
ReadPaper https://readpaper.com/pdf-annotate/note?pdfId=4748421678288076801?eId=1920373270663763712?
https://readpaper.com/pdf-annotate/note?pdfId=4748421678288076801?eId=1920373270663763712?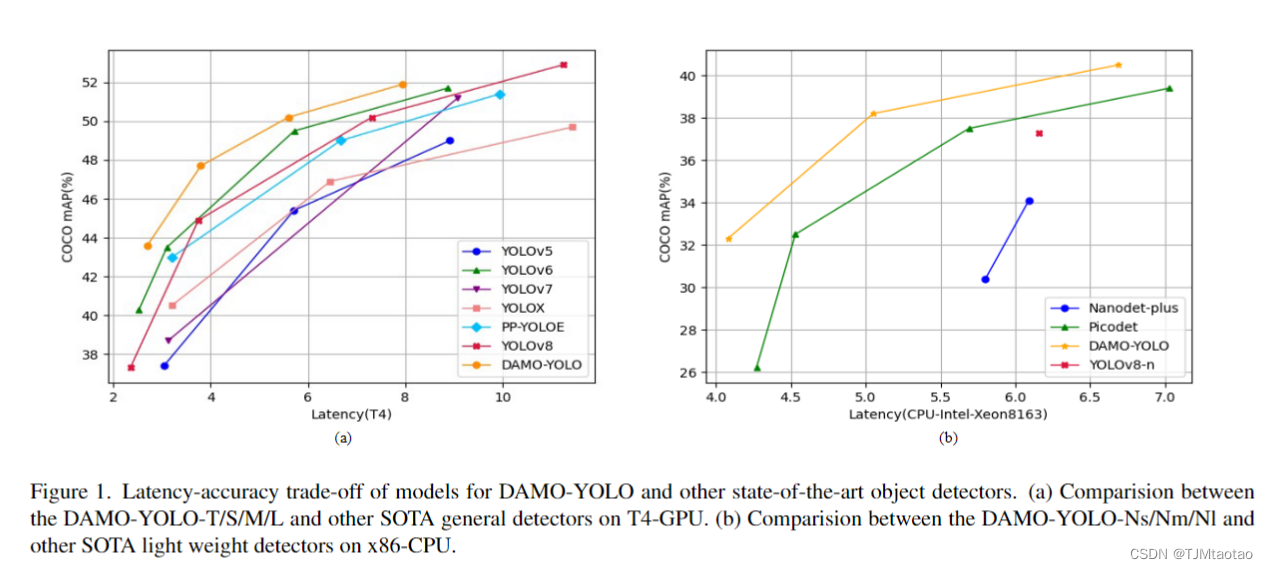
Abstract?
在本報告中,我們提出了一種快速準確的目標檢測方法,稱為DAMO-YOLO,它比最先進的YOLO系列實現了更高的性能。DAMO-YOLO 通過一些新技術從 YOLO 擴展,包括神經架構搜索 (NAS)、高效的重新參數化廣義 FPN (RepGFPN)、具有 AlignedOTA 標簽分配的輕量級頭和蒸餾增強。特別是,我們使用 MAE-NAS,一種由最大熵原理指導的方法,在低延遲和高性能約束下搜索我們的檢測主干,生成具有空間金字塔池和焦點模塊的類似 ResNet / CSP 的結構。在頸部和頭部的設計中,我們遵循“大頸部、小頭部”的規則。導入具有加速后融合的廣義FPN構建檢測器頸部,并通過高效的層聚合網絡(ELAN)和重新參數化升級其CSPNet。然后我們研究檢測器頭部大小會如何影響檢測性能,發現只有一個任務投影層的重頸部會產生更好的結果。此外,提出了AlignedOTA來解決標簽分配中的錯位問題。并引入蒸餾模式以將性能提高到更高的級別。基于這些新技術,我們構建了一套不同尺度的模型,以滿足不同場景的需求。對于一般行業要求,我們提出了 DAMO-YOLO-T/S/M/L。它們可以在COCO上實現43.6/47.7/50.2/51.9 mAP,在T4 GPU上延遲分別為2.78/3.83/5.62/7.95 ms。此外,對于計算能力有限的邊緣設備,我們還提出了DAMO-YOLO-Ns/Nm/Nl輕量級模型。它們可以在COCO上實現32.3/38.2/40.5 mAP,在X86-CPU上延遲為4.08/5.05/6.69 ms。我們提出的通用和輕量級模型在各自的應用場景上都優于其他 YOLO 系列模型。該代碼可在 https://github.com/tinyvision/damo-yolo?獲得。
?1. Introduction
最近,研究人員在巨大的進展中開發了對象檢測方法[1,9,11,23,24,27,33]。雖然該行業追求具有實時約束的高性能目標檢測方法,但研究人員專注于設計具有高效網絡架構 [4,16,17,29,30] 和高級訓練階段的一級檢測器 [1,22–24,26]。特別是YOLOv5/6/7[18,32,34]、YOLOX[9]和PP-YOLOE[38]在COCO上取得了顯著的AP-Latency權衡,使得YOLO系列目標檢測方法在工業中得到了廣泛的應用。
盡管目標檢測取得了很大進展,但仍有一些新技術可以進一步提高性能。首先,網絡結構在目標檢測中起著至關重要的作用。暗網在 YOLO 歷史 [1, 9, 24- 26, 32] 的早期階段占有主要地位。最近,一些作品調查了其他有效的網絡用于它們的檢測器,即 YOLOv6 [18] 和 YOLOv7。但是,這些網絡仍然是手動設計的。由于神經架構搜索 (NAS) 的發展,NAS 技術 [4, 16, 30] 可以找到許多對檢測友好的網絡結構,這與以前的手動設計的網絡相比具有很強的優越性。因此,我們利用 NAS 技術并將 MAE-NAS [30]1 導入我們的 DAMOYOLO。MAE-NAS 是一種啟發式和無訓練神經架構搜索方法,沒有 supervised 依賴,可用于在不同尺度上存檔主干。它可以生成具有空間金字塔池化和焦點模塊的類似 ResNet / CSP 的結構。
其次,檢測器在高級語義和低級空間特征之間學習足夠的融合信息至關重要,這使得檢測器頸部成為整個框架的重要組成部分。在其他著作[10,17,31,36]中也討論了頸部的重要性。特征金字塔網絡(FPN)[10]已被證明可以有效地融合多尺度特征。廣義FPN (GFPN)[17]通過一種新的女王融合改進了FPN。在DAMO-YOLO,我們設計了一個重新參數化的廣義FPN (RepGFPN)。它基于 GFPN,但涉及加速后融合、高效層聚合網絡 (ELAN) 和重新參數化。
為了在延遲和性能之間取得平衡,我們進行了一系列實驗來驗證檢測器頸部和頭部的重要性,發現“大頸部、小頭部”會導致更好的性能。因此,我們在以前的 YOLO 系列工作中丟棄了檢測器頭 [1, 9, 24-26, 32, 38],但只留下任務投影層。保存的計算被移動到頸部部分。除了任務投影模塊外,頭部沒有其他訓練層,因此我們將檢測器頭命名為 ZeroHead。結合我們的 RepGFPN,ZeroHead 實現了最先進的性能,我們相信這將為其他研究人員提供一些見解。
此外,與靜態標簽分配[43]相比,OTA[8]和TOOD[7]等動態標簽分配得到了廣泛的宣稱,取得了顯著的改進。然而,這些工作仍未解決錯位問題。我們提出了一種名為 AlignOTA 的更好解決方案來平衡分類和回歸的重要性,這可以部分解決這個問題。
最后,知識蒸餾 (KD) 已被證明在通過更大的模型監督來增強小型模型方面是有效的。該技術完全符合實時目標檢測的設計。然而,在 YOLO 系列上應用 KD 有時并不能取得顯著的改進,因為超參數很難優化,并且特征攜帶太多噪聲。在我們的 DAMO-YOLO 中,我們首先在所有大小的模型上再次進行蒸餾,尤其是在小型模型上。
如圖1所示,通過上述改進,我們提出了一系列通用和輕量級的模型,大大超過了現有技術。總之,貢獻有三方面:
1.本文提出了一種新的檢測器DAMOYOLO,它擴展了YOLO,但有了更多的新技術,包括MAE-NAS主干、RepGFPN頸部、ZeroHead、AlignedOTA和蒸餾增強。
2. DAMO-YOLO 在通用類別和輕量級類別的公共 COCO 數據集上優于最先進的檢測器(例如 YOLO 系列)。
3.DAMO-YOLO (tiny/small/medium)提出了一套不同尺度的模型來支持不同的部署。代碼和預訓練模型在 https://github.com/tinyvision/damooyolo 上發布,支持 ONNX 和 TensorRT。
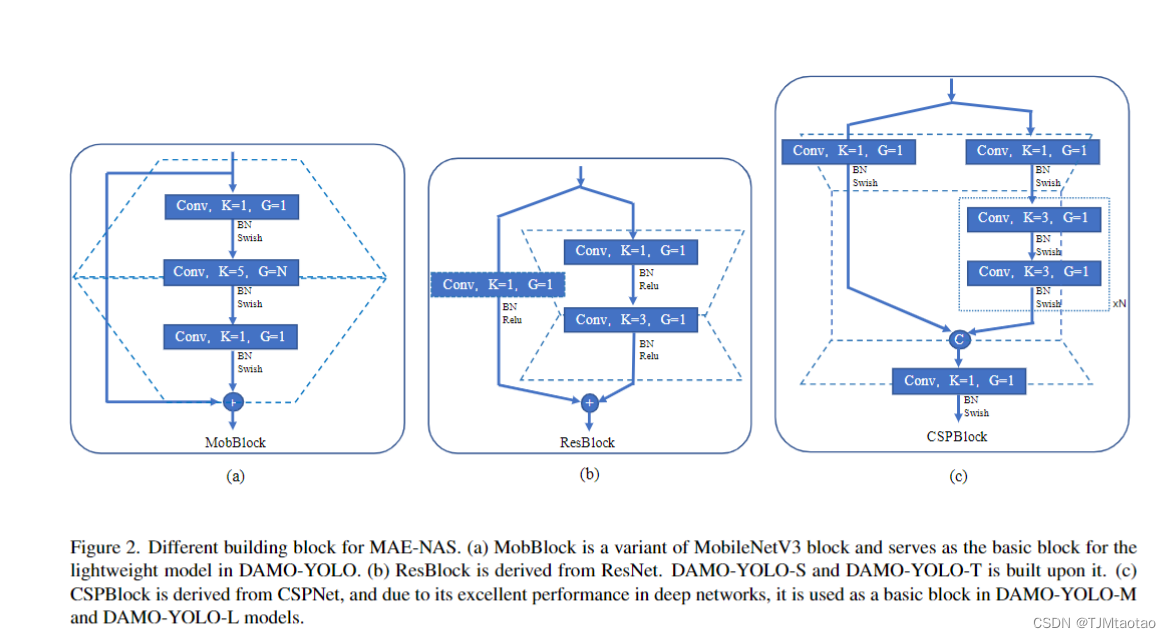
?圖 2. MAE-NAS 的不同構建塊。(a) MobBlock是MobileNetV3塊的變體,是DAMO-YOLO中輕量級模型的基本塊。(b) ResBlock 源自 ResNet。DMO-YOLO-S 和 DMO-YOLO-T 建立在它之上。(c) CSPBlock來源于CSPNet,由于其在深度網絡中的優越性能,它被用作DAMO-YOLO-M和DAMO-YOLO-L模型中的基本塊。
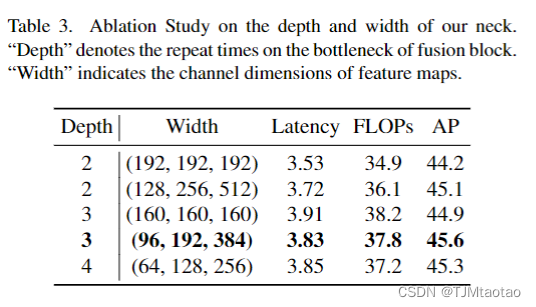
表3。頸部深度和寬度的消融研究。“深度”表示融合塊瓶頸上的重復時間。“Width”表示特征圖的通道維度。
2. DAMO-YOLO
在本節中,我們將詳細介紹DAMOYOLO的每個模塊,包括神經架構搜索(NAS)主干、高效的重新參數化廣義FPN (RepGFPN)頸部、ZeroHead、AlignedOTA標簽分配和蒸餾增強。DAMO-YOLO的整個框架如圖3所示。
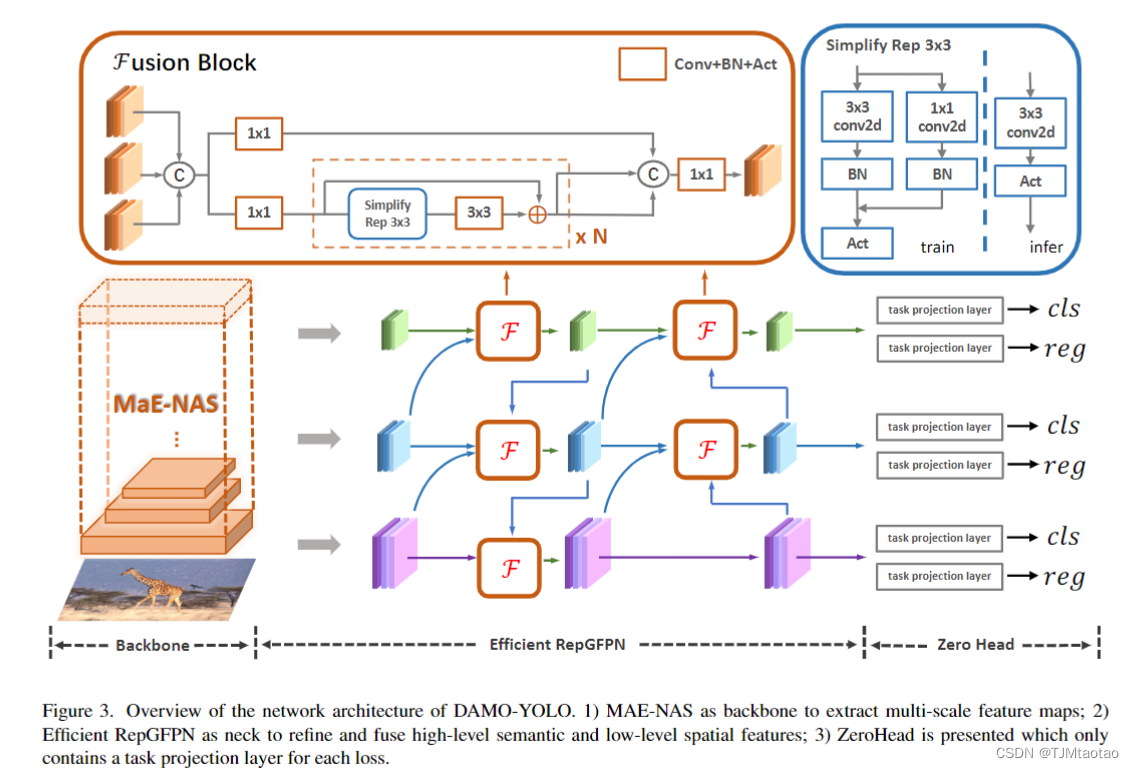
圖3。DAMO-YOLO網絡架構概述。1) MAE-NAS作為骨干提取多尺度特征圖;2)高效RepGFPN作為頸部,對高級語義和底層空間特征進行細化和融合;3)提出了ZeroHead,它只為每個損失包含一個任務投影層。?
2.1. MAE-NAS Backbone
以前,在實時場景中,設計師依靠Flops-MAP曲線作為評估模型性能的簡單方法。然而,模型的失敗和延遲之間的關系不一定是一致的。為了提高模型在工業部署中的實際性能,DAMO-YOLO在設計過程中優先考慮延遲-MAP曲線。
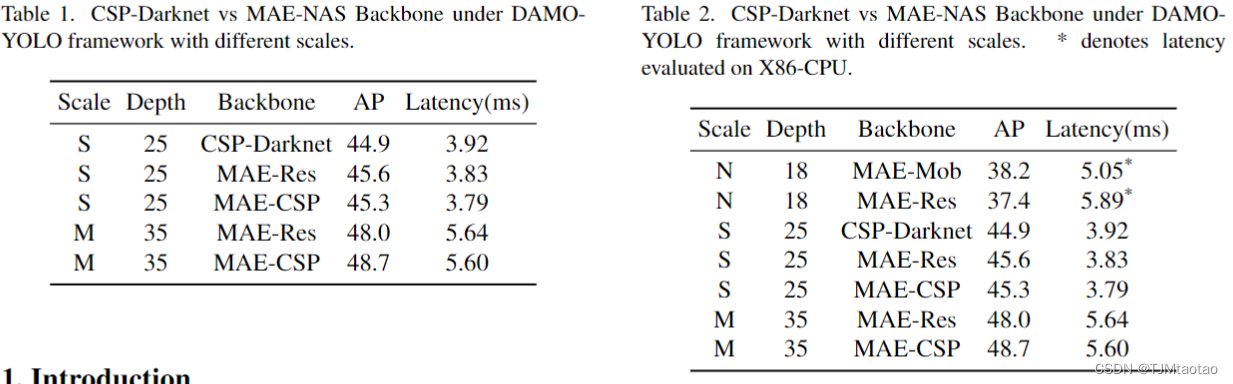
基于這一設計原則,我們使用MAE-NAS[30]在不同的延遲預算下獲得最佳網絡。MAE-NAS 構建了一個基于信息論的替代代理,以在沒有訓練的情況下對初始化網絡進行排名。因此,搜索過程只需要幾個小時,遠低于訓練成本。MAE-NAS提供了幾個基本搜索塊,如Mob-block、Res-block和CSP-block,如圖2所示。Mobblock是MobileNetV3[14]塊的變體,Res-block來源于ResNet[12],CSP-block來源于CSPNet[35]。完整的支持塊列表可以在 MAE-NAS 存儲庫 2 中找到。
我們發現,在不同尺度的模型中應用不同類型的塊可以更好地權衡實時推理。表1列出了CSPDarknet和我們的MAE-NAS骨干在不同尺度下的性能比較。在此表中,“MAE-Res”表示我們在MAENAS主干中應用Res-block,“MAE-CSP”表示我們在其中應用CSPblock。此外,“S”(Small)和“M”(Medium)代表不同尺度的主干。如表1所示,
MAE-NAS技術獲得的MAE-CSP在速度和精度方面都優于手動設計的CSP-Darknet,證明了MAE-NAS技術的優越性。此外,從表1可以觀察到,在較小的模型上使用Res-block可以在性能和速度之間取得比CSP-block更好的權衡,而使用CSP-block可以在更大更深的網絡上顯著優于Resblock。因此,我們在最終設置中的“T”(Tiny)和“S”模型中使用“MAE-Res”,在“M”和“L”模型中使用“MAE-CSP”。在處理計算能力或 GPU 有限的場景時,擁有滿足計算速度和速度嚴格要求的模型至關重要。為了解決這個問題,我們設計了一系列使用 Mob-Block 的輕量級模型。Mob-block來源于MobleNetV3[14],可以顯著減少模型計算,對CPU設備友好。
2.2.高效RepGFPN
特征金字塔網絡旨在聚合從主干中提取的不同分辨率的特征,這已被證明是目標檢測的關鍵有效部分[10,31,36]。傳統的FPN[10]引入了一種自頂向下的路徑來融合多尺度特征。考慮到單向信息流的局限性,PAFPN[36]增加了一個額外的自底向上路徑聚合網絡,但計算成本更高。BiFPN [31] 刪除了只有一個輸入邊的節點,并在同一級別上從原始輸入中添加 skiplink。在[17]中,提出了廣義FPN (GFPN)作為頸部,實現了SOTA性能,因為它可以充分交換高級語義信息和低級空間信息。在 GFPN 中,多尺度特征在前一層和當前層的兩級特征融合。更重要的是,log2(n) skip-layer 連接提供了更有效的信息傳輸,可以擴展到更深的網絡。當我們在現代 YOLO 系列模型中直接用 GFPN 替換修改后的 PANet 時,我們實現了更高的精度。然而,GFPN-的延遲基于模型遠高于基于修改panet的模型。通過分析GFPN的結構,其原因可以歸結為以下幾個方面:1)不同尺度的特征圖共享相同的信道維數;2)女王融合操作不能滿足實時檢測模型的要求;3)基于卷積的跨尺度特征融合效率不高。
基于 GFPN,我們提出了一種新穎的 Efficient-RepGFPN 來滿足實時目標檢測的設計,主要包括以下見解:1)由于不同尺度特征圖的 FLOP 差異很大,在有限的計算成本約束下很難控制每個尺度特征圖共享的相同維度通道。因此,在我們的頸部的特征融合中,我們采用了不同通道尺寸不同尺度特征圖的設置。比較了相同和不同通道的性能以及頸部深度和寬度權衡的精度優勢,表3顯示了結果。我們可以看到,通過靈活控制不同尺度的通道數,我們可以達到比在所有尺度上共享相同的通道更高的精度。當深度等于 3 且寬度等于 (96, 192, 384) 時,可以獲得最佳性能。2) GFPN通過女王融合增強了特征交互,但它也帶來了大量額外的上采樣和下采樣算子。比較了這些上采樣和下采樣算子的優點,結果如表4所示。我們可以看到,額外的上采樣算子導致延遲增加0.6ms,而精度提高僅為0.3mAP,遠遠小于額外的下采樣算子的好處。因此,在實時檢測的約束下,我們刪除了女王融合的額外上采樣操作。3)在特征融合塊中,我們首先將原始的基于3x3的卷積特征融合替換為CSPNet,得到4.2 mAP增益。之后,我們通過結合高效層聚合網絡(ELAN)[34]的重新參數化機制和連接來升級CSPNet。在不帶來額外的巨大計算負擔的情況下,我們實現了更高的精度。比較結果如表5所示。

 ?
?
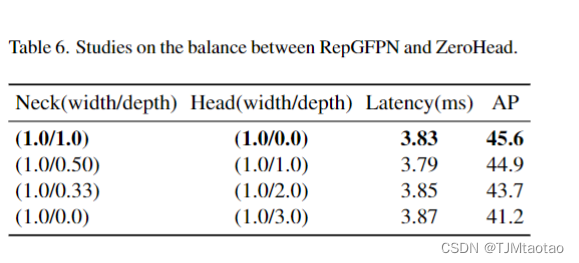
2.3. ZeroHead and AlignOTA?
在目標檢測的最新進展中,解耦頭被廣泛使用[9,18,38]。使用解耦的頭部,這些模型實現了更高的 AP,而延遲顯著增加。為了權衡延遲和性能,我們進行了一系列實驗來平衡頸部和頭部的重要性,結果如表6所示。在實驗中,我們發現“大頸部、小頭部”會帶來更好的性能。因此,我們在以前的作品 [9, 18, 38] 中丟棄了解耦的頭部,但只留下任務投影層,即用于分類的線性層和用于回歸的線性層。我們將頭部命名為 ZeroHead,因為我們的頭部沒有其他訓練層。ZeroHead 可以最大程度地節省大量 RepGFPN 頸部的計算。值得注意的是,ZeroHead本質上可以被認為是耦合頭,這與其他作品中的解耦頭有很大的不同[9,18,32,38]。在頭部后的損失中,在GFocal[20]之后,我們使用質量焦點損失(QFL)進行分類監督,并使用分布焦點損失(DFL)和GIOU損失進行回歸監督。QFL 鼓勵學習分類和定位質量的聯合表示。DFL 通過將位置建模為一般分布來提供更多信息和更精確的邊界框估計。提出的DAMO-YOLO的訓練損失公式為:
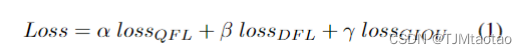
除了頭部和損失,標簽分配是檢測器訓練期間的至關重要的組件,負責將分類和回歸目標分配給預定義的錨點。最近,OTA[8]和TOOD[7]等動態標簽分配得到了廣泛的宣稱,與靜態標簽分配[43]相比,取得了顯著的改進。動態標簽分配方法根據預測和基本事實之間的分配成本分配標簽,例如OTA[8]。雖然分類和回歸在損失中的對齊已被廣泛研究 [7, 20],但在目前的工作中很少提及標簽分配中的分類和回歸之間的對齊。分類和回歸的錯位是靜態分配方法中的一個常見問題[43]。雖然動態分配緩解了這個問題,但由于分類和回歸損失的不平衡,如CrossEntropy和IoU Loss[40]仍然存在。為了解決這個問題,我們將焦點損失 [22] 引入分類成本,并使用預測框和地面實況框的 IoU 作為軟標簽,公式如下:
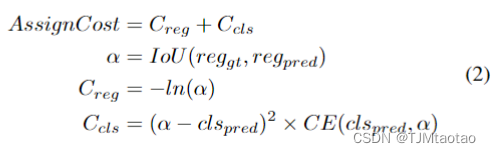 ?
?
 ?
?
通過這個公式,我們能夠為每個目標選擇分類和回歸對齊樣本。除了對齊的分配成本,在 OTA [8] 之后,我們從全局角度形成對齊分配成本的解決方案。我們將標簽分配命名為 AlignOTA。標簽分配方法的比較如表7所示。我們可以看到AlignOTA優于所有其他標簽分配方法。?
2.4. Distillation Enhancement(蒸餾增強)
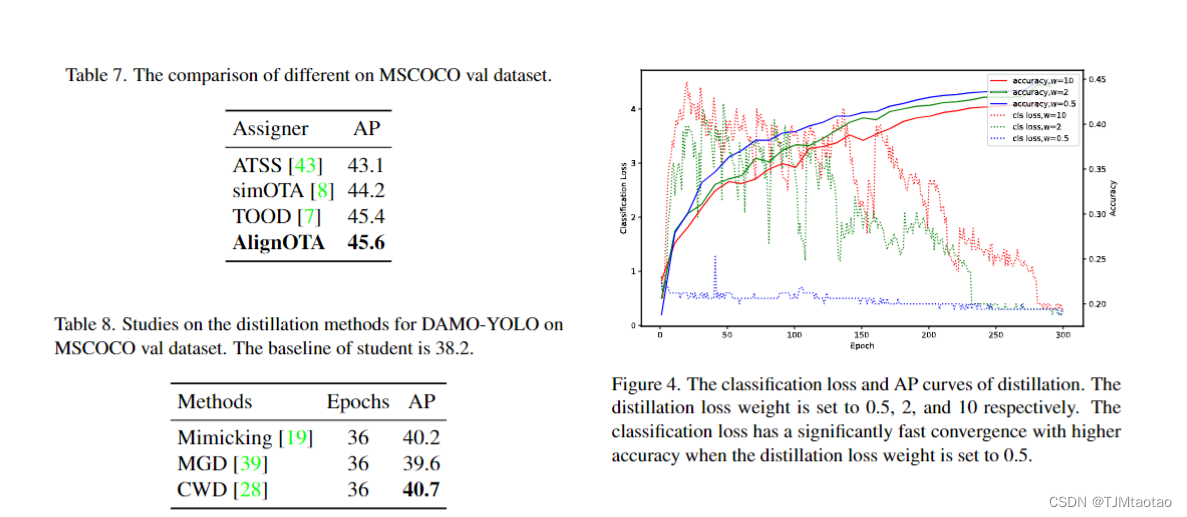
知識蒸餾(KD)[13]是進一步提高口袋尺寸模型的性能的有效方法。然而,在 YOLO 系列上應用 KD 有時并不能取得顯著的改進,因為超參數很難優化,并且特征攜帶太多噪聲。在 DAMO-YOLO 中,我們首先在所有大小的模型上再次進行蒸餾,尤其是在小尺寸上。我們采用基于特征的蒸餾來傳遞黑暗知識,可以提取中間特征圖[15]中的識別和定位信息。我們進行快速驗證實驗,為我們的DAMO-YOLO選擇合適的蒸餾方法。結果如表 8 所示。我們得出結論,CWD 更適合我們的模型,而 MGD 比模仿復雜超參數更差,使其不夠通用。
我們提出的蒸餾策略分為兩個階段:1)我們的老師在第一階段(284 個 epoch)提取學生,在強大的馬賽克域上。面對具有挑戰性的增強數據分布,學生可以在教師指導下平滑地提取信息。2) 學生在第二階段沒有馬賽克域上微調自己(16 個 epoch)。我們在這個階段不采用蒸餾的原因是,在如此短的時間內,當老師想要將學生拉在一個奇怪的領域(即沒有馬賽克領域)時,老師的經驗會損害學生的表現。長期蒸餾會削弱損傷,但成本很高。因此,我們選擇權衡來使學生獨立。
在 DAMO-YOLO 中,蒸餾配備了兩個高級增強:1)對齊模塊。一方面,它是一個線性投影層,使學生特征適應與教師相同的分辨率 (C, H, W )。另一方面,與自適應相比,強迫學生直接逼近教師特征和學生特征會帶來很小的收益,為了削弱真實值差異帶來的效果。在減去平均值后,每個通道的標準偏差將作為 KL 損失中的溫度系數發揮作用。
?
 ?
?
?4. Comparison with the SOTA
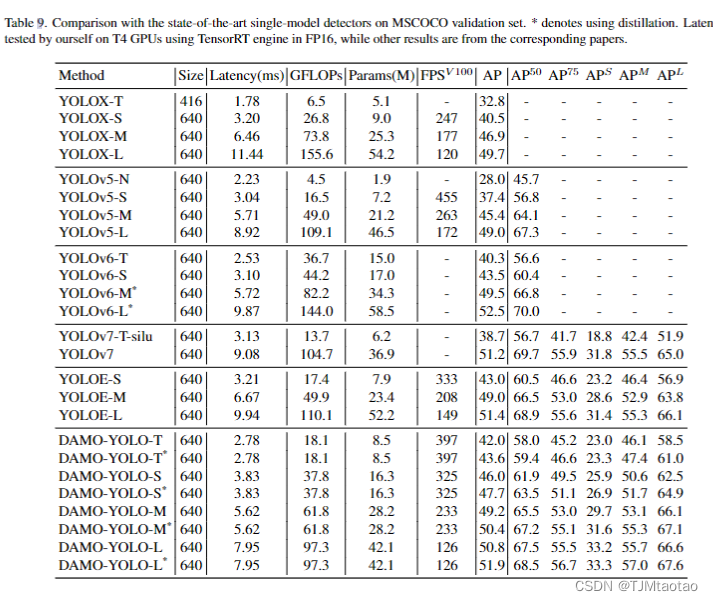
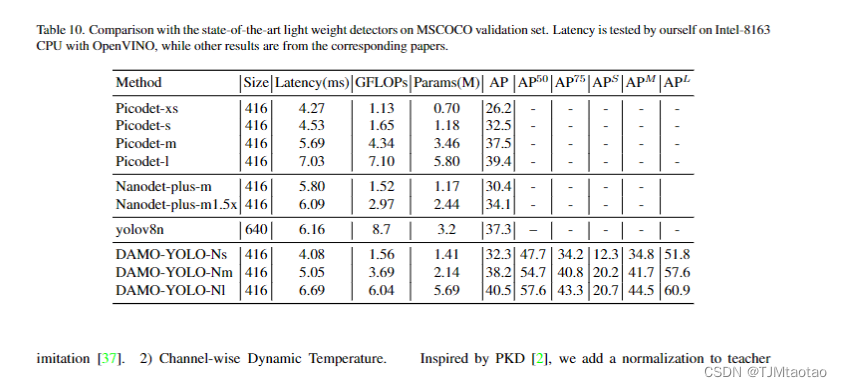
DMO-YOLO 發布了一系列通用模型和輕量級模型,同時滿足一般場景和資源有限的邊緣場景。為了評估 DAMO-YOLO 通用模型相對于其他最先進模型的性能,我們使用 TensorRT-FP16 推理引擎對 T4-GPU 進行了比較分析。結果如表9所示,表明DAMO-YOLO的一般模型在精度和速度方面都優于競爭對手。此外,我們提出的蒸餾技術顯著提高了準確性。為了評估輕量級模型的性能,我們使用 Openvino 作為推理引擎對 Intel-8163 CPU 進行了比較分析。如表2所示,DAMO-YOLO的輕量級模型取得了實質性的領先優勢,在速度和準確性方面都大大超過了競爭對手。
)












![GPU Microarch 學習筆記 [1]](http://pic.xiahunao.cn/GPU Microarch 學習筆記 [1])

B題題解)



