摘要:
語言是llm(例如ChatGPT)連接眾多AI模型(例如hugs Face)的接口,用于解決復雜的AI任務。在這個概念中,llms作為一個控制器,管理和組織專家模型的合作。LLM首先根據用戶請求規劃任務列表,然后為每個任務分配專家模型。專家執行任務后,LLM收集結果并響應用戶。
問題:
1.盡管LLMs在NLP任務中取得了重大成就,但由于文本輸入和輸出形式的限制,目前的LLMs缺乏處理復雜信息(如視覺和語音)的能力。
2.在現實場景中,一些復雜的任務通常由多個子任務組成,因此需要多個模型的調度和協作,這也超出了語言模型的能力。
3.對于一些具有挑戰性的任務,LLMs在零射擊或少射擊設置中表現出出色的結果,但他們仍然比一些專家(例如,微調模型)弱。
貢獻點:
1. 為了補充大型語言模型和專家模型的優勢,提出了HuggingGPT。HuggingGPT將llm作為規劃和決策的大腦,針對每個特定任務自動調用和執行專家模型,為通用AI解決方案的設計提供了新的途徑。
2.?通過將Hugging Face與ChatGPT周圍的許多任務特定模型集成,HuggingGPT能夠處理涵蓋多種模式和領域的廣義人工智能任務。HuggingGPT通過模型間的開放協作,為用戶提供多模式、可靠的服務。
3. 指出了HuggingGPT(和自治代理)中任務規劃的重要性,并制定了一些實驗評估來衡量llm的規劃能力。
4.在跨語言、視覺、語音和跨模態的多個具有挑戰性的人工智能任務上進行的大量實驗表明,HuggingGPT在理解和解決來自多個模態和領域的復雜任務方面具有巨大的潛力。
方法:
整體流程
1.任務規劃:使用ChatGPT分析用戶的請求,了解用戶的意圖,并通過提示將其分解為可能可解決的任務。
通常,在實際場景中,許多用戶請求將包含一些復雜的意圖,因此需要編排多個子任務來實現目標。因此,我們制定任務規劃作為HuggingGPT的第一階段,目的是利用LLM分析用戶請求,然后將其分解為結構化任務的集合。此外,我們還需要LLM來確定依賴關系以及這些分解任務的執行順序,以建立它們之間的聯系。
2.模型選擇:為了解決計劃的任務,ChatGPT根據模型描述選擇托管在hug Face上的專家模型。
完成任務規劃后,HuggingGPT接下來需要將任務和模型進行匹配,即在解析的任務列表中為每個任務選擇最合適的模型。為此,我們使用模型描述作為連接各個模型的語言接口。更具體地說,我們首先從機器學習社區(例如,hug Face)獲得專家模型的描述,然后通過上下文任務模型分配機制動態選擇任務模型。該策略支持增量模型訪問(簡單地提供專家模型的描述),并且可以更加開放和靈活地使用ML社區。
上下文任務模型分配我們將任務模型分配表述為一個單選問題,其中潛在的模型在給定的上下文中作為選項呈現。通常,HuggingGPT能夠根據提示符中提供的用戶查詢和任務信息,為每個已解析的任務選擇最合適的模型。然而,由于最大上下文長度的限制,提示符不可能包含所有相關的模型信息。為了解決這個問題,我們首先根據它們的任務類型過濾掉模型,只保留那些與當前任務類型匹配的模型。對于這些選定的模型,我們將根據它們在hug Face上的下載次數對它們進行排名(我們認為下載可以在一定程度上反映模型的質量),然后選擇top-K的模型作為HuggingGPT的候選模型。此策略可以大大減少提示中的令牌使用,并有效地為每個任務選擇適當的模型。
3.任務執行:調用并執行每個選定的模型,并將結果返回給ChatGPT。
一旦將特定的模型分配給已解析的任務,下一步就是執行該任務,即執行模型推理。因此,在這個階段,HuggingGPT會自動將這些任務參數輸入到模型中,執行這些模型來獲得推理結果,然后將其發送回LLM。在這個階段有必要強調資源依賴的問題。由于先決條件任務的輸出是動態生成的,因此HuggingGPT還需要在啟動任務之前動態地指定任務的依賴資源。
4.響應生成:最后,利用ChatGPT整合所有模型的預測并為用戶生成響應。
在所有任務執行完成后,HuggingGPT需要生成最終響應。HuggingGPT將前三個階段(任務規劃、模型選擇和任務執行)的所有信息集成為這一階段的簡明總結,包括計劃任務列表、任務選擇的模型以及模型的推斷結果。其中最重要的是推理結果,這是HuggingGPT做出最終決策的關鍵點。這些推理結果以結構化的格式呈現,如對象檢測模型中帶有檢測概率的邊界框,問答模型中的答案分布等。HuggingGPT允許LLM接收這些結構化的推理結果作為輸入,并以友好的人類語言形式生成響應。此外,LLM不是簡單地聚合結果,而是生成主動響應用戶請求的響應,從而提供具有置信度的可靠決策。
整體流程如下圖所示:語言是llm(例如ChatGPT)連接眾多AI模型(例如hugs Face)的接口,用于解決復雜的AI任務。在這個概念中,LLM作為一個控制器,管理和組織專家模型的合作。LLM首先根據用戶請求規劃任務列表,然后為每個任務分配專家模型。專家執行任務后,LLM收集結果并響應用戶。
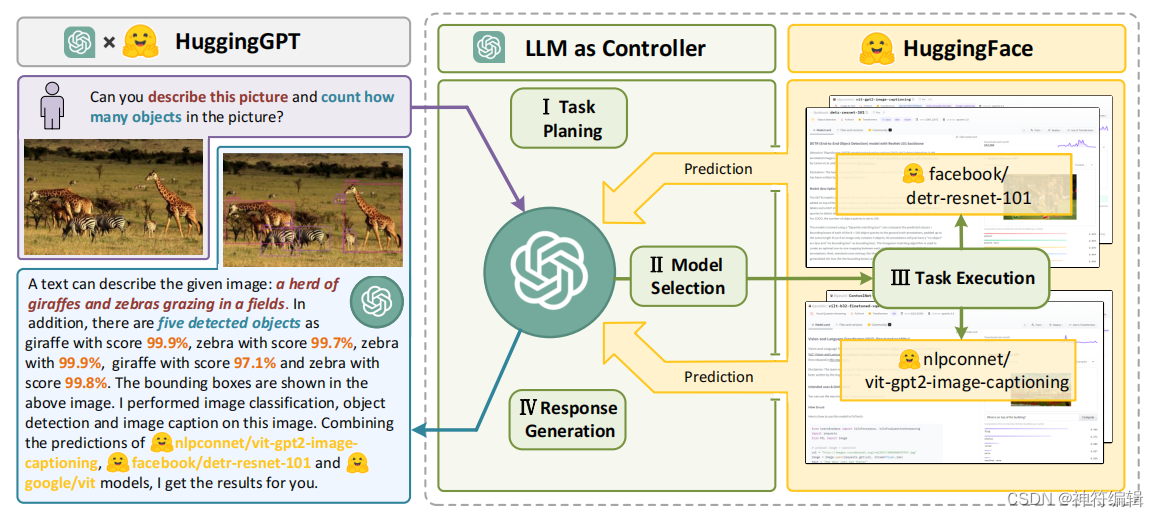
一個huggingGPT的例子,如下圖所示。HuggingGPT的工作流程以LLM(如ChatGPT)為核心控制器,專家模型為執行者,分為四個階段:1)任務規劃:LLM將用戶請求解析為任務列表,確定任務之間的執行順序和資源依賴關系;2)模型選擇:基于專家模型在hug Face上的描述,LLM為任務分配合適的模型;3)任務執行:混合端點上的專家模型執行分配的任務;4)響應生成:LLM集成專家的推理結果,生成工作流日志匯總,響應用戶。

局限性:
(1)HuggingGPT中的規劃嚴重依賴于LLM的能力。因此,我們不能保證生成的計劃總是可行和最優的。因此,如何對LLM進行優化,提高LLM的規劃能力至關重要;
(2) 在我們的框架中,效率是一個共同的挑戰。為了構建這樣一個具有任務自動化的協作系統(例如HuggingGPT),它嚴重依賴于一個強大的控制器(例如ChatGPT)。然而,HuggingGPT在整個工作流程中需要與llm進行多次交互,從而增加了生成響應的時間成本;
(3)令牌長度是使用LLM時的另一個常見問題,因為最大令牌長度總是有限的。雖然有些作品已經將最大長度擴展到32K,但如果我們想要連接眾多的模型,這對我們來說仍然是無法滿足的。因此,如何簡單有效地總結模型描述也是值得探索的問題;
(4)不穩定性的主要原因是llm通常是不可控的。雖然LLM在生成方面很熟練,但在預測過程中仍有可能不符合指令或給出不正確的答案,導致程序工作流程出現異常。如何減少推理過程中的不確定性是設計系統時必須考慮的問題。


ABC)





——Centos7安裝maven)







)


)