在最近的項目中,總是或多或少接觸到了搜索的能力。而在這些項目之中,或多或少都離不開一個中間件 - ElasticSearch。
今天忙里偷閑,就來好好了解下這個中間件是用來干什么的。
ES是什么?
? ES全稱ElasticSearch,是個基于Lucene的搜索服務器。其作為一個高度可拓展的開源全文搜索和分析引擎,可用于快速對大數據進行存儲,搜索和分析。
? ElasticSearch和Logstash(數據收集、日志解析引擎)、Kibana(分析和可視化平臺)一起開發的。這三個產品被設計成一個集成解決方案,稱為“Elastic Stack”(以前被稱為ELK技術棧)。
為什么要用ES?
傳統關系數據庫的缺陷
? 為了了解ES的優勢在哪,我們首先需要回顧傳統的mysql數據庫作為搜索的時候都有哪些缺陷。
在我們日常搜索的時候,我們都需要通過輸入關鍵詞,去檢索出來相關的數據。
以搜索“搜索引擎”為例子,你在百度、搜狗等搜索引擎中輸入這個關鍵字,就會得到一系列的搜索結果:
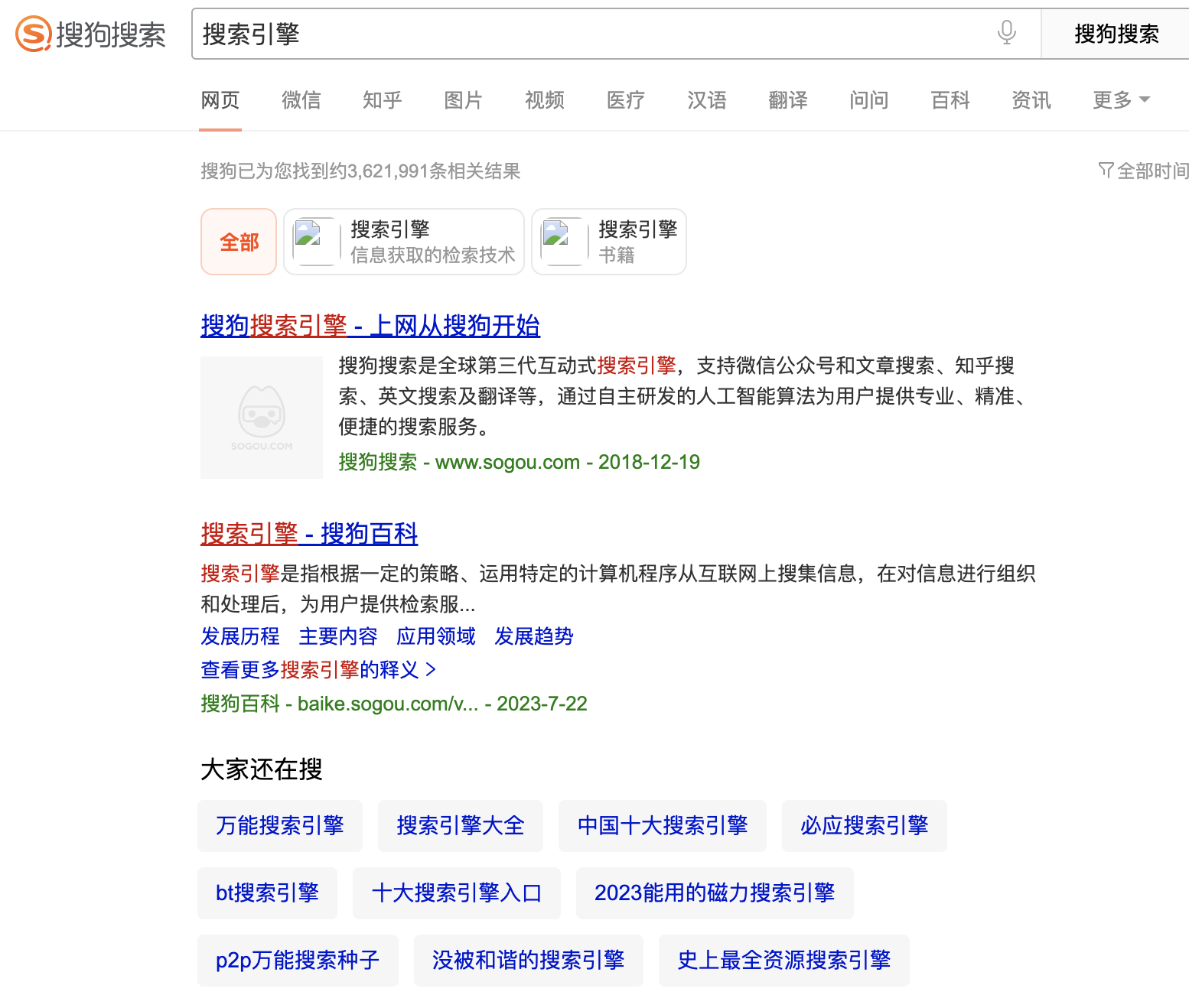
? 如果這些結果都存儲在Mysql數據庫中,它大致會呈現如下的存儲樣式:

? 每一行會存儲唯一標識id、數據內容。
因此,如果需要按照關系型數據庫的方式,需要逐行進行搜索匹配相關詞,甚至需要用上模糊搜索,如:‘LIKE %xx%’ 等。
? 且在mysql中,像這類模糊搜索語句,mysql是無法對其建立索引的。因此如果在大數據量下搜索將變得十分緩慢、困難。
? 而且另外一個點在于,對于搜索引擎來說,還需要將用戶輸入的詞做拆分,依舊是以”搜索引擎“為例子,那么搜索結果其實需要同時包含“搜索”、“引擎”、“搜索引擎”的結果,而這無疑又一次加大了采用關系型數據庫實現的復雜性。
? 總結下來,使用關系型數據庫處理搜索問題,主要有兩個較大的問題:模糊搜索困難、分詞查詢支持困難。
? 那么為什么關系型數據庫會有這樣的問題呢?本質上是關系型數據庫的正排索引限制了其搜索性能。你可能這里會好奇了。什么是正排索引呀?
? 以上面的數據為例子,正排索引就是先找到對應的文章,而后才能夠知道每個文章中對應的詞是什么。繪制成圖片大概就是下面的樣子:
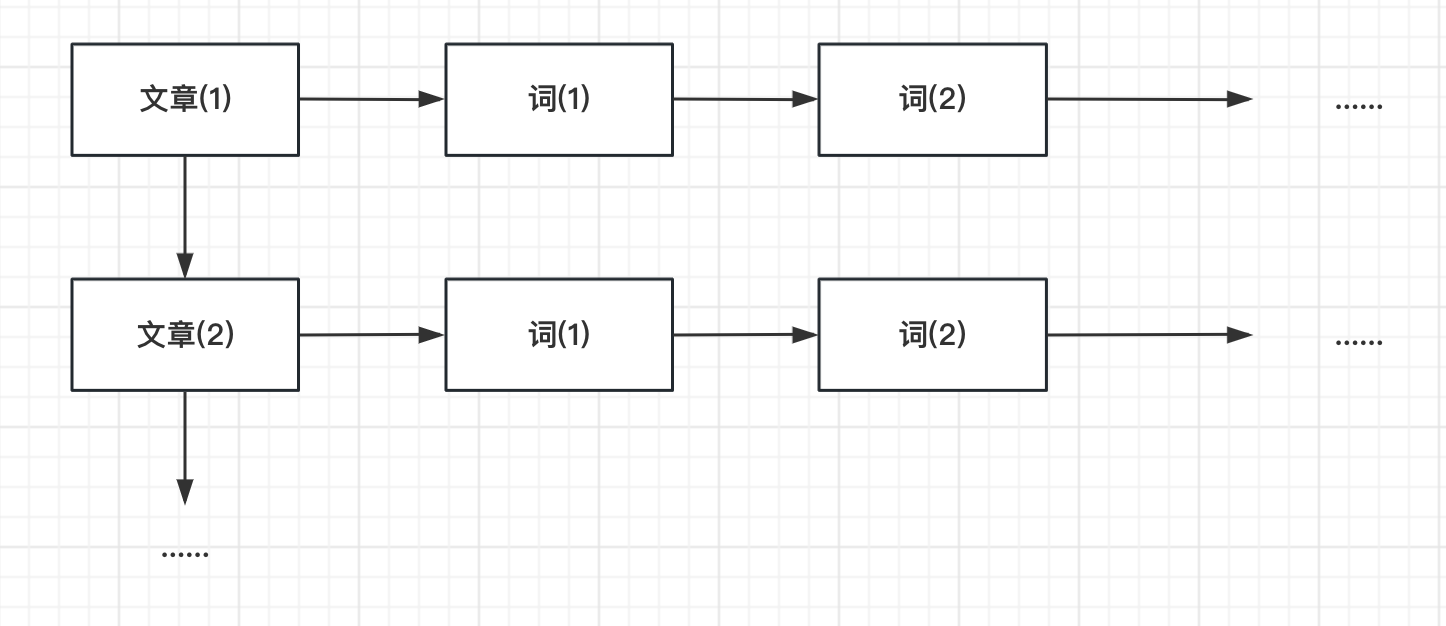
? 因此,如果用這樣正排索引的方式搜索,相當于每次都要進行全表的掃描、匹配,那么自然很難支持搜索的能力。
ElasticSearch優勢
倒排索引
? 上面我們總結了傳統數據庫實現搜索的主要難度在于:模糊搜索困難、分詞查詢困難。
而其歸根結底是由于數據庫的組織方式是通過正排索引實現的。導致了每次搜索需要匹配的難度大。
? 那么,這里可能就有聰明的同學想到了,如果根據文章搜索詞的難度大,那么是否轉變一下存儲方式,先存詞,再存文章,不就可以一下子搜索到了嘛!
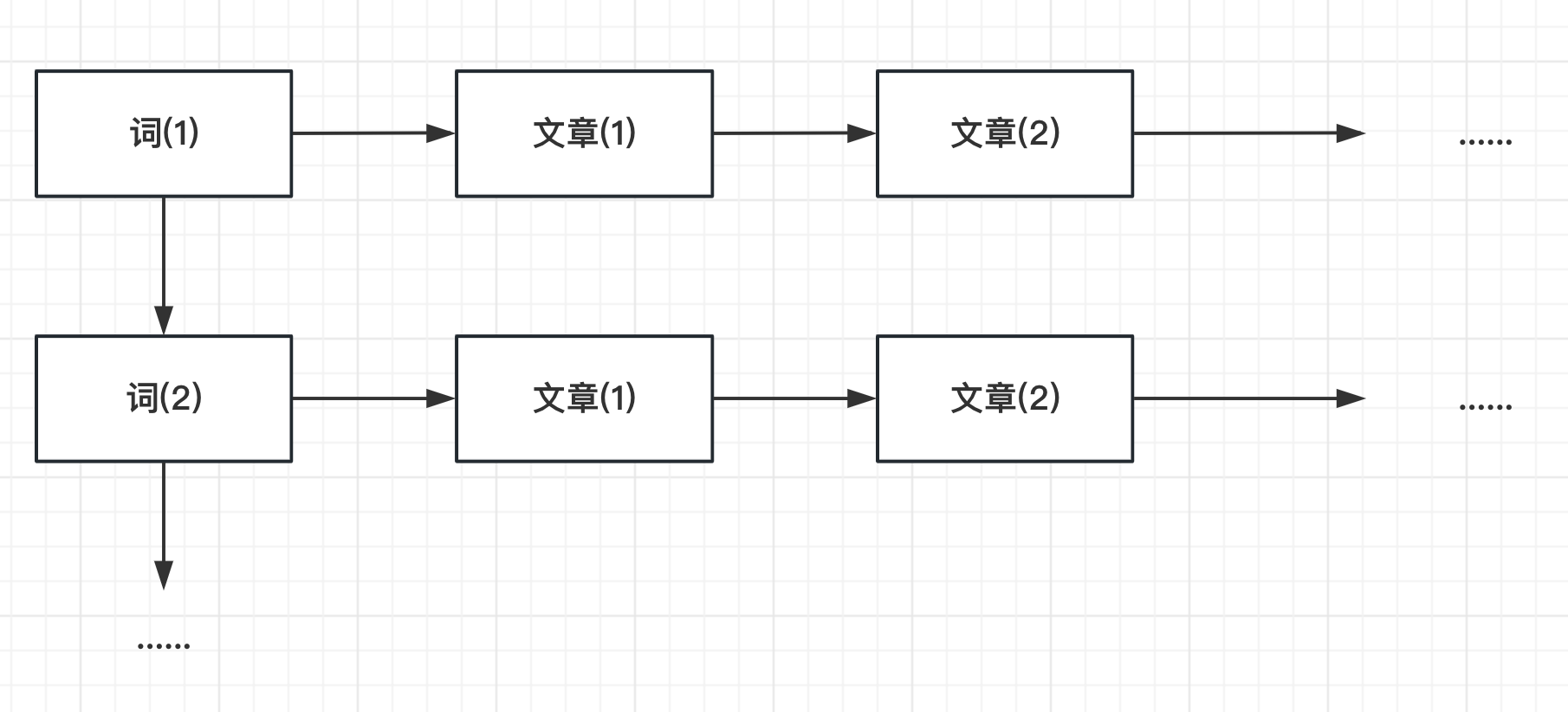
? 如果你想到了這個,那么恭喜你,你已經具備從零開始研發ES的潛力的。沒錯,ES為了支持快捷的搜索,底層的實現也是這么做的,而這種實現方法就是大名鼎鼎的----“倒排索引”。
數據存儲結構
? 要更深入的了解ES的倒排索引的設計邏輯,我們可以先參照Mysql的數據存儲設計介紹幾個ES中的常見名詞:
| Mysql等關系數據庫 | ElasticSearch數據庫 |
|---|---|
| 數據庫(dataBase) | 索引(index) |
| 表(table) | 類型(type) |
| 行(row) | 文檔(document) |
| 列(column) | 字段(field) |
? 結合同Mysql的定義對比,我們就不難理解如下的ES數據代表什么含義了:
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 1.0,"hits": [{"_index": "china","_type": "_doc","_id": "beijing","_score": 1.0,"_source": {"name": "beijing"}}]}
}
? 像如上的數據,就是實際通過es查詢得到的數據。其中的__index就是代表所屬的數據索引; __type就是指所屬的的文檔類型,__id就是對應分詞出來的結果內容
? 那么我們現在已經知道了ES是如何存儲數據的,那么還有個問題:ES建立倒排索引的流程是怎樣的呢?這個說來也并不困難,主要有以下四步:
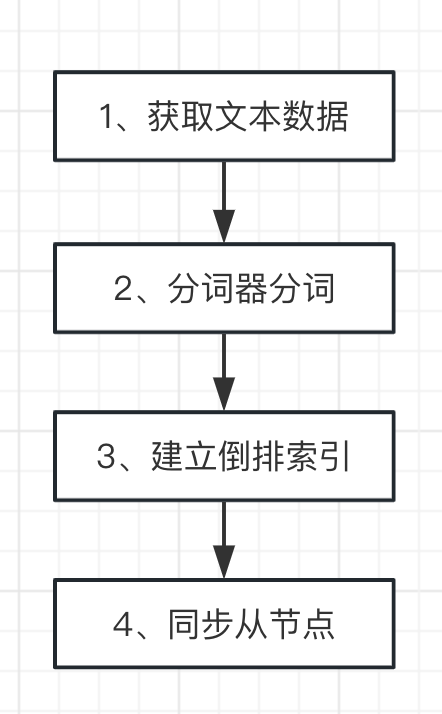
第一步,首先就是需要獲取文本數據,常見的方法就有網頁爬蟲、logstash搜集的方式。
第二步,等到數據收集完成以后,我們需要采用分詞器進行分詞。就是需要將咱們的文本數據拆分成多個細小的單詞,用于后續的倒排索引的建立。
第三步,就是生成倒排索引了。
第四步,就是將相關數據同步到集群中的其他節點上。
存在缺陷
? 那么說了這么多,ES就沒有缺點嗎?那當然也不是的,從上述的數據處理流程、處理原理來看,Es主要有兩個問題:
1、需要分詞,寫入存儲較慢。
2、需要建立的索引量大。
? 這兩種問題也不難理解。對于ES來說,一個文本存儲的方式寫入的時候需先分詞,拆分成多個詞才可以插入到索引中。而進行分詞的時候就會耗費較多的時間。
? 同時相比傳統的正排索引,原本只需要建立一個索引的文章,現在需要按照詞拆分后建立索引。因此創建出的數量就會比原本多得多。
?
ES的實際應用
? 上文介紹了ES的原理、優勢和劣勢。那么什么場景下會用到ES呢?其實最常見的場景就是日志實時分析。
? 這是推動 ES 快速發展的場景,從官方統計數字、云上運營經驗看,占據了 ES 使用場景的 70%+。Elastic Stack 提供的完整日志解決方案,已經助力 ES 成為日志實時分析的開源首先方案。
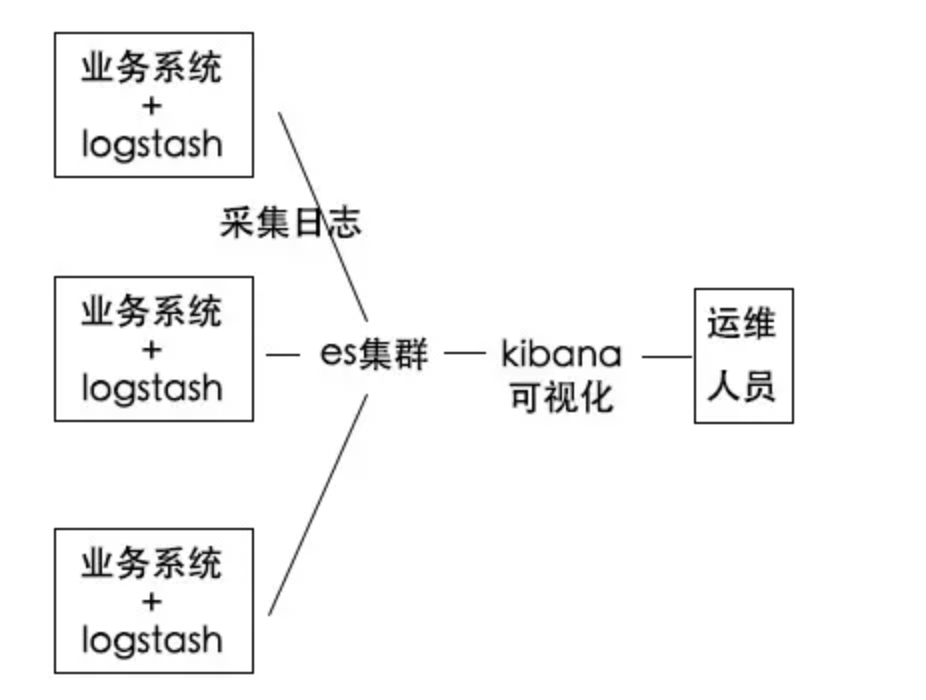
? 簡單來說,日志實時分析主要有三個主要部分組成:logstash、ES集群、kibana。logstash負責收集各個業務系統的日志并推送到ES集群,ES將接收到的日志數據收集起來建立索引。kibana則是提供了一個可視化的搜索能力,用于支持運維人員進行相關報錯日志的搜索。
參考文獻
ES是什么?
Elasticsearch最新完整版教程通俗易懂,最適合后端編程人員的elasticsearch快速實戰教程_ES搜索引擎之核心技術+實戰教學
終于有人把Elasticsearch原理講透了!



![[LeetCode]矩陣對角線元素的和](http://pic.xiahunao.cn/[LeetCode]矩陣對角線元素的和)


WebServerCustomizer的customize方法是在哪里被調用的?)




)



)



