1.什么是多級緩存
傳統的緩存策略一般是請求到達Tomcat后,先查詢Redis,如果未命中則查詢數據庫,如圖:

存在下面的問題:
?請求要經過Tomcat處理,Tomcat的性能成為整個系統的瓶頸
?Redis緩存失效時,會對數據庫產生沖擊
多級緩存就是充分利用請求處理的每個環節,分別添加緩存,減輕Tomcat壓力,提升服務性能:
- 瀏覽器訪問靜態資源時,優先讀取瀏覽器本地緩存
- 訪問非靜態資源(ajax查詢數據)時,訪問服務端
- 請求到達Nginx后,優先讀取Nginx本地緩存
- 如果Nginx本地緩存未命中,則去直接查詢Redis(不經過Tomcat)
- 如果Redis查詢未命中,則查詢Tomcat
- 請求進入Tomcat后,優先查詢JVM進程緩存
- 如果JVM進程緩存未命中,則查詢數據庫

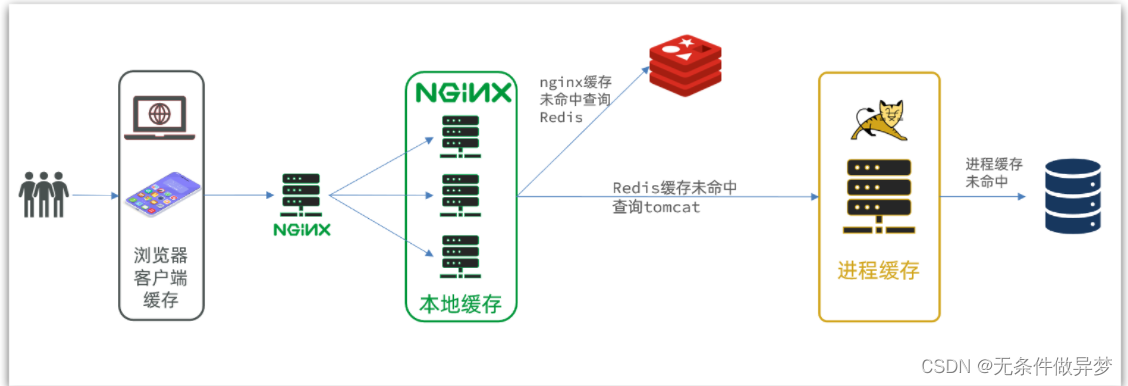
在多級緩存架構中,Nginx內部需要編寫本地緩存查詢、Redis查詢、Tomcat查詢的業務邏輯,因此這樣的nginx服務不再是一個反向代理服務器,而是一個編寫業務的Web服務器了。
因此這樣的業務Nginx服務也需要搭建集群來提高并發,再有專門的nginx服務來做反向代理,如圖:
另外,我們的Tomcat服務將來也會部署為集群模式:
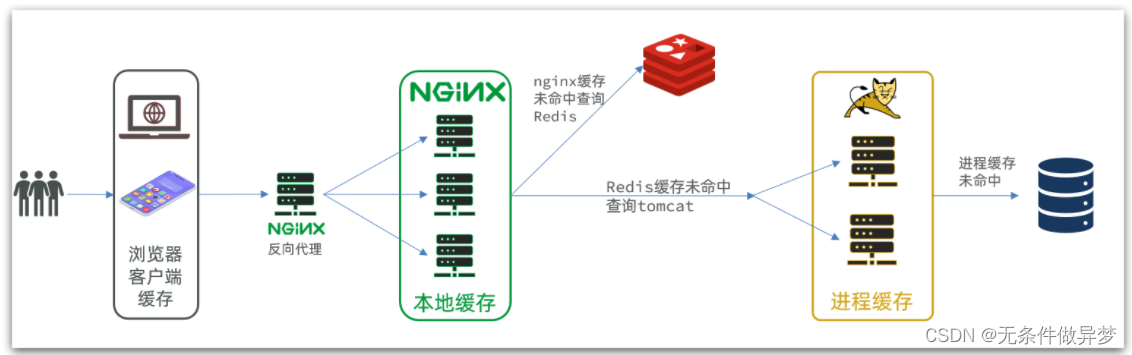
可見,多級緩存的關鍵有兩個:
-
一個是在nginx中編寫業務,實現nginx本地緩存、Redis、Tomcat的查詢
-
另一個就是在Tomcat中實現JVM進程緩存
其中Nginx編程則會用到OpenResty框架結合Lua這樣的語言。
2.JVM進程緩存
2.2.初識Caffeine
緩存在日常開發中啟動至關重要的作用,由于是存儲在內存中,數據的讀取速度是非常快的,能大量減少對數據庫的訪問,減少數據庫的壓力。我們把緩存分為兩類:
- 分布式緩存,例如Redis:
- 優點:存儲容量更大、可靠性更好、可以在集群間共享
- 缺點:訪問緩存有網絡開銷
- 場景:緩存數據量較大、可靠性要求較高、需要在集群間共享
- 進程本地緩存,例如HashMap、GuavaCache:
- 優點:讀取本地內存,沒有網絡開銷,速度更快
- 缺點:存儲容量有限、可靠性較低、無法共享
- 場景:性能要求較高,緩存數據量較小
利用Caffeine框架來實現JVM進程緩存。
Caffeine是一個基于Java8開發的,提供了近乎最佳命中率的高性能的本地緩存庫。目前Spring內部的緩存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
緩存使用的基本API:
@Test
void testBasicOps() {// 構建cache對象Cache<String, String> cache = Caffeine.newBuilder().build();// 存數據cache.put("gf", "迪麗熱巴");// 取數據String gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取數據,包含兩個參數:// 參數一:緩存的key// 參數二:Lambda表達式,表達式參數就是緩存的key,方法體是查詢數據庫的邏輯// 優先根據key查詢JVM緩存,如果未命中,則執行參數二的Lambda表達式String defaultGF = cache.get("defaultGF", key -> {// 根據key去數據庫查詢數據return "柳巖";});System.out.println("defaultGF = " + defaultGF);
}
Caffeine既然是緩存的一種,肯定需要有緩存的清除策略,不然的話內存總會有耗盡的時候。
Caffeine提供了三種緩存驅逐策略:
-
基于容量:設置緩存的數量上限
// 創建緩存對象 Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1) // 設置緩存大小上限為 1.build(); -
基于時間:設置緩存的有效時間
// 創建緩存對象 Cache<String, String> cache = Caffeine.newBuilder()// 設置緩存有效期為 10 秒,從最后一次寫入開始計時 .expireAfterWrite(Duration.ofSeconds(10)) .build(); -
基于引用:設置緩存為軟引用或弱引用,利用GC來回收緩存數據。性能較差,不建議使用。
注意:在默認情況下,當一個緩存元素過期的時候,Caffeine不會自動立即將其清理和驅逐。而是在一次讀或寫操作后,或者在空閑時間完成對失效數據的驅逐。
2.3.實現JVM進程緩存
2.3.1.需求
利用Caffeine實現下列需求:
- 給根據id查詢商品的業務添加緩存,緩存未命中時查詢數據庫
- 給根據id查詢商品庫存的業務添加緩存,緩存未命中時查詢數據庫
- 緩存初始大小為100
- 緩存上限為10000
2.3.2.實現
首先,我們需要定義兩個Caffeine的緩存對象,分別保存商品、庫存的緩存數據。
在item-service的com.heima.item.config包下定義CaffeineConfig類:
package com.heima.item.config;import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class CaffeineConfig {@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}@Beanpublic Cache<Long, ItemStock> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}
然后,修改item-service中的com.heima.item.web包下的ItemController類,添加緩存邏輯:
@RestController
@RequestMapping("item")
public class ItemController {@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;@Autowiredprivate Cache<Long, Item> itemCache;@Autowiredprivate Cache<Long, ItemStock> stockCache;// ...其它略@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id) {return itemCache.get(id, key -> itemService.query().ne("status", 3).eq("id", key).one());}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id) {return stockCache.get(id, key -> stockService.getById(key));}
}
3.Lua語法入門
Nginx編程需要用到Lua語言,因此我們必須先入門Lua的基本語法。
3.1.初識Lua
Lua 是一種輕量小巧的腳本語言,用標準C語言編寫并以源代碼形式開放, 其設計目的是為了嵌入應用程序中,從而為應用程序提供靈活的擴展和定制功能。官網:https://www.lua.org/
3.1.HelloWorld
CentOS7默認已經安裝了Lua語言環境,所以可以直接運行Lua代碼。
1)在Linux虛擬機的任意目錄下,新建一個hello.lua文件

2)添加下面的內容
print("Hello World!")
3)運行

3.2.變量和循環
3.2.1.Lua的數據類型
Lua中支持的常見數據類型包括:

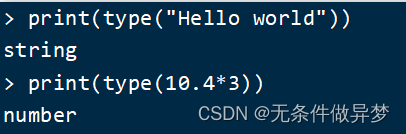
另外,Lua提供了type()函數來判斷一個變量的數據類型:
3.2.2.聲明變量
Lua聲明變量的時候無需指定數據類型,而是用local來聲明變量為局部變量:
-- 聲明字符串,可以用單引號或雙引號,
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 聲明數字
local num = 21
-- 聲明布爾類型
local flag = true
Lua中的table類型既可以作為數組,又可以作為Java中的map來使用。數組就是特殊的table,key是數組角標而已:
-- 聲明數組 ,key為角標的 table
local arr = {'java', 'python', 'lua'}
-- 聲明table,類似java的map
local map = {name='Jack', age=21}
Lua中的數組角標是從1開始,訪問的時候與Java中類似:
-- 訪問數組,lua數組的角標從1開始
print(arr[1])
Lua中的table可以用key來訪問:
-- 訪問table
print(map['name'])
print(map.name)
3.2.3.循環
對于table,我們可以利用for循環來遍歷。不過數組和普通table遍歷略有差異。
遍歷數組:
-- 聲明數組 key為索引的 table
local arr = {'java', 'python', 'lua'}
-- 遍歷數組
for index,value in ipairs(arr) doprint(index, value)
end
遍歷普通table
-- 聲明map,也就是table
local map = {name='Jack', age=21}
-- 遍歷table
for key,value in pairs(map) doprint(key, value)
end
3.3.條件控制、函數
Lua中的條件控制和函數聲明與Java類似。
3.3.1.函數
定義函數的語法:








報錯問題)

)
)





)
 模板方法設計模式)
