又是一個季度一次的現場巡檢,期待數據庫能跑的又快又穩,畢竟這是對DBA最大的饋贈了。
?
結果不遂人意發現在錯誤日志內存在大量的如下報錯:
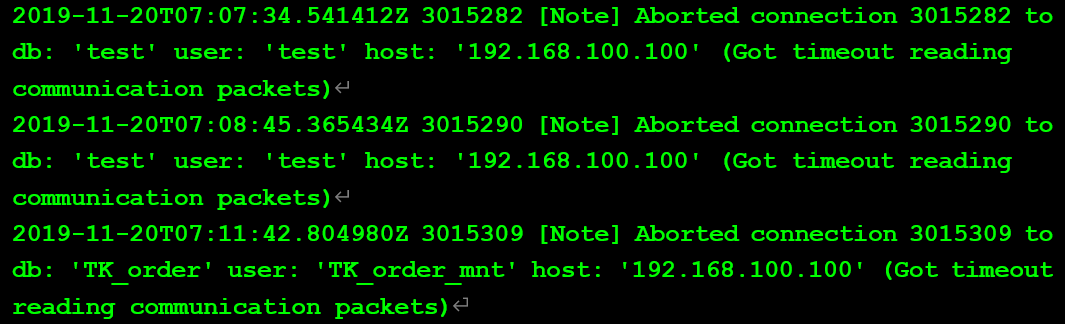
查看當前數據庫的狀態值:
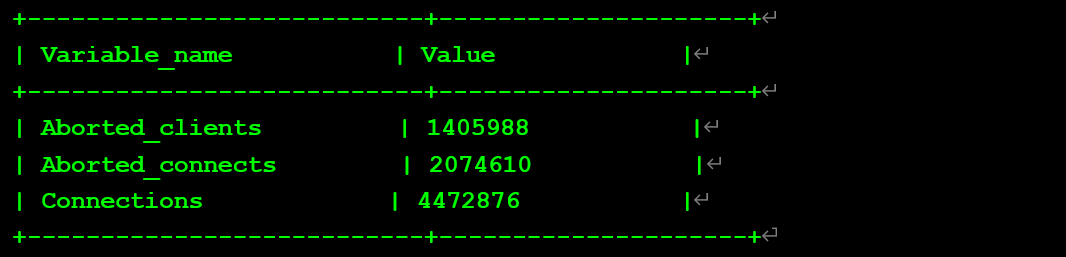
查看數據庫關于數據庫會話的關鍵參數:
數據庫環境及相關參數connect_timeout10
interactive_timeout28800
wait_timeout28800
max_connections151
net_write_timeout60
net_read_timeout30
可見,自數據庫啟動,440萬嘗試連接中,近140萬會話異常退出,近200萬會話未能正常連接到數據庫環境。而排查錯誤日志中該報錯無時間規律,同時客戶反饋在業務層面,經常有長連接斷開的現象。
TIP:
首先我們通過官方文檔來了解Aborted_clients和Aborted_connects兩個狀態變量的代表意義,以及哪些情況或因素會導致這些狀態變量變化呢?

造成Aborted_connects狀態變量增加的可能原因:
1.客戶機試圖訪問數據庫,但沒有數據庫的特權。
2.客戶端使用了錯誤的密碼。
3.連接包不包含正確的信息。
4.獲取一個連接包需要的時間超過connect_timeout秒。

造成Aborted_clients 狀態變量增加的可能原因:
1.程序退出前,客戶機程序沒有調用mysql_close()。
2.客戶端睡眠時間超過了wait_timeout或interactive_timeout秒。
3.客戶端程序在數據傳輸過程中突然終止。
簡單來說即:數據庫會話未能正常連接到數據庫,會造成Aborted_connects變量增加。數據庫會話已正常連接到數據庫但未能正常退出,會造成Aborted_clients變量增加。
根據錯誤日志中報錯:
Got timeout reading communication packets
出現如上錯誤,基本上可判斷為數據庫認證超時導致,或者業務線程異常退出。
客戶反饋并無相關業務客戶端異常退出等操作或現象。
可簡單判斷會話超過interactive_timeout/ wait_timeout限制時間(28800)導致會話被數據庫殺掉,跟應用溝通之后,應用確認其業務邏輯會話均為長連接,不會主動進行斷開操作。如上可初步解釋為何Aborted_clients狀態變量會如此之高。
那又該如何解釋Aborted_connects這個狀態變量如何之高?
能使該狀態變量增加的幾種可能性,我們依次來確認排查。
1.客戶機試圖訪問數據庫,但沒有數據庫的特權。
2.客戶端使用了錯誤的密碼。
3.連接包不包含正確的信息。
4.獲取一個連接包需要的時間超過connect_timeout秒。
關于1、2、3這三點,可統一解釋為 用戶/密碼/權限錯誤導致無法正常連接到數據庫。這幾個錯誤不會在錯誤日志中報該錯誤(Got timeout reading communication packets),錯誤日志中也不存在(Access denied for user)該類錯誤,且業務能正常運行。這樣就能排除這三點的可能性。
那唯一可能就是由于連接認證超時時間超過connect_timeout秒,數據庫層面connect_timeout參數設置為默認的10s。根據官方文檔解釋:
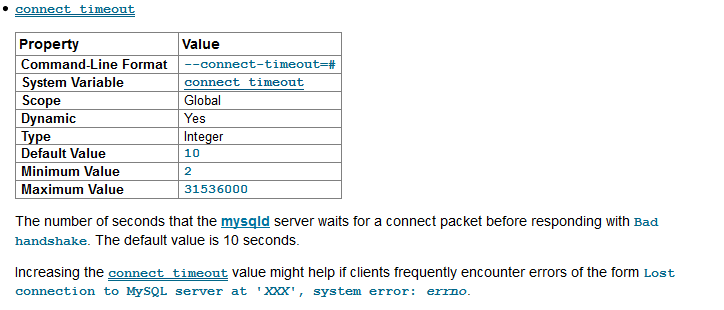
10s基本上能夠支持業務使用。
那還有什么可能呢?
跟客戶確認之后,了解到應用是通過MySQL Router連接到數據庫服務器。檢查Router 參數文件配置,發現如下參數設置

發現在Router的配置中connect_timeout 配置為3s,那是否可能由于客戶端連接數據庫的認證超過該限制導致。
因此建議修改Router配置文件中該參數,然后運行一段時間后是否情況得到一定的改善。
后續排查往網絡方向排查,簡單可通過客戶端長ping數據庫服務端,查看網絡是否存在波動現象。
TIP:
根據官方文檔中介紹,還可能是由于網絡或者硬件層面的問題造成這個問題。

1. max_allowed_packet變量值太小,或者查詢需要的內存比分配給mysqld的內存多。
2. 在Linux中使用以太網協議,包括半雙工和全雙工。一些Linux以太網驅動程序有這個bug。您應該通過在客戶機和服務器機器之間使用FTP傳輸一個大文件來測試這個bug。如果傳輸以突發-暫停-突發-暫停模式進行,那么您正在經歷一種Linux雙工綜合征。將網卡和集線器的雙工模式切換到全雙工或半雙工模式,并測試結果以確定最佳設置。
3. 線程庫中導致讀取中斷的問題。
4. 錯誤的TCP / IP配置。
5. 有故障的以太網、集線器、交換機、電纜等等。只有通過更換硬件才能正確診斷。
下面對各類Aborted connection的可能性進行一定的測試與分析:
測試環境說明:MySQL5.7
測試環境及相關參數connect_timeout10
interactive_timeout28800
wait_timeout28800
max_connections151
net_write_timeout60
net_read_timeout30
注:每次測試前均重啟數據庫重置狀態值,方便后續比較
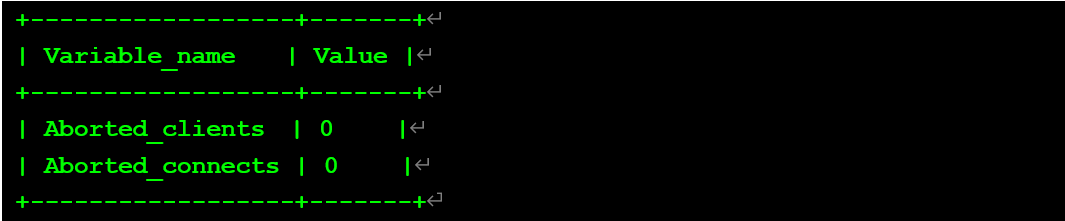
測試一:錯誤密碼、錯誤用戶
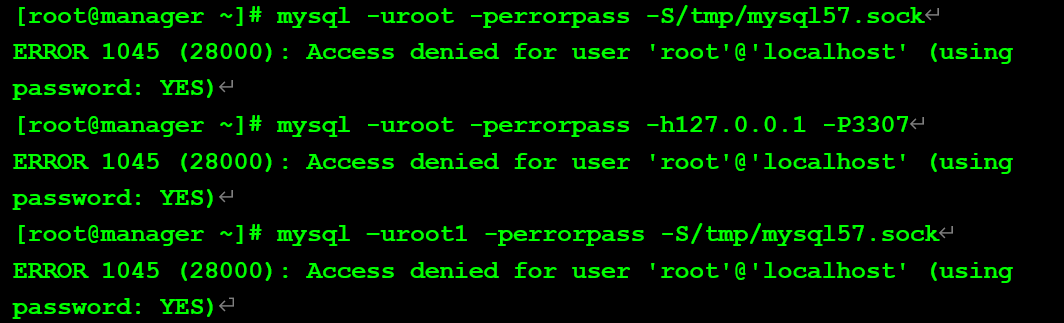
錯誤用戶:數據庫不存在該用戶。
查看數據庫內狀態值:
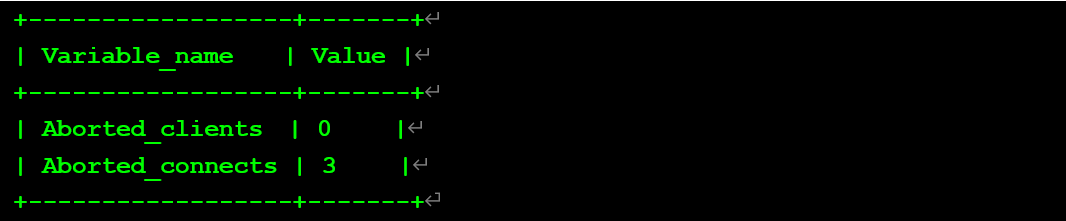
查看錯誤日志:
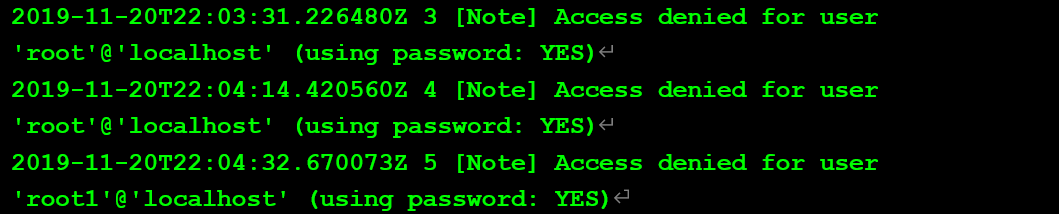
測試二:超時參數
當前數據庫wait_timeout 及interactive_timeout均為默認的28800,下面調整這兩個參數,測試對數據庫連接的行為影響。
該實驗同時修改兩個參數為10:
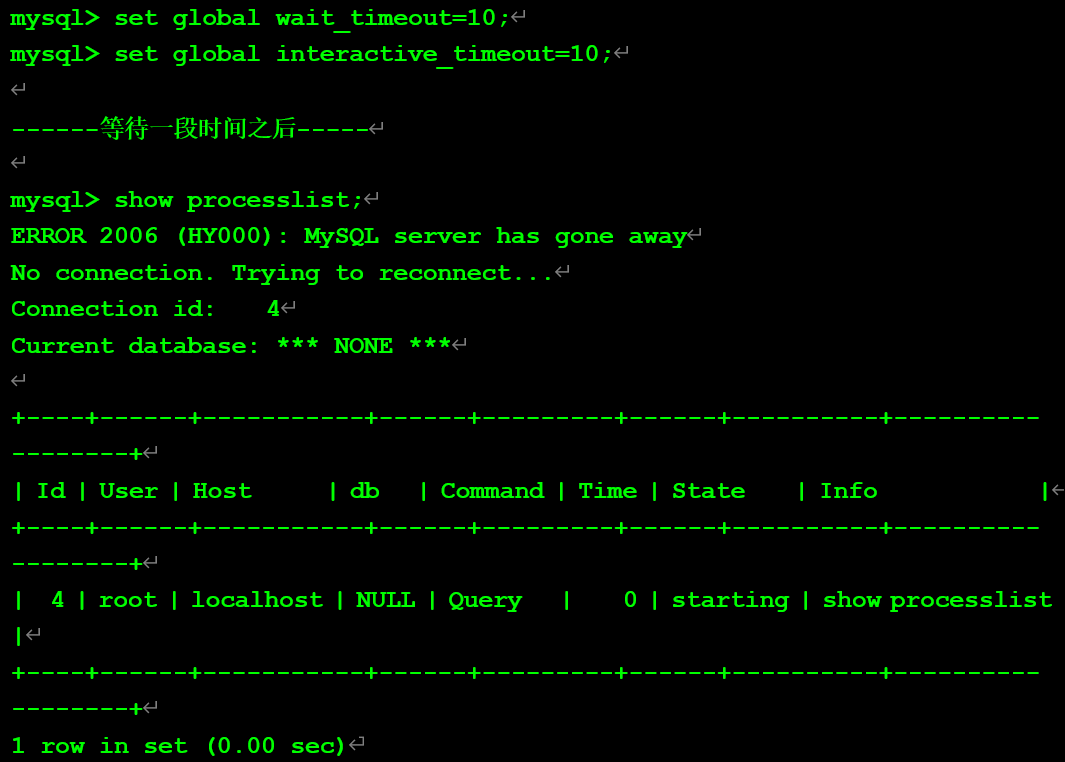
查看數據庫內狀態值:

查看錯誤日志:
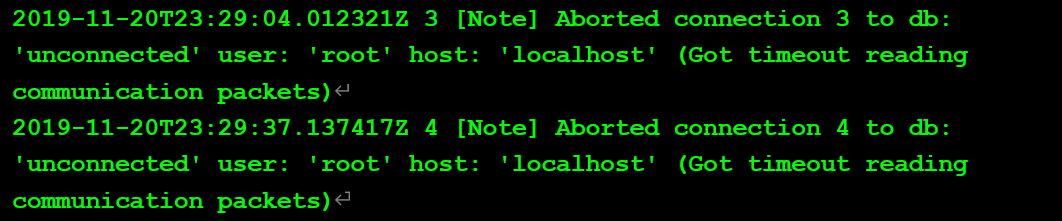
測試三:最大連接數
當前數據庫max_connections參數默認為151,下面調整改參數,測試對數據庫連接的行為影響。
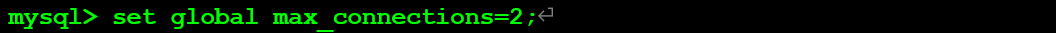
當開啟第四個連接會話,報如下錯誤:

查看數據庫內狀態值
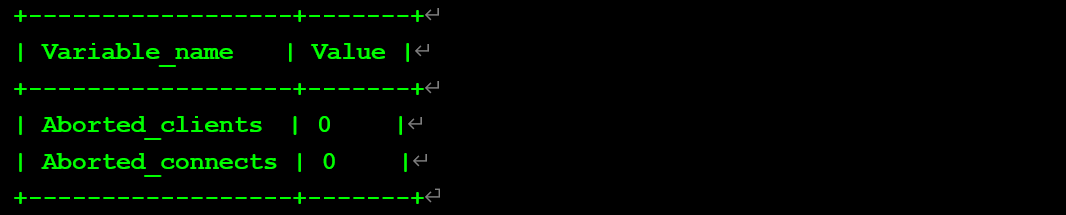
此時錯誤日志無變化。
測試四
第三方工具SQLyog select結果沒有出來的時候選擇停止則出現:

查看數據庫內狀態值:

此時錯誤日志無變化。
結論:
1.建議業務操作結束后使應用程序邏輯以正確關閉連接,以短連接替代長連接。
2.確保max_allowed_packet的值足夠高,并且客戶端沒有收到“數據包太大”消息。
3.確保客戶端應用程序不中止連接。
4.檢查是否啟用了skip-name-resolve,檢查主機根據其IP地址而不是其主機名進行身份驗證。
5.嘗試增加MySQL的net_read_timeout和net_write_timeout值,看看是否減少了錯誤的數量。
參考文獻

》一第2章 基于排名的聚類)



》—第1章1.5節 系統的方法)








是Internet的骨干。 這就是全部的運作方式。...)




