地圖 c-suite
We’ve all seen a great picture capture an audience of stakeholders.
我們所有人都看到了吸引利益相關者聽眾的美好畫面。

It’s such a potent effect that Edward Tufte makes a living deconstructing it. When a great visualization is used in a presentation it has a magnetic pull on the group. It generates discussion and deep study (I’d count focus on a picture lasting more than 30 seconds or so as deep study in a typical meeting). In the right context some charts serve as complete, stand-alone executive summaries.
愛德華·塔夫特(Edward Tufte)靠這種強大的作用來謀求解構。 在演示中使用出色的可視化效果時,會在組上產生磁性吸引力。 它會引發討論和深入研究(我希望將重點放在持續30秒鐘以上的圖片上,就像在典型會議中進行深入研究一樣)。 在適當的情況下,某些圖表可以作為完整的獨立執行摘要。
Network models offer this kind of clear and compelling visualization, making them very well suited for the executive audience. But these models are far more than a pretty picture. They are generative models allowing for simulation and inference with efficient automated model discovery methods. Under generally accepted causality frameworks network models estimate causal effects. Any one of those attributes makes for an analytics tool worth using, but having all of them in one method is truly exceptional
網絡模型提供了這種清晰而引人注目的可視化效果,非常適合高管受眾。 但是這些模型遠不止是一張漂亮的圖畫。 它們是生成模型,可以使用有效的自動模型發現方法進行仿真和推斷。 在普遍接受的因果關系框架下,網絡模型估計因果關系。 這些屬性中的任何一個都值得使用一種分析工具,但是將所有這些屬性合用一種方法確實是個例外
To demonstrate the power of network models, this article walks through a simple network model of Intel’s financials. We consider the link between net revenue and R&D and advertising expenses as our main focus.
為了演示網絡模型的強大功能,本文將介紹英特爾財務的簡單網絡模型。 我們將凈收入與研發和廣告費用之間的聯系作為我們的主要重點。
Let’s start with the simple network below.
讓我們從下面的簡單網絡開始。
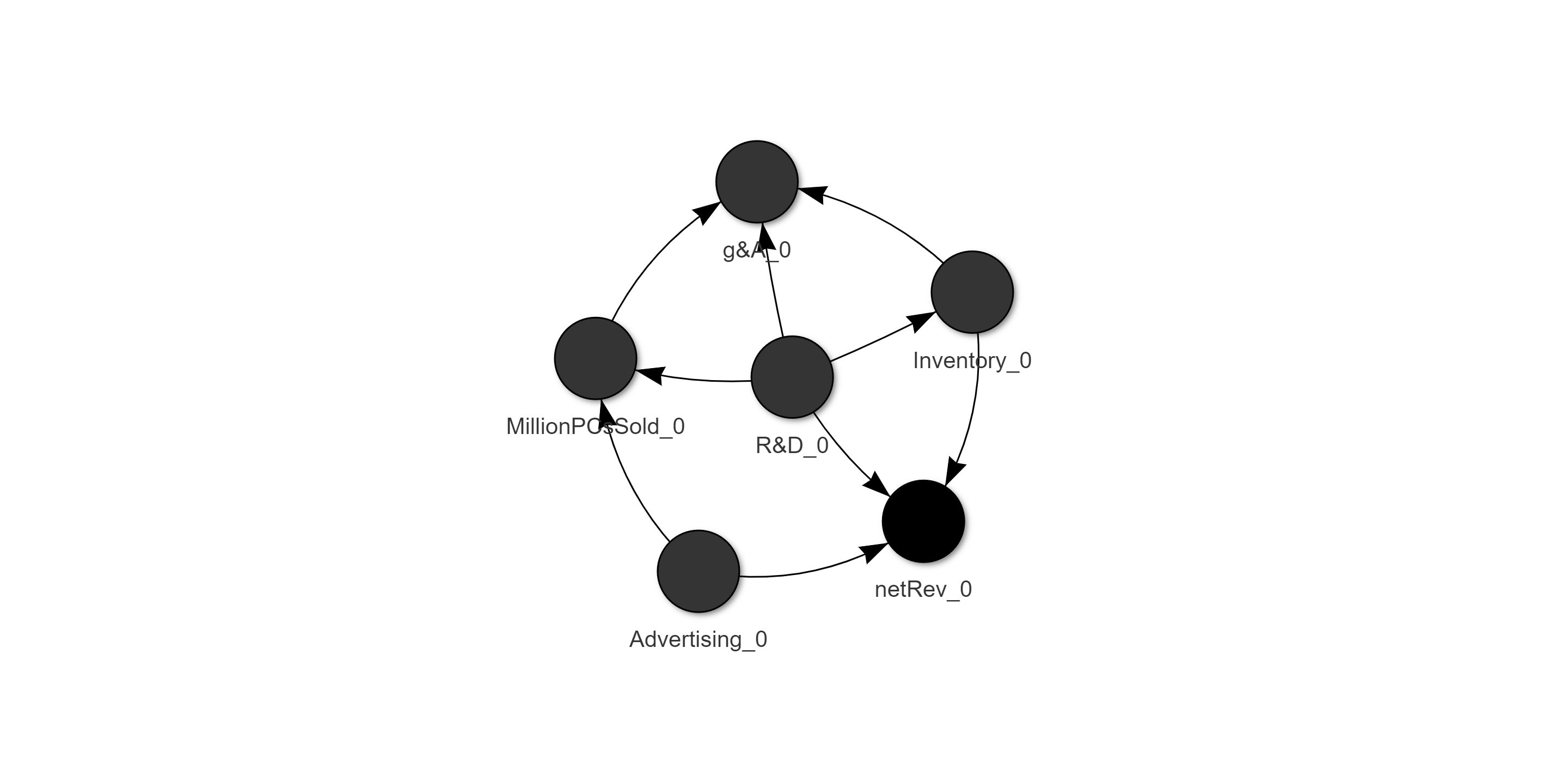
With no coaching at all, I’m willing to bet you immediately understand the key points of the picture to the left: each named dot (‘node’) is a quantity, the arrows (‘edges’) indicate relationships between those quantities, and you probably guessed that the arrows point from cause to effect.
完全沒有指導,我敢打賭,您立即了解左側圖片的關鍵點:每個命名點('node')是一個數量,箭頭('edge')表示這些數量之間的關系,您可能會猜到箭頭指向的是因果關系。
These nodes are a minimal skeleton of Intel’s financial reporting plus the global retail sales (in units) for one of the company’s key markets. Most labels are self explanatory, but g&A is likely not. It is computed from the reported Advertising, General & Administrative expense line item, with advertising spend subtracted to keep ad spend separate from the other two. The Intel data here is sourced from the 28 annual10-K filings found on SEC.gov covering 1992 to 2019. The global PC sales for the same years were found on wikipedia and ars technica. All values are in millions, and dollar amounts have been adjusted for inflation to the value of the dollar in 2000.
這些節點是英特爾財務報告以及該公司主要市場之一的全球零售額(以單位為單位)的最小框架。 多數標簽是不言自明的,但一般管理人員可能不會。 它是根據報告的廣告,一般和行政費用行項目計算得出的,減去廣告支出后,廣告支出便會與其他兩項分開。 英特爾數據在這里從28 annual10-K備案采購上找到SEC.gov涵蓋1992年至2019年在被發現的全球PC銷量為同里維基百科和Ars Technica的 。 所有值均以百萬為單位,并且根據通貨膨脹將美元金額調整為2000年的美元價值。
In the network, variables are tagged _0 to indicate that all of these represent the same time step; i.e. this network represents relationships between values in the same year.
在網絡中,變量被標記為_0,以指示所有這些變量代表相同的時間步長; 即,該網絡表示同一年中值之間的關系。
The network structure is learned from the data by a simple hill climbing algorithm with restarts and some trimming, using the AIC as an optimization metric. I’ve done this using R’s bnlearn package’s tabu() function. The method is fast (and applies well to larger networks) but does not guarantee a true global optimum is found. This ends up having some advantages can work to our advantage, leaving us room to apply business knowledge and still obtain a model no worse than the ‘optimal’ one.
使用AIC作為優化指標,通過簡單的爬山算法重新啟動并進行一些修整,從數據中了解網絡結構。 我已經使用R的bnlearn包的tabu()函數完成了此操作。 該方法快速(并且適用于較大的網絡),但不能保證找到真正的全局最優值。 最終,有些優勢可以發揮我們的優勢,給我們留出了應用業務知識的空間,并且仍然獲得了不比“最佳”模型更糟糕的模型。
The heart of a network model is showing relationships between variables — even very complex relationships. If a variable is a controllable quantity (e.g. ad spend) then the network shows what quantities will be impacted by changing the controllable quantity. If no path exists between two nodes in the network (not the case for any pair of nodes in our network) then the two quantities are independent of each other, both practically (i.e. we cannot change one to influence the other) and probabilistically (i.e. the distribution of one conditioned on the other is the same as the distribution first quantities distribution). If two nodes do have a path between them there is evidence that information about one node has implications for the other.
網絡模型的核心是顯示變量之間的關系,甚至是非常復雜的關系。 如果變量是可控制的數量(例如廣告支出),則網絡會顯示更改可控制的數量會影響哪些數量。 如果網絡中的兩個節點之間不存在路徑(我們網絡中的任何一對節點都不存在),則這兩個數量實際上是相互獨立的(即,我們不能改變一個以影響另一個),并且概率是相互獨立的(即,一個以另一個為條件的分布與分布第一數量分布相同)。 如果兩個節點之間確實有路徑,則有證據表明有關一個節點的信息對另一節點有影響。
In our example network, we can see that R&D expenses drive all the other values except advertising and that advertising drives both net revenue and total PC sales. While that’s interesting in and of itself, I think we would all agree that this is expected. Maybe a harder question is are there lasting (i.e. multi-year) effects of ad and research expenses?
在我們的示例網絡中,我們可以看到R&D支出驅動著除廣告之外的所有其他價值,而廣告推動了凈收入和PC總銷量。 盡管這本身很有趣,但我認為我們都同意這是預期的。 也許更難的問題是廣告和研究費用是否具有持久(即多年)的影響?
The model is easily extended to address this; we simply add nodes to cover previous years’ values. I’ll add two more years to our model and see what results. In the visualization below a suffix of “_-1” implies a variable value 1 year before the “_0” value.
該模型很容易擴展以解決此問題。 我們只需添加節點即可覆蓋前幾年的價值。 我將在模型中再加上兩年,看看結果如何。 在下面的圖表中,后綴“ _-1”表示“ _0”值之前1年的變量值。

As you explore the multi-year relationships (the link in the caption will get you to an interactive plot that might help make relationships more viewable) you’ll see that are persistent effects from last year’s R&D and indirectly R&D from two years ago via the previous years’ net revenue.
當您探索多年的關系時(標題中的鏈接將帶您到一個互動的情節,這可能有助于使關系更加可見),您將看到這是去年研發的持續影響,以及兩年前通過R&D間接產生的影響。前幾年的凈收入。
We also see that the relationships within a year aren’t the same in each layer. This means that if the current year is 2018, the current ad spend influences net revenue but once the current year is 2019, the 2018 spend no longer influenced 2018 net revenue.
我們還看到,一年之內的關系在每個層中都不相同。 這意味著如果當前年份為2018年,當前廣告支出會影響凈收入,但是當當前年份為2019年時,2018年支出將不再影響2018年凈收入。
Frankly, that doesn’t make a lot of sense. And because I promised a model that immediately made sense, we need to help the structure learning algorithm with some expert advice. I propose to keep the within-year relationship in all years the same as the initial model and let the between year relationships be identified algorithmically. This is simple to do by passing the edges of the single year network as a whitelist dataframe to bnlearn’s structure finding functions.
坦白說,這沒有什么意義。 而且因為我承諾了一個可以立即生效的模型,所以我們需要在專家建議下幫助結構學習算法。 我建議將所有年份的年內關系保持與初始模型相同,并通過算法確定年間關系。 通過將單年網絡的邊緣作為白名單數據幀傳遞到bnlearn的結構查找功能,可以很容易地做到這一點。

Now we see the original relationships conserved. We also see more connections between the years (each layer here is one year). More arrows mean more parameters, so it is important to note that the AIC of this modified model is very close to auto-magically learned model’s AIC.
現在,我們看到原始關系得以保留。 我們還可以看到年份之間的聯系更多(這里的每一層都是一年)。 箭頭越多意味著參數越多,因此需要注意的是,此修改模型的AIC非常接近自動學習模型的AIC。
So this ‘proves’ that R&D and advertising expenditures have lasting business impact. Which arms executives of those functions to argue that cutting budgets this year will leave the business hampered for years to come.
因此,這“證明”研發和廣告支出具有持久的業務影響。 這些職能部門的哪位高管爭論說,今年削減預算將使該業務在未來幾年受到阻礙。
Presumably, the follow-up question will be ‘how much will the business be hampered if we make the cuts anyway?’ Our network model allows for inference and simulation by simply setting the values of the decision nodes, our advertising and R&D budgets, and sampling the resulting distribution of the outcome of interest, net revenue.
據推測,后續問題將是“如果我們繼續裁員,業務將受到多少阻礙?” 我們的網絡模型可以通過簡單地設置決策節點的值,我們的廣告和R&D預算,以及對利息結果(凈收入)的結果分布進行采樣來進行推理和模擬。
If all relevant variables are accounted for in the model, the difference in the expected value of the outcome as the value of the decision node varies is the causal impact of varying the decision. We can easily find the historical causal impact of R&D and ad spends by comparing the expected value of net revenue in 2019 with actual spend levels in the last 3 years to the expected value of net revenue with 0 spend for all 3 of those years.
如果在模型中考慮了所有相關變量,那么隨著決策節點的值變化,結果的預期值的差異就是決策變化的因果關系。 通過將2019年凈收入的預期值與過去3年的實際支出水平進行比較,將這3年中支出為0的凈收入的預期值進行比較,可以輕松找到R&D和廣告支出的歷史因果關系。
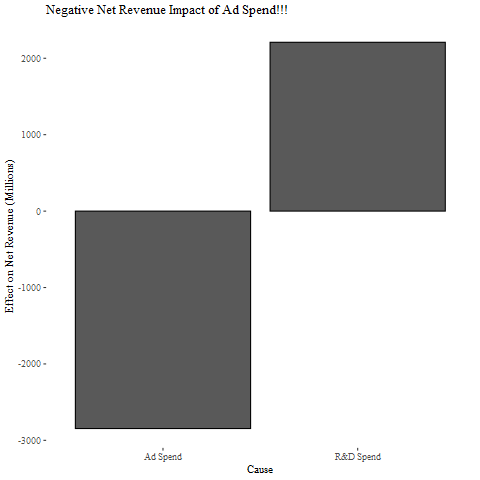
Well, this is certainly an unexpected result. A quick investigation shows that the within-year advertising coefficients are positive (as expected) but the between-year advertising coefficients are always negative. I suppose we could rationalize this by saying that ads driving sales this year are stealing from sales in the next year. . .but we can also note that the ad spend in year 0 is highly correlated to the spends in year -1 and year -2. This indicates the estimates for present and past ad spends onto a given net revenue node are subject to the ill effects of collinearity.
好吧,這肯定是出乎意料的結果。 快速調查顯示,年內廣告系數為正(如預期),但年間廣告系數始終為負。 我想我們可以通過說今年推動銷售的廣告從明年的銷售中竊取來合理化。 。 。,但我們還可以注意到,第0年的廣告支出與第-1年和-2年的支出高度相關。 這表明對給定凈收入節點上的當前和過去廣告支出的估算會受到共線性的不良影響。
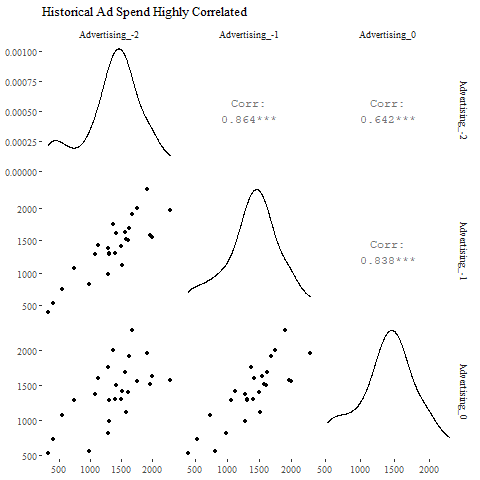
Given the high correlation, and the unreasonable estimates, we can simply ban previous years’ advertising from having a direct impact on current net revenue. This still leaves room for an indirect influence through, e.g., previous years net revenue. The final network is charted below.
鑒于相關性高且估算值不合理,我們可以簡單地禁止前幾年的廣告直接影響當前的凈收入。 這仍然通過例如前幾年的凈收入為間接影響留下了空間。 最終網絡如下圖所示。
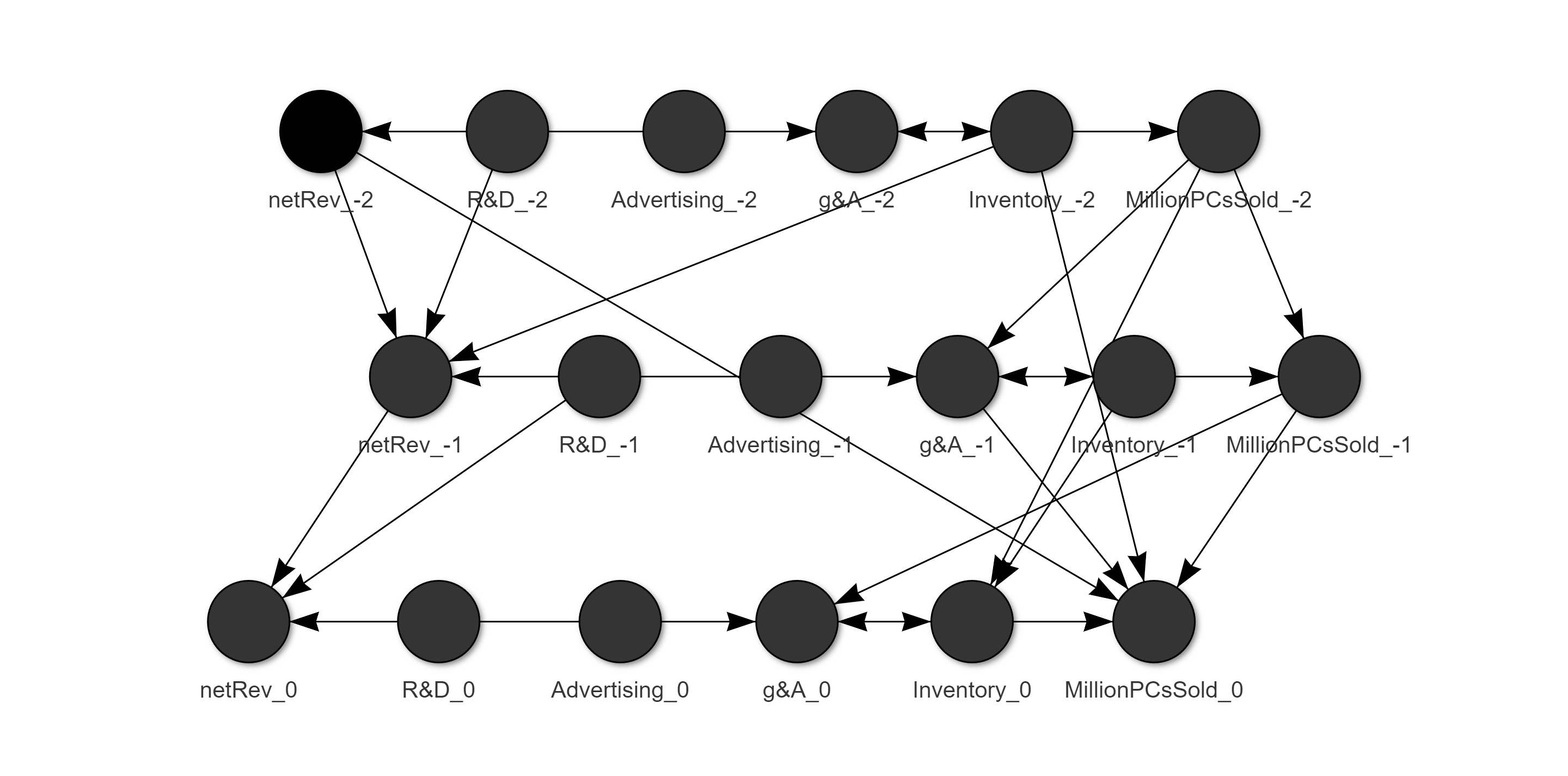
The AIC is lower than our last model, so we haven’t destroyed our model by removing the offending edges!
AIC比我們的上一個模型低,因此我們還沒有通過移除有害的邊來破壞我們的模型!
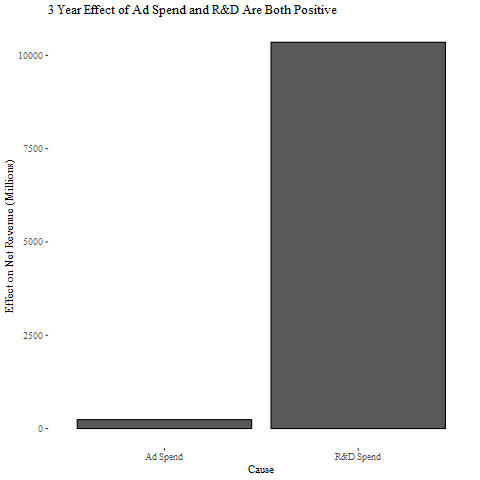
Now we can apply the same ‘turn it off’ approach as before to get the causal impact of R&D and advertising effect on net revenue. This model shows positive impacts all around, aligning with common sense and giving the CMO some relief. Interestingly, R&D is now showing a much stronger positive impact on revenue than before. So everyone is going to prefer this model!
現在,我們可以使用與以前相同的“關閉”方法來獲得研發和廣告效應對凈收入的因果關系。 該模型顯示了積極的影響,符合常識,并給CMO帶來了一些緩解。 有趣的是,現在研發對收入的積極影響比以前大得多。 所以每個人都會喜歡這種模型!
To wrap up, the models presented here are intentionally simple, and somewhat limited by the publicly available data used in the example.
總結起來,這里介紹的模型是故意簡單的,并且受到示例中使用的公開可用數據的限制。
For convenience, we have used bnlearn’s inbuilt fitting functions which limits continuous variales to gaussian distributions. This is not an inherent assumption to network models. More complex networks could ahve different distributions by node (bnlearn can handle this by discretizing continous variables and other software can directly model different distributions). Additionally (but not-additively), the relationships between the nodes could be non-linear whereas in these examples each nodes mean is a linear combination of its parents’ means.
為了方便起見,我們使用了bnlearn的內置擬合函數,該函數將連續變量限制為高斯分布。 這不是網絡模型的固有假設。 更復雜的網絡可能按節點具有不同的分布(bnlearn可以通過離散化連續變量來處理此問題,其他軟件可以直接對不同的分布進行建模)。 另外(但不是累加地),節點之間的關系可以是非線性的,而在這些示例中,每個節點的均值是其父代均值的線性組合。
From the analytics side, it is hard to swallow looking for a global impact of aggregate R&D spend (maybe capex vs working spend should be split out? Perhaps large initiatives should be modeled separately with different possible durations of effect?) or advertising spend (surely B2B and direct to consumer campaigns have potentially different effects over time?). Perhaps we need more years in the network to account for very long term effects? And we almost certainly should add more external factors (Competitor ad spend? Server sales? Merge and Acquisition activity in computer manufacturers?) to the model before claiming we had included all relevant variables influencing net revenue.
從分析的角度來看,很難吞噬研發總支出的全球影響(也許應該將資本支出與工作支出分開?也許應該對大型計劃進行建模,并采用不同的有效期限?)或廣告支出(一定要確定) B2B和直接面向消費者的運動隨著時間的推移可能會產生不同的影響?)。 也許我們需要在網絡中花費更多的時間來解決長期影響? 而且,在聲稱我們已包括影響凈收入的所有相關變量之前,我們幾乎肯定應該在模型中添加更多外部因素(競爭對手的廣告支出,服務器銷售,計算機制造商的并購活動)。
But our simplified example serves to demonstrate the flexbility and utility of graph models. And it highlights how fundamental data issues like collinearity are fundamental because they matter no matter the model being built.
但是我們的簡化示例用來說明圖模型的靈活性和實用性。 它強調了共線性之類的基本數據問題是多么基本,因為無論所構建的模型如何,它們都至關重要。
I hope I have also convinced you of the value of the network diagram itself. It is impossible to over-emphasize how potent it is for gaining an audience’s alignment with a model. Because the audience can really see the model, they almost immediately feel comfortable reasoning with it.
我希望我也已經使您相信網絡圖本身的價值。 不可能過分強調它對于使觀眾與模型保持一致的效力。 因為觀眾可以真正看到模型,所以他們幾乎立刻就可以輕松地進行推理了。
Imagine a final presentation where most of the conversation is about your recommendations and not what your model is — wouldn’t that be a nice change of pace?
想象一個最后的演講,其中大部分對話都是關于您的建議而不是您的模型的,這不是很好的步調嗎?

I’ll write a how-to-code-it companion article to this one and future articles on other methods; follow me here on medium for updates.
我將在這篇文章以及其他方法的后續文章中寫一篇“如何編碼”的配套文章。 在媒體上關注我,以獲取更新。
翻譯自: https://towardsdatascience.com/a-model-for-the-c-suite-2031a0cecc6d
地圖 c-suite
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/392048.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/392048.shtml 英文地址,請注明出處:http://en.pswp.cn/news/392048.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

框架和庫的區別_框架和庫之間的區別

Java—多線程實現生產者消費者模型

動態鏈接庫.so和靜態鏈接庫.a的區別

華為鴻蒙系統封閉,谷歌正式“除名”華為!“親兒子”榮耀表示:暫不考慮,鴻蒙OS處境尷尬...

使用vue-cli腳手架搭建簡單項目框架

sap中泰國有預扣稅設置嗎_泰國餐廳密度細分:帶有K-means聚類的python

自動化yaml文件_從YAML到TypeScript:開發人員對云自動化的看法

SQL SERVER-Extendevent系統視圖

Java—簡單的注冊頁面

【深度學習系列】用PaddlePaddle和Tensorflow實現經典CNN網絡AlexNet

圖片獲取像素坐標html,HTML5畫布Canvas圖片抽取、像素信息獲取、命中檢測

CentOS6 下Samba服務器的安裝與配置

傅里葉變換 直觀_A / B測試的直觀模擬

tableau for循環_Tableau for Data Science and Data Visualization-速成課程


Java—servlet簡單使用

phpstrom+phpstudy+postman


android emmc 命令,使用CoreELEC的ceemmc工具將系統寫入emmc
