我沒有混日子,只是辛苦的時候沒人看到罷了
一、什么是Tesseract
- Tesseract是一個開源的OCR(Optical Character Recognition)引擎,OCR是一種技術,它可以識別和解析圖像中的文本內容,使計算機能夠理解并處理這些文本。
- Tesseract提供了豐富的配置選項和接口,使得開發者可以根據自己的需求和場景進行定制化和集成。
- 通過使用Tesseract,你可以將一張包含文字的圖像(如掃描文檔、照片或截屏)輸入到引擎中,然后Tesseract會通過一系列的圖像處理和模式識別技術來提取出圖像中的文本信息。它將識別出的文本轉換為可以被計算機編輯和搜索的文本內容。
簡單來說,Tesseract是一個強大的OCR引擎,適用于將圖像中的文字提取出來,并將其轉換為計算機可處理的文本形式。它在許多領域和應用中被廣泛使用,如掃描和數字化文檔、自動化數據輸入、圖書館和檔案管理等。
傳送門
二、創建開發環境
使用conda創建一個名字為openCV的開發環境
conda create -n openCV
?引入openCV包
pip install opencv-python
?引入pytesseract包
三、代碼實戰
檢測圖片中的字符串并打印
先準備一張如下格式的圖片

編寫代碼解析
testDectection.py
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv將圖片讀進來
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將圖片的顏色通道格式由BGR轉化成pytesseract能識別的RGB格式
print(pytesseract.image_to_string(img)) # 調用pytesseract引擎將圖片中的內容輸出出來
cv2.imshow('result', img) # 顯示
cv2.waitKey(0)?輸出

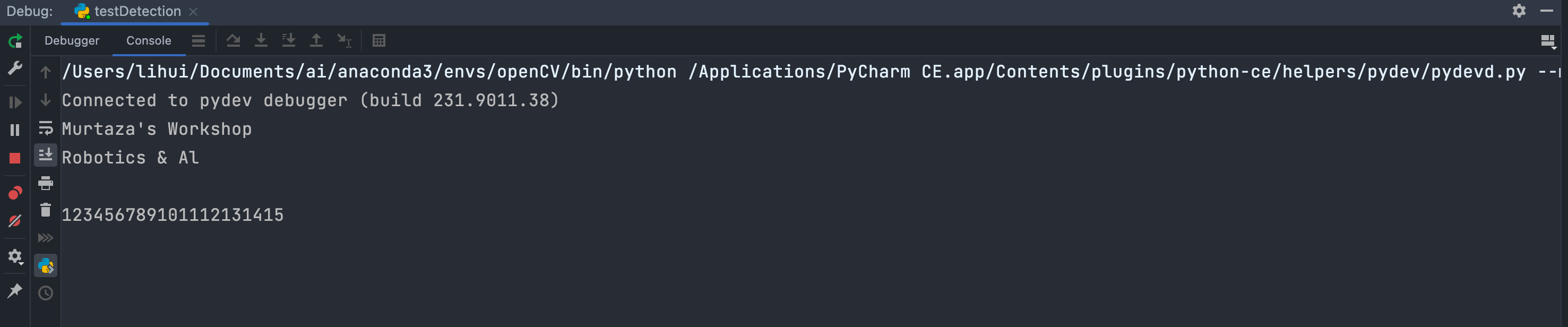
以上就是通過使用pytesseract簡單獲取圖像原始信息的方法。?
檢測圖中的字符并用紅框標注
代碼
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv將圖片讀進來
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將圖片的顏色通道格式由BGR轉化成pytesseract能識別的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出圖片的寬度和高度
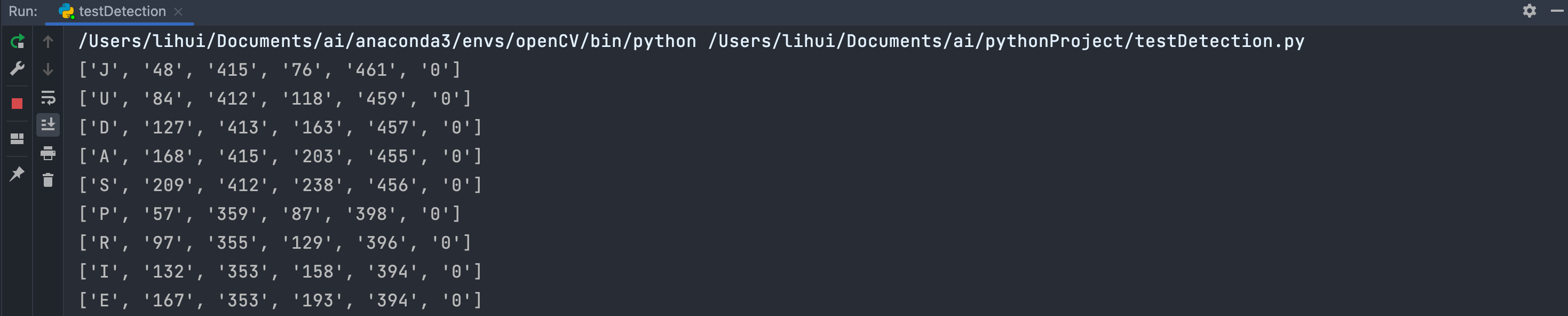
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出圖片中字符的坐標位置
for c in boxes.splitlines():c = c.split(' ')print(c)x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv畫框框,使用紅色,厚度為3cv2.imshow('result', img) # 顯示
cv2.waitKey(0)輸入兩張圖片
1.png

?2.png

輸出
每一個檢測出來字符串的坐標


圖像中添加識別的文本內容
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv將圖片讀進來
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將圖片的顏色通道格式由BGR轉化成pytesseract能識別的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出圖片的寬度和高度
boxes = pytesseract.image_to_boxes(img) # 使用pytesseract找出圖片中字符的坐標位置
for c in boxes.splitlines():c = c.split(' ')print(c)x, y, w, h = int(c[1]), int(c[2]), int(c[3]), int(c[4])cv2.rectangle(img, (x, hImg - y), (w, hImg - h), (0, 0, 255), 3) # 使用opencv畫框框,使用紅色,厚度為3cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向圖像中添加文本cv2.imshow('result', img) # 顯示
cv2.waitKey(0)?關鍵
cv2.putText(img, c[0], (x, hImg - y + 25), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2)
這行代碼使用OpenCV庫中的putText函數向圖像中添加文本。
解釋如下:
img:表示要添加文本的圖像。c[0]:表示要添加的文本內容,c[0]可能是一個字符串變量,用于指定要添加的文本。(x, hImg - y + 25):表示文本的起始位置,該位置是一個元組(x, y),其中x表示文本的橫坐標,hImg - y + 25表示文本的縱坐標。hImg可能是整個圖像的高度,y是用于定位白色文本的輪廓的頂端位置的變量。通過hImg - y + 25可以使文本出現在輪廓下方一些距離的位置。cv2.FONT_HERSHEY_COMPLEX:表示所使用的字體類型,這里使用的是復雜的字體類型。1:表示文本的字體縮放因子,1表示原始大小。(50, 50, 255):表示文本的顏色,該顏色為一個元組(B, G, R),其中B、G、R分別表示藍色、綠色、紅色通道的值。在這個例子中,文本顏色是一種深紅色。2:表示文本的線寬,即文本邊框的寬度。這里設置為2,使得文本邊框較粗。
輸出

檢測連續的字符串
實際中一般不關注一個字符,更多是關注連起來的字符串
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv將圖片讀進來
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將圖片的顏色通道格式由BGR轉化成pytesseract能識別的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出圖片的寬度和高度
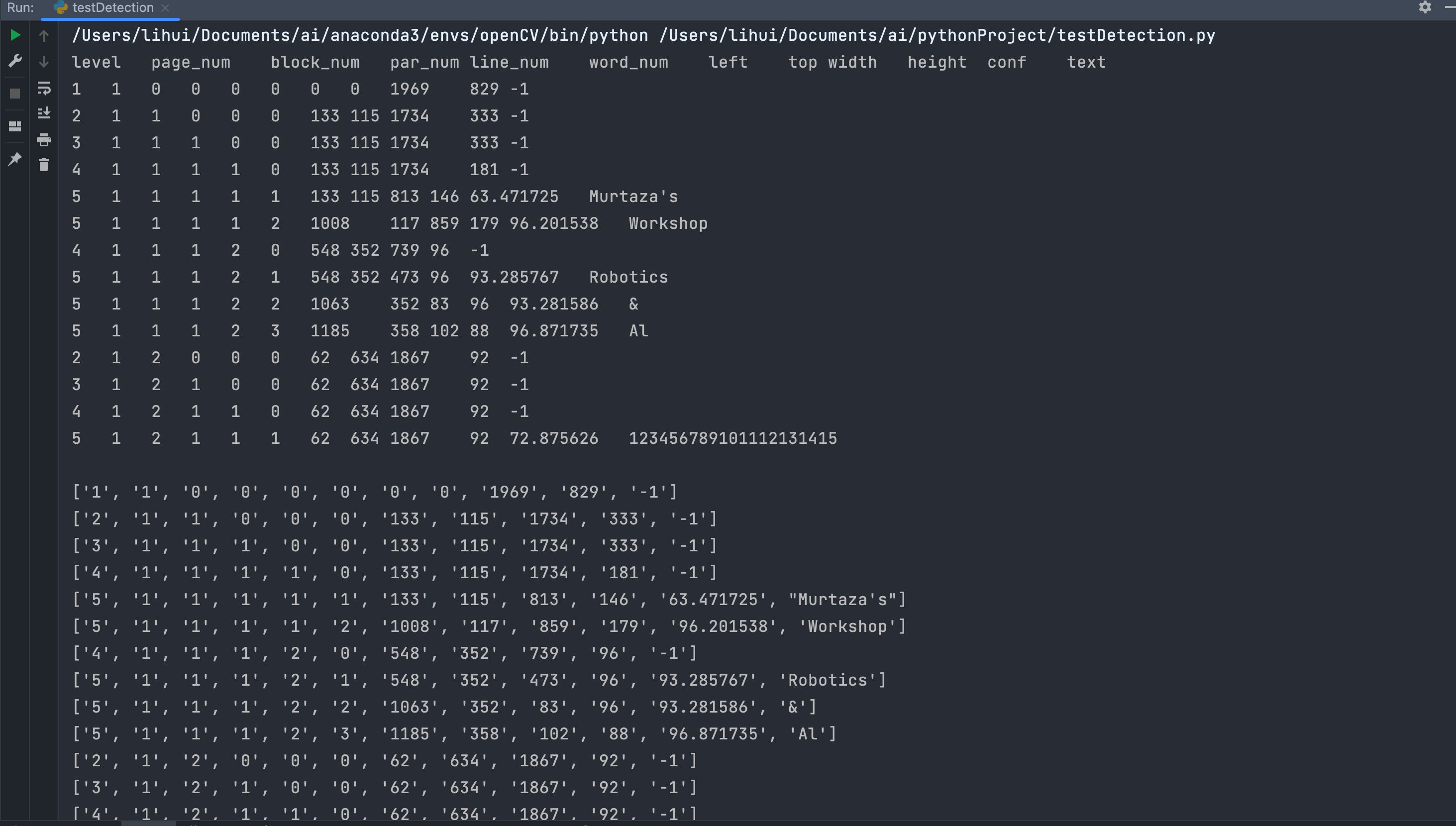
boxes = pytesseract.image_to_data(img) # 使用pytesseract找出圖片中字符的坐標位置
for x, c in enumerate(boxes.splitlines()):if x != 0:c = c.split()print(c)if len(c) == 12:x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv畫框框,使用紅色,厚度為3cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向圖像中添加文本cv2.imshow('result', img) # 顯示
cv2.waitKey(0)
?輸出
每個字段的含義:
level:代表文本在頁面中的級別。這里的級別是從1開始的,表示文本的嵌套層級。page_num:代表文本所在的頁碼。在多頁文檔中,每一頁都有一個唯一的頁碼。block_num:代表文本所在的文本塊的編號。文本塊是文檔中的一個矩形區域,包含多個段落或行。par_num:代表文本所在的段落的編號。段落是文檔中的一個文本段落,通常由一組相關的句子組成。line_num:代表文本所在行的編號。行通常是段落中的一個文本行。word_num:代表文本所在單詞的編號。單詞是文本的最小單位,通常由一個或多個字符組成。left:代表文本區域的左邊界相對于頁面的位置。top:代表文本區域的上邊界相對于頁面的位置。width:代表文本區域的寬度。height:代表文本區域的高度。conf:代表文本的置信度,通常在0到100之間。置信度表示OCR算法對所識別文本的可信程度。text:代表識別出的文本內容。

只識別圖片中的數字
import cv2
import pytesseractimg = cv2.imread('1.png') # 使用opencv將圖片讀進來
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 將圖片的顏色通道格式由BGR轉化成pytesseract能識別的RGB格式# Detecting Characters
hImg, wImg, _ = img.shape # 找出圖片的寬度和高度
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong) # 使用pytesseract找出圖片中字符的坐標位置
for x, c in enumerate(boxes.splitlines()):if x != 0:c = c.split()print(c)if len(c) == 12:x, y, w, h = int(c[6]), int(c[7]), int(c[8]), int(c[9])cv2.rectangle(img, (x, y), (x + w, h + y), (0, 0, 255), 3) # 使用opencv畫框框,使用紅色,厚度為3cv2.putText(img, c[11], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (50, 50, 255), 2) # 向圖像中添加文本cv2.imshow('result', img) # 顯示
cv2.waitKey(0)
?重點
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_data(img, config=cong)
參數解釋:
oem是一個參數,用于指定OCR引擎的OCR引擎模式(OCR Engine Mode)。OCR引擎模式控制Tesseract在文本識別過程中的行為和算法。psm是一種頁分割模式(Page Segmentation Mode),用于指定OCR引擎在識別文本時如何處理頁面布局和分割問題。psm參數控制Tesseract在識別文本時如何將圖像分割為單個字符、單詞、行和文本塊。

?
?




-用戶詳情)


)









)

