Stack
基于Vector實現,支持LIFO。
類聲明
public class Stack<E> extends Vector<E> {}
push
public E push(E item) {addElement(item);return item;
}pop
public synchronized E pop() {E? obj;int len = size();obj = peek();removeElementAt(len - 1);return obj;
}peek
public synchronized E peek() {int len = size();if (len == 0)throw new EmptyStackException();return elementAt(len - 1);
}Queue
先進先出”(FIFO—first in first out)的線性表
LinkedList類實現了Queue接口,因此我們可以把LinkedList當成Queue來用。
Java里有一個叫做Stack的類,卻沒有叫做Queue的類(它是個接口名字)。當需要使用棧時,Java已不推薦使用Stack,而是推薦使用更高效的ArrayDeque;既然Queue只是一個接口,當需要使用隊列時也就首選ArrayDeque了(次選是LinkedList)。
ArrayDeque和LinkedList是Deque的兩個通用實現。
ArrayDeque
(底層是循環數組,有界隊列)
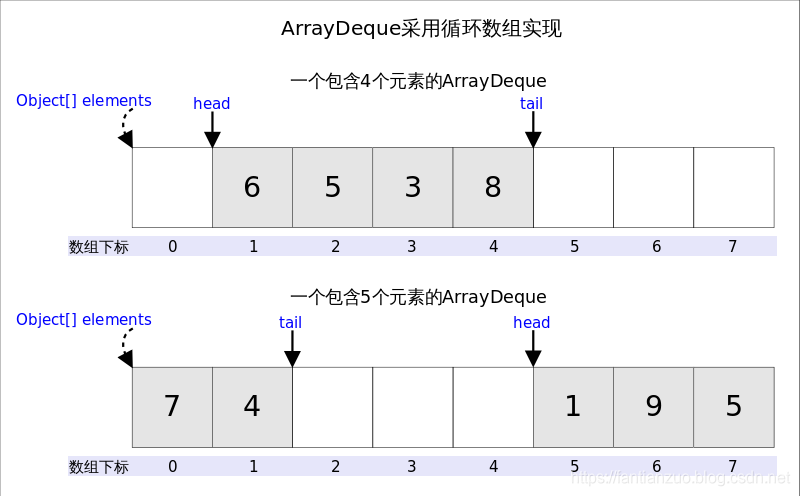
head指向首端第一個有效元素,tail指向尾端第一個可以插入元素的空位。因為是循環數組,所以head不一定總等于0,tail也不一定總是比head大。
ConcurrentLinkedQueue
(底層是鏈表,基于CAS的非阻塞隊列,無界隊列)
ConcurrentLinkedQueue是一個基于鏈接節點的無界線程安全隊列,它采用先進先出的規則對節點進行排序,當我們添加一個元素的時候,它會添加到隊列的尾部,當我們獲取一個元素時,它會返回隊列頭部的元素。它采用了“wait-free”算法(非阻塞)來實現。
1 . 使用 CAS 原子指令來處理對數據的并發訪問,這是非阻塞算法得以實現的基礎。
2. head/tail 并非總是指向隊列的頭 / 尾節點,也就是說允許隊列處于不一致狀態。 這個特性把入隊 / 出隊時,原本需要一起原子化執行的兩個步驟分離開來,從而縮小了入隊 / 出隊時需要原子化更新值的范圍到唯一變量。這是非阻塞算法得以實現的關鍵。
3. 以批處理方式來更新head/tail,從整體上減少入隊 / 出隊操作的開銷。
4. ConcurrentLinkedQueue的迭代器是弱一致性的,這在并發容器中是比較普遍的現象,主要是指在一個線程在遍歷隊列結點而另一個線程嘗試對某個隊列結點進行修改的話不會拋出ConcurrentModificationException,這也就造成在遍歷某個尚未被修改的結點時,在next方法返回時可以看到該結點的修改,但在遍歷后再對該結點修改時就看不到這種變化。
1. 在入隊時最后一個結點中的next域為null
2. 隊列中的所有未刪除結點的item域不能為null且從head都可以在O(N)時間內遍歷到
3. 對于要刪除的結點,不是將其引用直接置為空,而是將其的item域先置為null(迭代器在遍歷是會跳過item為null的結點)
4. 允許head和tail滯后更新,也就是上文提到的head/tail并非總是指向隊列的頭 / 尾節點(這主要是為了減少CAS指令執行的次數,但同時會增加volatile讀的次數,但是這種消耗較小)。具體而言就是,當在隊列中插入一個元素是,會檢測tail和最后一個結點之間的距離是否在兩個結點及以上(內部稱之為hop);而在出隊時,對head的檢測就是與隊列的第一個結點的距離是否達到兩個,有則將head指向第一個結點并將head原來指向的結點的next域指向自己,這樣就能斷開與隊列的聯系從而幫助GC
head節點并不是總指向第一個結點,tail也并不是總指向最后一個節點。
?
成員變量
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
?
構造方法
public ConcurrentLinkedQueue() {head = tail = new Node<E>(null);
}Node#CAS操作
在obj的offset位置比較object field和期望的值,如果相同則更新。這個方法的操作應該是原子的,因此提供了一種不可中斷的方式更新object field。
如果node的next值為cmp,則將其更新為val
boolean casNext(Node<E> cmp, Node<E> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}boolean casItem(E cmp, E val) {return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}private boolean casHead(Node<E> cmp, Node<E> val) {return UNSAFE.compareAndSwapObject(this, headOffset, cmp, val);
}void lazySetNext(Node<E> val) {UNSAFE.putOrderedObject(this, nextOffset, val);
}offer(無鎖)
/*** Inserts the specified element at the tail of this queue.* As the queue is unbounded, this method will never return {@code false}.** @return {@code true} (as specified by {@link Queue#offer})* @throws NullPointerException if the specified element is null*/
public boolean offer(E e) {checkNotNull(e);final Node<E> newNode = new Node<E>(e);for (Node<E> t = tail, p = t;;) {Node<E> q = p.next;// q/p.next/tail.next為null,則說明p是尾節點,則插入if (q == null) {// CAS插入 p.next = newNode,多線程環境下只有一個線程可以設置成功// 此時 tail.next = newNodeif (p.casNext(null, newNode)) {// CAS成功說明新節點已經放入鏈表// 如果p不為t,說明當前線程是之前CAS失敗后又重試CAS成功的,tail = newNodeif (p != t) // hop two nodes at a timecasTail(t, newNode);? // Failure is OK.return true;}// Lost CAS race to another thread; re-read next}else if (p == q)//多線程操作時候,由于poll時候會把老的head變為自引用,然后head的next變為新head,所以這里需要重新找新的head,因為新的head后面的節點才是激活的節點// p = head , t = tailp = (t != (t = tail)) ? t : head;else// 對上一次CAS失敗的線程而言,t.next/p.next/tail.next/q 不是null了// 副作用是p = q,p和q都指向了尾節點,進入第三次循環p = (p != t && t != (t = tail)) ? t : q;}
}?
poll(無鎖)
public E poll() {restartFromHead:for (;;) {for (Node<E> h = head, p = h, q;;) {// 保存當前節點的值E item = p.item;// 當前節點有值則CAS置為null, p.item = nullif (item != null && p.casItem(item, null)) {// CAS成功代表當前節點已經從鏈表中移除if (p != h) // hop two nodes at a timeupdateHead(h, ((q = p.next) != null) ? q : p);return item;} // 當前隊列為空時則返回nullelse if ((q = p.next) == null) {updateHead(h, p);return null;} // 自引用了,則重新找新的隊列頭節點else if (p == q)continue restartFromHead;elsep = q;}}
}final void updateHead(Node<E> h, Node<E> p) {if (h != p && casHead(h, p))h.lazySetNext(h);
}peek(無鎖)
public E peek() {restartFromHead:for (;;) {for (Node<E> h = head, p = h, q;;) {E item = p.item;if (item != null || (q = p.next) == null) {updateHead(h, p);return item;}else if (p == q)continue restartFromHead;elsep = q;}}
}size(遍歷計算大小,效率低)
public int size() {int count = 0;for (Node<E> p = first(); p != null; p = succ(p))if (p.item != null)// Collection.size() spec says to max outif (++count == Integer.MAX_VALUE)break;return count;
}PriorityQueue
(底層是數組,邏輯上是小頂堆,無界隊列)
PriorityQueue底層實現的數據結構是“堆”,堆具有以下兩個性質:
任意一個節點的值總是不大于(最大堆)或者不小于(最小堆)其父節點的值;堆是一棵完全二叉樹
基于數組實現的二叉堆,對于數組中任意位置的n上元素,其左孩子在[2n+1]位置上,右孩子[2(n+1)]位置,它的父親則在[(n-1)/2]上,而根的位置則是[0]。
1)時間復雜度:remove()方法和add()方法時間復雜度為O(logn),remove(Object obj)和contains()方法需要O(n)時間復雜度,取隊頭則需要O(1)時間
2)在初始化階段會執行建堆函數,最終建立的是最小堆,每次出隊和入隊操作不能保證隊列元素的有序性,只能保證隊頭元素和新插入元素的有序性,如果需要有序輸出隊列中的元素,則只要調用Arrays.sort()方法即可
3)可以使用Iterator的迭代器方法輸出隊列中元素
4)PriorityQueue是非同步的,要實現同步需要調用java.util.concurrent包下的PriorityBlockingQueue類來實現同步
5)在隊列中不允許使用null元素
6)PriorityQueue默認是一個小頂堆,然而可以通過傳入自定義的Comparator函數來實現大頂堆
替代:用TreeMap復雜度太高,有沒有更好的方法。hash方法,但是隊列不是定長的,如果改變了大小要rehash代價太大,還有什么方法?用堆實現,那每次get put復雜度是多少(lgN)
BlockingQueue
對于許多多線程問題,都可以通過使用一個或多個隊列以優雅的方式將其形式化
生產者線程向隊列插入元素,消費者線程則取出它們。使用隊列,可以安全地從一個線程向另一個線程傳遞數據。
比如轉賬
一個線程將轉賬指令放入隊列
一個線程從隊列中取出指令執行轉賬,只有這個線程可以訪問銀行對象的內部。因此不需要同步
?
當試圖向隊列中添加元素而隊列已滿,或是想從隊列移出元素而隊列為空的時候,阻塞隊列導致線程阻塞
在協調多個線程之間的合作時,阻塞隊列是很有用的。
工作者線程可以周期性地將中間結果放入阻塞隊列,其他工作者線程取出中間結果并進一步修改。隊列會自動平衡負載,大概第一個線程集比第二個運行的慢,那么第二個線程集在等待結果時會阻塞,反之亦然

1)LinkedBlockingQueue的容量是沒有上邊界的,是一個雙向隊列
2)ArrayBlockingQueue在構造時需要指定容量,并且有一個參數來指定是否需要公平策略
3)PriorityBlockingQueue是一個帶優先級的隊列,元素按照它們的優先級順序被移走。該隊列沒有容量上限。
4)DelayQueue包含實現了Delayed接口的對象
5)TransferQueue接口允許生產者線程等待,直到消費者準備就緒可以接收一個元素。如果生產者調用transfer方法,那么這個調用會阻塞,直到插入的元素被消費者取出之后才停止阻塞。
LinkedTransferQueue類實現了這個接口
ArrayBlockingQueue(底層是數組,阻塞隊列,一把鎖兩個Condition,有界同步隊列)
基于數組、先進先出、線程安全的集合類,特點是可實現指定時間的阻塞讀寫,并且容量是可限制的。
成員變量
/** The queued items */
final Object[] items;/** items index for next take, poll, peek or remove */
int takeIndex;/** items index for next put, offer, or add */
int putIndex;/** Number of elements in the queue */
int count;/** Concurrency control uses the classic two-condition algorithm* found in any textbook.*//** Main lock guarding all access */
final ReentrantLock lock;/** Condition for waiting takes */
private final Condition notEmpty;/** Condition for waiting puts */
private final Condition notFull;/*** Shared state for currently active iterators, or null if there* are known not to be any.? Allows queue operations to update* iterator state.*/
transient Itrs itrs = null;put(有鎖,隊列滿則阻塞)
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length)notFull.await();enqueue(e);} finally {lock.unlock();}
}private void enqueue(E x) {// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = x;if (++putIndex == items.length)putIndex = 0;count++;notEmpty.signal();
}take(有鎖,隊列空則阻塞)
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)notEmpty.await();return dequeue();} finally {lock.unlock();}
}private E dequeue() {// assert lock.getHoldCount() == 1;// assert items[takeIndex] != null;final Object[] items = this.items;@SuppressWarnings("unchecked")E x = (E) items[takeIndex];items[takeIndex] = null;if (++takeIndex == items.length)takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();notFull.signal();return x;
}offer(有鎖,最多阻塞一段時間)
public boolean offer(E e, long timeout, TimeUnit unit)throws InterruptedException {checkNotNull(e);long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length) {if (nanos <= 0)return false;nanos = notFull.awaitNanos(nanos);}enqueue(e);return true;} finally {lock.unlock();}
}?
poll(有鎖,最多阻塞一段時間)
public E poll(long timeout, TimeUnit unit) throws InterruptedException {long nanos = unit.toNanos(timeout);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0) {if (nanos <= 0)return null;nanos = notEmpty.awaitNanos(nanos);}return dequeue();} finally {lock.unlock();}
}peek(有鎖)
public E peek() {final ReentrantLock lock = this.lock;lock.lock();try {return itemAt(takeIndex); // null when queue is empty} finally {lock.unlock();}final E itemAt(int i) {return (E) items[i];
}遍歷(構造迭代器加鎖,遍歷迭代器也加鎖)
LinkedBlockingQueue
(底層是鏈表,阻塞隊列,兩把鎖,各自對應一個Condition,無界同步隊列)
另一種BlockingQueue的實現,基于鏈表,沒有容量限制。
由于出隊只操作隊頭,入隊只操作隊尾,這里巧妙地使用了兩把鎖,對于put和offer入隊操作使用一把鎖,對于take和poll出隊操作使用一把鎖,避免了出隊、入隊時互相競爭鎖的現象,因此LinkedBlockingQueue在高并發讀寫都多的情況下,性能會較ArrayBlockingQueue好很多,在遍歷以及刪除的情況下則要兩把鎖都要鎖住。
多CPU情況下可以在同一時刻既消費又生產。
LinkedBlockingDeque
(底層是雙向鏈表,阻塞隊列,一把鎖兩個Condition,無界同步隊列)
LinkedBlockingDeque是一個基于鏈表的雙端阻塞隊列。和LinkedBlockingQueue類似,區別在于該類實現了Deque接口,而LinkedBlockingQueue實現了Queue接口。
LinkedBlockingDeque內部只有一把鎖以及該鎖上關聯的兩個條件,所以可以推斷同一時刻只有一個線程可以在隊頭或者隊尾執行入隊或出隊操作(類似于ArrayBlockingQueue)。可以發現這點和LinkedBlockingQueue不同,LinkedBlockingQueue可以同時有兩個線程在兩端執行操作。
LinkedBlockingDeque和LinkedBlockingQueue的相同點在于:
1. 基于鏈表
2. 容量可選,不設置的話,就是Int的最大值
和LinkedBlockingQueue的不同點在于:
1. 雙端鏈表和單鏈表
2. 不存在哨兵節點
3. 一把鎖+兩個條件
LinkedBlockingDeque和ArrayBlockingQueue的相同點在于:使用一把鎖+兩個條件維持隊列的同步。
PriorityBlockingQueue
(底層是數組,出隊時隊空則阻塞;無界隊列,不存在隊滿情況,一把鎖一個Condition)
支持優先級的無界阻塞隊列。默認情況下元素采用自然順序升序排序,當然我們也可以通過構造函數來指定Comparator來對元素進行排序。需要注意的是PriorityBlockingQueue不能保證同優先級元素的順序。
擴容
(基于CAS+Lock,CAS控制創建新的數組原子執行,Lock控制數組替換原子執行)
private void tryGrow(Object[] array, int oldCap) {lock.unlock(); // must release and then re-acquire main lockObject[] newArray = null;if (allocationSpinLock == 0 &&UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,0, 1)) {try {int newCap = oldCap + ((oldCap < 64) ?(oldCap + 2) : // grow faster if small(oldCap >> 1));if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflowint minCap = oldCap + 1;if (minCap < 0 || minCap > MAX_ARRAY_SIZE)throw new OutOfMemoryError();newCap = MAX_ARRAY_SIZE;}if (newCap > oldCap && queue == array)newArray = new Object[newCap];} finally {allocationSpinLock = 0;}}if (newArray == null) // back off if another thread is allocatingThread.yield();lock.lock();if (newArray != null && queue == array) {queue = newArray;System.arraycopy(array, 0, newArray, 0, oldCap);}
}
?
DelayQueue
(底層是PriorityQueue,無界阻塞隊列,過期元素方可移除,基于Lock)
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>implements BlockingQueue<E> {private final transient ReentrantLock lock = new ReentrantLock();private final PriorityQueue<E> q = new PriorityQueue<E>();DelayQueue隊列中每個元素都有個過期時間,并且隊列是個優先級隊列,當從隊列獲取元素時候,只有過期元素才會出隊列。
每個元素都必須實現Delayed接口
public interface Delayed extends Comparable<Delayed> {/*** Returns the remaining delay associated with this object, in the* given time unit.** @param unit the time unit* @return the remaining delay; zero or negative values indicate* that the delay has already elapsed*/long getDelay(TimeUnit unit);
}getDelay方法返回對象的殘留延遲,負值表示延遲結束
元素只有在延遲用完的時候才能從DelayQueue移出。還必須實現Comparable接口。
一個典型場景是重試機制的實現,比如當調用接口失敗后,把當前調用信息放入delay=10s的元素,然后把元素放入隊列,那么這個隊列就是一個重試隊列,一個線程通過take方法獲取需要重試的接口,take返回則接口進行重試,失敗則再次放入隊列,同時也可以在元素加上重試次數。
成員變量
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();private Thread leader = null;private final Condition available = lock.newCondition();構造方法
public DelayQueue() {}
put
public void put(E e) {offer(e);}
public boolean offer(E e) {final ReentrantLock lock = this.lock;lock.lock();try {q.offer(e);if (q.peek() == e) {leader = null;// 通知最先等待的線程available.signal();}return true;} finally {lock.unlock();}
}take
獲取并移除隊列首元素,如果隊列沒有過期元素則等待。
第一次調用take時候由于隊列空,所以調用(2)把當前線程放入available的條件隊列等待,當執行offer并且添加的元素就是隊首元素時候就會通知最先等待的線程激活,循環重新獲取隊首元素,這時候first假如不空,則調用getdelay方法看該元素海剩下多少時間就過期了,如果delay<=0則說明已經過期,則直接出隊返回。否則看leader是否為null,不為null則說明是其他線程也在執行take則把該線程放入條件隊列,否則是當前線程執行的take方法,則調用(5) await直到剩余過期時間到(這期間該線程會釋放鎖,所以其他線程可以offer添加元素,也可以take阻塞自己),剩余過期時間到后,該線程會重新競爭得到鎖,重新進入循環。
(6)說明當前take返回了元素,如果當前隊列還有元素則調用singal激活條件隊列里面可能有的等待線程。leader那么為null,那么是第一次調用take獲取過期元素的線程,第一次調用的線程調用設置等待時間的await方法等待數據過期,后面調用take的線程則調用await直到signal。
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {for (;;) {
// 1)獲取但不移除隊首元素E first = q.peek();if (first == null)
// 2)無元素,則阻塞 available.await();else {long delay = first.getDelay(NANOSECONDS);
// 3)有元素,且已經過期,則移除if (delay <= 0)return q.poll();first = null; // don't retain ref while waiting
// 4)if (leader != null)available.await();else {Thread thisThread = Thread.currentThread();
// 5)leader = thisThread;try {
// 繼續阻塞延遲的時間available.awaitNanos(delay);} finally {if (leader == thisThread)leader = null;}}}}} finally {if (leader == null && q.peek() != null)available.signal();lock.unlock();}
}SynchronousQueue
(只存儲一個元素,阻塞隊列,基于CAS)
實現了BlockingQueue,是一個阻塞隊列。
一個只存儲一個元素的的阻塞隊列,每個插入操作必須等到另一個線程調用移除操作,否則插入一直處于阻塞狀態,吞吐量高于LinkedBlockingQueue。
SynchronousQueue內部并沒有數據緩存空間,你不能調用peek()方法來看隊列中是否有數據元素,因為數據元素只有當你試著取走的時候才可能存在,不取走而只想偷窺一下是不行的,當然遍歷這個隊列的操作也是不允許的。隊列頭元素是第一個排隊要插入數據的線程,而不是要交換的數據。數據是在配對的生產者和消費者線程之間直接傳遞的,并不會將數據緩沖數據到隊列中。可以這樣來理解:生產者和消費者互相等待對方,握手,然后一起離開。
// 如果為 true,則等待線程以 FIFO 的順序競爭訪問;否則順序是未指定的。?// SynchronousQueue<Integer> sc =new SynchronousQueue<>(true);//fair -?SynchronousQueue<Integer> sc = new SynchronousQueue<>(); // 默認不指定的話是false,不公平的?TransferQueue
(特殊的BlockingQueue)
生產者會一直阻塞直到所添加到隊列的元素被某一個消費者所消費(不僅僅是添加到隊列里就完事)當我們不想生產者過度生產消息時,TransferQueue可能非常有用,可避免發生OutOfMemory錯誤。在這樣的設計中,消費者的消費能力將決定生產者產生消息的速度。public interface TransferQueue<E> extends BlockingQueue<E> {/*** 立即轉交一個元素給消費者,如果此時隊列沒有消費者,那就false*/boolean tryTransfer(E e);/*** 轉交一個元素給消費者,如果此時隊列沒有消費者,那就阻塞*/void transfer(E e) throws InterruptedException;/*** 帶超時的tryTransfer*/boolean tryTransfer(E e, long timeout, TimeUnit unit)throws InterruptedException;/*** 是否有消費者等待接收數據,瞬時狀態,不一定準*/boolean hasWaitingConsumer();/*** 返回還有多少個等待的消費者,跟上面那個一樣,都是一種瞬時狀態,不一定準*/int getWaitingConsumerCount();}?
LinkedTransferQueue
(底層是鏈表,阻塞隊列,無界同步隊列)
LinkedTransferQueue實現了TransferQueue接口,這個接口繼承了BlockingQueue。之前BlockingQueue是隊列滿時再入隊會阻塞,而這個接口實現的功能是隊列不滿時也可以阻塞,實現一種有阻塞的入隊功能。
LinkedTransferQueue實際上是ConcurrentLinkedQueue、SynchronousQueue(公平模式)和LinkedBlockingQueue的超集。而且LinkedTransferQueue更好用,因為它不僅僅綜合了這幾個類的功能,同時也提供了更高效的實現。
Queue實現類之間的區別
非線程安全的:ArrayDeque、LinkedList、PriorityQueue
線程安全的:ConcurrentLinkedQueue、ConcurrentLinkedDeque、ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue
線程安全的又分為阻塞隊列和非阻塞隊列,阻塞隊列提供了put、take等會阻塞當前線程的方法,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,也有offer、poll等阻塞一段時間候返回的方法;
非阻塞隊列是使用CAS機制保證offer、poll等可以線程安全地入隊出隊,并且不需要加鎖,不會阻塞當前線程,比如ConcurrentLinkedQueue、ConcurrentLinkedDeque。
ArrayBlockingQueue和LinkedBlockingQueue 區別
1. 隊列中鎖的實現不同
??? ArrayBlockingQueue實現的隊列中的鎖是沒有分離的,即生產和消費用的是同一個鎖;
??? LinkedBlockingQueue實現的隊列中的鎖是分離的,即生產用的是putLock,消費是takeLock
2. 底層實現不同
前者基于數組,后者基于鏈表
3. 隊列邊界不同
??? ArrayBlockingQueue實現的隊列中必須指定隊列的大小,是有界隊列
??? LinkedBlockingQueue實現的隊列中可以不指定隊列的大小,但是默認是Integer.MAX_VALUE,是無界隊列
?

--Vector容器)



--裸指針、智能指針、引用)



--猿界神猿)



--動態分配內存new,程序的內存分配)



--Tensorboard)

