1:Hadoop分布式計算平臺是由Apache軟件基金會開發的一個開源分布式計算平臺。以Hadoop分布式文件系統(HDFS)和MapReduce(Google MapReduce的開源實現)為核心的Hadoop為用戶提供了系統底層細節透明的分布式基礎架構。
?注意:HADOOP的核心組件有:
1)HDFS(分布式文件系統)
2)YARN(運算資源調度系統)
3)MAPREDUCE(分布式運算編程框架)
????? Hadoop 中的分布式文件系統 HDFS 由一個管理結點 ( NameNode )和N個數據結點 ( DataNode )組成,每個結點均是一臺普通的計算機。在使用上同我們熟悉的單機上的文件系統非常類似,一樣可以建目錄,創建,復制,刪除文件,查看文件內容等。但其底層實現上是把文件切割成 Block,然后這些 Block 分散地存儲于不同的 DataNode 上,每個 Block 還可以復制數份存儲于不同的 DataNode 上,達到容錯容災之目的。NameNode 則是整個 HDFS 的核心,它通過維護一些數據結構,記錄了每一個文件被切割成了多少個 Block,這些 Block 可以從哪些 DataNode 中獲得,各個 DataNode 的狀態等重要信息。
???? MapReduce 是 Google 公司的核心計算模型,它將復雜的運行于大規模集群上的并行計算過程高度的抽象到了兩個函數,Map 和 Reduce, 這是一個令人驚訝的簡單卻又威力巨大的模型。適合用 MapReduce 來處理的數據集(或任務)有一個基本要求: 待處理的數據集可以分解成許多小的數據集,而且每一個小數據集都可以完全并行地進行處理。基于它寫出來的程序能夠運行在由上千臺商用機器組成的大型集群上,并以一種可靠容錯的方式并行處理T級別的數據集,實現了Haddoop在集群上的數據和任務的并行計算與處理。
?個人認為,從HDFS(分布式文件系統)觀點分析,集群中的服務器各盡其責,通力合作,共同提供了整個文件系統的服務。從職責上集群服務器以各自任務分為namenode、datanode服務器.其中namenode為主控服務器,datanode為數據服務器。Namenode管理所有的datanode數據存儲、備份、組織記錄分配邏輯上的處理。說明白點namenode就是運籌帷幄、負責布局指揮將軍,具體的存儲、備份是由datanode這樣的戰士執行完成的。故此很多資料將HDFS分布式文件系統的組織結構分為master(主人)和slaver(奴隸)的關系。其實和namenode、datanode劃分道理是一樣的。
從MapReduce計算模型觀點分析,Map/Reduce框架和分布式文件系統是運行在一組相同的節點上的,也就是說計算節點和存儲節點在一起。這種配置允許在那些已經存好數據的節點上高效的調度任務,這樣可以使整個集群的網絡寬帶得到非常高效的利用。另外,在Hadoop中,用于執行MapReduce任務的機器有兩個角色:JobTracker,TaskTracker。JobTracker(一個集群中只能有一臺)是用于管理和調度工作的,TaskTracker是用于執行工作的。
在技術方面Hadoop體系具體包含了以下技術:
Common:在0.20及以前的版本中,包含HDFS、MapReduce和其他項目公共內容,從0.21開始HDFS和MapReduce被分離為獨立的子項目,其余內容為Hadoop Common。
?
1:HADOOP(hdfs、MAPREDUCE、yarn) :元老級大數據處理技術框架,擅長離線數據分析;
2:Avro:新的數據序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制。
3:MapReduce:并行計算框架,0.20前使用org.apache.hadoop.mapred舊接口,0.20版本開始引入org.apache.hadoop.mapreduce的新API。? 分布式運算程序開發框架;
4:HDFS:Hadoop分布式文件系統(Hadoop Distributed File System)。分布式文件系統;
5:Pig:大數據分析平臺,為用戶提供多種接口。
6:Hive:數據倉庫工具,由Facebook貢獻。基于大數據技術(文件系統+運算框架)的SQL數據倉庫工具;數據倉庫工具,使用方便,功能豐富,基于MR延遲大;
7:Hbase:類似Google BigTable的分布式NoSQL列數據庫。(HBase和Avro已經于2010年5月成為頂級Apache項目)。基于HADOOP的分布式海量數據庫;分布式海量數據庫,離線分析和在線業務通吃;
8:ZooKeeper:分布式鎖設施,提供類似Google Chubby的功能,由Facebook貢獻。分布式協調服務基礎組件;分布式協調服務基礎組件;
9:Sqoop:Sqoop是一個用來將Hadoop和關系型數據庫中的數據相互轉移的工具,可以將一個關系型數據庫(例如 :MySQL, Oracle, Postgres等)中的數據導入到Hadoop的HDFS中,也可以將HDFS的數據導入到關系型數據庫中。數據導入導出工具;
10:Oozie:負責MapReduce作業調度。工作流調度框架;
11:Mahout:基于mapreduce/spark/flink等分布式運算框架的機器學習算法庫。
12:Flume:日志數據采集框架;數據采集框架;
?
以上對Hadoop體系框架和相應技術做了相應分析,并從HDFS、MapReduce的角度分析了集群中的角色扮演,這既是我們實驗的理論基礎,也是實驗研究Hadoop深層次系統知識體系結構的意義所在。
Hadoop集群簡介:
1)HADOOP集群具體來說包含兩個集群:HDFS集群和YARN集群,兩者邏輯上分離,但物理上常在一起
2)HDFS集群:
負責海量數據的存儲,即負責數據文件的讀寫操作,集群中的角色主要有 NameNode (Hdfs的大哥)/ DataNode(Hdfs的小弟)
3)YARN集群:
負責海量數據運算時的資源調度,即負責為mapreduce程序分配運算硬件資源,集群中的角色主要有 ResourceManager (Yarn的小哥)/NodeManager(Yarn的小弟)
4)注意:節點分配思想,hdfs是數據的存儲,所以DataNode存儲數據,而yarn是資源調度,所在的機器正好存在數據,就可以進行調度,否則通過網絡傳輸,在yarn上ResourceManager對NodeManager進行管理,管理資源調度?。
5)如果,集群搭建案例,以5節點為例進行搭建,角色分配如下:
機器-01 ???NameNode ?SecondaryNameNode
機器-02 ???ResourceManager
機器-03?? DataNode ???NodeManager
?? 機器-04?? DataNode ???NodeManager
? ? 機器-05?? DataNode ???NodeManager
2:首先自己搞三臺虛擬機,這里使用centOs虛擬機(本實驗只搭建一個有三臺主機的小集群。三臺機器的具體分工命名如下):
| IP | 主機名 | 功能角色 |
| 192.168.3.129 | ?CentOS-01/master(主人) | namenode(控制節點)、JobTracker(工作分配) |
| 192.168.3.130 | ?CentOS-02/slaver1(奴隸) | datanode(數據節點)、TaskTracker(任務執行) |
| 192.168.3.131 | ?CentOS-03/slaver2(奴隸) | datanode(數據節點)、TaskTracker(任務執行) |
?3:講解一下網絡配置,不然好多小伙伴不知道網絡怎么搞,以至于一直拖延不前:
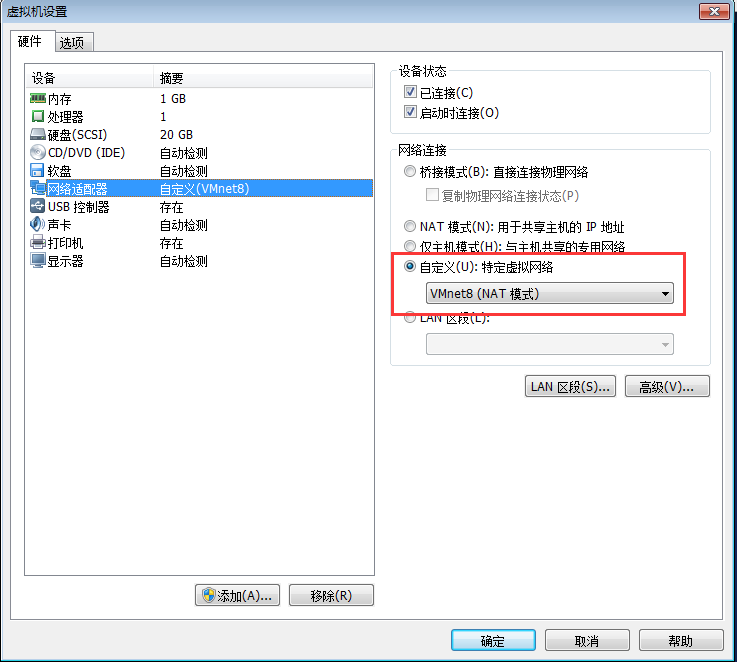
首先,在VMware軟件里面的編輯----》虛擬網絡編輯器---》選擇VMnet8模式
?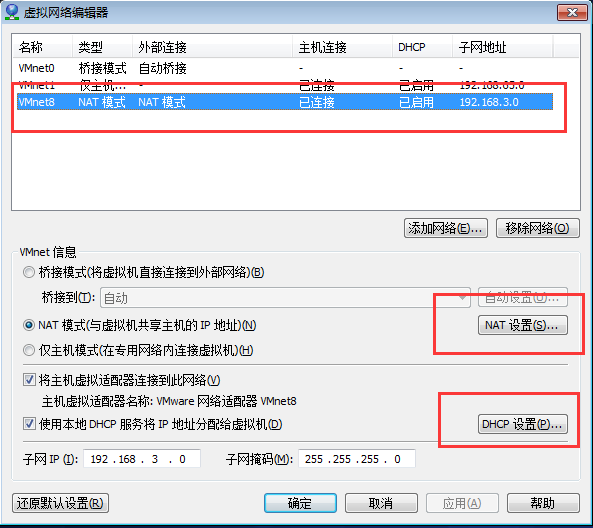
然后選擇NET設置,將網關ip修改為這個模式192.168.x.1格式:
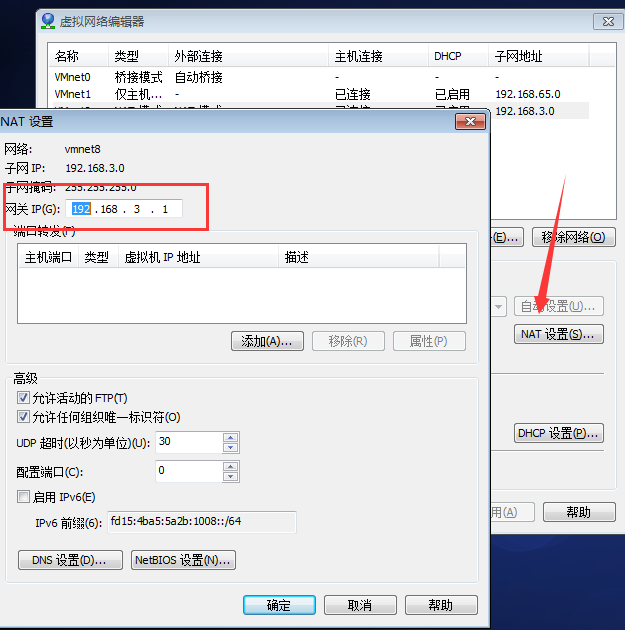
然后選擇DHCP設置,自己可以選擇的ip地址范圍:
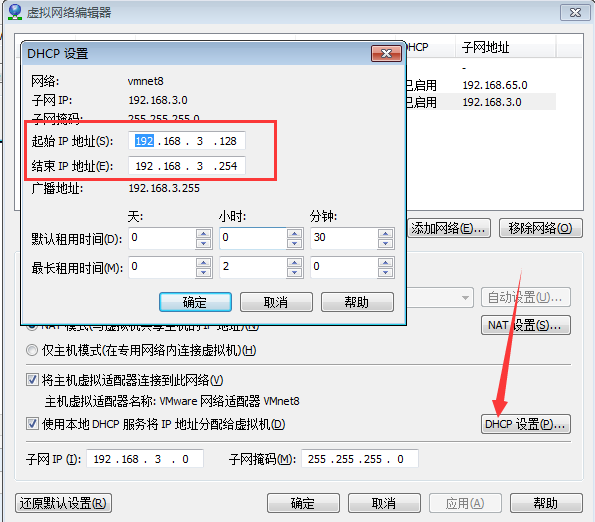
然后找到本地的網絡設置,設置一下本地網絡:
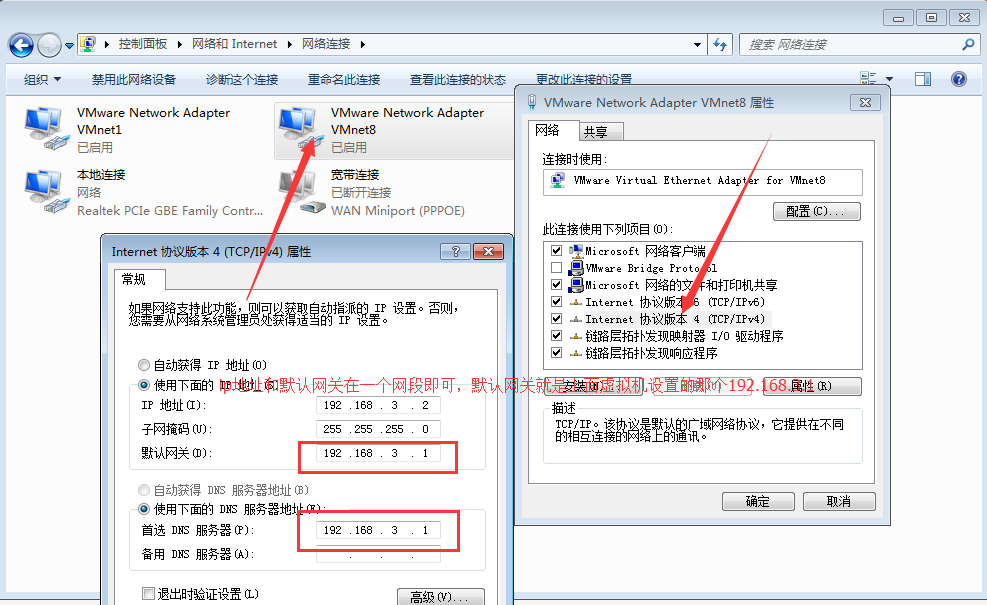
然后開始設置虛擬機的靜態ip地址,如下所示,三個虛擬機按照如下進行設置,下面只寫一個虛擬機,其他兩個類比即可:
?鼠標右擊找到Edit Connections:
然后進行編輯:
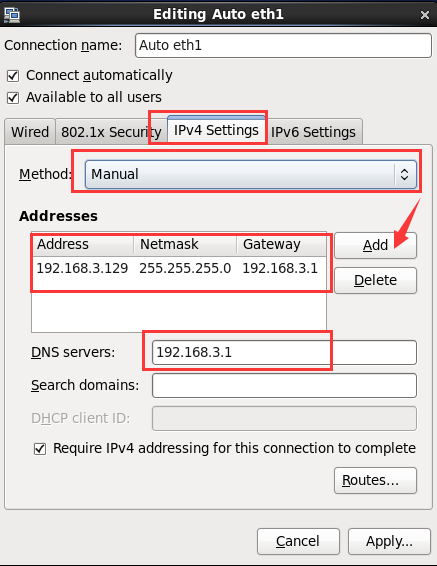
注意下面紅色圈起來的地方(Address分別設置成自己容易識別的,我的是192.168.3.129,192.168.3.130,192.168.3.131):
最后網絡就可以使用了,使用XShell進行遠程連接方便操作:
需要注意的是這里的網絡設置必須是Net8模式的:
?4:Hadoop完全分布式的安裝需要以下幾個過程:
1 綜述:Hadoop完全分布式的安裝需要以下幾個過程: 2 (1)為防止權限不夠,三臺機器均開啟root登錄。 3 (2)為三臺機器分配IP地址及相應的角色。 4 (3)對三臺機器進行jdk安裝并配置環境變量。 5 (4)對三臺機器進行ssh(安全外殼協議)遠程無密碼登錄安裝配置。 6 (5)進行Hadoop集群完全分布式的安裝配置。 7 下面對以上過程進行詳細敘述。
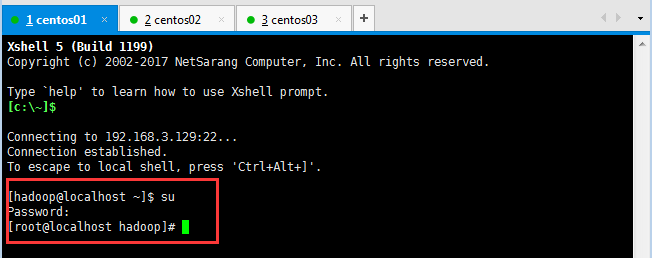
5:切換root用戶進行操作(三臺機器都執行此操作即可):
1)如果正式工作了,建議使用自己的用戶,而非root用戶(詳細創建用戶命令可百度):
useradd 用戶名稱;
passwd 密碼;
2)新建用戶以后,會遇到一些很煩心的事情,這個時候修改:vim /etc/sudoers新用戶的權限,如給hadoop用戶添加執行的權限;
6:在三臺主機上分別設置/etc/hosts及/etc/sysconfig/network(centos操作系統)?????? /etc/hostname(ubuntu操作系統):
hosts文件用于定義主機名與IP地址之間的對應關系(三臺主機配置相同)。
如下所示:
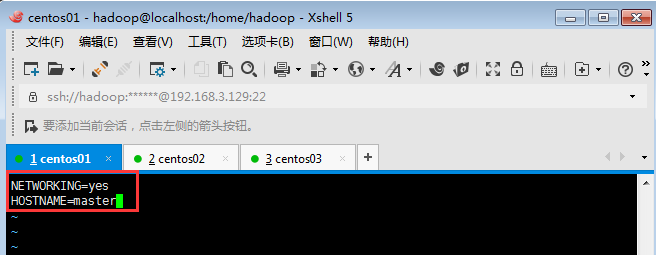
執行此命令:[root@localhost hadoop]# vim /etc/sysconfig/network
主節點修改為master:
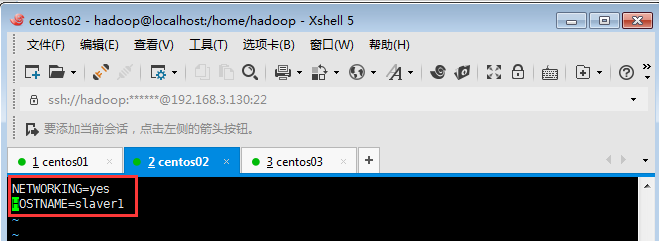
?節點一修改為slaver1
??節點二修改為slaver2

然后修改主機名稱和ip的對應關系:
三臺主機配置相同:
如下命令:[root@localhost hadoop]# vim /etc/hosts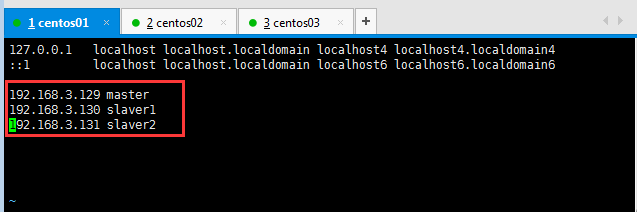
配置好以后進行重啟三臺電腦即可(重啟命令reboot):
自己可以進行驗證一下是否修改正確,如ping master/ping slaver1/ping slaver2:
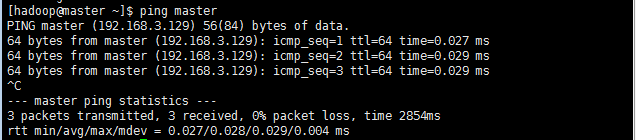
7:三臺機器上安裝jdk(將linux版本的jdk上傳到虛擬機,上傳操作之前說過,此處省略,注意jdk的是linux版本的):
上傳之后進行解壓縮和配置環境變量:
?
配置一下jdk的環境變量(必須用root權限進行修改配置文件):
[root@master hadoop]# vim /etc/profile
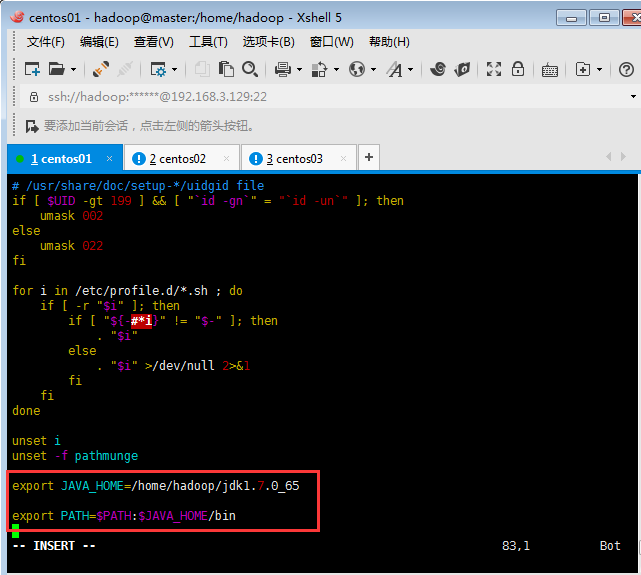
然后驗證三臺機器的jdk是否安裝成功:
驗證之前先刷新一下配置文件:[root@slaver1 hadoop]# source /etc/profile
然后使用java/javac/java -version三個命令分別在三臺機器上面進行驗證:
8:安裝SSH,配置免秘鑰登錄操作,由于我的已經安裝好了,所以這一步略過,自己可以去百度,直接配置免秘鑰登錄:
生成密鑰并配置SSH免密碼登錄本機,執行以下命令,生成密鑰對,并把公鑰文件寫入授權文件中:
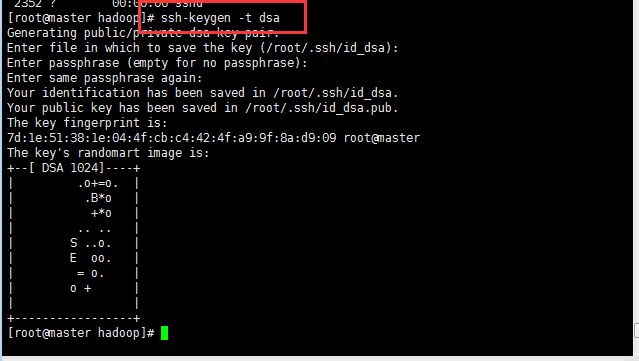
?生成密鑰對,并把公鑰文件寫入授權文件中,cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys會自動創建authorized_keys文件,然后將id_dsa.pub的內容寫到authorized_keys文件里面,這個時候去查看authorized_keys已經存在id_dsa.pub里面的內容(生成密鑰對及授權文件,公鑰在/root/.ssh/下):
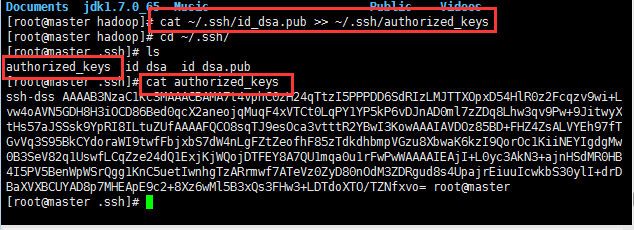
然后將授權文件復制到slaver1主機中,輸入命令:
[hadoop@master .ssh]$ scp authorized_keys root@192.168.3.130:~/.ssh/
可以看到slaver1已經存在授權文件:
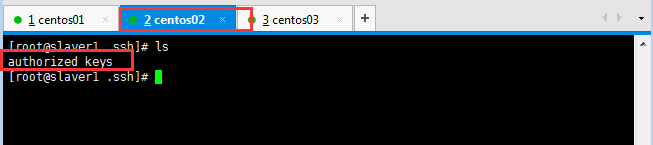
然后在slave1機器中,使用同樣命令生成密鑰對,將公鑰寫入授權文件中。然后將slaver1主機中的授權文件復制到slaver2中,使用同樣命令生成密鑰對,將公鑰寫入授權文件中。這樣就完成了同一個授權文件擁有三個公鑰。最后將此時的授權文件分別復制到master主機、slaver1主機中,這樣就完成了,ssh免密登錄驗證工作。
為了防止防火墻禁止一些端口號,三臺機器應使用
關閉防火墻命令:ufw disable
重啟三臺機器,防火墻關閉命令才能生效,重啟后后查看是否可以從master主機免密碼登錄slaver,輸入命令:ssh slaver1,ssh slaver2:
在slaver1進行生成密鑰對,將公鑰寫入授權文件中:
?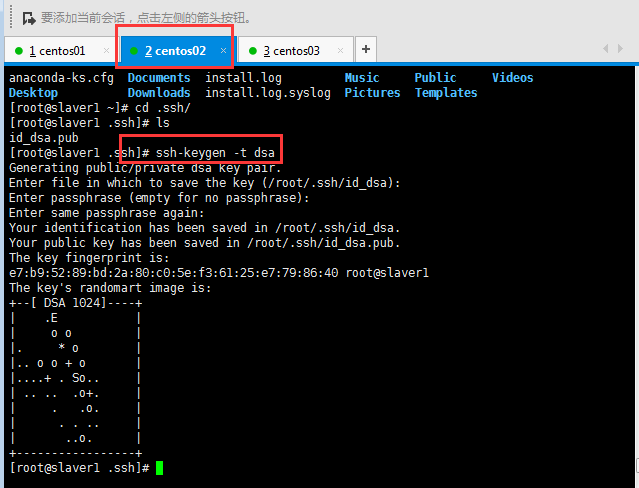
?將公鑰寫入授權文件中:
?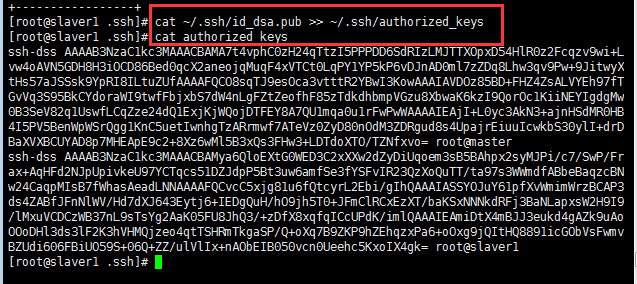
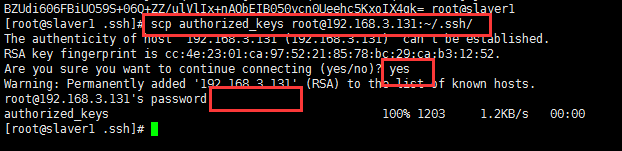
然后將slaver1主機中的授權文件復制到slaver2中,使用同樣命令生成密鑰對,將公鑰寫入授權文件中。
?
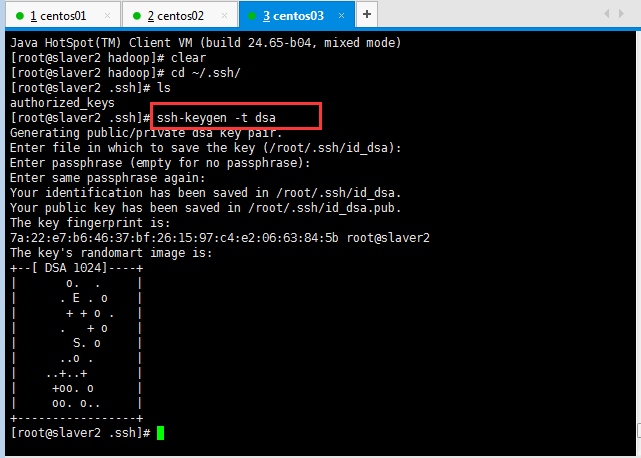
?使用同樣命令在slaver2生成密鑰對,將公鑰寫入授權文件中。
?
將公鑰寫入授權文件中:
?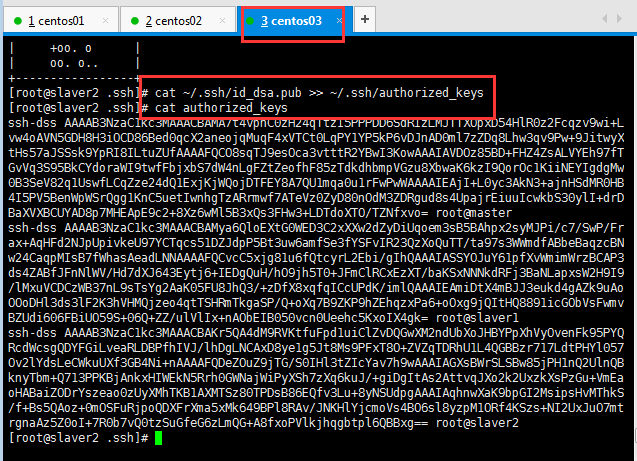
這樣就完成了同一個授權文件擁有三個公鑰。最后將此時的授權文件分別復制到master主機、slaver1主機中,這樣就完成了,ssh免密登錄驗證工作。
?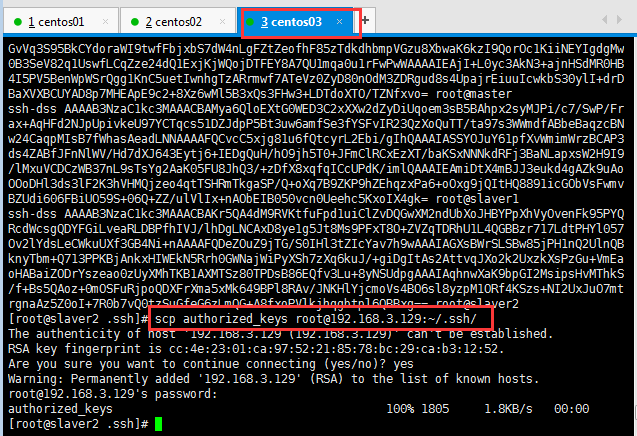
然后查看master的授權文件:
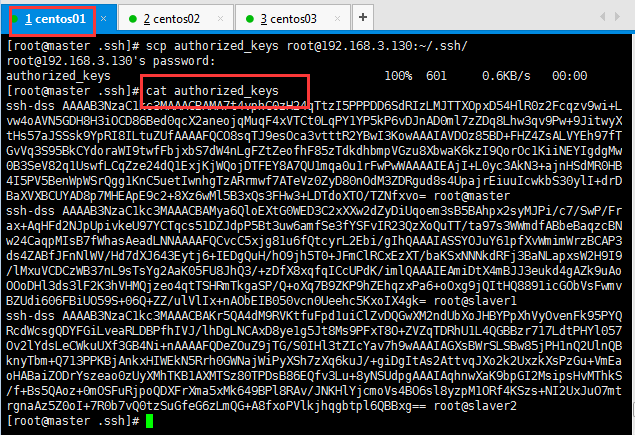
然后將此時的授權文件分別復制到slaver1主機中,這樣就完成了:
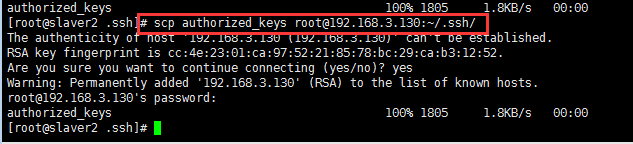
然后查看slaver1的授權文件:
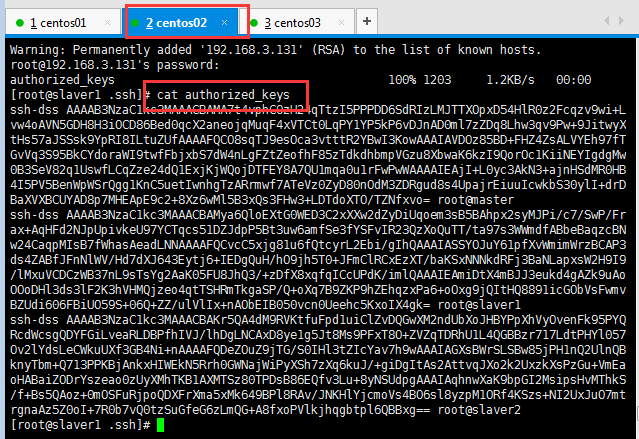
為了防止防火墻禁止一些端口號,三臺機器應使用
關閉防火墻命令:ufw disable(重啟三臺機器,防火墻關閉命令才能生效)/?service iptables stop(暫時關閉防火墻,方便測試使用)

重啟后后查看是否可以從master主機免密碼登錄slaver,輸入命令:
ssh slaver1
ssh slaver2
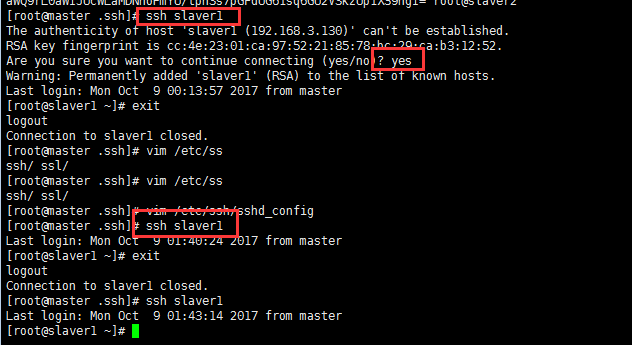
第一次登陸不知道為啥還是讓輸入一個yes,之后再進行登陸就直接登陸成功了:
?
?9:進行Hadoop集群完全分布式的安裝配置(將下載的hadoop-2.2.0上傳到虛擬機并解壓至/home/hadoop目錄下):
?[root@master hadoop]# tar -zxvf hadoop-2.4.1.tar.gz
三臺hadoop文件配置相同,所以配置完一臺后,可以把整個hadoop復制過去就行了,現在開始配置master主機的hadoop文件。
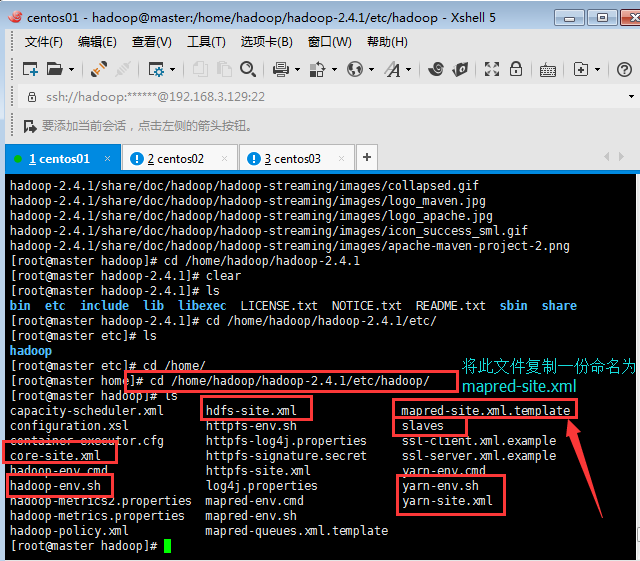
需要配置的文件涉及到的有7個(mapred-site.xml文件默認不存在的,可以復制相應的template文件獲得(如mapred-site.xml文件)。)
如下圖標示部分:
?
配置文件1:vim hadoop-env.sh
修改JAVA_HOME值如下圖:
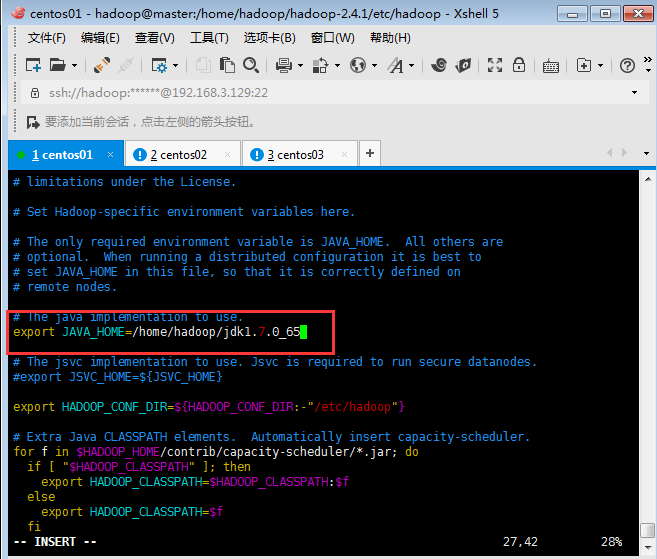
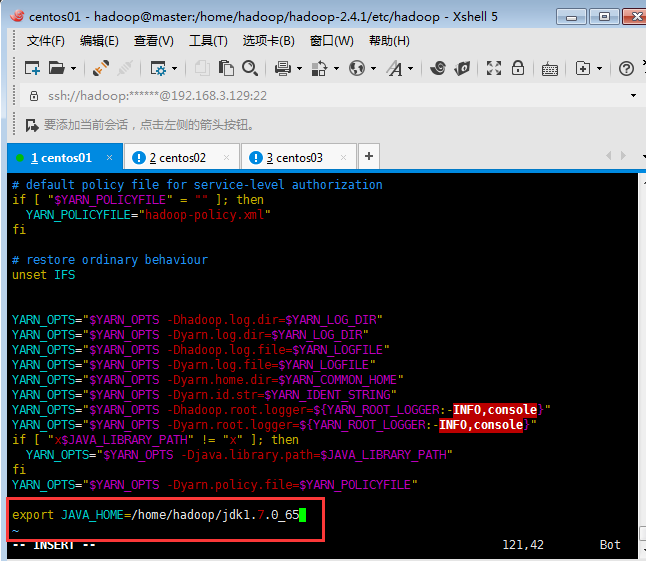
配置文件2:yarn-env.sh
修改JAVA_HOME值如下圖:
?
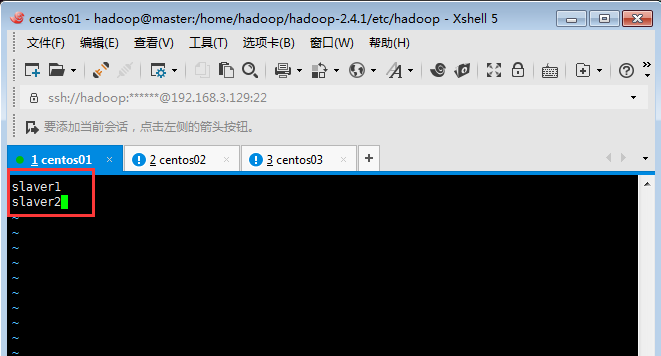
配置文件3:slaves(保存所有slave節點)寫入以下內容,是給自動化啟動腳本使用的哦,切記,是啟動DataNode的:
(這里需要注意一下,開始我的master節點寫的 vim slaves出現了,出現了hadoop DataNode啟動不了的問題,這里不是多次格式化造成的問題,這里是master主節點的vim slaves內容是master,而slaver1和slaver2的vim slaves內容是slaver1,slaver2,即下圖內容,所以造成了DataNode啟動不了的問題。)
?
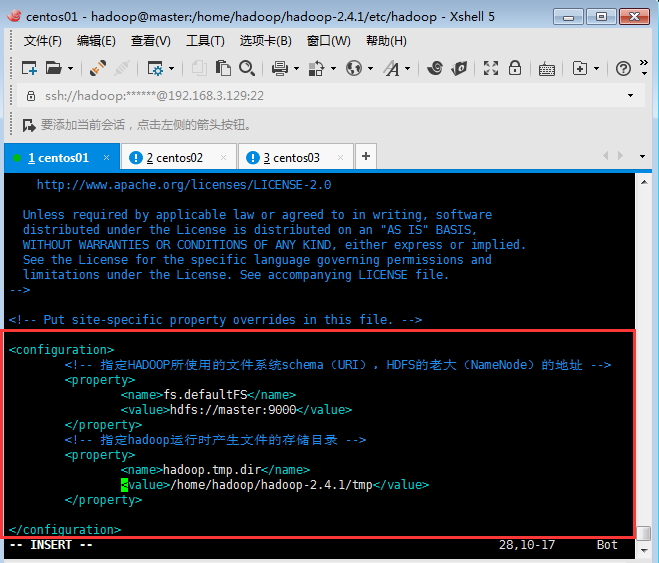
配置文件4:core-site.xml
添加配置內容如下圖:
<configuration><!-- 指定HADOOP所使用的文件系統schema(URI),HDFS的老大(NameNode)的地址,master即是namenode所在的節點機器,9000是端口號,NameNode是為客戶提供服務的,NameNode知道每一個文件存在哪一個datanode上面 --><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><!-- 指定hadoop運行時產生文件的存儲目錄 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.4.1/tmp</value></property></configuration>
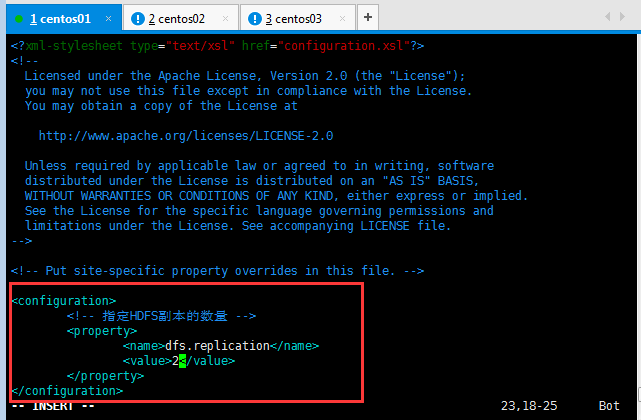
配置文件5:hdfs-site.xml
<configuration><!-- 指定HDFS副本的數量,副本的數量,避免一個機器宕掉了,數據丟失,默認是3個副本 --><property><name>dfs.replication</name><value>2</value></property>
<!-- 指定SecondNameNode在那臺機器上面啟動 -->?? ??? ?
<property>
?? ?<name>dfs.secondary.http.address</name>
?? ? <value>master:50090</value>
</property>
??? </configuration>
?
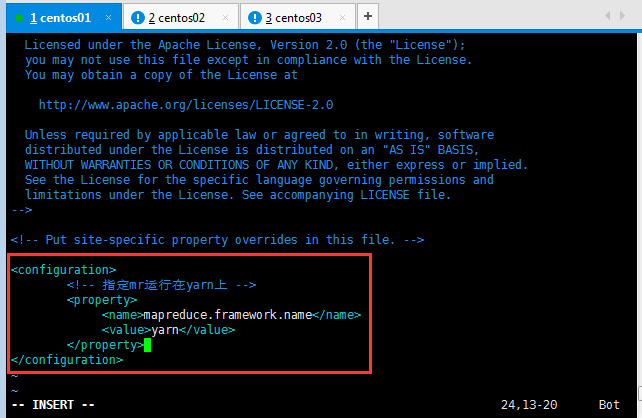
配置文件6:mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
<configuration><!-- 指定mr運行在yarn上,即mapreduce運行在yarn上面 --><property><name>mapreduce.framework.name</name><value>yarn</value></property> </configuration>
配置文件7:yarn-site.xml
<configuration><!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址,這個地方主要看自己的機器分配情況,如果是四臺機器,這個value值就是第四臺的主機名稱哦, --><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><!-- reducer獲取數據的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration> 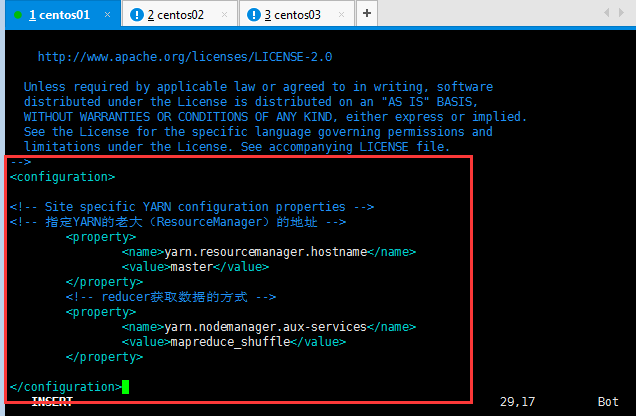
上面配置完畢后,基本上完成了90%的工作,剩下的就是復制。我們可以把整個hadoop復制過去使用命令如下:
[root@master hadoop]# scp -r /home/hadoop/hadoop-2.4.1 slaver1:/home/hadoop/
[root@master hadoop]# scp -r /home/hadoop/hadoop-2.4.1 slaver2:/home/hadoop/
然后去slaver1和slaver2就可以看到復制過去的hadoop-2.4.1:
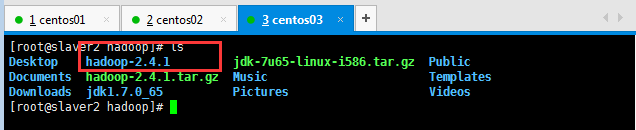
為方便用戶和系統管理使用hadoop、hdfs相關命令置系統環境變量,使用命令:vim /etc/profile
配置內容為hadoop目錄下的bin、sbin路徑,具體如下:
[root@slaver1 hadoop]# vim /etc/profile
export JAVA_HOME=/home/hadoop/jdk1.7.0_65export HADOOP_HOME=/home/hadoop/hadoop-2.4.1export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
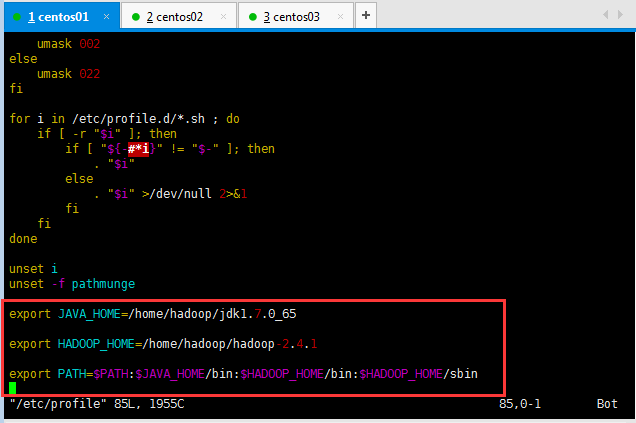
添加完后執行生效命令:source /etc/profile
?下面要做的就是啟動驗證,建議在驗證前,把以上三臺機器重啟,使其相關配置生效。
?10:啟動驗證
在master節點上進行格式化namenode? (是對namenode進行初始化):
命令:hadoop ?namenode ?-format或者hdfs namenode -format
start-all.sh或者啟動(start-dfs.sh和start-yarn.sh)
使用Jps命令master有如下進程,說明ok
start-yarn.sh 啟動namenode和datanode.
hadoop-daemon.sh start namenode 啟動namenode.
hadoop-daemon.sh start datanode 啟動datanode.??
?[root@master hadoop]# start-all.sh

?上面這個圖是錯誤的,由于master的vim slaves沒有配置正確,造成的。下圖是修改過后顯示的。

使用jps命令slaver1、slaver2有如下進程,說明ok:
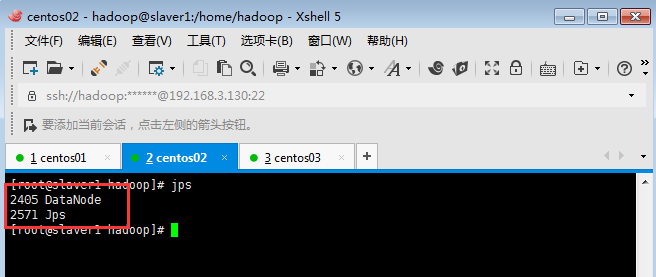
查看集群狀態,命令:hadoop dfsadmin -report
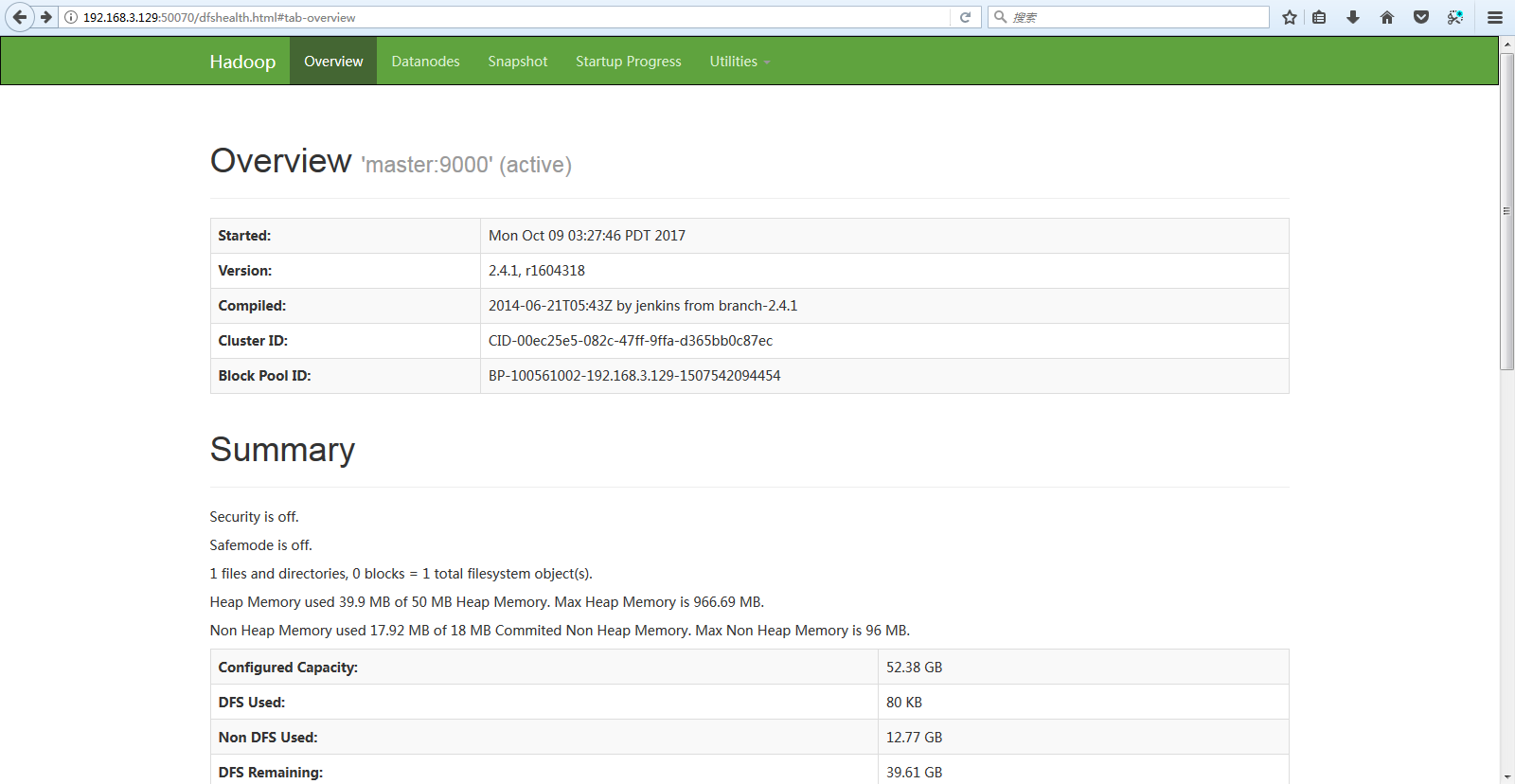
查看分布式文件系統:http://master:50070
除了瀏覽器查看集群的狀態,可以使用命令查看,此命令比瀏覽器查看更加準確:
[root@master hadoop]# hdfs dfsadmin -report
?查看MapReduce:http://master:8088
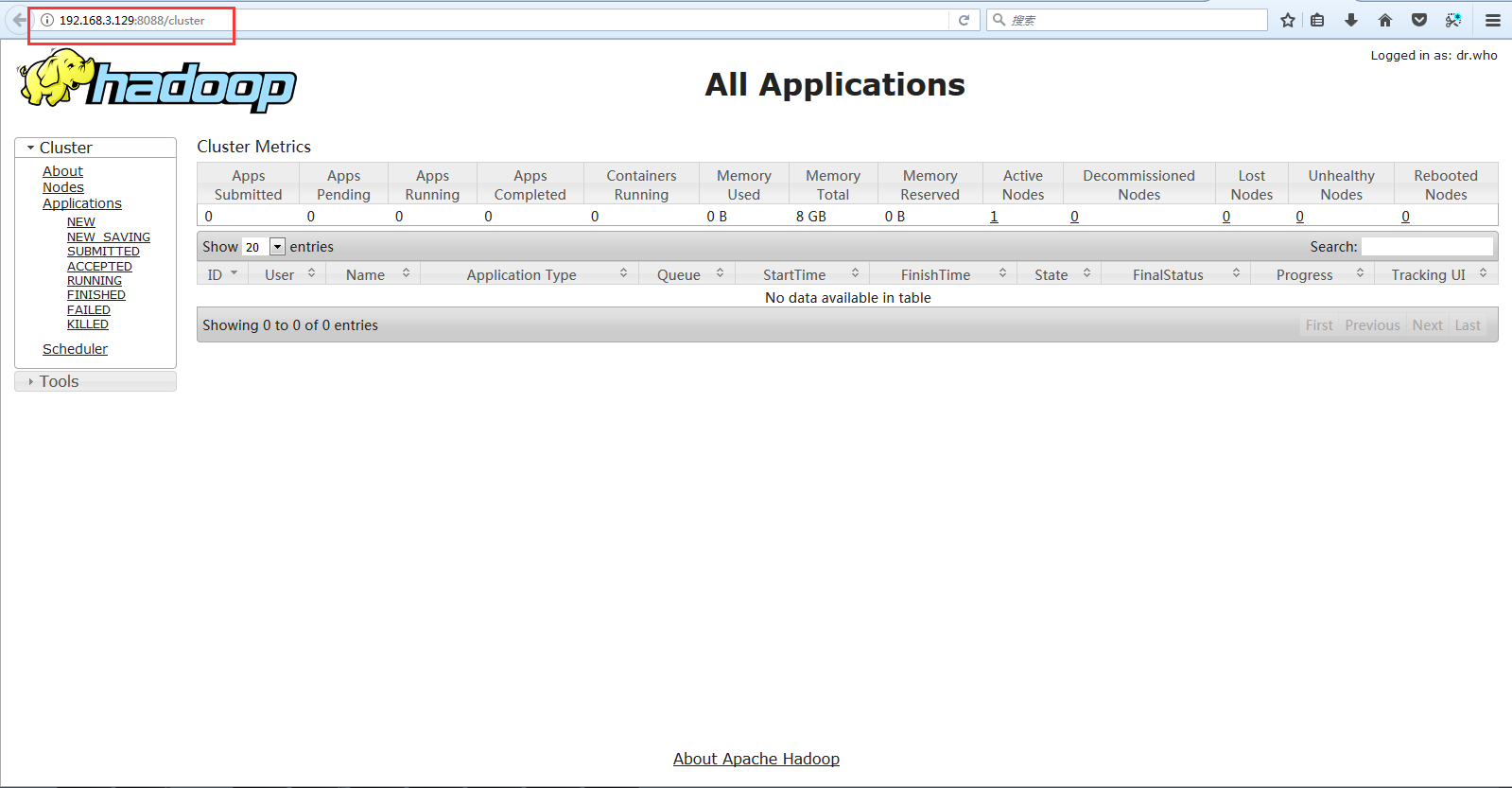
使用以上命令,當你看到如下圖所示的效果圖時,恭喜你完成了Hadoop完全分布式的安裝設置,其實這些部署還是比較基本的,對于Hadoop高深的體系結構和強大技術應用,這僅僅是一個小小的開始。
11:集群的關閉在master節點上執行命令如下:
stop-all.sh或者(stop-dfs.sh和stop-yarn.sh)
12:hadoop基本操作實踐
基本命令
1. 格式化工作空間
進入bin目錄,運行 hadoop namenode –format
2. 啟動hdfs
進入hadoop目錄,在bin/下面有很多啟動腳本,可以根據自己的需要來啟動。
* start-all.sh 啟動所有的Hadoop守護。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-dfs.sh 啟動Hadoop DFS守護Namenode和Datanode
* stop-dfs.sh 停止DFS守護
HDFS文件操作
Hadoop使用的是HDFS,能夠實現的功能和我們使用的磁盤系統類似。并且支持通配符,如*。
1. 查看文件列表
b. 執行hadoop fs -ls /
查看hdfs中/目錄下的所有文件(包括子目錄下的文件)。
a. 執行hadoop fs -ls -R /
2. 創建文件目錄
a. 執行hadoop fs -mkdir /newDir
3. 刪除文件
刪除hdfs中/目錄下一個名叫needDelete的文件
a. 執行hadoop fs -rm /needDelete
刪除hdfs中/hdfs目錄以及該目錄下的所有文件
a. 執行hadoop fs -rm -r /hdfs
4. 上傳文件
上傳一個本機/home/admin/newFile的文件到hdfs中/目錄下
執行hadoop fs –put /home/admin/newFile /
5. 下載文件
下載hdfs中/ 目錄下的newFile文件到本機/home/admin/newFile中
a. 執行hadoop fs –get /newFile /home/admin/newFile
6. 查看文件內容
查看hdfs中/目錄下的newFile文件
a. 執行hadoop fs –cat /newFile 2017-11-22? 14:06:19
停更......




)
![linux內核epub,Android底層開發技術實戰詳解——內核、移植和驅動(第2版)[EPUB][MOBI][AZW3][42.33MB]...](http://pic.xiahunao.cn/linux內核epub,Android底層開發技術實戰詳解——內核、移植和驅動(第2版)[EPUB][MOBI][AZW3][42.33MB]...)




)


![在VirtualBox里復制VDI文件[轉]](http://pic.xiahunao.cn/在VirtualBox里復制VDI文件[轉])



)

