/Oracle查詢優化改寫/
--1、coalesce 返回多個值中,第一個不為空的值
select coalesce('', '', 's') from dual;
--2、order by
-----dbms_random.value 生產隨機數,利用隨機數對查詢結果進行隨機排序
select * from emp order by dbms_random.value;
--指定查詢結果中的一列進行排序
select * from emp order by 4;
-----order by 中認為null是最大所以null會排在第一或者最后一個
-----可以利用 nulls first 或者 nulls last 對null進行排序處理
select * from emp order by comm nulls first;
select * from emp order by comm nulls last;
----- 多列排序,job 降序排列,如果工作一樣,按照工號升序排列
select * from emp order by job desc, empno asc;
------依次按照job,empno降序排序
select * from emp order by job, empno desc;
------將empno = 7934 的排在第一位,其余的按照empno將序排列
------ORDER BY DECODE 按照自定義的順序排序,如果沒有
------定義則按照原始值排序 case when then else end 也是同樣的道理
select * from emp order by decode(empno, 7934, 2, 1) asc;
--先按照打的分組排序,然后在分組內按照字段排序
select empno, ename, sal
from emp
order by case
when sal <= 5000 and sal >= 3000 then
0
when sal < 3000 and sal > 1000 then
1
when sal < 1000 then
2
else
3
end asc,
3 asc;
--2
select empno,
ename,
case
when sal <= 5000 and sal >= 3000 then
0
when sal < 3000 and sal > 1000 then
1
when sal < 1000 then
2
else
3
end,
sal
from emp
order by 2 asc, 3 asc;
--3、_ 通配符,代替一個字符。
select T.*, T.ROWID from emp T where t.ename like '_EN%';
---可以通過,將_表示為一個普通的字符,倆種寫法
select T.*, T.ROWID from emp T where t.ename like '_EN%' ESCAPE '';
--4、tanslate
-----對應字符一一替換,每一個字符的替換相當于執行一次REPLACE('C','1')
-----會將job字段中的C全部替換為1
select translate(job, 'CRK', '123') from emp t where t.job = 'CLERK';
---第二個字段為空的時候返回null
select translate(job, 'CRK', '') from emp t where t.job = 'CLERK';
---可以利用這個函數,刪除字段的部分字符,對應位置字符為空
select translate(job, '1CRK', '1') from emp t where t.job = 'CLERK';
--5、內連接、左連接、右連接、外連接
--SQL-92標準寫法,不建議用Oracle特有的= + 來表示連接
--inner join on left join on right join on outer join on
---左右連接的時候,只過濾左邊或者右邊的數據,用左連接作為例子
select a.empno, a.job, a.comm, b.empno, b.job, b.comm
from emp a
left join emp2 b
on (a.empno = b.empno and b.comm is not null);
select a.empno, a.job, a.comm, b.empno, b.job, b.comm
from emp a, emp2 b
where a.empno = b.empno(+)
and b.comm(+) is not null;
--6、in 多列寫法
select *
from emp t
where (t.empno, t.ename) in (select t2.empno, t2.ename from emp t2);
---not in 注意事項:如果在子查詢結果中包含null,not in 則返回null
select * from emp t where t.mgr not in (select mgr from emp2);
-- 7、insert into 如果表中有默認字段嗎,那么不能顯示的插入null,否則表中的字段值
---不會是默認值,依然是null
---8、形成數據結構
---level 代表總共有幾層樹形結構
select level from dual connect by level;
---9、正則表達式(沒必要記住,了解規則和用途就可以了)
---regexp_count 統計匹配的
---regexp_replace 替換匹配的
---regexp_like 用正則表達式模糊查詢
select regexp_count('abc,bcd,ddd,4434', ',') from dual;
select regexp_replace('abc,bcd,ddd,4434', ',') from dual;
---X 報表分析精華--Oracle分析函數
--listagg(x,',') within group (order by x)
--將某個字段的多列用逗號(,)連接起來
--同樣的方法有wm_concat,但是
select job, listagg(ename, ',') within group(order by ename asc)
from emp
group by job;
---10、instr 字符串位置查找函數
--- 查找分割符的位置,然后截取
--- 從第一個字符開始,檢索第二次出現的位置
select instr('zzz,xxx,tt', ',', '1', '2') from dual;
---11、count(*) 當表中沒有數據時返回一條數據值為0,當有group by 的時候 沒有數據返回
---12、 sum() over (order by x) 按順序累加
---(如果需要計算累計差,可以將數字轉換為負數,然后計算累積和)
select ENAME, SAL, SUM(SAL) OVER(ORDER BY EMPNO) from emp;
---13、分析函數
----按照分組排序獲取第一個值或者最后一個值
---- max(ename) keep(dense_rank first order by sal desc) over()
select empno,
ename,
sal,
max(ename) keep(dense_rank first order by sal desc) over(),
max(sal) keep(dense_rank first order by sal desc) over(),
max(ename) keep(dense_rank last order by sal desc) over()
from emp;
---獲取分組的最后一個值
select deptno,
max(ename) keep(dense_rank last order by sal desc),
max(sal) keep(dense_rank last order by sal desc),
max(ename) keep(dense_rank last order by sal desc)
from emp group by deptno;
---- lead 獲取當前行下一行的數據, lag獲取當前行上一行的數據
select ename,
sal,
lead(sal) over(order by sal),
lag(sal) over(order by sal)
from emp
order by sal;
----14、extract 函數返回值為數字,獲取時間字段的某一個值
select extract(day from sysdate) from dual;
---- to_char(sysdate,'xxx') d day 1 ww iw ...
---- next_day 1234567 下一個 1 代表周天 2代表周一。。。>
select to_char(sysdate, 'day') from dual;
select next_day(sysdate, 1) from dual;
--月歷
select max((case dd
when 2 then
d
end)) d1
from (select to_char(dt, 'iw') weak,
to_char(dt, 'dd') d,
to_number(to_char(dt, 'd')) dd
from (select (trunc(sysdate, 'mm') + level - 1) dt
from dual
connect by level <= 30))
group by weak
order by weak
--rows between 分析函數開窗 (按行)
--range between 按照范圍開窗(針對數字和日期列)
select sum(sal) over(order by empno rows between unbounded preceding and 1 preceding)
from emp;
-----15 求余數函數
select mod(34, 4) from dual;
-----16 分頁常用偽列 rownum
----- 16.1 先排序,在獲取rownum取值
----- 16.2 獲取rownum的值后才能按照分頁過濾
-----17 SQL動態分割字符串
----- 知道分隔符,但每一個都可能包含多個分割符
---- 針對的是一行數據的結果,
---- level 樹形結構查詢結構
select regexp_substr(l, '[^,]+', 1, level)
from test6
where id = 1
connect by level <= regexp_count(l, ',');
----18、行轉列 pivot 等價與 case when
----帶有聚合函數的時候,不要使用倆次或倆次以上的pivot
select *
from (select job, ename, deptno from emp) pivot(count(ename) as c for deptno in(10 as d10,
20 as d20,
30 as d30));
select *
from (select deptno, ename, job from emp) pivot(count(ename) as c for job in('CLERK' as
job_clark,
'SALESMAN' as
job_SALESMAN,
'MANAGER' as
job_MANAGER,
'ANALYST' as
job_ANALYST,
'PRESIDENT' as
job_PRESIDENT));
----19、列轉行 unpivot (同樣的需求可以用 union all 處理),要保證轉換的列有同樣的
----數據類型
-----unpivot include unlls 包含空值
select
from (select
from (select job, ename, deptno from emp) pivot(count(ename) as c for deptno in(10 as d10,
20 as d20,
30 as d30))) unpivot(sal for deptno in(d10_c,
d20_c,
--包含null值 d30_c));
select * from emp unpivot INCLUDE NULLS(salZE for lie in(SAL, COMM));
----20、ceil(rn/5) 返回大于或等于表達式的最小整數
---- ceil 按照5個一組編號,然后在組內排序加序號
---- 然后用序號進行行轉列
select *
from (select gp,
ename,
row_number() over(partition by gp order by ename) xh
from (select ceil(rn / 5) gp, ename
from (select rownum rn, ename
from (select ename from emp order by ename)))) pivot(max(ename) as x for xh in(1 as e1,
2 as e2,
----21 ntile(3) over 多數據進行分組,3為分組約定
select ntile(3) over(order by empno),empno,ename from emp where job in ('CLERK', 'MANAGER')
----22 rollup 求統計列的合計值
---- grouping(deptno) 該列被匯總的時候 返回值為1 ,否則返回0
---- 處理分組字段存在空的情況下,與合計行無法區分
select deptno,sum(sal) from emp group by rollup (deptno)
-- emp 按照 deptno, job, empno 分組,同時計算出 deptno, job, empno 的合計、deptno, job的合計
-- deptno 的合計
--grouping 用來區分合計列
select deptno, job, empno, sum(sal), grouping(deptno), grouping(job),grouping(empno)
from emp
group by rollup(deptno, job, empno);
--cube 按照 deptno, job, empno 各種可能組合計算合計,最后加一行總計
--grouping_id deptno,job,empno 三種可能組合合計的分類ID
select deptno, job, empno, sum(sal), grouping_id(deptno,job,empno)
from emp
group by cube(deptno, job, empno);
select deptno,
job,
sum(sal),
grouping_id(deptno, job),
case grouping_id(deptno, job)
when 0 then
'按照部門和工作分組'
when 1 then
'按照部分分組'
when 2 then
'按照工作分組'
when 3 then
'總合計'
end fl
from emp
where emp.deptno is not null
and emp.job is not null
group by cube(deptno, job);
----23 lpad rpad 左右補齊位數
----第二個參數代表字符串
----第二個參數代表期望的長度,不足補齊,超過截取
----第三個參數代表如果字符串長度不夠則用這個補齊
select rpad(1,2,',') from dual;
select lpad(1,2,',') from dual;
----24 九九乘法表
with x as(
select level lv from dual connect by level <=9)
, xx as(
select x1.lv lv_a,x2.lv lv_b, to_char(x1.lv) || ' * ' ||
to_char(x2.lv) || ' = ' || to_char(x1.lv * x2.lv) c from x x1,x x2 where x1.lv <= x2.lv)
select lv_b,listagg(c,' ') within group(order by lv_b) from xx group by lv_b; 3 as e3,
4 as e4,
-----25 遞歸查詢
----(PRIOR ename) 獲取上一級的信息,可以獲取所有列的信息
---- PRIOR 指定按照哪一個字段進行遞歸
---- connect by PRIOR emp.empno = emp.mgr 找出與本級empno 相等的mgr數據,向下遞歸
---- connect by emp.empno = PRIOR emp.mgr 找出與本級mgr 相等的empno數據,向上遞歸
select empno, ename,mgr,(PRIOR ename)
from emp
start with empno = '7902'
connect by PRIOR emp.empno = emp.mgr;
--偽列
--level 層級編碼
--connect_by_isleaf 葉子節點標識
select empno, ename,mgr,(PRIOR job),level,connect_by_isleaf
from emp
start with empno = '7902'
connect by PRIOR emp.empno = emp.mgr;
---sys_connect_by_path 可以將層級中的部分字段連接起來(按照層級連接)
--- 3、2、1 連接;2、1連接;1連接
select empno,
ename,
mgr,
(PRIOR job),
level,
connect_by_isleaf,
sys_connect_by_path(ename, ',')
from emp
start with empno = '7902'
connect by emp.empno = PRIOR emp.mgr;
--- order siblings by 樹形分支,分別排序,不按照整體結構排序
---無法看清層級結構
select empno, ename,mgr,(PRIOR job),level,connect_by_isleaf
from emp
start with empno = '7566'
connect by PRIOR emp.empno = emp.mgr
order siblings by empno;
--- 樹形查詢中 where 字段過濾的是查詢結果,
--- 所以如果需要樹形查詢部分數據,必須先過濾,然后作為子查詢結構
--- 進行樹形查詢
select
from (select from emp where deptno = '20')
start with mgr is null
connect by prior empno = mgr;
--如果要過濾一個完整的分支
--需要在connect by prior 后加入過濾語句
--不能在where中加入
select *
from emp
start with mgr is null
connect by prior empno = mgr
and empno !='7566';
----26、取各個分組的 最大最小 第一行 最后一行
select job,
first_value(ename) over(partition by job order by sal desc),
max(ename) keep(dense_rank first order by sal desc) over(partition by job),
last_value(ename) over(partition by job order by sal desc),
max(ename) keep(dense_rank last order by sal desc) over(partition by job)
from emp;
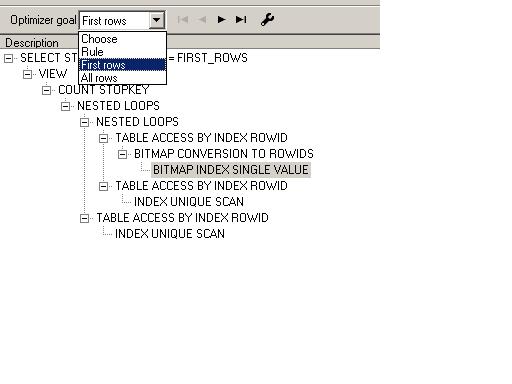
Oracle 在執行SQL語句時,有兩種優化方法:即基于規則的RBO和基于代價的CBO。 在SQL執教的時候,到底采用何種優化方法,就由Oracle參數 optimizer_mode 來決定。
SQL> show parameter optimizer_mode
PL/SQL F5 根據不同的選擇應用不同的優化方法
)





)

)




)
)




