作者:xuty
本文來源:原創投稿
*愛可生開源社區出品,原創內容未經授權不得隨意使用,轉載請聯系小編并注明來源。
一、現象
有個 MySQL 5.7 開發庫異常掛掉后,奔潰恢復一直處于如下位置,且持續了 2 小時左右才起來。非常疑惑這段時間 MySQL 到底做了什么事情?居然需要這么長時間。雖說這里虛擬機的 IOPS 并不是很高,但也絕對不需要這么久吧?而且從日志輸出來看,這塊應該也不是在做真正的數據恢復,那么也可以排除是大事務回滾導致的耗時長,那么原因到底是啥呢?
值得注意的是,這臺開發庫上面有將近 1500 個庫和上萬張表,難道MySQL 崩潰恢復時長和表的數量也存在一定關系嘛?
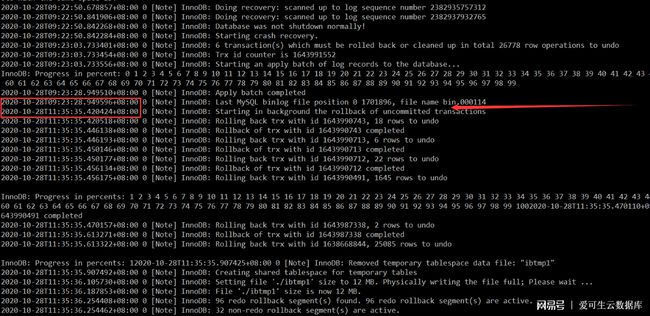
二、分析棧幀
在 MySQL 崩潰恢復時,用pstack打了棧幀,再用pt-pmp工具分析棧幀后顯示如下:
pread64(libpthread.so.0),os_file_io(os0file.cc:5435),os_file_pread(os0file.cc:5612),os_file_read_page(os0file.cc:5612),os_file_read_no_error_handling_func(os0file.cc:6069),pfs_os_file_read_no_error_handling_func(os0file.ic:341),Datafile::read_first_page(os0file.ic:341),Datafile::validate_first_page(fsp0file.cc:551),Datafile::validate_to_dd(fsp0file.cc:404),fil_ibd_open(fil0fil.cc:3969),dict_check_sys_tables(dict0load.cc:1465),dict_check_tablespaces_and_store_max_id(dict0load.cc:1525),innobase_start_or_create_for_mysql(srv0start.cc:2329),innobase_init(ha_innodb.cc:4048),ha_initialize_handlerton(handler.cc:838),plugin_initialize(sql_plugin.cc:1197),plugin_init(sql_plugin.cc:1538),init_server_components(mysqld.cc:4033),mysqld_main(mysqld.cc:4673),__libc_start_main(libc.so.6),_start根據函數名字,感覺像是在遍歷校驗每個表空間文件的有效性?,難道 MySQL 崩潰恢復時會額外進行校驗操作?貌似和表數量扯上點關系了。
三、GDB 調試Server version: 5.7.26-log MySQL Community Server (GPL)
直接去分析源碼感覺有點找不到切入點,因為不知道正常啟動是不是也是這樣的函數調用。為了知道正常啟動與崩潰恢復的區別,先在本地的 MySQL 5.7.26 環境中用 GDB 調試 MySQL 啟動過程,看下正常啟動和崩潰恢復的函數調用有哪些區別,再針對性的去分析源碼比較好。
-- 將之前的棧幀弄成了樹狀,便于分析>innobase_init| >innobase_start_or_create_for_mysql| | >dict_check_tablespaces_and_store_max_id| | | >dict_check_sys_tables| | | | >fil_ibd_open| | | | | >Datafile::validate_to_dd| | | | | | >Datafile::validate_first_page| | | | | | | >Datafile::read_first_page| | | | | | | | >pfs_os_file_read_no_error_handling_func| | | | | | | | | >os_file_read_no_error_handling_func| | | | | | | | | | >os_file_read_page| | | | | | | | | | | >os_file_pread| | | | | | | | | | | | >os_file_io
正常啟動 GDB 調試結果:
從上到下,每次打一個斷點函數,發現到Datafile::validate_to_dd這個函數時,MySQL 正常啟動就不會執行,看樣子是fil_ibd_open函數中做了某些判斷。
崩潰恢復 GDB 調試結果:
一邊用 sysbench 壓,一邊直接 kill -9 進程就可以模擬崩潰恢復,同樣從上到下,依次打斷點函數,發現會走到Datafile::validate_to_dd這個函數中,Continue 后會一直斷點在這個函數上,說明外層包裝了一層循環會遍歷所有表,如果繼續增加斷點函數的話,發現絕大部分表會繼續走下去,直到os_file_io,而小部分表則不會繼續走下去。
四、源碼分析
4.1. fil_ibd_open
我們先去fil_ibd_open函數中看下,進入Datafile::validate_to_dd函數的判斷條件,發現主要和一個validate參數有關,如果為false則可以跳過檢測,為true則需要進入Datafile::validate_to_dd函數。
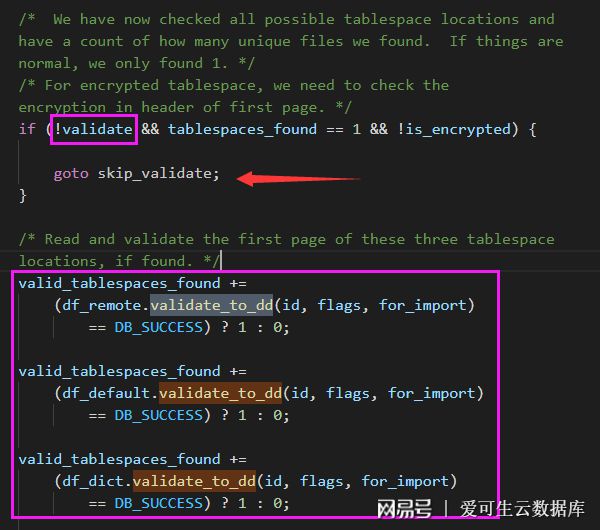
4.2. innobase_start_or_create_for_mysql
然后我們需要看下validate參數的定義,分析崩潰恢復與正常啟動的區別。發現validate 參數最早是在innobase_start_or_create_for_mysql函數中定義的,并且其注釋已經解釋的非常詳細。1. 正常啟動:直接為每張表的創建 space object 即可,不需要打開 ibd 文件的 header page 進行表空間校驗。2. 崩潰恢復:為了數據字典的一致性,需要遍歷打開所有 ibd 文件的 header page 進行表空間校驗。
validate 這個參數表明當一個表空間被打開時,同時會去讀取其 ibd 文件的頭頁(header page)來驗證數據字典的一致性,而當數據庫包含許多 ibd 文件時,這個過程就會比較久,所以只在崩潰恢復且非強制恢復時執行表空間校驗操作!
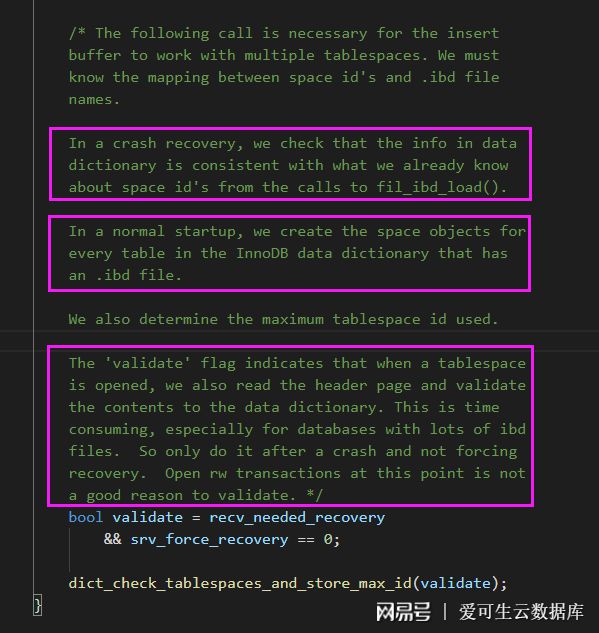
4.3. recv_needed_recovery & srv_force_recovery
接著我們來看下決定 validate 值的 2 個參數:recv_needed_recovery與srv_force_recovery,默認崩潰恢復時,recv_needed_recovery = 1 而 srv_force_recovery = 0 ,所以 validate = true,即需要進行表空間校驗。
bool validate = recv_needed_recovery && srv_force_recovery == 0;//跳過表空間校驗validate = false//執行表空間校驗validate = true先看下recv_needed_recovery參數,默認為 0。MySQL 在啟動時會比對checkpoint_lsn與flush_lsn。如果不相等,就會調用recv_init_crash_recovery方法將recv_needed_recovery置為。只有當 MySQL 正常關閉時,這 2 個 lsn 才會相等。另外一個小發現,MySQL 5.7 中服務起來后,什么操作都不做,checkpoint_lsn 永遠會落后 9,所以即使你什么都不做,直接 kill -9 進程,也算是崩潰重啟。
LOG---Log sequence number 2563079308Log flushed up to 2563079308Pages flushed up to 2563079308Last checkpoint at 2563079299
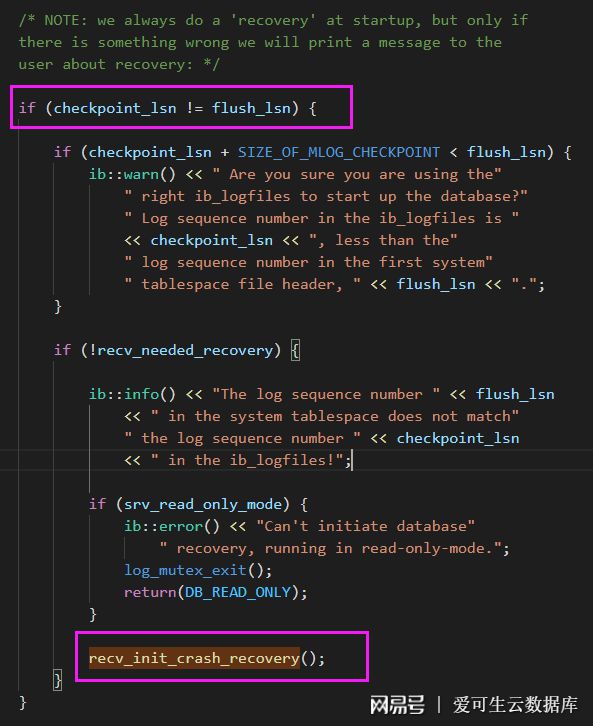
再來看下srv_force_recovery參數,默認值為 0,如果設置了 innodb_force_recovery ,那么 srv_force_recovery 的值就等于 innodb_force_recovery 的值,即只要配置了強制恢復,srv_force_recovery 就會大于 0。
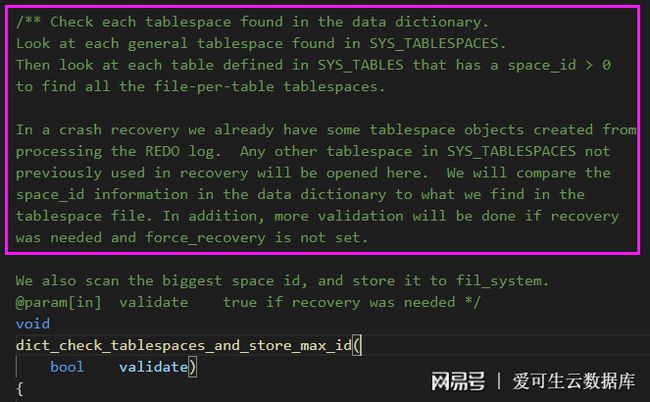
4.4. dict_check_tablespaces_and_store_max_id
最后看下dict_check_tablespaces_and_store_max_id函數,根據注釋介紹,這個函數會檢查所有在數據字典中發現的表空間, 先檢查每個共享表空間,然后檢查每個獨立表空間。
在崩潰恢復中,部分表空間已經在處理 redolog 時被打開(對應之前 GDB 調試時部分表未繼續走下去),而其他沒有被打開的表空間,將會通過比較數據字典中的 space_id 與表空間文件是否一致的方式進行驗證(也就是之前所說的表空間校驗過程)。
五、測試驗證
到這里,原理大概已經知道了,主要就是:MySQL 在崩潰恢復時,會遍歷打開所有 ibd 文件的 header page 驗證數據字典的準確性,如果 MySQL 中包含了大量表,這個校驗過程就會比較耗時。那么我們可以模擬下這個場景,進一步驗證,比如在測試庫中用 sysbench 建 50W 張空表,然后模擬非正常關閉,對比下崩潰恢復時長。
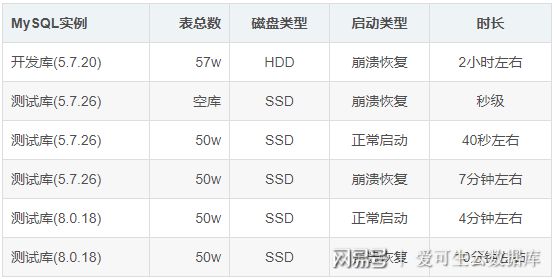
可以看到 MySQL 下崩潰恢復確實和表數量有關,表總數越大,崩潰恢復時間越長。另外磁盤 IOPS 也會影響崩潰恢復時間,像這里開發庫的 HDD IOPS 較低,因此面對大量的表空間,校驗速度就非常緩慢。另外一個發現,MySQL 8 下正常啟用時居然也會進行表空間校驗,而故障恢復時則會額外再進行一次表空間校驗,等于校驗了 2 遍。不過 MySQL 8.0 里多了一個特性,即表數量超過 5W 時,會啟用多線程掃描,加快表空間校驗過程。

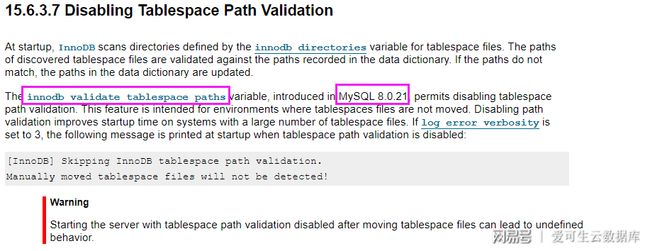
MySQL 8.0.21 開始可以通過innodb_validate_tablespace_paths參數關閉正常啟動時的表空間校驗過程。
六、如何跳過校驗
MySQL 5.7 下有方法可以跳過崩潰恢復時的表空間校驗過程嘛?查閱了資料,方法主要有兩種:1. 配置 innodb_force_recovery可以使 srv_force_recovery != 0 ,那么 validate = false,即可以跳過表空間校驗。實際測試的時候設置 innodb_force_recovery =1,也就是強制恢復跳過壞頁,就可以跳過校驗,然后重啟就是正常啟動了。通過這種臨時方式可以避免崩潰恢復后非常耗時的表空間校驗過程,快速啟動 MySQL,個人目前暫時未發現有什么隱患。2. 使用共享表空間替代獨立表空間這樣就不需要打開 N 個 ibd 文件了,只需要打開一個 ibdata 文件即可,大大節省了校驗時間。自從聽了姜老師講過使用共享表空間替代獨立表空間解決 drop 大表時性能抖動的原理后,感覺共享表空間在很多業務環境下,反而更有優勢。
bool validate = recv_needed_recovery && srv_force_recovery == 0;
//跳過表空間校驗
validate = false
//執行表空間校驗
validate = true
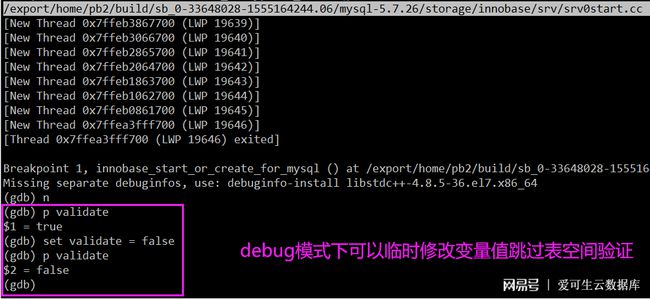
臨時冒出另外一種解決想法,即用 GDB 調試崩潰恢復,通過臨時修改 validate 變量值讓 MySQL 跳過表空間驗證過程,然后讓 MySQL 正常關閉,重新啟動就可以正常啟動了。但是實際測試發現,如果以 debug 模式運行,確實可以臨時修改 validate 變量,跳過表空間驗證過程,但是 debug 模式下代碼運行效率大打折扣,反而耗時更長。而以非 debug 模式運行,則無法修改 validate 變量,想法破滅。

附錄:
https://dev.mysql.com/worklog/task/?id=7142
http://blog.symedia.pl/2015/11/mysql-56-and-57-crash-recovery.html
https://www.percona.com/community-blog/2019/07/23/impact-of-innodb_file_per_table-option-on-crash-recovery-time/
https://jira.mariadb.org/browse/MDEV-18733


![[轉載]linux內存映射mmap原理分析](http://pic.xiahunao.cn/[轉載]linux內存映射mmap原理分析)















)
