四、 多表查詢
1 什么是多表查詢
多表查詢:當查詢的數據并不是來源一個表時,需要使用多表鏈接操作完成查詢。根據 不同表中的數據之間的關系查詢相關聯的數據。
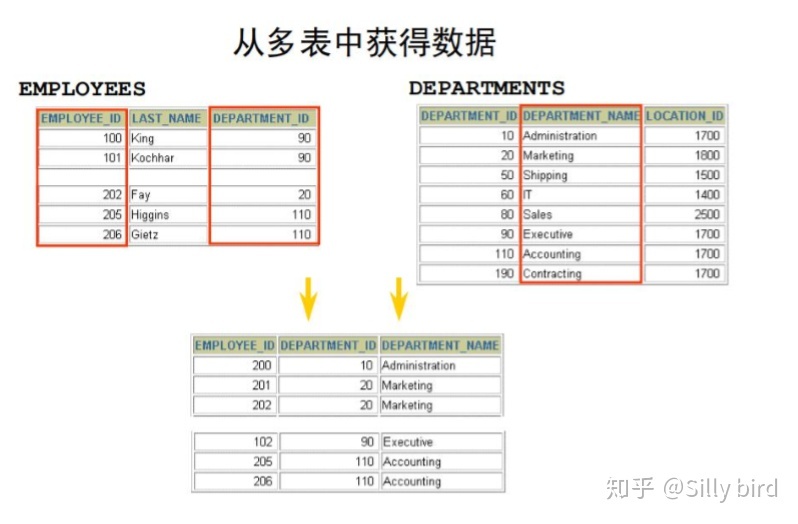
多表鏈接方式: 內連接:連接兩個表,通過相等或不等判斷鏈接列,稱為內連接。在內連接中典型 的聯接運算有 = 或 <> 之類的比較運算符。包括等值聯接和自然聯接 等值連接 非等值連接 自連接 SQL99:交叉鏈接(CROSS JOIN) SQL99:內連接(INNERJOIN) SQL99:自然鏈接(NATURALJOIN) 外連接:在兩個表之間的連接,返回內連接的結果,同時還返回不匹配行的左(或
右)表的連接,稱為左(或右)連接。返回內連接的結果, 同時還返回左和右連接, 稱為全連接。 左外鏈接 右外鏈接 全外鏈接 子查詢:當一個查詢是另一個查詢的條件時,稱之為子查詢。
2 笛卡爾乘積
2.1什么是笛卡爾乘積
笛卡爾乘積是指在數學中,兩個集合 X 和 Y 的笛卡尓積(Cartesianproduct),又稱直 積,表示為 X*Y,第一個對象是 X 的成員而第二個對象是 Y 的所有可能有序對的其中一 個成員。
2.2如何避免出現笛卡爾乘積
當一個連接條件無效或被遺漏時,其結果是一個笛卡爾乘積 (Cartesian product),其中 所有行的組合都被顯示。第一個表中的所有行連接到第二個表中的所有行。一個笛卡爾乘積 會產生大量的行,其結果沒有什么用。應該在 WHERE 子句中始終包含一個有效的連接條 件。
2.3示例 select * from employees,departments;
3 多表連接語法
3.1語法結構
使用一個連接從多個表中查詢數據。

3.2定義連接
當數據從多表中查詢時,要使用連接 (join) 條件。一個表中的行按照存在于相應列中
的值被連接到另一個表中的行。
3.3原則
? 在寫一個連接表的 SELECT 語句時,在列名前面用表名或者表別名可以使語義清楚, 并且加快數據庫訪問。 ? 為了連接 n 個表在一起,你最少需要 n-1 個連接條件。例如,為了連接 4 個表, 最少需要 3 個連接條件。
4 等值連接
4.1什么等值連接
等值連接也被稱為簡單連接 (simple joins) 或內連接 (inner joins)。是通過等號來判斷連 接條件中的數據值是否相匹配。
4.2抉擇矩陣 (decision matrix)
是通過行與列來分析一個查詢的方式。 例如,如果你想顯示同一個部門中所有名字為 Taylor 的雇員的名字和部門名稱,可以 寫出下面的決策矩陣: 投影列 源表 條件 last_name employees last_name=‘Taylor’ department_name departments employees.department_id = departments.department_id
4.2.1示例一
查詢所有雇員名字以及他們所在的部門名稱。
select last_name,department_name from employees , departments where employees.department_id = departments.department_id;
4.3使用 AND 操作符附加搜索條件
除連接之外,還可以要求用 WHERE 子句在連接中限制一個或多個表中的行。
4.3.1示例二
顯示同一個部門中所有名字為 Taylor 的雇員的名字和部門號。select last_name,department_name from employees , departments where employees.department_id = departments.department_id and last_name = 'Taylor';
4.4使用表別名
使用表別名簡化查詢語句的長度。
4.4.1表別名
可以使用表別名代替表名。就象列別名給列另一個名字一樣。表別名有助于保持 SQL 代碼較小,因此使用的存儲器也少。
4.4.2使用表別名原則
? 表別名最多可以有 30 個字符,但短一些更好。 ? 如果在 FROM 子句中表別名被用于指定的表,那么在整個 SELECT 語句中都可以 使用表別名。 ? 表別名應該是有意義的。 ? 表別名只對當前的 SELECT 語句有效。
4.4.3示例
使用表別名方式改寫顯示同一個部門中所有名字為 Taylor 的雇員的名字和部門號。 select em.last_name, de.department_name from employees em,departments de where em.department_id = de.department_id and em.last_name = 'Taylor';
4.5多于兩個表的連接
為了連接 n 個表,你最少需要 n-1 個連接條件。例如,為了連接 3 個表,最少需要 兩個連接。
4.5.1示例一
查詢每個雇員的 last name、department name 和 city(city 來源于 locations 表)。 select em.last_name,de.department_name ,lo.city - Registered at Name cheap.com from employees em,departments de,locations lo where em.department_id = de.department_id and de.location_id = lo.location_id;
4.5.2示例二
查詢 Taylor 的雇員 ID、部門名稱、和工作的城市。 select em.employee_id, em.last_name,de.department_name ,lo.city - Registered at Namecheap.com fromemployees em,departments de,locations lo where em.department_id = de.department_id and de.location_id = lo.location_id and em.last_name = 'Taylor';
5 非等值連接
5.1非等值連接
一個非等值連接是一種不使用相等(=)作為連接條件的查詢。如!=、>、<、>=、<=、 BETWEEN AND 等都是非等值鏈接的條件判斷。
5.2創建案例表 create table JOB_GRADES ( lowest_sal NUMBER, highest_sal NUMBER, gra VARCHAR2(10) )
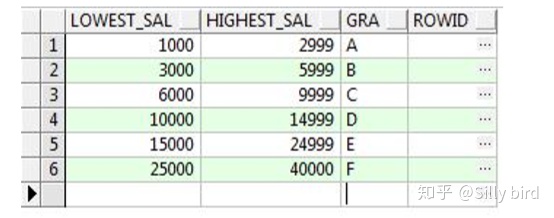
5.3示例
查詢所有雇員的薪水級別。
select em.last_name,em.salary,gr.gra from employees em ,job_grades gr where em.salary between gr.lowest_sal and gr.highest_sal;
6 自連接
6.1什么是自連接
使用一個表連接它自身的操作。
6.2示例
查詢每個雇員的經理的名字以及雇員的名字。
select worker.last_name,manager.last_name from employees worker,employees manager where worker.manager_id = manager.employee_id;
7 外連接(OUTER JOIN)
7.1什么是外連接
外連接是指查詢出符合連接條件的數據同時還包含孤兒數據。左外鏈接包含左表的孤兒 數據,右外連接包含右表的孤兒數據,全外連接包含兩個表中的孤兒數據。
7.2孤兒數據(Orphan Data)
孤兒數據是指被連接的列的值為空的數據。
7.3外連接類型
左外(LEFT OUTER JOIN):包含左表的孤兒數據。 右外(RIGHT OUTER JOIN):包含右表的孤兒數據。 全外(FULL OUTER JOIN):包含兩個表中的孤兒數據。
7.4 SQL 99 中的外連接
SQL 99 外連接語法格式: 用 LEFT OUTER JOIN | RIGHT OUTER JOIN | FULL OUTER JOIN 定義連接類型,用 ON 子句創建連接條件。
7.4.1左外鏈接(LEFT OUTER JOIN)
7.4.1.1 示例
用左外鏈接查詢雇員名字以及他們所在的部門名稱,包含那些沒有部門的雇員。 selecte.last_name,d.department_namefrom employees e left outer join departments d on e.department_id = d.department_id;
7.4.2右外鏈接(RIGHT OUTER JOIN)
7.4.2.1 示例
用右外鏈接查詢雇員名字以及他們所在的部門名稱,包含那些沒有雇員的部門。 selecte.last_name,d.department_namefrom employees e right outer join departments d on e.department_id = d.department_id;
7.4.3全外鏈接(FULL OUTER JOIN)
7.4.3.1 示例
查詢所有雇員和部門,包含那些沒有雇員的部門以及沒有部門的雇員。 selecte.last_name,d.department_name from employees e full outer join departments d on e.department_id = d.department_id;
7.5 Oracle 擴展的外連接
在 Oracle 數據庫中對外連接中的左外與右外連接做了擴展,可以簡化外連接的語法。 通過在連接條件的后側使用(+)來表示是否顯示孤兒數據,有(+)表示不顯示孤兒數據而另一 側則顯示孤兒數據。但是該種寫法僅能在 Oracle 數據庫中使用。
7.5.1示例一
查詢雇員名字以及他們所在的部門名稱,包含那些沒有雇員的部門。 selecte.last_name,d.department_name from employees e ,departments d where e.department_id(+) = d.department_id;
7.5.2示例二
查詢雇員名字以及他們所在的部門名稱,包含那些沒有部門的雇員。
selecte.last_name,d.department_name from employees e ,departments d where e.department_id = d.department_id(+);
8 SQL 99 中的交叉連接
?CROSS JOIN 子句導致兩個表的交叉乘積 ? 該連接和兩個表之間的笛卡爾乘積是一樣的

8.1示例
查詢 Employees 表與 Departments 表的笛卡爾乘積。 select * from employees cross join departments;
9 SQL 99 中的自然連接(NATURAL JOIN)
?NATURAL JOIN 子句基于兩個表之間有相同名字的所有列。 ? 它從兩個表中選擇在所有的匹配列中有相等值的行。 ? 如果有相同名字的列的數據類型不同,返回一個錯誤。
9.1使用自然連接需要注意
1.如果做自然連接的兩個表的有多個字段都滿足有相同名稱個類型,那么他們會被作為 自然連接的條件。
2.如果自然連接的兩個表僅是字段名稱相同,但數據類型不同,那么將會返回一個錯誤。
3.由于 oracle 中可以進行這種非常簡單的 natural join,我們在設計表時對具有相同含 義的字段需要考慮到使用相同的名字和數據類型。
9.2示例
查詢部門 ID,部門名稱以及他們所在的城市。 select
d.department_id,d.department_name,l.city from departments d natural join locations l;
9.3用 USING 子句創建連接
? 當有多個列匹配時,用 USING 子句匹配唯一的列。 ? 如果某列在 USING 中使用,那么在引用該列時不要使用表名或者別名。 ?NATURAL JOIN 和 USING 子句是相互排斥的。
9.3.1示例
查詢 location_id 為 1800 的部門名稱以及他們所在的城市名稱,指定 location_id 為連接
列。
select d.department_name,l.city from departments d join locations l using(location_id) where location_id = 1800;
10 SQL 99 中的內連接(INNER JOIN)
內連接(INNER JOIN): 內連接通過 INNER JOIN 來建立兩個表的連接。在內連接中使 用 INNER JOIN 作為表的連接,用 ON 子句給定連接條件。INNER JOIN 語句在性能上其他 語句沒有性能優勢。
10.1示例
查詢雇員 id 為 202 的雇員名字,部門名稱,以及工作的城市。
等值連接: select e.last_name,d.department_name,l.city from employees e,departments d ,locations l where e.department_id = d.department_id and d.location_id = l.location_id and e.employee_id = 202;
內連接: select e.last_name,d.department_name,l.city from employees e inner join departments d on e.department_id = d.department_id inner join locations l on d.location_id = l.location_id where e.employee_id = 202;
在內連接中使用 USING 子句定義等值連接
select e.last_name,d.department_name,l.city from employees e inner join departments d using(department_id) inner join locations l using(location_id) where e.employee_id = 202;
11 多表查詢小節練習
11.1寫一個查詢顯示所有雇員的
last name、department number、and department_name。
答案(等值): select e.last_name,e.department_id,d.department_na me from employees e ,departments d where e.department_id = d.department_id;
答案(內連接): select e.last_name,e.department_id,d.department_name from employees e inner join departments d on(e.department_id = d.department_id);
11.2查詢部門編號 80 中的所有工作崗位的唯一列表,在輸出中包括部門編號、地點編號。
答案: select distinct e.job_id,d.location_id from employees e,departments d where e.department_id = d.department_id and e.department_id = 80;
11.3寫 一 個 查 詢 顯 示 所 有 有 傭 金 的 雇 員 的 last name、 department name、location ID 和城市。
答案: select e.last_name,d.department_name,l.location_id, l.city from employees e,departments d,locations l where e.department_id = d.department_id and d.location_id = l.location_id and e.commission_pct is not null;
11.4顯示所有在其 last names 中有一個小寫 a 的雇員的 last name 和 department name。
答案: selecte.last_name,d.department_name from employees e,departments d where
e.department_id = d.department_id and e.last_name like '%a%';
11.5使用內連接寫一個查詢顯示那些工作在 Toronto 的所有雇 員 的 last name 、 job 、 department number 和 department name。
答案: select e.last_name,e.job_id,e.department_id,d.depatment_name from employees e inner join departments d on(e.department_id = d.department_id) inner join locations l on(d.location_id = l.location_id) where lower(l.city) ='toronto';
11.6顯示雇員的 lastname 和 employeenumber 連同他們的 經理的 last name 和 manager number。列標簽分別為 Employee、Emp#、Manager 和 Mgr#。
答案: select emp.last_name "Employee",emp.employee_id "Emp#",manager.last_name "Manager" ,manager.employee_id "Mar#" from employees emp ,employees manager where
emp.manager_id = manager.employee_id;
11.7查詢所有雇員的經理包括 King,他沒有經理。顯示雇員的 名字、雇員 ID、經理名、經理 ID、用雇員號排序結果。
答案: select emp.last_name "Employee",emp.employee_id "Emp#",manager.last_name "Manager" ,manager.employee_id "Mar#" from employees emp left outer join employees manager on(emp.manager_id = manager.employee_id);
11.8創建一個查詢顯示所有與被指定雇員工作在同一部門的雇員 (同事) 的 last names、department numbers。給每列一個適當的標簽。
答案: select e.last_name, e.department_id from employees e , employees c where c.department_id = c.department_id and e.employee_id <> c.employee_id;
11.9顯示 JOB_GRADES 表的結構。創建一個查詢顯示所有雇員 的 name、job、department name、salary 和 grade。
答案:
select e.last_name,e.job_id,d.department_name,e.sa lary,j.gra from employees e,departments d,job_grades j where e.department_id = d.department_id and e.salary between j.lowest_sal and j.highest_sal;
11.10 創建一個查詢顯示那些在雇員 Davies 之后入本公司工作 的雇員的 name 和 hiredate
答案: select e.last_name,e.hire_date from employees e ,employees d where d.last_name = 'Davies' and d.hire_date < e.hire_date;
11.11 顯示所有雇員的 names 和 hiredates,他們在他們的經理之前進入本公司,連同他們的經理的名字和受雇日期一起顯示。列標簽分別為 Employee、Emp Hired、Manager 和 Mgr Hired。
答案: select e.last_name,e.hire_date,m.last_name,m.hire_ date from employees e,employees m where e.manager_id = m.employee_id and e.hire_date < m.hire_date;
五、 組函數(聚合函數)
1 組函數介紹
1.1什么是組函數
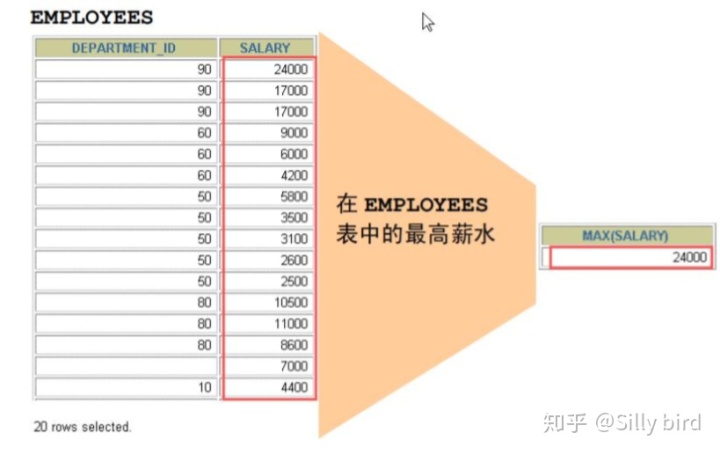
組函數操作行集,給出每組的結果。組函數不象單行函數,組函數對行的集合進行操作, 對每組給出一個結果。這些集合可能是整個表或者是表分成的組。
1.2組函數與單行函數區別
單行函數對查詢到每個結果集做處理,而組函數只對分組數據做處理。 單行函數對每個結果集返回一個結果,而組函數對每個分組返回一個結果。
1.3組函數的類型
?AVG 平均值 ?COUNT 計數 ?MAX 最大值 ?MIN 最小值 ?SUM 合計
1.4組函數的語法

1.5使用組函數的原則
? 用于函數的參數的數據類型可以是 CHAR、VARCHAR2、NUMBER 或 DATE。 ? 所有組函數忽略空值。為了用一個值代替空值,用 NVL、NVL2 或 COALESCE 函
數。
2 組函數的使用
2.1使用 AVG 和 SUM 函數
AVG(arg)函數:對分組數據做平均值運算。 arg:參數類型只能是數字類型。
SUM(arg)函數:對分組數據求和。 arg:參數類型只能是數字類型。
2.1.1示例
求雇員表中的的平均薪水與薪水總額。 select avg(salary) ,sum(salary) from employees;
2.2使用 MIN 和 MAX 函數
MIN(arg)函數:求分組中最小數據。 arg:參數類型可以是字符、數字、日期。
MAX(arg)函數:求分組中最大數據。 arg:參數類型可以是字符、數字、日期。
2.2.1示例
求雇員表中的最高薪水與最低薪水。 select min(salary),max(salary) from employees;
2.3使用 COUNT 函數
COUNT 函數:返回一個表中的行數。
COUNT 函數有三種格式: ?COUNT(*) ?COUNT(expr) ?COUNT(DISTINCT expr)
2.3.1 COUNT(*)
返回表中滿足 SELECT 語句標準的行數,包括重復行,包括有空值列的行。如果 WHERE 子句包括在 SELECT 語句中,COUNT(*) 返回滿足 WHERE 子句條件的行數。
2.3.1.1 示例一
返回查詢結果的總條數。 select count(*) from employees;
2.3.2 COUNT(expr)函數
返回在列中的由 expr 指定的非空值的數。
2.3.2.1 示例二 顯示部門 80 中有傭金的雇員人數。 select count(commission_pct) from employees e where e.department_id = 80;
2.3.3 COUNT (DISTINCT expr):
使用 DISTINCT 關鍵字禁止計算在一列中的重復值。
2.3.3.1 示例三 顯示 EMPLOYEES 表中不重復的部門數。 select count(distinct department_id) from employees ;
2.4組函數和 Null 值
所有組函數忽略列中的空值。 在組函數中使用 NVL 函數來處理空值。
2.4.1示例一
計算有傭金的員工的傭金平均值。 select avg(commission_pct) from employees;
2.4.2示例二
計算所有員工的傭金的平均值。 select avg(nvl (commission_pct,0)) from employees;
3 創建數據組(GROUP BY)
3.1什么是創建數據組
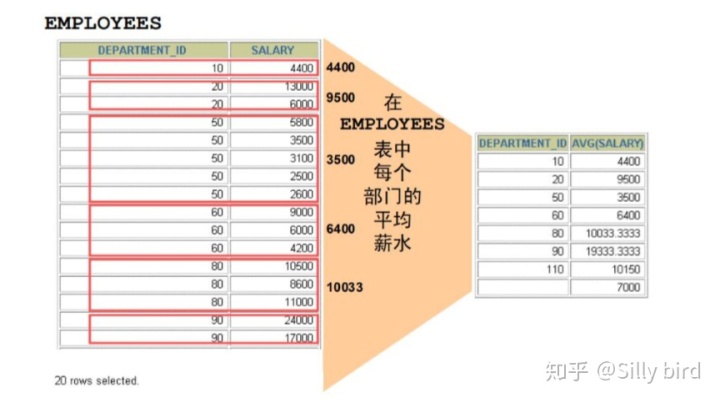
可以根據需要將查詢到的結果集信息劃分為較小的組,用 GROUP BY 子句實現。
3.2 GROUP BY 子句語法

3.3使用分組原則
? 如果在 SELECT 子句中包含了組函數,就不能選擇單獨的結果,除非單獨的列出現 在 GROUP BY 子句中。如果未能在 GROUP BY 子句中包含一個字段列表,你會收到一個 錯誤信息。 ? 使用 WHERE 子句,你可以在劃分行成組以前過濾行。 ? 在 GROUP BY 子句中必須包含列。 ? 在 GROUP BY 子句中你不能用列別名。 ? 默認情況下,行以包含在 GROUP BY 列表中的字段的升序排序。可以用 ORDER BY 子句覆蓋這個默認值。
3.4 GROUP BY 子句的使用
我們可以根據自己的需要對數據進行分組,在分組時,只要將需要做分組的列的列名添 加到 GROUP BY 子句后側就可以。GROUP BY 列不必在 SELECT 列表中。

3.4.1示例一
求每個部門的平均薪水。 select department_id , avg(salary) from employees e group by e.department_id;
3.5多于一個列的分組
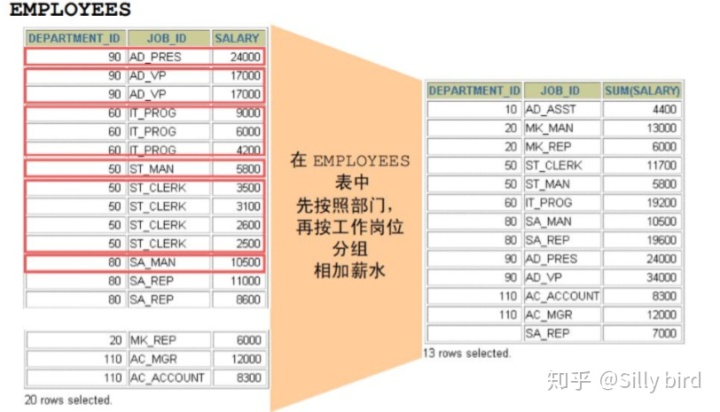
3.5.1示例一
顯示在每個部門中付給每個工作崗位的合計薪水的報告。 select department_id,job_id, sum(salary)from employees group by
department_id,job_id order by department_id;
3.6 GROUP BY 子句的執行順序
先進行數據查詢,在對數據進行分組,然后執行組函數。
3.7非法使用 Group 函數的查詢
? 在 SELECT 列表中的任何列必須在 GROUP BY 子句中。 ? 在 GROUP BY 子句中的列或表達式不必在 SELECT 列表中。

3.8約束分組結果
3.8.1什么是 HAVING 子句
HAVING 語句通常與 GROUP BY 語句聯合使用,用來過濾由 GROUP BY 語句返回的記 錄集。 HAVING 語句的存在彌補了 WHERE 關鍵字不能與聚合函數聯合使用的不足。
3.8.2 HAVING 子句語法

3.8.3示例一
顯示那些最高薪水大于 $10,000 的部門的部門號和最高薪水。 select e.department_id,max(e.salary)from employees e group by e.department_id having max(e.salary) > 10000; 3.8.4示例二
查詢那些最高薪水大于 $10,000 的部門的部門號和平均薪水。 selecte.department_id,avg(e.salary)from employees e group by e.department_id having max(e.salary) > 10000;
3.9嵌套組函數
在使用組函數時我們也可以根據需要來做組函數的嵌套使用。
3.9.1示例
顯示部門中的最大平均薪水。 select max(avg(e.salary)) from employees e group by e.department_id;
4 組函數小節練習
4.1組函數在多行上計算,對每個組產生一個結果。True/False
答案:True
4.2組函數在計算中包含空值。True/False
答案:False 組函數會忽略空值,如果需要空值參與計算,需要使用 nvl 函數處理空值。
4.3在分組計算中,WHERE 子句對行的限制在計算的前面。 True/False
答案:True
4.4顯示所有雇員的最高、最低、合計和平均薪水,列標簽分別為: Maximum、Minimum、Sum 和 Average。四舍五入結果為最近的整數。
答案: select max(salary),min(salary),sum(salary),avg(sal ary) from employees;
4.5修改上題顯示每中工作類型的最低、最高、合計和平均薪水。
答案: select max(salary),min(salary),sum(salary),avg(sal ary) from employees group by job_id;
4.6寫一個查詢顯示每一工作崗位的人數。
答案: select job_id, count(*) from employees group by job_id;
4.7確定經理人數,不需要列出他們,列標簽是 Number of Managers。
答案: select count(distinct manager_id) from
employees ;
4.8寫一個查詢顯示最高和最低薪水之間的差。列標簽是 DIFFERENCE。
答案: select max(salary) - min(salary) from employees;
4.9顯示經理號和經理付給雇員的最低薪水。排除那些經理未知的 人。排除最低薪水小于等于 $6,000 的組。按薪水降序排序
輸出。
答案: select e.manager_id ,min(e.salary) from employees e where e.manager_id is not null group by e.manager_id having min(e.salary) > 6000 order by min(e.salary) desc;
4.10寫一個查詢顯示每個部門的名字、地點、人數和部門中所有
雇員的平均薪水。四舍五入薪水到兩位小數。
答案: select d.department_name,d.location_id,count(*) ,a vg(e.salary) from employees e ,departments d where e.department_id = d.department_id group by d.department_name ,d.location_id;
4.11創建一個查詢顯示雇員總數,和在 2001、2002、2003 和
受雇的雇員人數。創建適當的列標題。
答案: select count(*) total,sum(decode(to_char(hire_date,'yyyy'), '2000',1,0))"2000" ,sum(decode(to_char(hire _date,'yyyy'),'2001',1,0))"2001",sum(decode (to_char(hire_date,'yyyy'),'2002',1,0))"200 2",sum(decode(to_char(hire_date,'yyyy'),'20 03',1,0))"2003" from employees e;
4.12創建一個混合查詢顯示工作崗位和工作崗位的薪水合計,并 且合計部門 20、50、80 和 90 的工作崗位的薪水。給每
列一個恰當的列標題。
答案: select job_id,sum(salary),sum(decode(department_id, 20,salary))"Dep 20",sum(decode(department_id,50,salary))"Dep 50",sum(decode(department_id,80,salary))"Dep 80" ,sum(decode(department_id,90,salary))"Dep 90"from employees group by job_id;


——原型的靈活性)







![計算機網絡怎么查看連接打印機驅動,如何檢測網絡打印機是否已成功連接到計算機[檢測方法]...](http://pic.xiahunao.cn/計算機網絡怎么查看連接打印機驅動,如何檢測網絡打印機是否已成功連接到計算機[檢測方法]...)








