Hive是建立在 Hadoop 上的數據倉庫基礎架構,定義了簡單的類 SQL 查詢語言(HQL)
函數分類:
簡單內置函數:數學函數,字符函數,日期函數,條件函數,聚合函數。
高級內置函數:行列轉換函數,分析性函數。
自定義函數:udf。
以上是小編自己整理分類的,網上也有很多不同分類的版本,下圖就是在別人博客中我覺得比較好的分類方法。
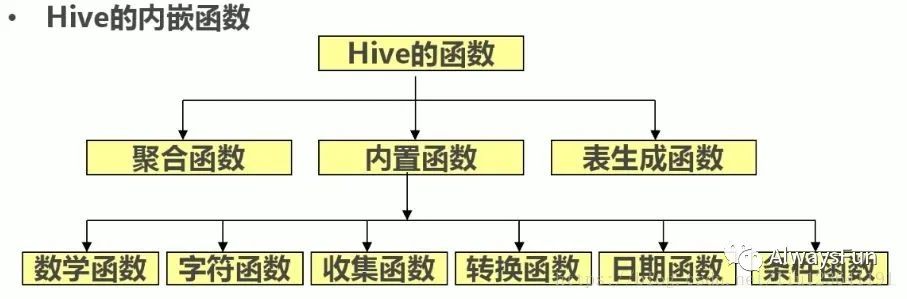
數學函數
round():四舍五入
floor(): 向下取整
ceil(): ?向上取整
rand(): ?隨機數
mod():取余
字符函數
length(string1):長度
concat(string1,string2):拼接
concat_ws(sep,string1,string2):返回按指定分隔符拼接的字符串
lower(string1):小寫字符串 upper():返回大寫字符串
trim(string1):去左右空格,ltrim(string1):去左空格。rtrim(string1):去右空格
reverse(string1):字符串逆置
rpad(string1,len1,pad1):字符右填充。lpad():左填充
split(string1,pat1):分隔字符串返回數組。如split('a,b,c',',')返回["a","b","c"]
substr():截取。如substr('abcde',1,3)返回'abc'
日期函數
curdate:返回當前日期
year(date):month(date):day(date): ?返回日期date的年,月,日,類型為int
datediff(date1,date2):返回日期date1與date2相差的天數
str_to_date將日期格式的字符轉換成指定格式的日期
例子:str_to_date('9-13-2020','%m-%d-%y')結果:2020-09-13
date_format()將日期轉換成字符
例子:date_format('2020/9/13','%Y年%m月%d日')結果:2020年9月13日
條件函數
if(條件,t1,t2):若條件成立,則返回t1,反正返回t2。如if(1>2,100,200)返回200
case when 條件 then t1 else t2 end:若條件成立,則t1,否則t2,可加多重判斷
isnull(a):若a為null則返回true,否則返回false
聚合函數
count():統計行數
sum(col1):統計指定列和
avg(col1):統計指定列平均值
min(col1):返回指定列最小值
max(col1):返回指定列最大值
行轉列函數
lateral ?view explode(split(col1,',')) :同組同列的數據拆分成多行,以sep分隔符區分
列轉行函數
concat_ws(sep, collect_set(col1)) :同組不同行合并成一列,以sep分隔符分隔。collect_set在無重復的情況下也可以collect_list()代替。collect_set()去重,collect_list()不去重
分析類函數
row_number() ?over(partitiion by .. order by .. ):根據partition排序,相同值取不同序號,不存在序號跳躍
rank() over(partition by .. ?order by .):根據partition排序,相同值取相同序號,存在序號跳躍
sum() over(partition by .. order by ..)根據partition排序,累計和
count() over(partition by .. order by ..)根據partition排序,累計行數
UDF函數
UDF(User-Defined Functions)即是用戶定義的hive函數。hive自帶的函數并不能完全滿足業務需求,這時就需要我們自定義函數了
UDF的分類
UDF:one to one,進來一個出去一個,row mapping。是row級別操作,如:upper、substr函數
UDAF:many to one,進來多個出去一個,row mapping。是row級別操作,如sum/min。
UDTF:one to many ,進來一個出去多個。如alteral view與explode

今天無錫也下雪了,從朋友圈盜圖一張,每天進步多一點~
降溫了,大家做好保暖






)




![[樹形dp] Jzoj P3914 人品問題](http://pic.xiahunao.cn/[樹形dp] Jzoj P3914 人品問題)







