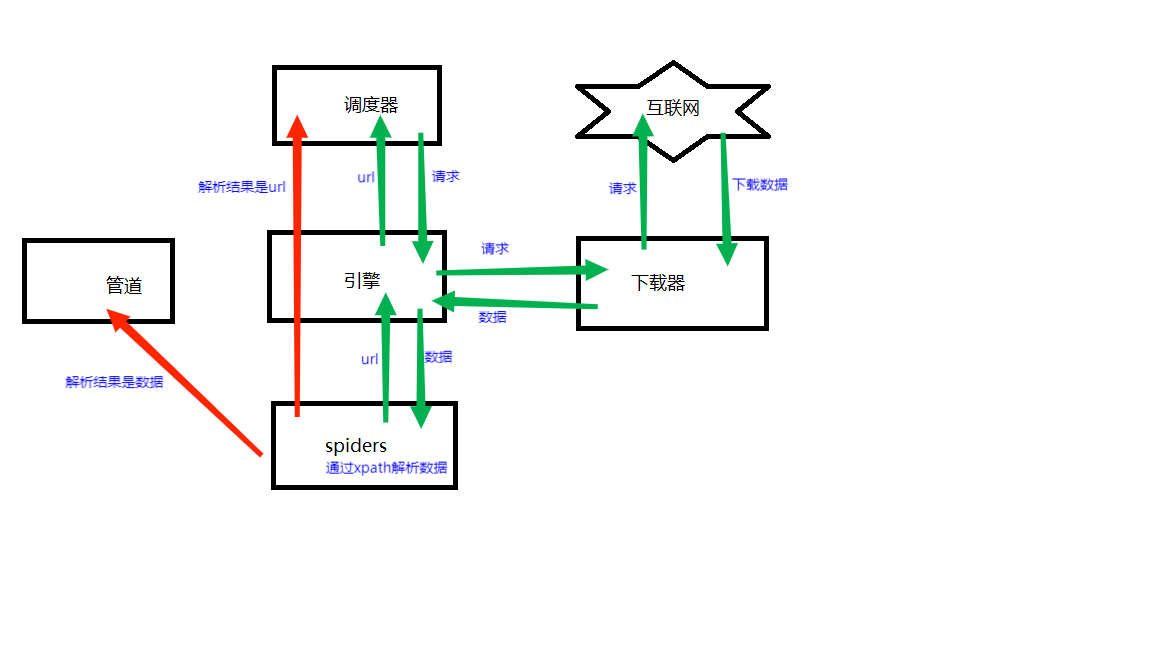
- 引擎向spiders要url
- 引擎把將要爬取的url給調度器
- 調度器會將url生成的請求對象放入到指定的隊列中
- 從隊列中出隊一個請求
- 引擎將請求交給下載器進行處理
- 下載器發送請求獲取互聯網數據
- 下載器將數據返回給引擎
- 引擎將數據再次給到spiders
- spiders通過xpath解析該數據,得到數據或者url
- spiders將數據或者url給到引擎
- 引擎判斷改數據是url,還是數據,是數據的話就交給管道(itempipeline)處理,是url的話就交給調度器處理
Python爬蟲——scrapy_工作原理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/41240.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/41240.shtml 英文地址,請注明出處:http://en.pswp.cn/news/41240.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
)
vue3+ts+tsx的使用與好處(語法方面:tsx==jsx)
前言: 整理分享下vue3tstsx相關的資料,有react使用經驗的小伙伴應該更能理解這個的好處,終于在vue3中也支持了,相當于函數的方法來操作界面。
1、vue3項目中為什么要用tsx(等同于我們react的jsx) 類型安全…

【STM32】 工程
🚩 WRITE IN FRONT 🚩 🔎 介紹:"謓澤"正在路上朝著"攻城獅"方向"前進四" 🔎🏅 榮譽:2021|2022年度博客之星物聯網與嵌入式開發TOP5|TOP4、2021|2022博客之星TO…

oracle 更新語句條件匹配不生效
最近在工作中寫了一個供別人調用的Oracle的存儲過程接口,功能很簡單,就是根據傳入的幾個參數來更新表中的某些數據,但是在聯調過程中傳入的更新匹配條件和被更新的數據一致對不上,更新的數據會比匹配的三個條件的數據多࿰…


Spring系列篇--關于AOP【面向切面】的詳解
目錄
一.AOP是什么
二.案例演示
1.前置通知1.1 先準備接口
1.2然后再準備好實現類
1.3對我們的目標對象進行JavaBean配置
1.4 編寫前置系統日志通知
1.5配置系統通知XML中的JavaBean
1.6 配置代理XML中的JavaBean
1.7 測試代碼開始測試
注意這里有一個報錯問題&…

JVM虛擬機:初始化的介紹
本文重點
我們前面學習了三個步驟: 裝載 連接 初始化 初始化
初始化的時候,會為靜態成員變量賦值初始值,它有兩種方式: ①聲明類變量是指定初始值 ②使用靜態代碼塊為類變量指定初始值 例子 最后輸出的結果為3,它的過程是這樣的:
main方法中輸出T.count,由于count是…

自簽證書讓Chrome信任的方式
自簽證書讓Chrome信任的方式(域名情況)
網站是搭建在linux上的,內容大概是一個code-server;我要在windows的chrome中訪問,在Linux機器上自簽了一個證書,準備讓windows中的chrome信任。linux裝好openssl。首先買好域名,配置好解析…

tkinter+爬蟲+pygame實現音樂播放器
文章目錄 前文安裝模塊示意圖爬蟲完整代碼pygametkinter完整代碼結尾前文
本文將涉及爬蟲(數據的獲取),pygame(音樂播放器),tkinter(界面顯示),將他們匯聚到一起制造一個音樂播放器,歡迎大家的訂閱。
安裝模塊 pip install requests,parsel,lxpy,pygame 示意圖

Flask下載文件報錯304 NOT MODIFIED
文章目錄 問題描述解決方案參考文獻 問題描述
前端 Vue 下下來的文件無法正常打開,大小比正常的略大一點,通過 Postman 直接調用是正常的 解決方案
由前端解決
如果響應大小比文件略大一點,從 responses 中取出關鍵數據再組成文件如果響應…
色彩空間和通道)
open cv學習 (二)色彩空間和通道
色彩空間和通道
demo1
import cv2hsv_image cv2.imread("./img.png")cv2.imshow("img", hsv_image)
hsv_image cv2.cvtColor(hsv_image, cv2.COLOR_BGR2HSV)
h, s, v cv2.split(hsv_image)
cv2.imshow("B", h)
cv2.imshow("G", s…
)

文本圖片怎么轉Excel?分享一些好用的方法
在處理數據時,Excel 是一個非常強大的工具,但有時候需要將文本和圖片轉換為 Excel 格式,這可能會讓人感到困惑。在本文中,我們將介紹一些好用的方法,以便您能夠輕松地將文本和圖片轉換成 Excel 格式。 將文本圖片為Exc…

部署piwigo網頁 通過cpolar分享本地電腦上的圖片
通過cpolar分享本地電腦上有趣的照片:發布piwigo網頁 文章目錄 通過cpolar分享本地電腦上有趣的照片:發布piwigo網頁前言1. 設定一條內網穿透數據隧道2. 與piwigo網站綁定3. 在創建隧道界面填寫關鍵信息4. 隧道創建完成 總結 前言
首先在本地電腦上部署…
)
K8S核心組件etcd詳解(上)
1 介紹 https://etcd.io/docs/v3.5/ etcd是一個高可用的分布式鍵值存儲系統,是CoreOS(現在隸屬于Red Hat)公司開發的一個開源項目。它提供了一個簡單的接口來存儲和檢索鍵值對數據,并使用Raft協議實現了分布式一致性。etcd廣泛應用…
--使用兩個表來滿足操作)
關于計數以及Index返回訂單號升級版002(控制字符長度,控制年月標記,拾取未使用編號)--使用兩個表來滿足操作
1實現步驟以及說明
1.根據參數獲取當前setNoIndex表里現在的No的index值,如果包含關鍵字當前對應數據,則現在SetIndexNoLeft 表中找到有無未使用并未占用的那條數據(被占用的數據IsTaken1,生成后使用當前時間與updated時間進行比…

Django圖書商城系統實戰開發-實現訂單管理
Django圖書商城系統實戰開發-實現訂單管理
簡介
在本教程中,我們將繼續基于Django框架開發圖書商城系統,這次的重點是實現訂單管理功能。訂單管理是一個電子商務系統中非常重要的部分,它涉及到用戶下單、支付、發貨以及訂單狀態的管理等方面…

【hive】簡單介紹hive的幾種join
文章目錄 前言1. Common Join2. Map Join介紹:使用方法:限制: 3. Bucket Map Join介紹:好處:使用條件:使用方法: 4. Sort Merge Bucket Map Join介紹:如何使用: 5. Skew …

如何在控制臺查看excel內容
背景
最近發現打開電腦的excel很慢,而且使用到的場景很少,也因為mac自帶了預覽的功能。但是shigen就是閑不住,想自己搞一個excel預覽軟件,于是在一番技術選型之后,我決定使用python在控制臺顯示excel的內容。 具體的需…

Redis與MySQL的比較:什么情況下使用Redis更合適?什么情況下使用MySQL更合適?
Redis和MySQL是兩種不同類型的數據庫,各有自己的特點和適用場景。下面是Redis和MySQL的比較以及它們適合使用的情況:
Redis適合的場景:
高性能讀寫:Redis是基于內存的快速Key-Value存儲,讀寫性能非常高。它適用于需要…

NodeJs導出PDF
(優于別人,并不高貴,真正的高貴應該是優于過去的自己。——海明威) 場景
根據訂單參數生成賬單PDF
結果 示例代碼
/* eslint-disable no-unused-vars */
/* eslint-disable no-undef */
/* eslint-disable complexity */
const…