????????TRT8 一個大版本,8.4-、 8.5、 8.6(包含預覽功能)卻有很多變動,一不注意就發現很混亂,特備注此貼。建議具體case可以參考這個合集,真心安利:https://github.com/NVIDIA/trt-samples-for-hackathon-cn/tree/master/cookbook
版本差異概述
1)當前使用了8.4;
參考: https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/01-SimpleDemo/TensorRT8.0/main-cuda.py
2)8.5版本廢棄了binding, 導致開內存代碼不同;
參考: https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/01-SimpleDemo/TensorRT8.5/main.py
3)8.6版本以后支持dynamic shape統一個profile 用于不同的context。不再支持Pascal (P40),但完全改變了原來TRT engine必須綁定硬件和版本的要求, 現在可以解耦出來,但是有如下限制:

1、binding 改變
1)8.5前需要使用biding 接口
對應dynamic batch 多個profile 需要計算偏置。偏置或者說index 是針對profile (同一個engine)的不是針對context的。下圖是一個engine里有3個profile,模型有4個輸入1個輸出,那么就有(4+1)*3 =15個binding。
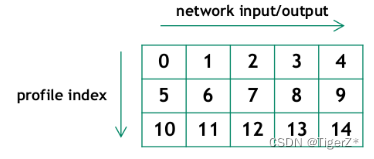
engine.num_bindings 獲取binding 總數
engine.binding_is_input 計算出input數量(每個profile里 算一個, engine.binding_is_inpu?// nProfile 才是模型的輸入個數)
context.set_binding_shape 設置輸入輸出的維度,如上面表格需要計算出pad和對應輸入輸出的順序index
contex.get_binding_shape 獲得對應profile 的輸出的維度
context.execute_async_v2 執行推理,這里傳入的第一個參數為輸出輸出GPU顯存的地址,并且需要填滿如上的表格,不用的位置填0。
完整代碼: https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/08-Advance/MultiOptimizationProfile/main-BindingAPI.py
logger = trt.Logger(trt.Logger.ERROR)
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString) # engineString 是二進制 open engine文件
nIO = engine.num_bindings
nInput = np.sum([engine.binding_is_input(i) for i in range(engine.num_bindings)])
nOutput = nIO - nInput
nIO, nInput, nOutput = nIO // nProfile, nInput // nProfile, nOutput // nProfile
context = engine.create_execution_context()
context.set_optimization_profile_async(index, stream)
bindingPad = nIO * index_profile? # 計算binding 的偏置
context.set_binding_shape(bindingPad + 0, inputShape) # 第一個輸入
outputShape = contex.get_binding_shape(bindingPad + nInput + 0) # 第一個輸出
bufferList = [int(0) for b in bufferD[:bindingPad]] + \[int(b) for b in bufferD[bindingPad:(bindingPad + nInput + nOutput)]] + \[int(0) for b in bufferD[(bindingPad + nInput + nOutput):]]
context.execute_async_v2(bufferList, stream)2)8.5 之后廢棄binding
使用范例如下
engine.num_io_tensors ?獲取輸入輸出總個數
engine.get_tensor_name ?獲得對應的輸入輸出名字
engine.get_tensor_mode 判斷是輸入還是輸出(trt.TensorIOMode.INPUT 、trt.TensorIOMode.OUTPUT)
context.set_input_shape 直接設置對應的形狀,不再需要計算偏置
context.get_tensor_shape 直接獲得輸入輸出(需要先設置輸入自動計算)形狀
context.set_tensor_address 綁定TRT 輸入輸出和 開辟的顯存
context.execute_async_v3 來執行推理
完整代碼: https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/08-Advance/MultiOptimizationProfile/main.py
logger = trt.Logger(trt.Logger.ERROR)
engine = trt.Runtime(logger).deserialize_cuda_engine(engineString) # engineString 是二進制 open engine文件
nIO = engine.num_io_tensors
lTensorName = [engine.get_tensor_name(i) for i in range(nIO)]
nInput = [engine.get_tensor_mode(lTensorName[i]) for i in range(nIO)].count(trt.TensorIOMode.INPUT)
context = engine.create_execution_context()
context.set_optimization_profile_async(index, stream)
context.set_input_shape(lTensorName[0], inputShape)
outputShape = context.get_tensor_shape(lTensorName[1])
context.set_tensor_address(lTensorName[0], int(cudart.cudaMalloc(nbytes)[1]))
context.execute_async_v3(0)2、dynamic shape 性能
如果跨度較大建議使用多個配置文件,可以明顯提升推理性能
參考:
Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/09-BestPractice/UsingMultiOptimizationProfile/result-A30.md
https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/09-BestPractice/UsingMultiOptimizationProfile/main.py
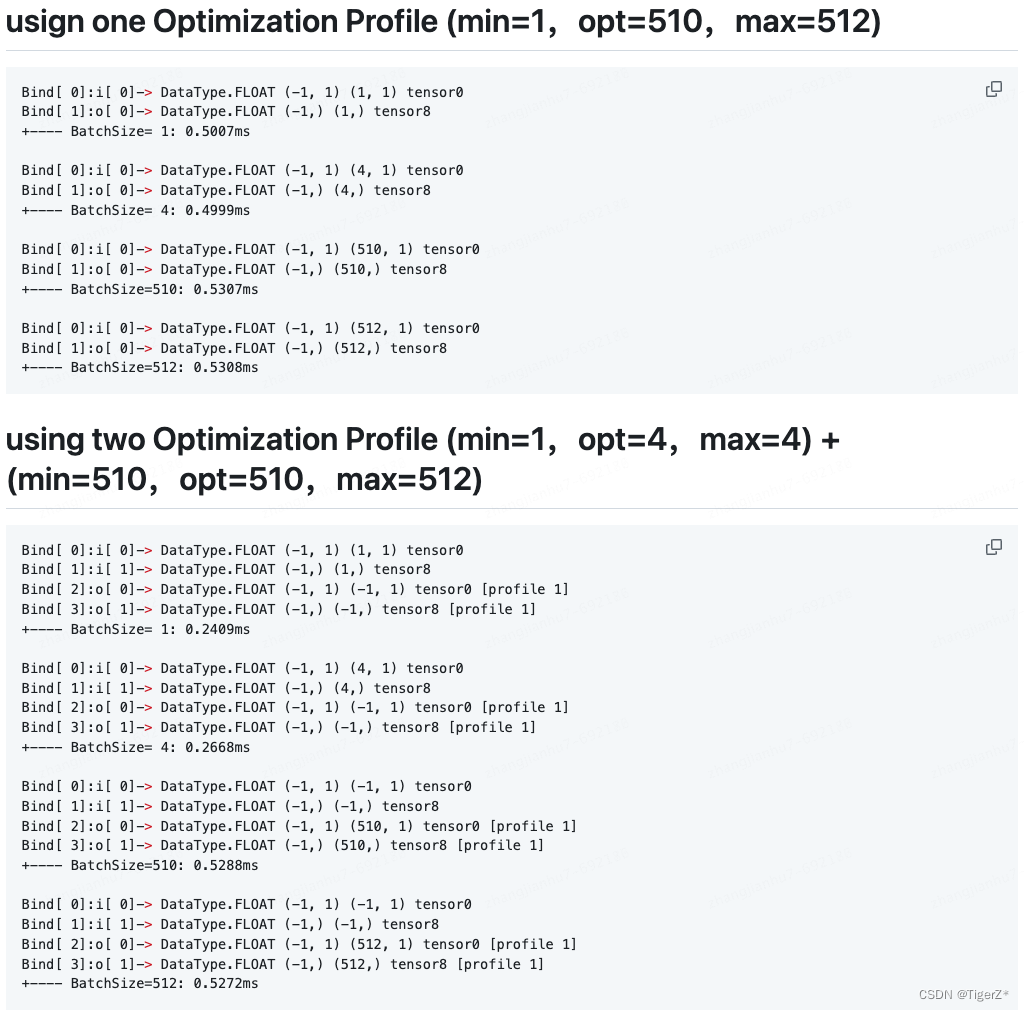
獲得真實推理形狀(假設真實為(3,150,150)),要使用 context.get_tensor_shape(0)?(返回 (3, 150, 250)),而不是 engine.get_tensor_shape("foo”) ?(返回? (3, -1, -1) )?。
3、engine、 context、stream、profile(動態batch的配置文件)
一個engine 可以擁有多個context,共享一個權重。
可以將不同的context 放到不同的stream 中,實現并行。
一個context可以擁有多個profile(至少一個),但是8.6 0805預覽特性前,一個profile 只能綁定一個context(context 和profile 需要錯開使用)。
參考:
多流(8.6): https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/08-Advance/MultiStream/main.py
多上下文-動態batch(8.6+): https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/08-Advance/MultiContext/main.py?
多上下文-動態batch(8.5-): https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/cookbook/08-Advance/MultiContext/main-MultiOptimizationProfile.py


)




-論壇管理系統)


)








色彩空間和通道)