一. YOLOv8網絡結構
1. Backbone
YOLOv8的Backbone同樣參考了CSPDarkNet-53網絡,我們可以稱之為CSPDarkNet結構吧,與YOLOv5不同的是,YOLOv8使用C2f(CSPLayer_2Conv)代替了C3模塊(如果你比較熟悉YOLOv5的網絡結構,那YOLOv8的網絡結構理解起來就easy了)。
如圖1所示為YOLOv8網絡結構圖(引用自MMYOLO),對比圖2的YOLOv5結構圖,可以看到基本的架構是類似的。
這里值得注意的是,很多博文中寫到YOLOv8使用了CSPDarkNet53作為backbone,當然是可以用的,但是官方代碼中明顯不是套用的CSPDarkNet53網絡結構。事實上,YOLOv5的主干也并非是CSPDarkNet53網絡。
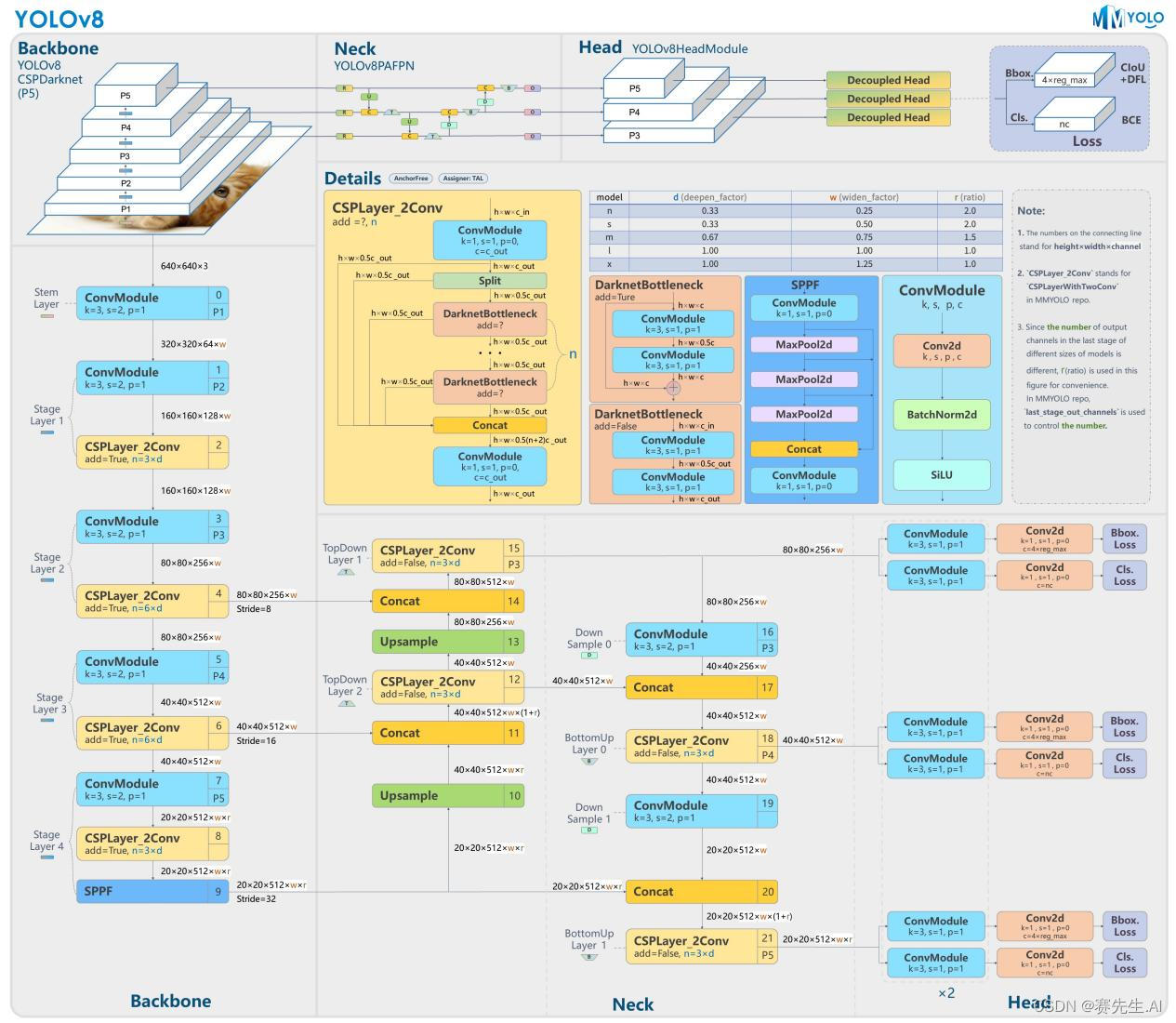
圖1 YOLOv8網絡架構

圖2 YOLOv5網絡架構
2. Neck
YOLOv8的Neck使用的也是類似于YOLOv5的PAN-FPN,稱作雙流FPN,高效,速度快。
3. Head
與之前的YOLOv6,YOLOX類似,使用了Decoupled Head,YOLOv3、YOLOv4、YOLOv5均使用Coupled Head。
YOLOv8也使用3個輸出分支,但是每一個輸出分支又分為2部分,分別來分類和回歸邊框(參照圖1的Decoupled Head)。
二. 細說Backbone
前面講到,YOLOv8的Backbone類似于YOLOv5的Backbone,不同點是將C3換成了C2F,以及將第一個Convolution層設置為kernel size等于3,stride為2(YOLOv5的Kernel Size為6,padding為2)。
1. C2F與C3對比
那么C2F與C3單元相比,有什么優勢呢?我們先上各自的網絡結構圖。如圖3為C3結構圖,圖4為C2F結構圖。
圖4中,每一個Bottleneck的輸入Tensor的Channel都只有上一級的0.5倍,因此計算量明顯降低。從另一方面講,梯度流的增加,也能夠明顯提升收斂速度和收斂效果。
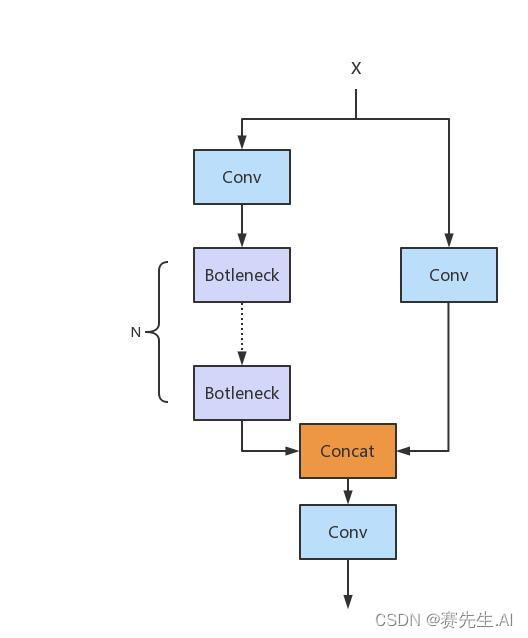
圖3 C3單元

圖4 C2F單元
2. Bottleneck
YOLOv8的C2F使用了Bottleneck單元,但需要注意的是,Darknet所引入的Bottleneck不同于ResNet的Bottleneck。如圖5和圖6分別為Darknet的Bottleneck和ResNet的Bottelneck。
由圖5和圖6可以看出,Darknet的Bottleneck單元并未使用最后的1*1卷積進行通道的恢復,而是直接在中間的3*3卷積中進行了恢復。
此處大家進記住一點即可,Bottleneck可以大大減少參數,降低計算量。
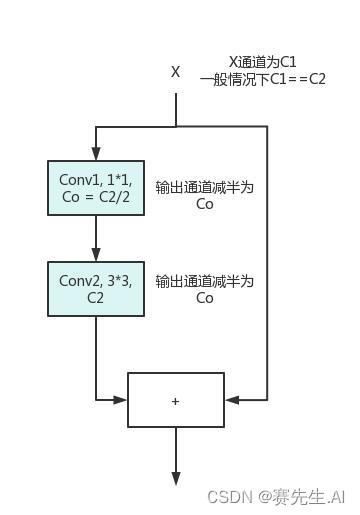
圖5 Darknet Bottleneck
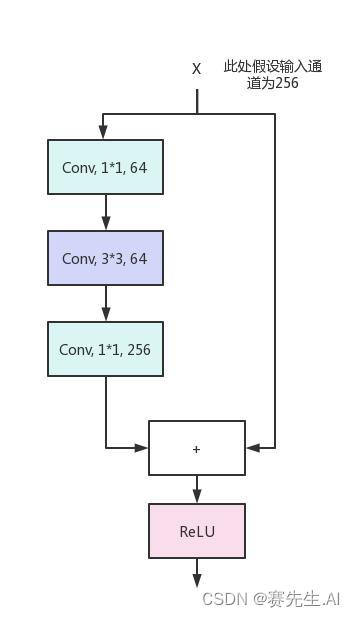
圖6 ResNet Bottleneck
三. Neck
YOLOv8的Neck采用了PANet結構。如圖7為網絡局部圖。
由圖7可以看出,Backbone最后經過了一個SPPF(SPP Fast,圖示Layer9),之后H和W已經經過了32被的下采樣。對應的,Layer4經過了8被下采樣,Layer6經過了16背的下采樣。設定輸入為640*640,得到Layer4、Layer6、Layer9的分辨率分別為80*80、40*40和20*20。
Layer4、Layer6、Layer9作為PANnet結構的輸入,經過上采樣,通道融合,最終將PANet的三個輸出分支送入到Detect head中進行Loss的計算或結果解算。
與FPN(單向,自上而下)不同,PANet是一個雙向通路網絡。與FPN相比,PANet引入了自下向上的路徑,使得底層信息更容易傳遞到高層頂部(紅色曲線標注路線)。
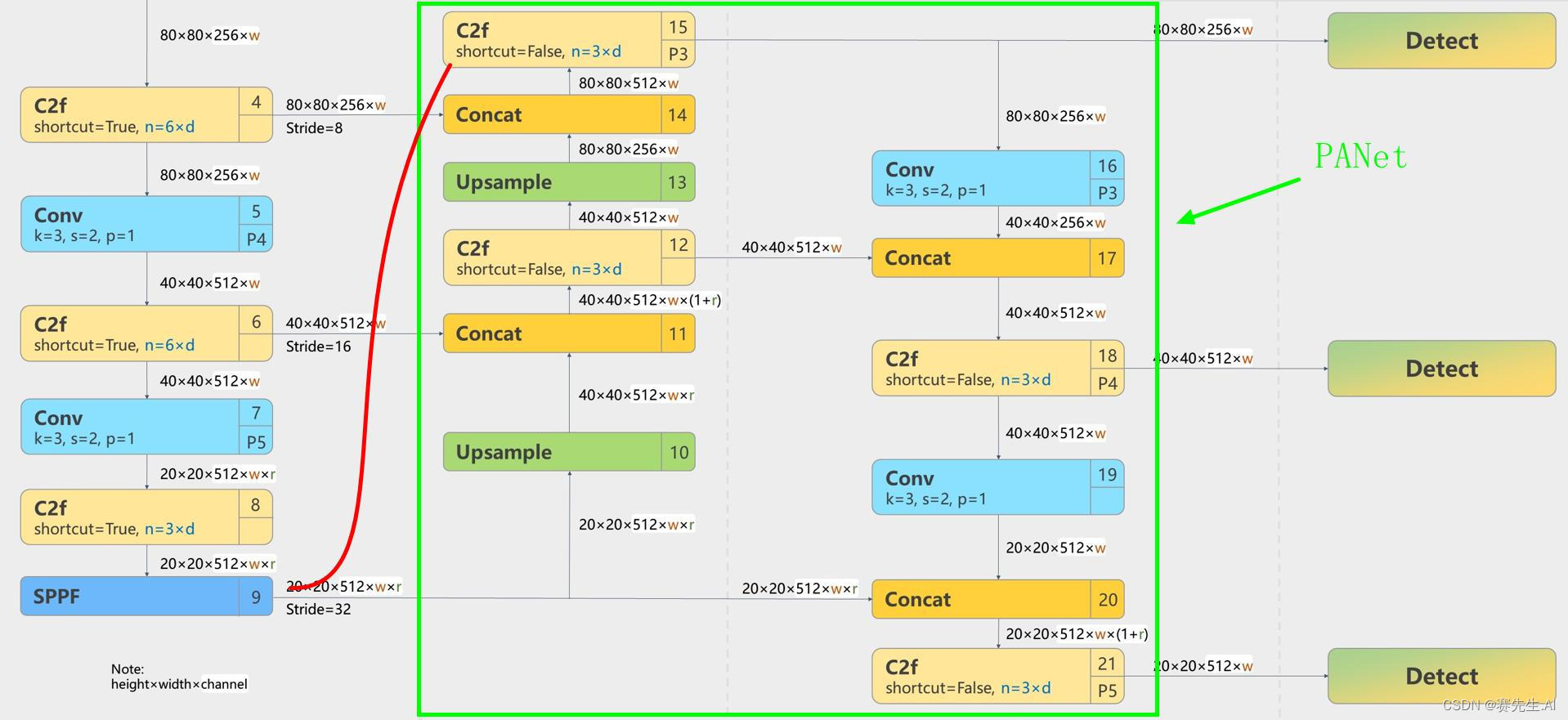
圖7 YOLOv8 Neck(PANet)
四. Detect Head
YOLOv8采用了類似于YOLOX的Decoupled Head,將回歸分支和預測分支進行分離。Decoupled Head的有點可以參考YOLOX的論文中提到的,收斂更快,效果更好。
需要特別提及的是,YOLOv8的Detect Head中,針對回歸分支使用了DFL策略,之前的目標檢測網絡將回歸坐標作為一個確定性單值進行預測,DFL將坐標轉變成了一個分布。
DFL理論主要用來解決邊界模糊的問題。詳細了解可以參考論文“Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection”。




)






)







