1.什么是狀態
官方定義:當前計算流程需要依賴到之前計算的結果,那么之前計算的結果就是狀態。
這句話還是挺好理解的,狀態不只存在于Flink,也存在生活的方方面面,比如看到一個認識的人,如何識別認識呢?就是眼睛看到這個人的樣子,再和大腦記憶中的人做對比,就知道認識這個人,其中大腦記憶中的人就是存儲在狀態中。
狀態又分為無狀態和有狀態。
- 無狀態:例如消費延遲計算,單條輸入包含所有的信息,不依賴于歷史消息。在這種模式的計算中,無論這條輸入進來多少次,輸出的結果都是一樣的,因為單條輸入中已經包含了所需的所有信息。消費落后等于生產者減去消費者。生產者的消費在單條數據中可以得到,消費者的數據也可以在單條數據中得到,所以相同輸入可以得到相同輸出,這就是一個無狀態的計算。
- 有狀態:例如訪問量統計,單條輸入僅包含部分信息,依賴歷史消息。這種模式是將數據輸入算子中,用來進行各種復雜的計算并輸出數據。這個過程中算子會去訪問之前存儲在里面的狀態。另外一方面,它還會把現在的數據對狀態的影響實時更新,如果輸入100 條數據,最后輸出就是 100 條結果。
2.狀態應用場景
通常以下4種場景會用到狀態:
- 去重:比如上游的系統數據可能會有重復,落到下游系統時希望把重復的數據都去掉。去重需要先了解哪些數據來過,哪些數據還沒有來,也就是把所有的主鍵都記錄下來,當一條數據到來后,能夠看到在主鍵當中是否存在。
- 窗口計算:比如統計每分鐘 Nginx 日志 API 被訪問了多少次。窗口是一分鐘計算一次,在窗口觸發前,如 08:00 ~ 08:01 這個窗口,前59秒的數據來了需要先放入內存,即需要把這個窗口之內的數據先保留下來,等到 8:01 時一分鐘后,再將整個窗口內觸發的數據輸出。未觸發的窗口數據也是一種狀態。
- 機器學習/深度學習:如訓練的模型以及當前模型的參數也是一種狀態,機器學習可能每次都用有一個數據集,需要在數據集上進行學習,對模型進行一個反饋。
- 訪問歷史數據:比如與昨天的數據進行對比,需要訪問一些歷史數據。如果每次從外部去讀,對資源的消耗可能比較大,所以也希望把這些歷史數據也放入狀態中做對比。
3.狀態管理
實時計算中的狀態的功能主要體現在任務可以做到失敗重啟后沒有數據質量、時效問題。
- 數據質量問題:當實時任務掛掉后,從消息失敗offset位置開始消費,數據就錯誤。
- 數據時效問題:實時任務要求有時效性,當從源offset開始位置運行時,需要好幾個小時才能追上當前offset。時效性就很差。
針對以上問題,就引出了狀態管理。
當我們把數據定期(例如每隔10min)的給存儲到 HDFS 上面時,任務掛了、恢復之后。我們的任務還可以從 HDFS 上面把這個數據給讀回來,接著從最新的一個 Kafka Offset 繼續計算就可以,這樣既沒沒有數據質量問題,也沒有數據時效性問題。
因此,實時計算中提到的狀態的概念重點不止在于狀態本身,更重要的在于強調 "管理" 狀態。
基于上述,狀態管理對流式作業的要求總結如下:
- 7*24小時運行,高可靠;
- 數據不丟不重,恰好計算一次;
- 數據實時產出,不延遲;
但是基于以上要求,內存的管理就會出現一些問題。由于內存的容量是有限制的。如果要做 24 小時的窗口計算,將 24 小時的數據都放到內存,可能會出現內存不足;另外,作業是 7*24,需要保障高可用,機器若出現故障或者宕機,需要考慮如何備份及從備份中去恢復,保證運行的作業不受影響;此外,考慮橫向擴展,假如網站的訪問量不高,統計每個 API 訪問次數的程序可以用單線程去運行,但如果網站訪問量突然增加,單節點無法處理全部訪問數據,此時需要增加幾個節點進行橫向擴展,這時數據的狀態如何平均分配到新增加的節點也問題之一。因此,將數據都放到內存中,并不是最合適的一種狀態管理方式。
最理想的狀態管理需要滿足易用、高效、可靠三點需求:
- 易用,Flink 提供了豐富的數據結構、多樣的狀態組織形式以及簡潔的擴展接口,讓狀態管理更加易用;
- 高效,實時作業一般需要更低的延遲,一旦出現故障,恢復速度也需要更快;當處理能力不夠時,可以橫向擴展,同時在處理備份時,不影響作業本身處理性能;
- 可靠,Flink 提供了狀態持久化,包括不丟不重的語義以及具備自動的容錯能力,比如 HA,當節點掛掉后會自動拉起,不需要人工介入。
4.狀態后端
做狀態數據(持久化,restore)的工具就叫做狀態后端。比如在 Flink 中見到的 RocksDB、FileSystem 的概念就是指狀態后端。這些狀態后端就是實際存儲上面的狀態數據的。比如配置了 RocksDB 作為狀態后端,MapState 的數據就會存儲在 RocksDB 中。
總的來說可以這么理解:應用中有一份狀態數據,把這份狀態數據存儲到 MySQL 中,這個 MySQL 就能叫做狀態后端。
5.Checkpoint和Savepoint
概念:協調整個任務 when,how 去將 Flink 任務本地機器中存儲在狀態后端的狀態去同步到遠程文件存儲系統(比如 HDFS)的過程就叫 Checkpoint、Savepoint。
Flink 狀態保存主要依靠 Checkpoint 機制,Checkpoint 會定時制作分布式快照,對程序中的狀態進行備份。分布式快照 Checkpoint 完成后,當作業發生故障了如何去恢復?假如作業分布跑在 3 臺機器上,其中一臺掛了。這個時候需要把進程或者線程移到 active 的 2 臺機器上,此時還需要將整個作業的所有 Task 都回滾到最后一次成功 Checkpoint 中的狀態,然后從該點開始繼續處理。
Checkpoint流程如下:
- JM 定時調度 Checkpoint 的觸發:JM CheckpointCoorinator 定時觸發,CheckpointCoordinator 會去通過 RPC 接口調用 Source 算子的 TM 的 StreamTask 告訴 TM 可以開始執行 Checkpoint 了。
- Source 算子:接受到 JM 做 Checkpoint 的請求后,開始做本地 Checkpoint,本地執行完成之后,發 barrier 給下游算子。barrier 發送策略是隨著 partition 策略走,將 barrier 發往連接到的所有下游算子(舉例:keyby 就是廣播,forward 就是直接送)。
- 剩余的算子:接收到上游所有 barrier 之后進行觸發 Checkpoint。當一個算子接收到上游一個 channel 的 barrier 之后,就停止處理這個 input channel 來的數據(本質上就是不會再去影響狀態了)
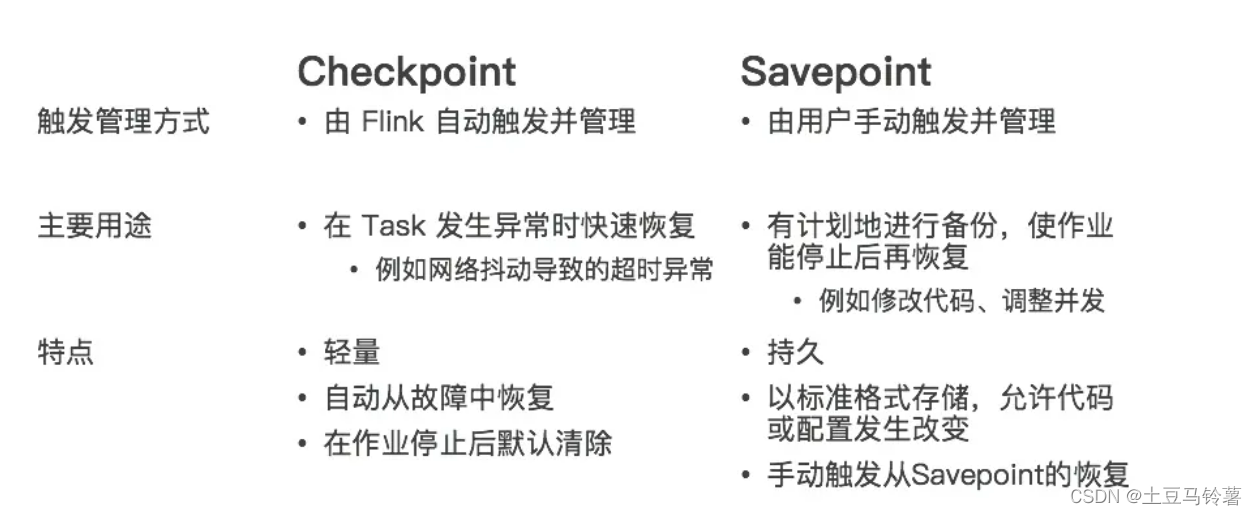
Savepoint 與 Checkpoint 類似,同樣是把狀態存儲到外部介質。當作業失敗時,可以從外部恢復。主要區別如下:















報錯問題解決)



