流處理
批處理應用于有界數據流的處理,流處理則應用于無界數據流的處理。
有界數據流:輸入數據有明確的開始和結束。
無界數據流:輸入數據沒有明確的開始和結束,或者說數據是無限的,數據通常會隨著時間變化而更新。
在Flink中,應用程序由數據流組成,這些數據流可以經由用戶自定義的算子進行轉換。數據流最終形成有向圖,這些圖以一個或多個源(Source)開始,以一個或多個接收器(Sink)結束。
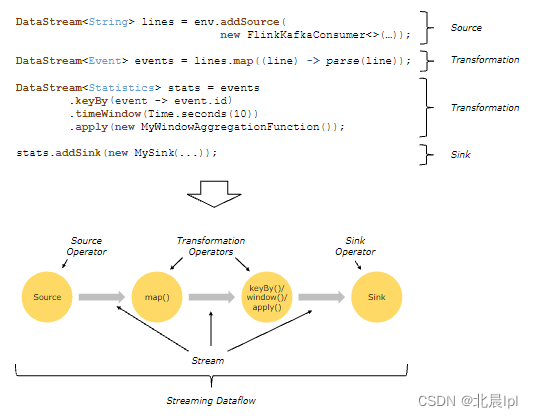
通常來說,轉換(Transformation)與算子之間存在一對一的映射關系,但這并不是絕對的,一個轉換也可以包含多個算子。
Flink可以處理來自數據流源(例如Kafka)的實時數據,同時也可以處理來自數據源的歷史數據。
并行數據流
Flink中的程序本質上是并行和分布式的。在執行期間,流具有一個或多個流分區,每個算子都擁有一個或多個子任務。子任務之間彼此相互獨立,在不同的線程、機器、或容器中執行。
子任務的數量就代表了該算子的并行度(parallelism),同一程序的不同算子可能會具有不同的并行度。
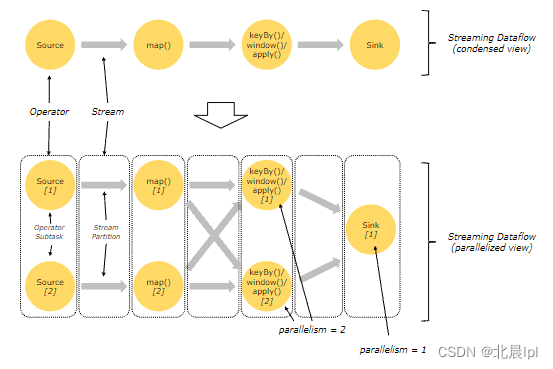
兩個算子之間可以通過一對一或重新分發的方式傳遞數據。
-
一對一:該模式會保留元素的分區和排序。上圖中Source到map()的過程就屬于一對一
-
重新分發:
-
該模式會更改流的分區,上圖中map()到keyBy()/window()的過程就屬于重新分發
-
keyBy()-通過散列重新分區,broadcast()-廣播,rebalance()-隨即分發
-
及時流處理
對于大多數流應用程序來說,能夠使用用于處理實時數據的相同代碼重新處理歷史數據,并無論如何都能產生確定性、一致性的結果,這是非常有價值的。
同等重要的是,注意事件發生的順序,而不是交付處理的順序,并能夠推斷一組事件何時(或應該)完成。
通過使用記錄在數據流中的事件時間戳,而不是使用處理數據的機器的時鐘,可以滿足及時流處理的這些要求。
有狀態流處理
Flink的操作是可以有狀態的。這意味著如何處理一件事可能取決于之前所有事件的累積。
Flink 應用程序在分布式集群上并行運行。
有狀態算子的并行實例集實際上是一個分片鍵值存儲。每個并行實例負責處理一組特定鍵的事件,這些鍵的狀態保存在本地。
下圖顯示了作業圖中前三個算子以 2 的并行度運行的作業,最終由并行度為1的接收器結束。第三個算子是有狀態的,第二個和第三個算子之間正在發生隨機的網絡連接。
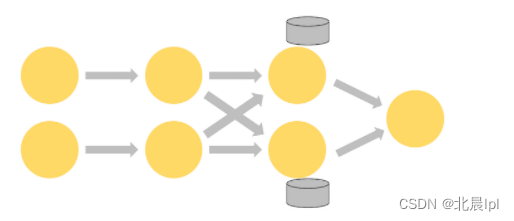
狀態始終在本地訪問,這有助于 Flink 應用程序實現高吞吐量和低延遲。 你可以選擇將狀態保留在 JVM 堆上,如果狀態開銷太大,可以選擇將其存儲于高效率的磁盤中。
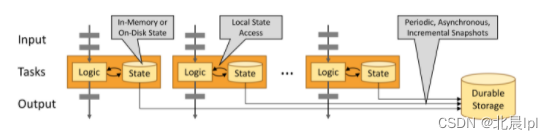
通過狀態快照實現容錯
Flink能夠通過狀態快照和流回溯的組合提供容錯。這些快照將捕獲分布式管道以及整個作業圖的狀態,將其記錄在隊列中,當發生故障時,進行回溯,恢復至最近的狀態。快照的捕獲是異步進行的,并不會影響正在處理的任務。



)

)

)




——JPA是啥? SpringBoot整合JPA JPA的增刪改查 條件模糊查詢 多對一查詢)

)
安裝deb文件)


 持續更新、持續分享)
