http://geek.csdn.net/news/detail/139152
本文主要為大家介紹深度學習算法在自然語言處理任務中的應用——包括算法的原理是什么,相比于其他算法它具有什么優勢,以及如何使用深度學習算法進行情感分析。
原理解析
在講算法之前,我們需要先剖析一下我們要完成的任務,我們希望算法能夠最大程度模擬大腦對于人類語言的處理邏輯,對文本進行褒義、貶義、中性的判斷。在大多應用場景下,只分為兩類。比說如,對于“喜愛”和“厭惡”這兩個詞,就屬于不同的情感傾向。有一點需要特別注意,這里面所說的褒義、貶義并不是絕對的,分類的類別是根據我們的目標自由定義的,并且嚴格以人的判斷為基準,比如我們可以把句子分類為陳述句、疑問句、祈使句和感嘆句。
我們的第一個模型——基于情感詞典的情感分類模型。
?
?
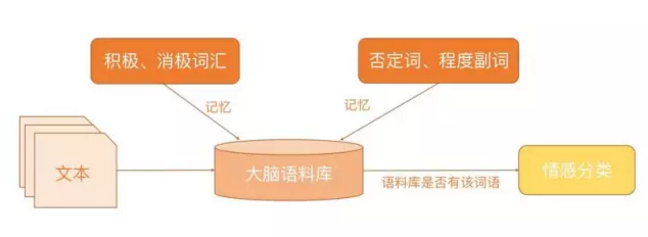
傳統的基于情感詞典的文本情感分類,是對人的記憶和判斷思維的最簡單的模擬,如圖所示。我們首先通過學習來記憶一些基本詞匯,如否定詞語有“不”,積極詞語有“喜歡”、“愛”,消極詞語有“討厭”、“恨”等,從而在大腦中形成一個基本的語料庫。然后,我們再對輸入的句子進行分詞,看看我們所記憶的詞匯表中是否存在相應的詞語,然后根據這個詞語的類別來判斷情感,比如“我喜歡數學”,“喜歡”這個詞在我們所記憶的積極詞匯表中,所以我們判斷它具有積極的情感。
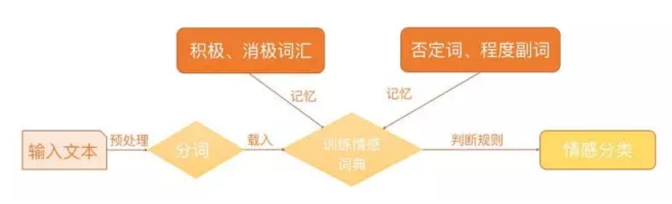
基于上述思路,我們可以通過以下幾個步驟實現基于情感詞典的情感分類:包括預處理、分詞、訓練情感詞典、判斷,整個過程可以如下圖表示。
?
?
1.文本的預處理
由網絡爬蟲爬取到的原始語料,通常都會帶有我們不需要的信息,比如額外的Html標簽,所以需要對語料進行預處理。這里的預處理工作主要是為了提取完整的句子,去掉一些多余的標記符號。處理之后我們需要對原始語料進行情感標注,我們可以用-1標記消極情感評論,1標記積極情感評論。
2.分詞
為了判斷句子中是否存在情感詞典中相應的詞語,我們需要把句子準確切割為一個個詞語,即分詞。現有可選擇的分詞工具有很多,我們可以研讀各分詞工具的測試報告,根據自己的需求選擇合適的分詞工具。
3.構建情感詞典
情感詞典可分為四個部分:積極情感詞典、消極情感詞典、否定詞典以及程度副詞詞典。為了得到更加完整的情感詞典,我們可以收集多個情感詞典,對它們進行整合去重,同時需要對部分詞語進行調整,以達到盡可能高的準確率。
此外,我們需要根據需求加入某些行業詞匯,以增加分類中的命中率。不同行業某些詞語的詞頻會有比較大的差別,而這些詞有可能是情感分類的關鍵詞之一。比如手機行業,“耐摔”和“防水”就是在這個領域有積極情緒的詞。因此,有必要將這些因素考慮進模型之中。
4.分類
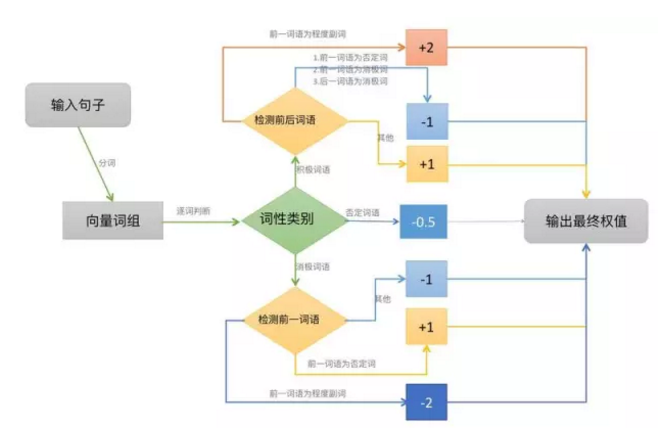
為了簡單起見,我們將每個積極情感詞語賦予權重1,將每個消極情感詞語賦予權重-1,并且假設情感值滿足線性疊加原理;我們已經將句子進行分詞,如果分詞后的詞語向量包含相應的詞語,就加上其對應的權值,其中,否定詞和程度副詞會有特殊的判別規則,否定詞會導致權值取反,而程度副詞則讓權值加倍。最后,根據總權值的正負性來判斷句子的情感。基本的規則如圖所示。
?
?
最后我們需要對模型的效果進行檢驗。通過在我們爬取的微博語料上進行測試,基于情感詞典的模型準確率只有76%,這個結果有點差強人意。
那么,為什么這個模型的效果不那么好?這是由于這個任務本身的復雜性所致的。
文本情感分類的困難在于:
- 語言系統是相當復雜的
人的語言是一個相當復雜的文化產物,一個句子并不是詞語的簡單線性組合,它有相當復雜的非線性在里面。我們在描述一個句子時,都是將句子作為一個整體而不是詞語的集合看待的,詞語的不同組合、不同順序、不同數目都能夠帶來不同的含義和情感,這導致了分類工作的困難。因此,這個任務實際上是對人腦思維的模擬。我們前面的模型,實際上已經對此進行了最簡單的模擬。然而,我們模擬的不過是一些簡單的思維定式,真正的情感判斷并不是只靠一些簡單的規則。
- 大腦做的事情比情感分類要多
事實上,我們在判斷一個句子的情感時,我們不僅僅在想這個句子是什么情感,而且還會判斷這個句子的類型(祈使句、疑問句還是陳述句?);當我們在考慮句子中的每個詞語時,我們不僅僅關注其中的積極詞語、消極詞語、否定詞或者程度副詞,我們會關注每一個詞語(主語、謂語、賓語等等),從而形成對整個句子整體的認識;我們甚至還會聯系上下文對句子進行判斷。這些判斷我們可能是無意識的,但我們大腦確實做了這些事情,以形成對句子的完整認識,才能對句子的情感傾向做出準確的判斷。也就是說,我們的大腦是一個非常高速而復雜的處理器,我們做情感判斷,其實同時做了很多事情。
通過上面的分析,我們不難發現傳統的方法存在著兩個難以克服的局限性:
- 精度問題:傳統的模型無法模擬語言中復雜的非線性關系,故難以進一步提高精度;
- 背景知識依賴問題:傳統思路需要事先提取好情感詞典,而這一步驟,往往需要專業人員的大量人工操作才能保證準確率。
下面我給大家解釋深度學習是如何做到的。
自然語言處理任務中,有一個非常核心的問題,就是如何把一個句子用數字的形式有效地表達出來?如果能夠完成這一步,句子的分類就不成問題了。
那么,一個初步的思路是:給每個詞語賦予唯一的編號,然后把句子看成是編號的集合,比如假設1,2,3,4分別代表“我”、“數學”、“喜歡”、“討厭”,那么“我喜歡數學”就是[1, 3, 2],“我討厭數學”就是[1, 4, 2]。這種思路看起來有效,實際上非常有問題,比如一個穩定的模型會認為3跟4是很接近的,因此[1, 3, 2]和[1, 4, 2]應當給出接近的分類結果,但是按照我們的編號,3跟4所代表的詞語意思完全相反,分類結果不可能相同。因此,這種編碼方式并不可取。
有人可能會想到,把意思相近的詞語的編號湊在一堆不就行了?確實如果把相近的詞語編號放在一起,會大大提高模型的準確率。可是如果給每個詞語唯一的編號,并且將語義相近的詞語編號設為相近,實際上是假設了語義的單一性。然而事實并非如此,語義應該是高維的,一個詞語在不同的語境下總是有著不同的語義。
語義既然是高維的,那么在計算機中,詞語就應該表示成高維的向量。為什么高維向量可行?首先,高維向量解決了詞語的多方向發散問題。其次,高維向量允許我們用變化較小的數字來表征詞語。怎么說?我們知道,就中文而言,詞語的數量就多達數十萬,如果給每個詞語唯一的編號,那么編號就是從1到幾十萬變化,變化幅度如此之大,模型的穩定性是很難保證的。如果是高維向量,比如說20維,那么僅需要0和1就可以表達220 = 1048576(100萬)個詞語了。變化較小則能夠保證模型的穩定性。
現在有了這個思路,新的問題是,如何把詞語放到正確的高維向量中?Google有一個著名的開源工具——Word2Vec,它完成了的我們想要做的事情。
Word2Vec使用高維向量(詞向量,Word Embedding)表示詞語,并把語義相近的詞語放在相近的位置。我們只需要有大量的某語言的語料,就可以用它來訓練模型,獲得詞向量。對于詞向量,我們可以使用歐氏距離或余弦相似度找出具有相近語義的詞語。有了Word2Vec,我們就可以用詞向量來表示詞語,那么句子就對應著詞向量的集合,也就是矩陣,類似于圖像處理,圖像數字化后對應著一個像素矩陣。
對于圖像處理來說,已經有一套成熟的方法了,那就是卷積神經網絡(CNNs),它是能夠將矩陣形式的輸入編碼為較低維度的一維向量,而保留大多數有用信息。事實上,卷積神經網絡在圖像處理的那一套方法也可以直接用到自然語言處理任務中。
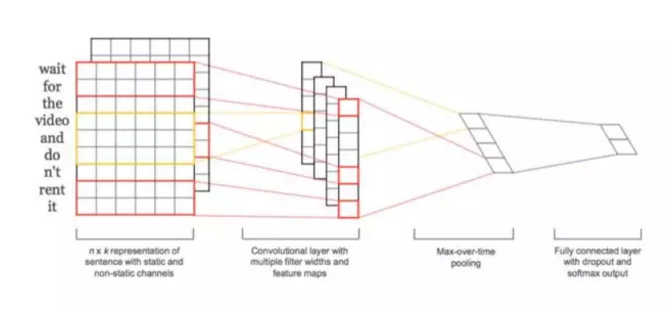
下面我給出一個基于CNN的文本分類模型的結構圖,非常直觀:
?
?
這個CNN模型共分四層:
- 第一層是詞向量層,文本中的每個詞,都將其映射到詞向量空間,假設詞向量為k維,則n個詞映射后,相當于生成一張n*k維的圖像;
- 第二層是卷積層,多個濾波器作用于詞向量層,不同濾波器生成不同的feature map;
- 第三層是池化層,取每個feature map的最大值;
- 第四層是一個全連接 + softmax層,輸出是每個類別的概率。
我們使用這種基于詞向量 + CNN的方法做文本分類,不需要人工提取特征,不需要領域知識,整個訓練過程高度自動化。在我們的任務中,這個模型的準確度可以達到90%以上,遠遠超過傳統模型。
自然語言處理任務中,另一個常用到的方法是循環神經網絡(RNNs)。它的作用跟卷積神經網絡是一樣的,將矩陣形式的輸入編碼為較低維度的一維向量,而保留大多數有用信息。跟卷積神經網絡的區別在于,卷積神經網絡更注重全局的模糊感知(就好像我們看一幅照片,事實上并沒有看清楚某個像素,而只是整體地把握圖片內容),而RNNs則是注重鄰近位置的重構,由此可見,對于語言任務,RNN似乎更具有說服力。因為語言總是由相鄰的字構成詞,相鄰的詞構成短語,相鄰的短語構成句子,因此,語言任務需要把鄰近位置的信息進行有效的整合。
基于詞向量 + LSTM(Long-Short Term Memory)的模型結構和基于CNN的模型結構是類似的,只需要把卷積層和池化層換成一個LSTM層即可。
不難發現,不管是CNN的模型還是RNN的模型,都使用詞向量(Word Embedding)來進行語義表示,事實上,基于神經網絡的自然語言處理方法大都是在詞向量的基礎上進行的。所以,理解Word Embedding,對于我們理解和使用深度學習的自然語言處理方法至關重要。
海航輿情云平臺實踐
下面我會講上面介紹的深度學習算法在海航輿情云平臺中的應用。
首先我簡單介紹一下海航的輿情云平臺:輿情云平臺項目的初衷是為了加強海航集團及其下屬各成員企業的品牌效應,并且減少關鍵信息傳播的成本,及時洞悉客戶評價和輿論走向,以及指導輿論引導工作,加快對緊急事件的響應速度。目前主要功能如下,包括數據爬取、數據存儲、微博輿情、新聞輿情、熱詞統計、情感分析、輿情監測、數據接口服務、熱點事件梳理:
- 數據爬取:每天定時計劃爬取指定微博,新聞媒體最新發布信息,存儲以供分析
- 數據存儲:存儲微博、新聞內容、圖片等,以及中間分析結果、計算結果
- 微博輿情:統計分析、信息監測、信息檢索
- 新聞輿情:統計分析、信息監測、信息檢索
- 熱詞統計:高頻度熱詞統計
- 情感分析:文本分析、根據文字內容定位情感傾向
- 輿情監測:根據指定敏感詞進行信息過濾,并提供通知功能
- 數據接口服務:提供對外的Rest的API數據服務
- 熱點事件梳理:提供檢索,優先列出熱度高的新聞、微博記錄
- 圖像識別和內容分析:(這部分正在做)
部分展示效果圖:
?
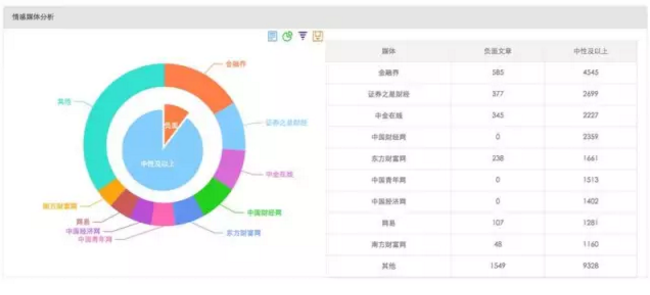
?
在輿情云平臺開發過程中,我們訓練了多個基于詞向量 + CNN模型,來實現情感分析的相關功能。
我們的機器學習工作流,如下圖:
?
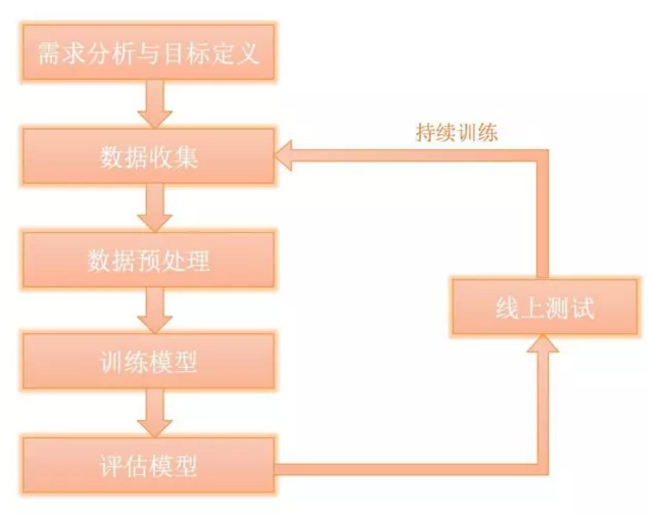
?
1.定義預測目標
我們的客戶比較關注用戶對其服務的評價和反饋情況,微博平臺就是一個很好的信息收集渠道,新浪微博中有大量對于其服務的肯定或者吐槽的信息,類似于商品評論,我們很容易就能判斷出某條微博的情感傾向。
此外,客戶常會關注一些敏感的新聞信息,和微博不同,新聞大多數都是在客觀地陳述某件事情,并沒有主觀的情緒在里面,那該如何定義『負面新聞』呢?通過進一步的溝通和梳理,我將『負面新聞』定義為:對于一個企業/組織/個人不利的、有消極影響的新聞,就可以被認為是『負面新聞』。
2.數據收集
收集數據的方式有很多,我們使用定向爬蟲從網上爬取需要的數據。數據源包括微博、主流媒體網站、大型論壇、指定行業網站等。
3.數據預處理
這里的主要工作是對上一步收集的數據進行情感標注,規則是:負面的標記0,中性及以上標記為1。我們的模型是監督訓練的,所以這一步必不可少。
4.構建并訓練模型
不同行業的常用詞匯和表述是不一樣的,為了簡化模型結構,同時保證準確率,我對不同行業的語料分開建模,這里以財經新聞為例,具體步驟是:
- 取10W條(越多越好)財經類新聞,對每條新聞進行分詞,統計每個詞出現的頻次,并將詞按頻次從高到低進行排序,形成一個序數——詞語的關系映射表。
- 構建基于詞向量 + CNN的網絡。
- 將數據劃分為訓練集和測試集。將訓練集數據進行分詞,通過查找映射表將文本轉化為模型所需要的輸入形式,然后把處理后的數據喂給模型進行訓練,密切關注訓練過程以防止過擬合。
- 在測試集上進行預測,計算得到準確率、召回率等指標。
- 交叉驗證。保證從多個方向學習樣本,避免陷入局部極小值。
5.評估模型
我認為評估模型可以從以下方面考慮:
- 精度方面:包括準確度(Accuracy)、精確度(Precision)、召回率(Recall)、ROC曲線等評價指標。
- 性能方面:在數據量有限、任務不復雜的情況下,盡量設計淺層的模型,它們計算開銷小,并且易于擴展。
6.使用模型
對于訓練好的模型,我們使用標準的API接口進行封裝,新爬取的數據無需經過任何加工,直接批量地送入模型,就可以批量地返回分類結果。
一般認為準確率達80%以上的模型具有生產價值。我們使用微博語料、財經新聞語料、科技新聞語料訓練的情感分類模型,平均準確率達到了90%以上,并且隨著數據量的逐步增長,我們的模型還可以進一步優化。
答疑
Q1:情感的強度如何量化??
楊欣偉:其實這對人來說也是一個難題,比如我們很容易判斷一段評論是積極的還是消極的,但是我們難以對評論的情感傾向進行更細粒度的量化;機器在學習我們的判斷邏輯,我們做不到的,機器也做不到。Q2:情感分析的情感是指什么??
楊欣偉:情感是指態度、意見和感情。換句話說,它們是主觀印象,而不是客觀事實。我在分享中延伸了它的概念,『情感』是可以由我們自由定義的。Q3:能推薦一款比較好的分詞工具嗎??
楊欣偉:出于對效率的考慮,我選擇了Jieba。這里有一個關于中文分詞工具的評測,您可以參考下http://it.sohu.com/20161201/n474637590.shtml。Q4:咱們平臺用了哪些深度學習開源工具??
楊欣偉:使用了Keras和Tensorflow。Tensorflow是時下最流行的深度學習框架,隨著版本的更迭它的功能也越來越完善。但是它的API非常的低層,使用的時候往往需要編寫大量代碼,即便是構建一個相對簡單的模型。Keras則是一個高層的庫,它的后臺可以在Tensorflow和Theano之間自由切換,并且,Keras代碼可以和Tensorflow代碼無縫銜接。





)


__ name__中包含什么?)



)


的兩個模式)

css-loader詳細使用說明)

