排序一直以來都是讓我很頭疼的事,以前上《數據結構》打醬油去了,整個學期下來才勉強能寫出個冒泡排序。由于要找工作了,也知道排序算法的重要性(據說是面試必問的知識點),所以又花了點時間重新研究了一下。
排序大的分類可以分為兩種:內排序和外排序。在排序過程中,全部記錄存放在內存,則稱為內排序,如果排序過程中需要使用外存,則稱為外排序。下面講的排序都是屬于內排序。
內排序可以分為以下幾類:
(1)、插入排序:直接插入排序、二分法插入排序、希爾排序。
(2)、選擇排序:簡單選擇排序、堆排序。
(3)、交換排序:冒泡排序、快速排序。
外排序可以分為一下幾類(既使用內部存儲也使用外部存儲,內存不夠時建議使用):
(4)、歸并排序
(5)、基數排序
穩定性:就是能保證排序前兩個相等的數據其在序列中的先后位置順序與排序后它們兩個先后位置順序相同。再簡單具體一點,如果A?i == A j,Ai?原來在?Aj 位置前,排序后?Ai??仍然是在?Aj?位置前。
不穩定:簡單選擇排序、快速排序、希爾排序、堆排序不是穩定的排序算法
穩定:冒泡排序、直接插入排序、二分法插入排序,歸并排序和基數排序都是穩定的排序算法。
平均時間復雜度
O(n^2):直接插入排序,簡單選擇排序,冒泡排序。
在數據規模較小時(9W內),直接插入排序,簡單選擇排序差不多。當數據較大時,冒泡排序算法的時間代價最高。性能為O(n^2)的算法基本上是相鄰元素進行比較,基本上都是穩定的。
O(nlogn):快速排序,歸并排序,希爾排序,堆排序。
其中,快排是最好的, 其次是歸并和希爾,堆排序在數據量很大時效果明顯。
排序算法的選擇
1.數據規模較小
(1)待排序列基本序的情況下,可以選擇直接插入排序;
(2)對穩定性不作要求宜用簡單選擇排序,對穩定性有要求宜用插入或冒泡
2.數據規模不是很大
(1)完全可以用內存空間,序列雜亂無序,對穩定性沒有要求,快速排序,此時要付出log(N)的額外空間。
(2)序列本身可能有序,對穩定性有要求,空間允許下,宜用歸并排序
3.數據規模很大
(1)對穩定性有求,則可考慮歸并排序。
(2)對穩定性沒要求,宜用堆排序
4.序列初始基本有序(正序),宜用直接插入,冒泡
一、插入排序
?思想:每步將一個待排序的記錄,按其順序碼大小插入到前面已經排序的字序列的合適位置,直到全部插入排序完為止。
?關鍵問題:在前面已經排好序的序列中找到合適的插入位置。
?方法:
–直接插入排序
–二分插入排序
–希爾排序
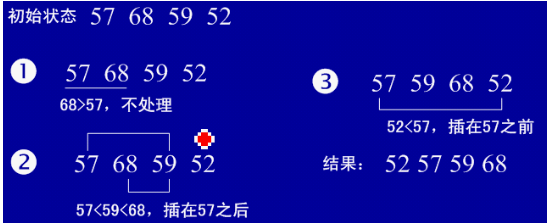
①直接插入排序(從后向前找到合適位置后插入)
1、基本思想:每步將一個待排序的記錄,按其順序碼大小插入到前面已經排序的字序列的合適位置(從后向前找到合適位置后),直到全部插入排序完為止。
2、實例
3、java實現
importjava.util.Scanner;public classMain {public static voidmain(String[] args) {//輸入參數
Scanner in = newScanner(System.in);while(in.hasNext()) {
String inStr=in.nextLine();
String[] str= inStr.split(" ");int a[] = new int[str.length];for (int i = 0; i < a.length; i++) {
a[i]=Integer.parseInt(str[i]);
}//輸出結果
int[] results =zhiJieChaRu(a);
StringBuffer result= newStringBuffer();for (int i = 0; i < results.length; i++) {
result.append(results[i]).append(",");
}//刪除最后一個逗號
if (result.length() > 0) {
result.deleteCharAt(result.length()-1);
}
System.out.println(result);
}
}/*** 直接插入排序。
*@parama
*@return
*/
public static int[] zhiJieChaRu(int[] a) {//直接插入排序
for (int i = 1; i < a.length; i++) {//待插入元素
int temp =a[i];intj;for (j = i - 1; j >= 0; j--) {//將大于temp的往后移動一位
if (a[j] >temp) {
a[j+ 1] =a[j];
}else{break;
}
}
a[j+ 1] =temp;
}returna;
}
}
4、分析
直接插入排序是穩定的排序。
文件初態不同時,直接插入排序所耗費的時間有很大差異。若文件初態為正序,則每個待插入的記錄只需要比較一次就能夠找到合適的位置插入,故算法的時間復雜度為O(n),這時最好的情況。若初態為反序,則第i個待插入記錄需要比較i+1次才能找到合適位置插入,故時間復雜度為O(n2),這時最壞的情況。
直接插入排序的平均時間復雜度為O(n2)。
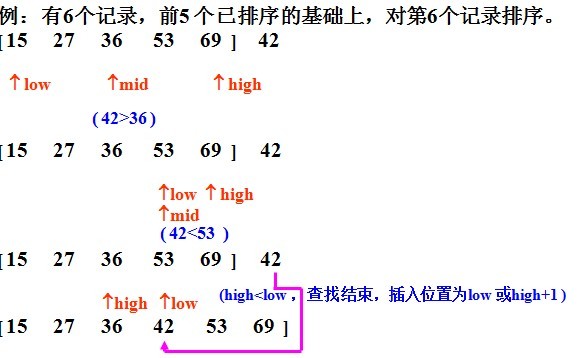
②二分法插入排序(按二分法找到合適位置插入)
1、基本思想:二分法插入排序的思想和直接插入一樣,只是找合適的插入位置的方式不同,這里是按二分法找到合適的位置,可以減少比較的次數。
2、實例
3、java實現
importjava.util.Scanner;public classMain {public static voidmain(String[] args) {//輸入參數
Scanner in = newScanner(System.in);while(in.hasNext()) {
String inStr=in.nextLine();
String[] str= inStr.split(" ");int a[] = new int[str.length];for (int i = 0; i < a.length; i++) {
a[i]=Integer.parseInt(str[i]);
}//調用方法得到數組
int[] results =erFenChaRu(a);//將數組轉換成字符串輸出
StringBuffer result = newStringBuffer();for (int i = 0; i < results.length; i++) {
result.append(results[i]).append(",");
}//刪除最后一個逗號
if (result.length() > 0) {
result.deleteCharAt(result.length()- 1);
}
System.out.println(result);
}
}/*** 二分插入排序
*@parama
*@return
*/
public static int[] erFenChaRu(int[] a) {for (int i = 0; i < a.length; i++) {int temp =a[i];int left = 0;int right = i - 1;int mid = 0;while (left <=right) {
mid= (left + right) / 2;if (temp
right= mid - 1;
}else{
left= mid + 1;
}
}for (int j = i - 1; j >= left; j--) {
a[j+ 1] =a[j];
}if (left !=i) {
a[left]=temp;
}
}returna;
}
}
4、分析
當然,二分法插入排序也是穩定的。
二分插入排序的比較次數與待排序記錄的初始狀態無關,僅依賴于記錄的個數。當n較大時,比直接插入排序的最大比較次數少得多。但大于直接插入排序的最小比較次數。算法的移動次數與直接插入排序算法的相同,最壞的情況為n2/2,最好的情況為n,平均移動次數為O(n2)。
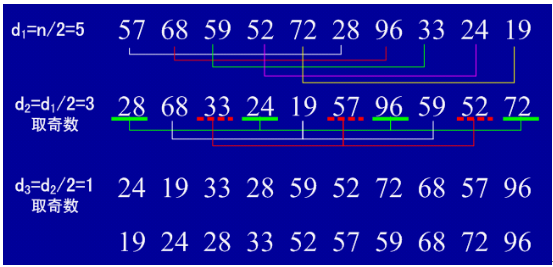
③希爾排序
1、基本思想:先取一個小于n的整數d1作為第一個增量,把文件的全部記錄分成d1個組。所有距離為d1的倍數的記錄放在同一個組中。先在各組內進行直接插入排序;然后,取第二個增量d2
2、實例
3、java實現
/*** 希爾排序。
*@parama
*@return
*/
public static int[] xiErSort(int[] a) {int d =a.length;while (true) {
d= d / 2;for (int x = 0; x < d; x++) {for (int i = x + d; i < a.length; i = i +d) {int temp =a[i];intj;for (j = i - d; j >= 0 && a[j] > temp; j = j -d) {
a[j+ d] =a[j];
}
a[j+ d] =temp;
}
}if (d == 1) {break;
}
}returna;
}
4、分析
我們知道一次插入排序是穩定的,但在不同的插入排序過程中,相同的元素可能在各自的插入排序中移動,最后其穩定性就會被打亂,所以希爾排序是不穩定的。
希爾排序的時間性能優于直接插入排序,原因如下:
(1)當文件初態基本有序時直接插入排序所需的比較和移動次數均較少。
(2)當n值較小時,n和n2的差別也較小,即直接插入排序的最好時間復雜度O(n)和最壞時間復雜度0(n2)差別不大。
(3)在希爾排序開始時增量較大,分組較多,每組的記錄數目少,故各組內直接插入較快,后來增量di逐漸縮小,分組數逐漸減少,而各組的記錄數目逐漸增多,但由于已經按di-1作為距離排過序,使文件較接近于有序狀態,所以新的一趟排序過程也較快。
因此,希爾排序在效率上較直接插人排序有較大的改進。
希爾排序的平均時間復雜度為O(nlogn)。
二、選擇排序
?思想:每趟從待排序的記錄序列中選擇關鍵字最小的記錄放置到已排序表的最前位置,直到全部排完。
?關鍵問題:在剩余的待排序記錄序列中找到最小關鍵碼記錄。
?方法:
–直接選擇排序
–堆排序
①簡單的選擇排序
1、基本思想:在要排序的一組數中,選出最小的一個數與第一個位置的數交換;然后在剩下的數當中再找最小的與第二個位置的數交換,如此循環到倒數第二個數和最后一個數比較為止。
2、實例

3、java實現
/*** 直接選擇排序。
*@parama
*@return
*/
public static int[] zhiJieXuanZe(int[] a) {for (int i = 0; i < a.length; i++) {int min =a[i];int n = i; //最小數的索引
for (int j = i + 1; j < a.length; j++) {if (a[j] < min) { //找出最小的數
min =a[j];
n=j;
}
}
a[n]=a[i];
a[i]=min;
}returna;
}
4、分析
簡單選擇排序是不穩定的排序。
時間復雜度:T(n)=O(n2)。
②堆排序
1、基本思想:
堆排序是一種樹形選擇排序,是對直接選擇排序的有效改進。
堆的定義下:具有n個元素的序列 (h1,h2,...,hn),當且僅當滿足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,...,n/2)時稱之為堆。在這里只討論滿足前者條件的堆。由堆的定義可以看出,堆頂元素(即第一個元素)必為最大項(大頂堆)。完全二 叉樹可以很直觀地表示堆的結構。堆頂為根,其它為左子樹、右子樹。
思想:初始時把要排序的數的序列看作是一棵順序存儲的二叉樹,調整它們的存儲序,使之成為一個 堆,這時堆的根節點的數最大。然后將根節點與堆的最后一個節點交換。然后對前面(n-1)個數重新調整使之成為堆。依此類推,直到只有兩個節點的堆,并對 它們作交換,最后得到有n個節點的有序序列。從算法描述來看,堆排序需要兩個過程,一是建立堆,二是堆頂與堆的最后一個元素交換位置。所以堆排序有兩個函數組成。一是建堆的滲透函數,二是反復調用滲透函數實現排序的函數。
2、實例
初始序列:46,79,56,38,40,84
建堆:
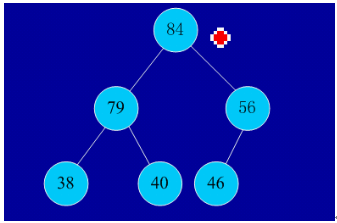
交換,從堆中踢出最大數
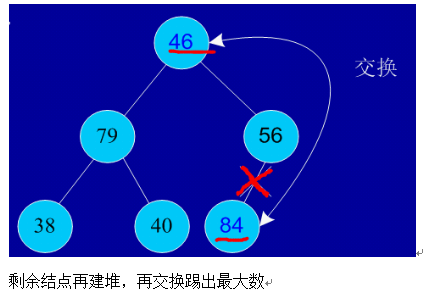
依次類推:最后堆中剩余的最后兩個結點交換,踢出一個,排序完成。
3、java實現
/*** 堆排序
*@parama
*@return
*/
public static int[] heapSort(inta[]) {int arrayLength =a.length;//循環建堆
for (int i = 0; i < arrayLength - 1; i++) {//建堆
buildMaxHeap(a, arrayLength - 1 -i);//交換堆頂和最后一個元素
swap(a, 0, arrayLength - 1 -i);
}returna;
}//對data數組從0到lastIndex建大頂堆
public static void buildMaxHeap(int[] data, intlastIndex) {//從lastIndex處節點(最后一個節點)的父節點開始
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {//k保存正在判斷的節點
int k =i;//如果當前k節點的子節點存在
while (k * 2 + 1 <=lastIndex) {//k節點的左子節點的索引
int biggerIndex = 2 * k + 1;//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k節點的右子節點存在
if (biggerIndex
if (data[biggerIndex] < data[biggerIndex + 1]) {//biggerIndex總是記錄較大子節點的索引
biggerIndex++;
}
}//如果k節點的值小于其較大的子節點的值
if (data[k]
swap(data, k, biggerIndex);//將biggerIndex賦予k,開始while循環的下一次循環,重新保證k節點的值大于其左右子節點的值
k =biggerIndex;
}else{break;
}
}
}
}//交換
private static void swap(int[] data, int i, intj) {int tmp =data[i];
data[i]=data[j];
data[j]=tmp;
}
4、分析
堆排序也是一種不穩定的排序算法。
堆排序優于簡單選擇排序的原因:
直接選擇排序中,為了從R[1..n]中選出關鍵字最小的記錄,必須進行n-1次比較,然后在R[2..n]中選出關鍵字最小的記錄,又需要做n-2次比較。事實上,后面的n-2次比較中,有許多比較可能在前面的n-1次比較中已經做過,但由于前一趟排序時未保留這些比較結果,所以后一趟排序時又重復執行了這些比較操作。
堆排序可通過樹形結構保存部分比較結果,可減少比較次數。
堆排序的最壞時間復雜度為O(nlogn)。堆序的平均性能較接近于最壞性能。由于建初始堆所需的比較次數較多,所以堆排序不適宜于記錄數較少的文件。
三、交換排序
①冒泡排序
1、基本思想:在要排序的一組數中,對當前還未排好序的范圍內的全部數,自上而下對相鄰的兩個數依次進行比較和調整,讓較大的數往下沉,較小的往上冒。即:每當兩相鄰的數比較后發現它們的排序與排序要求相反時,就將它們互換。
2、實例

3、java實現
/*** 冒泡排序。
*@parama
*@return
*/
public static int[] maoPaoSort(inta[]) {//冒泡排序
for (int i = 0; i < a.length; i++) {for(int j = 0; j
if(a[j]>a[j+1]){int temp =a[j];
a[j]= a[j+1];
a[j+1] =temp;
}
}
}returna;
}
4、分析
冒泡排序是一種穩定的排序方法。
?若文件初狀為正序,則一趟起泡就可完成排序,排序碼的比較次數為n-1,且沒有記錄移動,時間復雜度是O(n)
?若文件初態為逆序,則需要n-1趟起泡,每趟進行n-i次排序碼的比較,且每次比較都移動三次,比較和移動次數均達到最大值∶O(n2)
?起泡排序平均時間復雜度為O(n2)
②快速排序
1、基本思想:選擇一個基準元素,通常選擇第一個元素或者最后一個元素,通過一趟掃描,將待排序列分成兩部分,一部分比基準元素小,一部分大于等于基準元素,此時基準元素在其排好序后的正確位置,然后再用同樣的方法遞歸地排序劃分的兩部分。
2、實例

3、java實現
/*** 快速排序。
*@parama
*@return
*/
public static int[] quick(int[] a) {
quickSort(a,0, a.length - 1);returna;
}public static void quickSort(int[] a, int low, inthigh) {if (low < high) { //如果不加這個判斷遞歸會無法退出導致堆棧溢出異常
int middle =getMiddle(a, low, high);
quickSort(a,0, middle - 1);
quickSort(a, middle+ 1, high);
}
}public static int getMiddle(int[] a, int low, inthigh) {int temp = a[low];//基準元素
while (low
while (low < high && a[high] >=temp) {
high--;
}
a[low]=a[high];while (low < high && a[low] <=temp) {
low++;
}
a[high]=a[low];
}
a[low]=temp;returnlow;
}
4、分析
快速排序是不穩定的排序。
快速排序的時間復雜度為O(nlogn)。
當n較大時使用快排比較好,當序列基本有序時用快排反而不好。
四、歸并排序
1、基本思想:歸并(Merge)排序法是將兩個(或兩個以上)有序表合并成一個新的有序表,即把待排序序列分為若干個子序列,每個子序列是有序的。然后再把有序子序列合并為整體有序序列。
2、實例

3、java實現
/*** 歸并排序。
*
*@parama
*@return
*/
public static int[] guiBingSort(int[] a) {
mergeSort(a,0, a.length-1);returna;
}public static void mergeSort(int[] a, int left, intright) {if (left
mergeSort(a, left, middle);//對右邊進行遞歸
mergeSort(a, middle + 1, right);//合并
merge(a, left, middle, right);
}
}public static void merge(int[] a, int left, int middle, intright) {int[] tmpArr = new int[a.length];int mid = middle + 1; //右邊的起始位置
int tmp =left;int third =left;while (left <= middle && mid <=right) {//從兩個數組中選取較小的數放入中間數組
if (a[left] <=a[mid]) {
tmpArr[third++] = a[left++];
}else{
tmpArr[third++] = a[mid++];
}
}//將剩余的部分放入中間數組
while (left <=middle) {
tmpArr[third++] = a[left++];
}while (mid <=right) {
tmpArr[third++] = a[mid++];
}//將中間數組復制回原數組
while (tmp <=right) {
a[tmp]= tmpArr[tmp++];
}
}
4、分析
歸并排序是穩定的排序方法。
歸并排序的時間復雜度為O(nlogn)。
速度僅次于快速排序,為穩定排序算法,一般用于對總體無序,但是各子項相對有序的數列。
五、基數排序
1、基本思想:將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零。然后,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以后,數列就變成一個有序序列。
2、實例
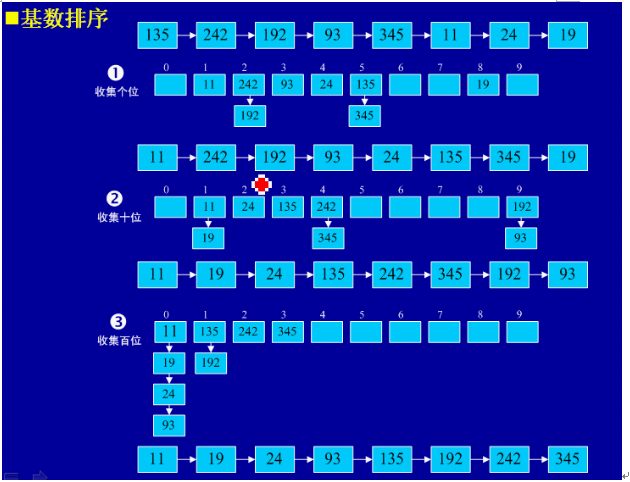
3、java實現
public static int[] jiShuSort(int[] array) {//找到最大數,確定要排序幾趟
int max = 0;for (int i = 0; i < array.length; i++) {if(max
max=array[i];
}
}//判斷位數
int times = 0;while(max>0){
max= max/10;
times++;
}//建立十個隊列
List queue = new ArrayList();for (int i = 0; i < 10; i++) {
ArrayList queue1= newArrayList();
queue.add(queue1);
}//進行times次分配和收集
for (int i = 0; i < times; i++) {//分配
for (int j = 0; j < array.length; j++) {int x = array[j]%(int)Math.pow(10, i+1)/(int)Math.pow(10, i);
ArrayList queue2=queue.get(x);
queue2.add(array[j]);
queue.set(x,queue2);
}//收集
int count = 0;for (int j = 0; j < 10; j++) {while(queue.get(j).size()>0){
ArrayList queue3 =queue.get(j);
array[count]= queue3.get(0);
queue3.remove(0);
count++;
}
}
}returnarray;
}
4、分析
基數排序是穩定的排序算法。
基數排序的時間復雜度為O(d(n+r)),d為位數,r為基數。









)








初始設置)
