NeuralNLP-NeuralClassifier的使用記錄,訓練預測自己的【中文文本多分類】
數據準備:
? 與英文的訓練預測一致,都使用相同的數據格式,將數據通過代碼處理為JSON格式,以下是我使用的一種,不同的原數據情況會有所改動:
import jieba.analyse as ana
import re
import jiebadef make_data_json(df,outpath):def stop_words(path):txt = open(outpath,"r",encoding='utf-8') lines = txt.readlines()txt.close()stop_txt = []for line in lines:stop_txt.append(line.strip('\n'))return stop_txtwith open(outpath, "w+", encoding='utf-8') as f:# with open(output_path, "w") as fw:for indexs in df.index:dict1 = {}dict1['doc_label'] = [str(df.loc[indexs].values[0])]doc_token = df.loc[indexs].values[1]# 只保留中文、大小寫字母和阿拉伯數字reg = "[^0-9A-Za-z\u4e00-\u9fa5]"doc_token = re.sub(reg, '', doc_token)print(doc_token)# 中文分詞seg_list = jieba.cut(doc_token, cut_all=False)#$提取關鍵詞,20個:ana.set_stop_words('./人工智能挑戰賽-文本分類/停用詞列表.txt')keyword = ana.extract_tags(doc_token, topK=20,withWeight=False,) #True表示顯示權重# 去除停用詞content = [x for x in seg_list if x not in stop_words('../data/stop_words.txt')]dict1['doc_token'] = contentdict1['doc_keyword'] = keyworddict1['doc_topic'] = []# 組合成字典print(dict1)# 將字典轉化成字符串json_str = json.dumps(dict1, ensure_ascii=False)f.write('%s\n' % json_str)使用構造JSON數據方法:

訓練前期準備:
1、創建中文數據文件夾,Chinese_datas,
2、創建該數據的文本數據對應的標簽集Chinese_label.taxonomy
3、創建該數據的訓練配置文件Chinese_train_conf.json,
繼續目錄如下:

配置文件的注意點:

其中需要額外修改的地方:
work_nums=0
以及涉及代碼中,有讀取文件的部分都需要給編碼中文編碼:
with open(encoding=‘utf-8’)
訓練:
訓練代碼:
python train.py conf/Chinese_train_conf.json
訓練后生成的權重文件,在配置文件中就寫出了:

預測:

python predict.py conf/Chinese_train_conf.json Chinese_datas/predict_data.json
預測結果:
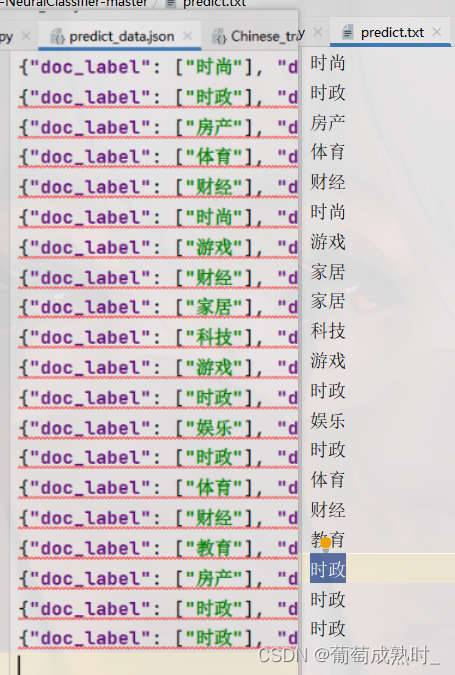
可以看出預測效果僅一個錯誤,該模型方便NLP的比賽分類等,準確率也很高。
代碼獲取:
下載就是中文分類版,在命令界面進行命令行輸入,訓練和預測,:
鏈接:https://pan.baidu.com/s/1fw_ipmOFWMiTLAFrs9i5ig
提取碼:2023

















)

