戳上方藍字關注我?
? ? 這兩年學會了跑sql,當時有很多同學幫助我精進了這個技能,現在也寫成一個小教程,反饋給大家。
? ? 適用對象:工作中能接觸到sql查詢平臺的業務同學(例如有數據查詢權限的產品與運營同學)
? ? 適用場景:查詢hive&mysql上的數據
????文檔優勢:比起各類從零起步的教程教材,理解門檻低,有效信息密度大,可以覆蓋高頻業務場景。? ?
????文末有一些常見的小技巧,希望幫助同學們提升工作效率。
SQL的基礎結構:
做一個類比,我們用的“表”,就像是一個賬本,每天就是一個“分區”,“字段”就是日記上記的不同的事情,例如支出、收入、物品和價格等;
一般來講sql有如下結構,意思是從表α.table里面,獲取某一天的abc三個字段,后面的講解都是在這個基礎上展開的:
select a,b,c --select后面輸入需要查詢的字段fromα.table --from后面輸入需要查詢的表名wheredate='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據多個條件同時生效-and和or
and的用法--表示多條件同時生效
select a,b,c --select后面輸入需要查詢的字段fromα.table --from后面輸入需要查詢的表名where date='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據and --表示要看date='yymmdd' 且id='XXX'id=XXXor的用法--表示有一個條件生效即可
select a,b,c --select后面輸入需要查詢的字段fromα.table --from后面輸入需要查詢的表名where date='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據and (id=XXXor d_id=XXX)???--表示要看date='yymmdd'?,且id是xxx或d_id是xxx的數據。如果沒有這個括號,表示的是要看date是yymmdd且id是xxx,或者不分日期,d_id是xxx的數據對指標進行加和--sum
學習到本節時,我們需要明白維度和指標的區別,維度是表示屬性的,指標是表示量級的,例如全中國有56個民族,全中國就是一個維度,民族數量就是一個指標
select --select后面輸入需要查詢的字段a,b,sum(c) --需要加和的c字段(指標)括起來加sum即可,有點像excel那種fromα.table --from后面輸入需要查詢的表名where date='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據and (id=XXXor sp_id=XXX) --表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的數據。如果沒有這個括號,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的數據group by a,b --沒有被處理的字段(維度),需要在尾部group by 一下為字段重新命名--as
select --select后面輸入需要查詢的字段a,b as b1,sum(c) as c1 --需要加和的c字段括起來加sum即可,有點像excel那種;這里用as把b重新命名成了b1,把c重新命名成了c1fromα.table --from后面輸入需要查詢的表名where date='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據and (id=XXXor sp_id=XXX) --表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的數據。如果沒有這個括號,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的數據group by a,b --沒有被處理的字段,需要在尾部group by 一下;被重新命名的維度字段,group by時仍用as前面的內容查數據條數,或查詢維度的數量--count和distinct
select --select后面輸入需要查詢的字段a,b,sum(c), --需要加和的c字段括起來加sum即可,有點像excel那種count(distinct d)--去重查詢在a,b枚舉下,d有幾個,例如查ka,la(a)的客戶id(b)下,總共有幾個廣告主(d);不加distinct查詢的是所有的廣告主(d)總共出現了幾次fromα.table --from后面輸入需要查詢的表名where date='yymmdd' --where后面輸入需要卡的條件,例如只看哪天的數據and (id=XXXor sp_id=XXX) --表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的數據。如果沒有這個括號,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的數據group by a,b --沒有被處理的字段,需要在尾部group by 一下對一份數據做多次處理--嵌套結構
如下sql查詢了每個人在當天的頁面訪問頻次。3到7行先查詢出每個用戶id的頁面訪問頻次,然后使用3到7行的結果,查詢每個訪問頻次下,有幾個id:
SELECT?cnt,count(id)FROM(select?id,count(*)?as?cnt??---'*'可以用來查詢行數from α.tablewhere date ='20190928' and label='show'group?by?id) a ---這里寫一個'a',用來給3到7行的結果命名,這樣外層的sql才能識別括號里面的內容group by cnt對多份數據做關聯處理--join
最常用的場景:假設表A上有門店id是a,收入是b,表B上有門店id是a,門店名稱c,如果需要獲取門店id,收入,門店名稱的關系,可以這么寫:
SELECT a,b,cFROM(select a,sum (b) from A group by a)?cost????????????????---為3到6行的sql命名為costleft join ( ---這里使用左連接select a,cfrom B group?by?a,c?)text????---為8到10行的sql命名為texton cost.a=text.a ---這里需要寫清連接兩段sql的字段放下這張圖,形象的表達了各種join方法,獲取的數據范圍。想獲取對應數據時,替換上邊第7行就可以用:?
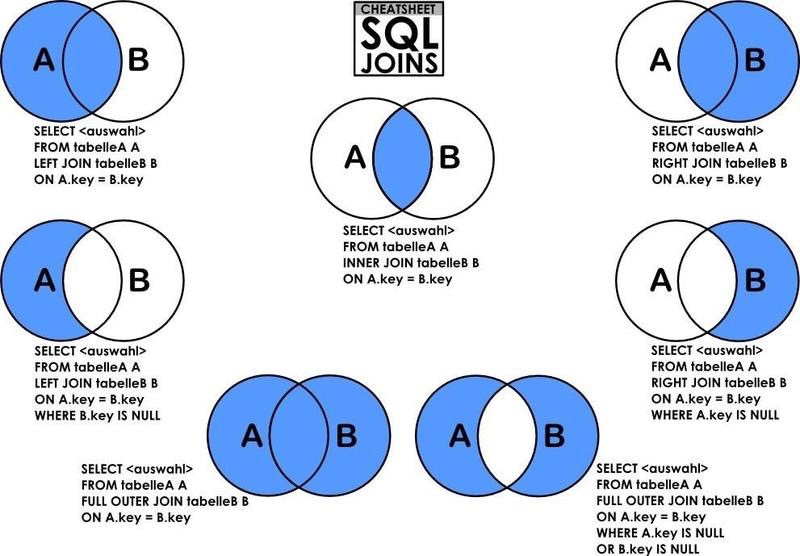
(圖片來源于網絡,侵刪)
條件判斷,對同一個字段做區分計算--if 和case when
判斷一次是否--if
select a,sum (b),if (label = 'show_over', duration, 0) --這一句的意思是,當這一行數據的label是show_over的時候,取duration這個字段里的值,label不是show_over的時候,取0from A group by a判斷一次或多次是否--case when
多加判斷的方式見4和5兩行:
select a,sum (b),case when label?=?'pv'?then?durationwhenlabel='play'?then?mockdurationelse 0end,?--2到4行的意思是,當這一行數據的label是pv的時候,取duration這個字段里的值,如果label是play的時候,取duration這個字段里的值,如果還沒有,就取0from A group by a除法取整--floor
select?a,floor?(X/100)??---把X按100分檔,0檔表示X在[0,100)之間,1檔表示X在[100,200)之間,以此類推from A group by a篩選字段為空/不為空的方法--null
select a,sum (b)from A where type is not null --找出type 不是null的情況,不加"not",就是找出type 是null的情況group by a各種常見類型字段、指定值的查詢方法:
string:加單引號即可,例如一個字段type是string,就可以寫:
select a,sum (b)from A where?type='1'???---string加單引號group by abigint:后面加一個L,例如一個字段type是bigint,就可以寫:
select a,sum (b)from A where?type=1L --- bigint后加Lgroup by aarray:XXX代表數組內的字段類型,需要根據此類型的方式取數,假設model字段的類型是array:
select a,sum (b)from A where array_contains(model,123L)group by ajson:json經常會出現字段包字段的情況,例如常用的data是個json字段,里面會有a字段,a字段里面還會有b字段,如果想取出b,我們應該這么寫:
select?get_json_object(data,'$.a.b')?from A擴展閱讀
一些提升效率的方法
時間分區有多種存儲方式,查詢where條件的時候需要注意:有的表是‘yymmdd’,有的表是‘yy-mm-dd’;字段名也不固定,有的表是p_date,有的表是date,但是對于單個表,分區字段一般是固定的,例如你經常查a.bcde這個表,上次他的時間分區格式是date=‘yymmdd’,下次查的時候它還會是date=‘yymmdd’;
有時表中的時間戳不是常見的yymmdd,而是一串數字,如果where條件里需要卡時間戳,卻不知道日期對應的一串數字是什么,可使用時間戳轉換器轉換:https://tool.lu/timestamp/
sql沒數、跑錯怎么辦:有時解析功能沒有發現問題,但是數據直觀感覺不對,可以用如下方式自查:
檢查相關表的分區,和你取的分區一致不一致,例如日期有多種格式,例如yymmdd,yy-mm-dd,yy-mm-dd 00:00:00等等;
如果sql包含多個部分,比如有join,可以把其他部分的sql注釋掉,分別看每個部分的sql哪里有問題;(注釋方式:代碼前加“--” ?例如 ?--select ...)
需要研究單個json字段的邏輯:可以用這個網址整理json字段,方便閱讀:https://www.json.cn/
同時編輯多行,可以按住shift+alt/option,鼠標點擊起始行和結束行,就能同時編輯多行了,例如批量
常用概念的解釋
全量表和增量表
增量表:每天存下來的數據,是當天產生的所有數據,例如日記,每日走路的步數,銀行每天的收支信息等;
全量表:每天存下來的數據,是從有表開始所有的數據,相當于每天抄一份歷史上所有的日記,再寫今天的日記,例如銀行賬戶的余額;
不同數據庫的區別
mysql等實時查詢的數據庫:一般沒有分區概念,存儲的數據比較少,但是響應快;
hive等離線查詢數據庫:有分區概念,可以較低成本的存儲海量數據,支持各種復雜處理,查詢速度一般比mysql慢。







)
轉)


...)



![[轉]DevExpress GridControl 關于使用CardView的一點小結](http://pic.xiahunao.cn/[轉]DevExpress GridControl 關于使用CardView的一點小結)



對象和類的應用實例)