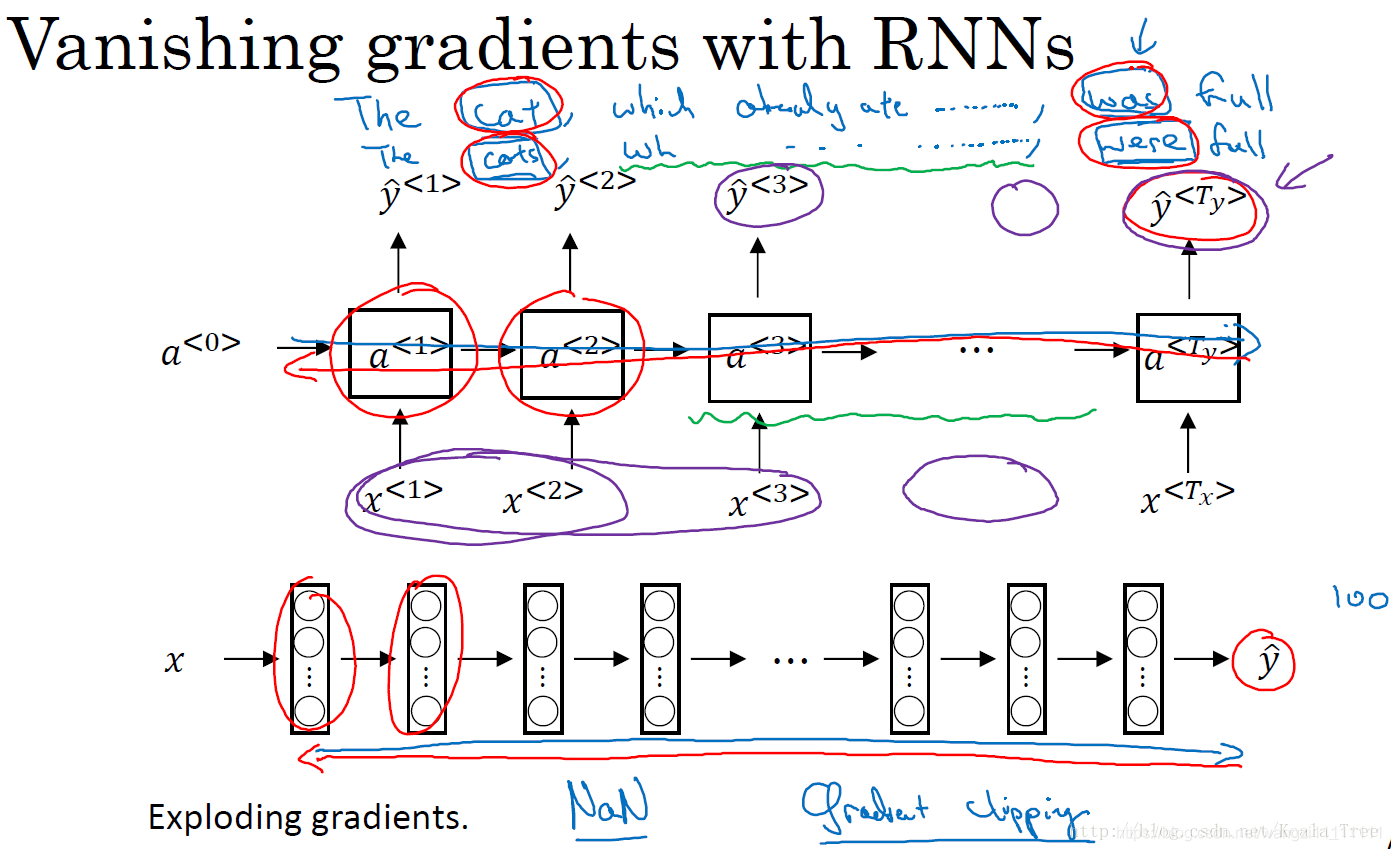
對于梯度消失問題,在RNN的結構中是我們首要關心的問題,也更難解決;雖然梯度爆炸在RNN中也會出現,但對于梯度爆炸問題,因為參數會指數級的梯度,會讓我們的網絡參數變得很大,得到很多的Nan或者數值溢出,所以梯度爆炸是很容易發現的,我們的解決方法就是用梯度修剪,也就是觀察梯度向量,如果其大于某個閾值,則對其進行縮放,保證它不會太大。
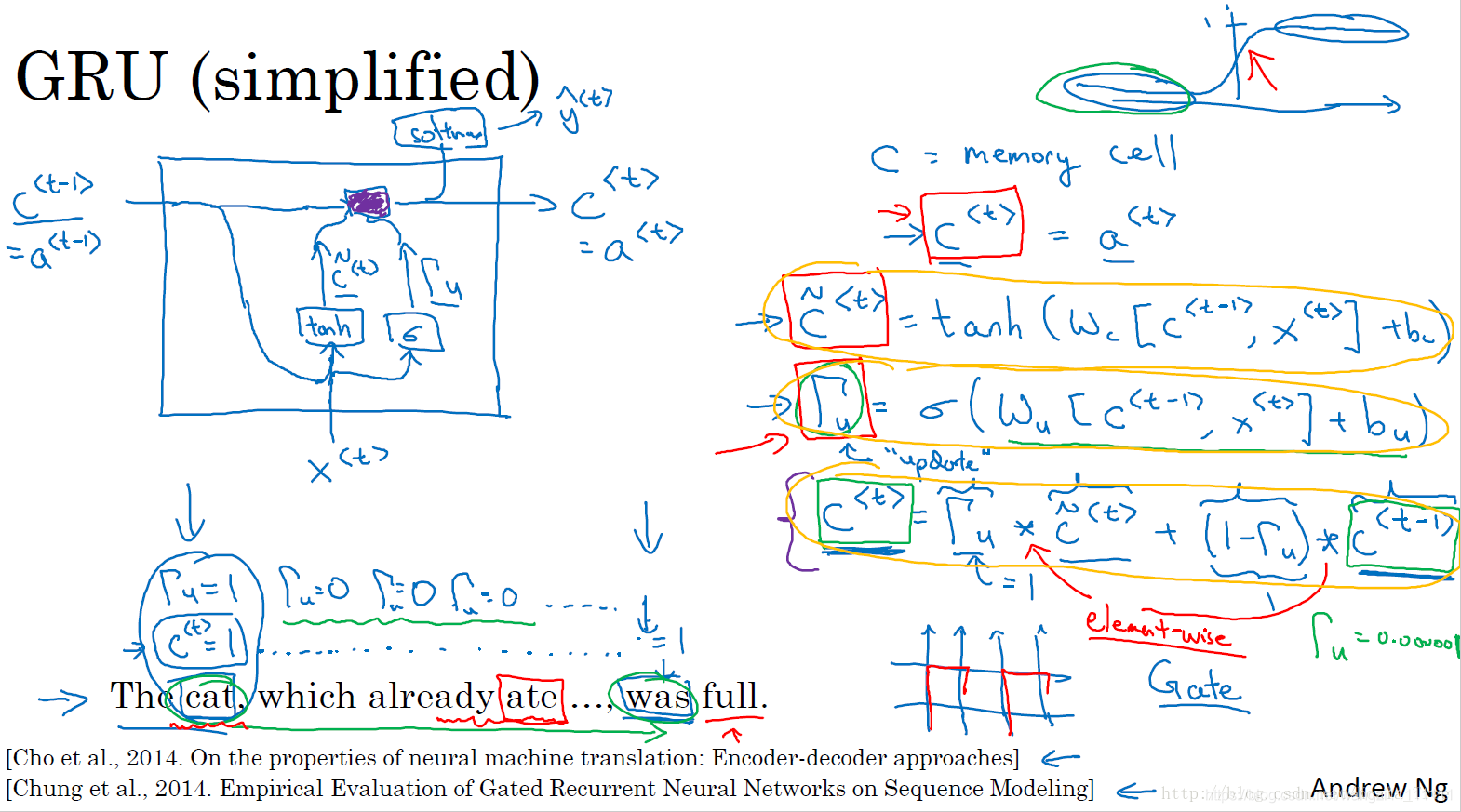
9.GRU單元



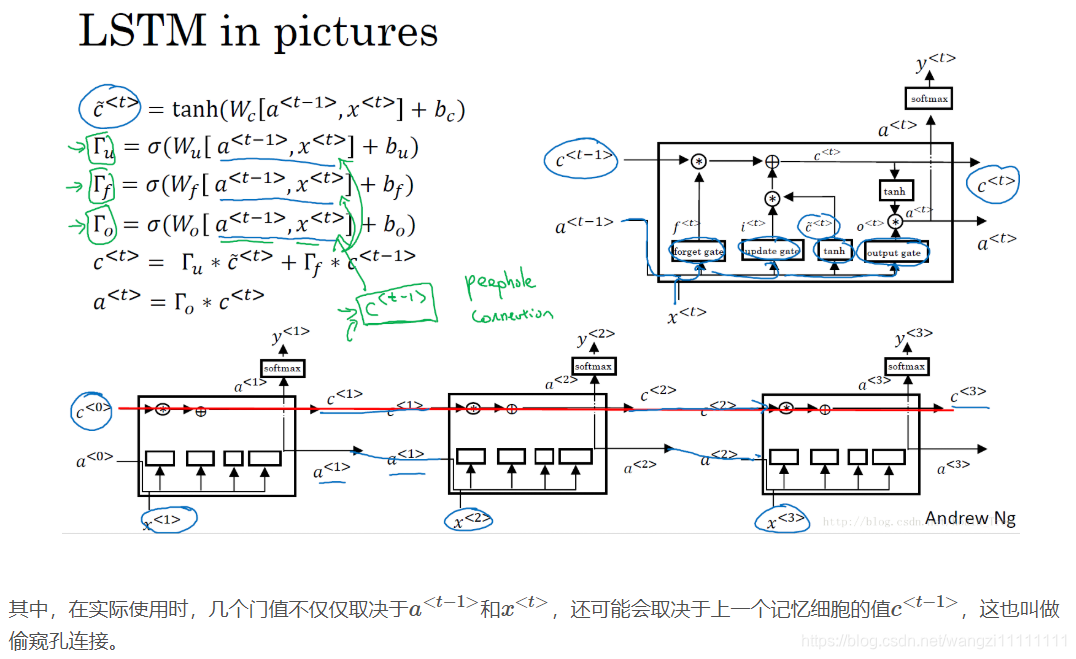
10.LSTM
GRU能夠讓我們在序列中學習到更深的聯系,長短期記憶(long short-term memory, LSTM)對捕捉序列中更深層次的聯系要比GRU更加有效。

11. 雙向RNN

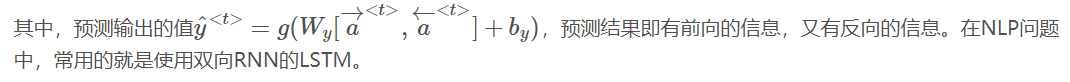
12.深層RNN

)
 - 房價預測案例(進階版))








---avazu_ctr_predictor(baseline))



----Introduction and Linear Regression)

)

--c++,Python版本)