scrape創建
網頁搜羅,數據科學 (Web Scraping, Data Science)
In this tutorial, I will show you how to perform web scraping using Anaconda Jupyter notebook and the BeautifulSoup library.
在本教程中,我將向您展示如何使用Anaconda Jupyter筆記本和BeautifulSoup庫執行Web抓取。
We’ll be scraping Company reviews and ratings from Indeed platform, and then we will export them to Pandas library dataframe and then to a .CSV file.
我們將從Indeed平臺上抓取公司的評論和評分,然后將它們導出到Pandas庫數據框,然后導出到.CSV文件。
Let us get straight down to business, however, if you’re looking on a guide to understanding Web Scraping in general, I advise you of reading this article from Dataquest.
但是,讓我們直接從事業務,但是,如果您正在尋找一般理解Web爬網的指南,建議您閱讀Dataquest的這篇文章。
Let us start by importing our 3 libraries
讓我們從導入3個庫開始
from bs4 import BeautifulSoup
import pandas as pd
import requestsThen, let’s go to indeed website and examine which information we want, we will be targeting Ernst & Young firm page, you can check it from the following link
然后,讓我們轉到確實的網站并檢查我們想要的信息,我們將以安永會計師事務所為目標頁面,您可以從以下鏈接中進行檢查
https://www.indeed.com/cmp/Ey/reviews?fcountry=ITBased on my location, the country is indicated as Italy but you can choose and control that if you want.
根據我的位置,該國家/地區顯示為意大利,但您可以根據需要選擇和控制該國家/地區。
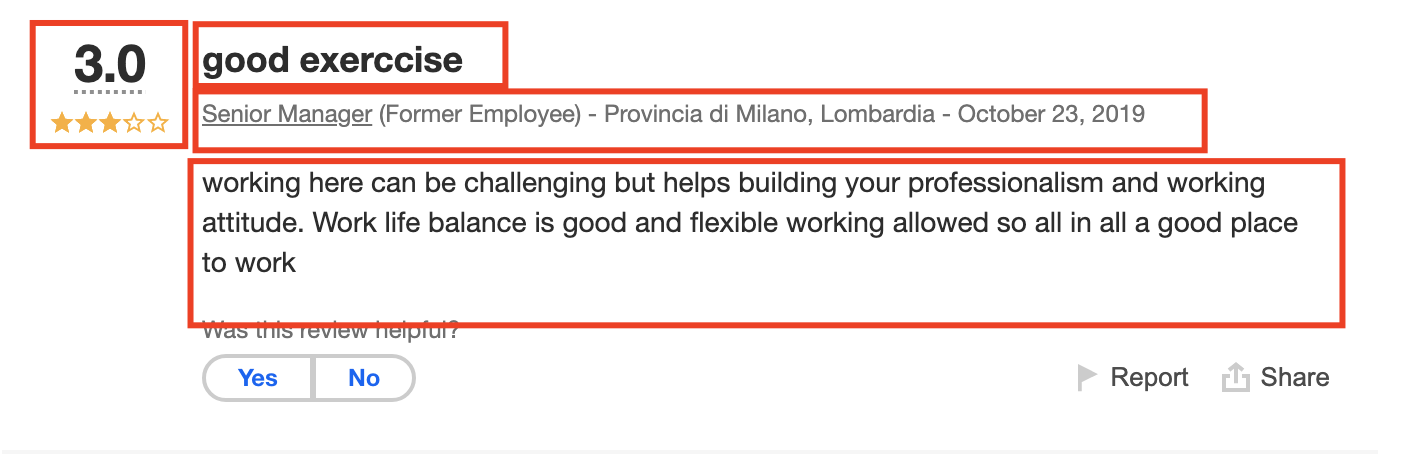
In the next picture, we can see the multiple information that we can tackle and scrape:
在下一張圖片中,我們可以看到我們可以解決和抓取的多種信息:
1- Review Title
1-評論標題
2- Review Body
2-審查機構
3- Rating
3-評分
4- The role of the reviewer
4-審稿人的角色
5- The location of the reviewer
5-評論者的位置
6- The review date
6-審查日期
However, you can notice that Points 4,5&6 are all in one line and will be scraped together, this can cause a bit of confusion for some people, but my advice is to scrape first then solve problems later. So, let’s try to do this.
但是,您會注意到,點4,5&6都在同一行中,并且將被刮擦在一起,這可能會使某些人感到困惑,但是我的建議是先刮擦然后再解決問題。 因此,讓我們嘗試執行此操作。
After knowing what we want to scrape, we need to find out how much do we need to scrape, do we want only 1 review? 1 page of reviews or all pages of reviews? I guess the answer should be all pages!!
知道要抓取的內容后,我們需要找出需要抓取的數量,我們只需要進行1次審核嗎? 1頁評論或所有頁面評論? 我想答案應該是所有頁面!
If you scrolled down the page and went over to page 2 you will find that the link for that page became as following:
如果您向下滾動頁面并轉到頁面2,則會發現該頁面的鏈接如下:
https://www.indeed.com/cmp/Ey/reviews?fcountry=IT&start=20Then try to go to page 3, you will find the link became as following:
然后嘗試轉到第3頁,您會發現鏈接如下所示:
https://www.indeed.com/cmp/Ey/reviews?fcountry=IT&start=4Looks like we have a pattern here, page 2=20 , page 3 = 40, then page 4 = 60, right? All untill page 8 = 140
看起來我們這里有一個模式,第2頁= 20,第3頁= 40,然后第4頁= 60,對嗎? 全部直到第8頁= 140
Let’s get back to coding, start by defining your dataframe that you want.
讓我們回到編碼,首先定義所需的數據框。
df = pd.DataFrame({‘review_title’: [],’review’:[],’author’:[],’rating’:[]})In the next code I will make a for loop that starts from 0, jumps 20 and stops at 140.
在下一個代碼中,我將創建一個for循環,該循環從0開始,跳20,然后在140處停止。
1- Inside that for loop we will make a GET request to the web server, which will download the HTML contents of a given web page for us.
1-在該for循環內,我們將向Web服務器發出GET請求,該服務器將為我們下載給定網頁HTML內容。
2- Then, We will use the BeautifulSoup library to parse this page, and extract the text from it. We first have to create an instance of the BeautifulSoup class to parse our document
2-然后,我們將使用BeautifulSoup庫解析此頁面,并從中提取文本。 我們首先必須創建BeautifulSoup類的實例來解析我們的文檔
3- Then by inspecting the html, we choose the classes from the web page, classes are used when scraping to specify specific elements we want to scrape.
3-然后通過檢查html,我們從網頁上選擇類,在抓取時使用這些類來指定要抓取的特定元素。
4- And then we can conclude by adding the results to our DataFrame created before.
4-然后我們可以通過將結果添加到之前創建的DataFrame中來得出結論。
“I added a picture down for how the code should be in case you copied and some spaces were added wrong”
“我在圖片上添加了圖片,以防萬一您復制了代碼并添加了錯誤的空格,應該如何處理”
for i in range(10,140,20):
url = (f’https://www.indeed.com/cmp/Ey/reviews?fcountry=IT&start={i}')
header = {“User-Agent”:”Mozilla/5.0 Gecko/20100101 Firefox/33.0 GoogleChrome/10.0"}
page = requests.get(url,headers = header)
soup = BeautifulSoup(page.content, ‘lxml’)
results = soup.find(“div”, { “id” : ‘cmp-container’})
elems = results.find_all(class_=’cmp-Review-container’)
for elem in elems:
title = elem.find(attrs = {‘class’:’cmp-Review-title’})
review = elem.find(‘div’, {‘class’: ‘cmp-Review-text’})
author = elem.find(attrs = {‘class’:’cmp-Review-author’})
rating = elem.find(attrs = {‘class’:’cmp-ReviewRating-text’})
df = df.append({‘review_title’: title.text,
‘review’: review.text,
‘author’: author.text,
‘rating’: rating.text
}, ignore_index=True)
DONE. Let’s check our dataframe
完成。 讓我們檢查一下數據框
df.head()
Now, once scraped, let’s try solve the problem we have.
現在,一旦刮掉,讓我們嘗試解決我們遇到的問題。
Notice the author coulmn had 3 differnt information seperated by (-)
請注意,作者可能有3個不同的信息,并以(-)分隔
So, let’s split them
所以,讓我們分開
author = df[‘author’].str.split(‘-’, expand=True)
Now, let’s rename the columns and delete the last one.
現在,讓我們重命名列并刪除最后一列。
author = author.rename(columns={0: “job”, 1: “location”,2:’time’})del author[3]Then let’s join those new columns to our original dataframe and delete the old author column
然后,將這些新列添加到原始數據框中,并刪除舊的author列
df1 = pd.concat([df,author],axis=1)
del df1[‘author’]let’s examine our new dataframe
讓我們檢查一下新的數據框
df1.head()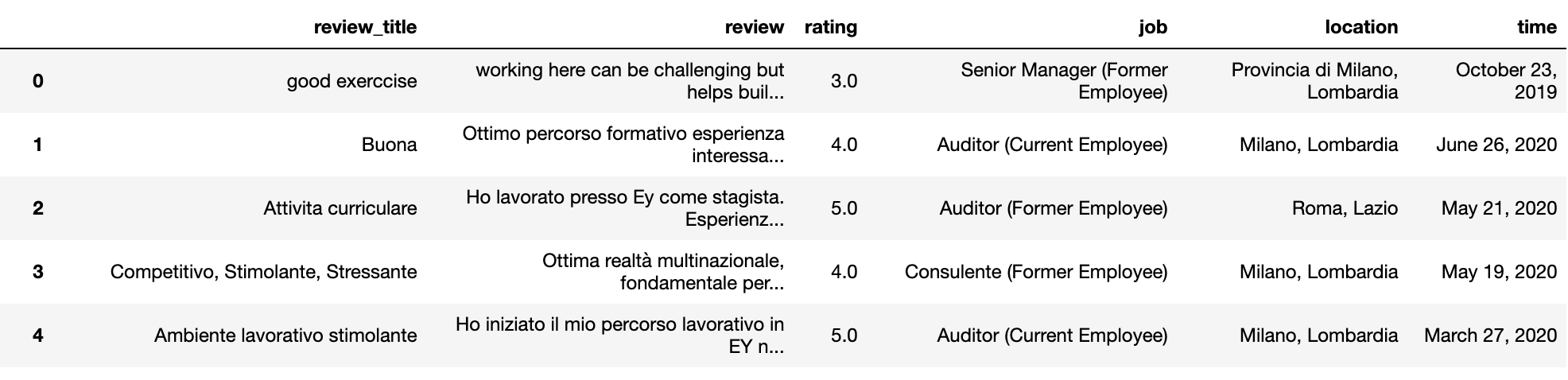
Let’s re-organize the columns and remove any duplicates
讓我們重新整理各列并刪除所有重復項
df1 = df1[[‘job’, ‘review_title’, ‘review’, ‘rating’,’location’,’time’]]
df1 = df1.drop_duplicates()Then finally let’s save the dataframe to a CSV file
最后,讓我們將數據框保存到CSV文件中
df1.to_csv(‘EY_indeed.csv’)You should now have a good understanding of how to scrape and extract data from Indeed. A good next step for you if you are familiar a bit with web scraping it to pick a site and try some web scraping on your own.
您現在應該對如何從Indeed抓取和提取數據有很好的了解。 如果您對網絡抓取有點熟悉,可以選擇一個不錯的下一步來選擇一個站點,然后自己嘗試一些網絡抓取。
Happy Coding:)
快樂編碼:)
翻譯自: https://towardsdatascience.com/scrape-company-reviews-ratings-from-indeed-in-2-minutes-59205222d3ae
scrape創建
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392385.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392385.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392385.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

)
Java基礎——String類(一)
實現過程解析)
java jol原理_Java對象布局(JOL)實現過程解析


Redux初學者指南
)
leetcode 86. 分隔鏈表(鏈表)


電腦通過手機上網的方法

java入門學習_Java入門學習進階知識點


JDBC 數據庫連接操作——實習第三天

webassembly_WebAssembly的設計
)
leetcode 509. 斐波那契數(dfs)

java基本特性_Java面試總結之Java基礎

plotly python_使用Plotly for Python時的基本思路


Python模塊之hashlib:提供hash算法

css flexbox模型_完整CSS課程-包括flexbox和CSS網格

leetcode 830. 較大分組的位置
