1. 端口相關的命令
1.1 查看端口是否打開
使用 nc 和 telnet 這兩個命令可以非常方便的查看到對方端口是否打開或者網絡是否可達。如果對端端口沒有打開,使用 telnet 和 nc 命令會出現 “Connection refused” 錯誤
1.2 查看監聽端口的進程
- 使用 netstat
sudo netstat -ltpn | grep :22

2. 使用 lsof
因為在 linux 上一切皆文件,TCP socket 連接也是一個 fd。因此使用 lsof 也可以
sudo lsof -n -P -i:22
其中 -n 表示不將 IP 轉換為 hostname,-P 表示不將 port number 轉換為 service name,-i:port 表示端口號為 22 的進程
1.3 查看進程監聽的端口
- 使用 netstat
sudo netstat -atpn | grep 22
- 使用 lsof
sudo lsof -n -P -p 1333 | grep TCP
- /proc/pid
每個進程啟動后,會生成/proc/pid目錄,里面存在一個fd目錄,fd 目錄表示進程打開的所有的文件,cd 到那個目錄,fd 為 0,1,2的分別表示標準輸入stdin(0)、標準輸出stdout(1)、錯誤輸出stderr(2)。fd 為 3 表示 nc 監聽的套接字的inode ,通過這個 inode 號來找改 socket 的信息。
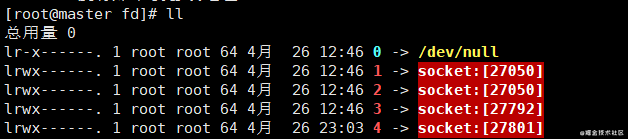
cat /proc/net/tcp存有tcp連接的信息,根據inode可以找到特定的socket信息

2. 臨時端口號是如何分配的
有兩種典型的使用方式會生成臨時端口:
- 調用 bind 函數不指定端口
- 調用 connect 函數
3. 最大傳輸單元(Maximum Transmission Unit, MTU)
數據鏈路層傳輸的幀大小是有限制的,不能把一個太大的包直接塞給鏈路層,這個限制被稱為「最大傳輸單元(Maximum Transmission Unit, MTU)」以太網的幀最小的幀是 64 字節,除去 14 字節頭部和 4 字節 CRC 字段,有效荷載最小為 46 字節。最大的幀是 1518 字節,除去 14 字節頭部和 4 字節 CRC,有效荷載最大為 1500,這個值就是以太網的 MTU。
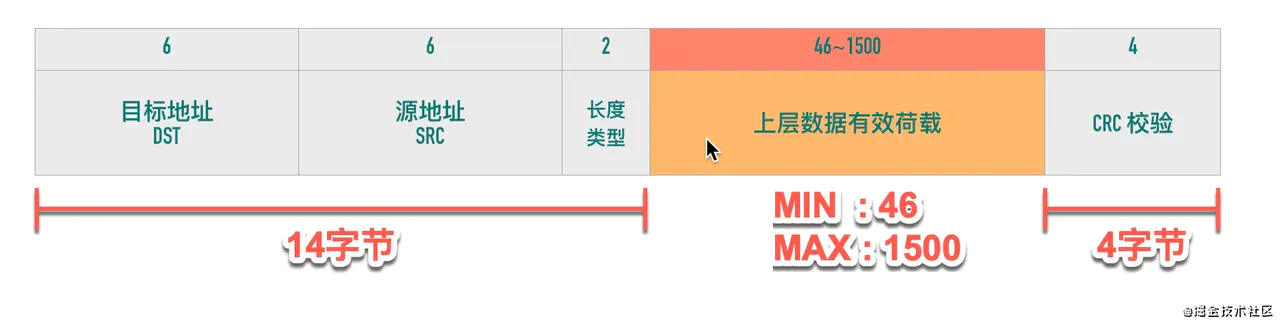
MTU=1500的由來
最早的以太網工作方式:載波多路復用/沖突檢測(CSMA/CD),因為網絡是共享的,即任何一個節點發送數據之前,先要偵聽線路上是否有數據在傳輸,如果有,需要等待,如果線路可用,才可以發送。
假設A發出第一個bit位,到達B,而B也正在傳輸第一個bit位,于是產生沖突,沖突信號得讓A在完成最后一個bit位之前到達A,這個一來一回的時間間隙slot time是57.6μs。在10Mbps的網絡中,在57.6μs的時間內,能夠傳輸576個bit,所以要求以太網幀最小長度為576個bits,從而讓最極端的碰撞都能夠被檢測到。這個576bit換算一下就是72個字節,去掉8個字節的前導符和幀開始符,所以以太網幀的最小長度為64字節。
為什么標準以太網幀長度上限為1518字節?
IP頭total length為兩個byte,理論上IP packet可以有65535 byte,加上Ethernet Frame頭和尾,可以有65535 +14 + 4 = 65553 byte。如果在10Mbps以太網上,將會占用共享鏈路長達50ms,這將嚴重影響其它主機的通信,特別是對延遲敏感的應用是無法接受的。由于線路質量差而引起的丟包,發生在大包的概率也比小包概率大得多,所以大包在丟包率較高的線路上不是一個好的選擇。但是如果選擇一個比較小的長度,傳輸效率又不高,拿TCP應用來說,如果選擇以太網長度為218byte,TCP payload = 218 - Ethernet Header - IP Header - TCP Header = 218 - 18 - 20 - 20 = 160 byte那有效傳輸效率= 160 / 218 = 73%而如果以太網長度為1518,那有效傳輸效率= 1460 / 1518 = 96%通過比較,選擇較大的幀長度,有效傳輸效率更高,而更大的幀長度同時也會造成上述的問題,于是最終選擇一個折衷的長度:1518 byte ! 對應的IP packet 就是 1500 byte,這就是最大傳輸單元MTU的由來。
4. IP 分段
IPv4 數據報的最大大小為 65535 字節,這已經遠遠超過了以太網的 MTU,而且有些網絡還會開啟巨幀(Jumbo Frame)能達到 9000 字節。 當一個 IP 數據包大于 MTU 時,IP 會把數據報文進行切割為多個小的片段(小于 MTU),使得這些小的報文可以通過鏈路層進行傳輸

利用 IP 包分片的策略,有一種對應的網絡攻擊方式IP fragment attack,就是一直傳More fragments = 1的包,導致接收方一直緩存分片,從而可能導致接收方內存耗盡。
IP分片實例
// 在cmd 下ping 網關10.103.240.1
// ping 命令: -l表示數據長度 -n ping次數 -f設置DF標志表示不能分片
ping 10.103.240.1 -l 5000 -n 1
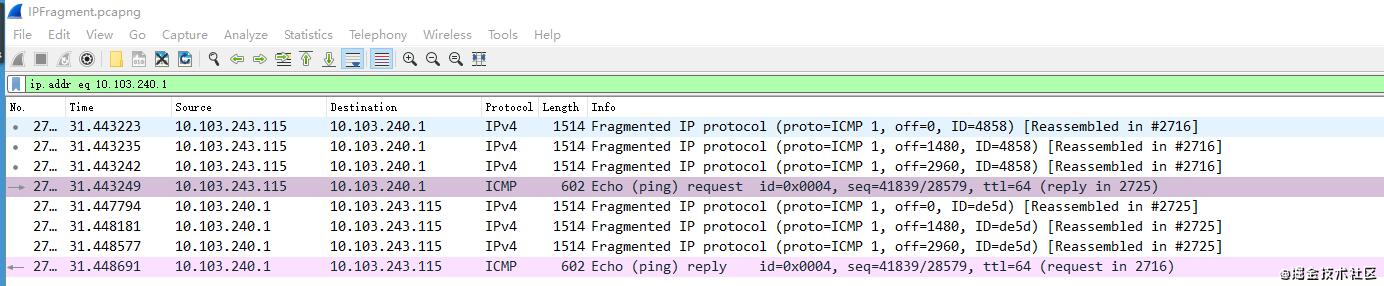
由上圖可知,每個分片都包含off=xxx,ID=4858信息,接收方依據這兩個值,把ID相同的分片按照off值(偏移量)進行重組的。
下圖所示的最后一個分片,即第2716號包,它包含了一個More fragment = 0的Flag,表示最后一個分片,因此接收方可以開始重組。
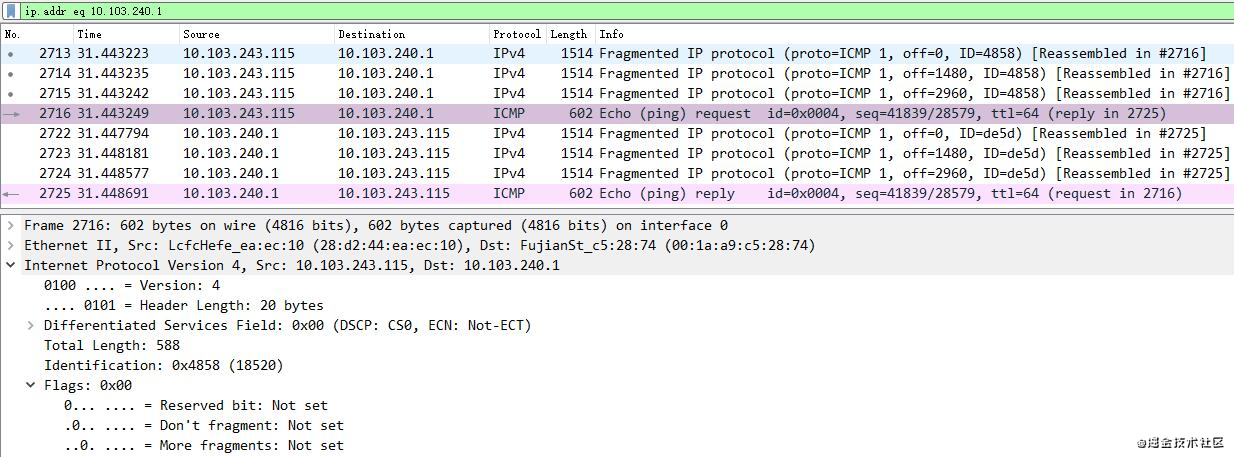
而其他的分片比如第2715號包包含一個More fragment = 1的Flag,如下圖所示,因此接收方知道后續還有更多的分片,所以先緩存著不重組。IP分片導致的網絡攻擊方式就是持續發送More fragment為1的包,導致接收方一直緩存分片,從而耗盡內存。

5. TCP 最大段大小(Max Segment Size,MSS)
TCP 為了避免被發送方分片,會主動把數據分割成小段再交給網絡層,最大的分段大小稱之為 MS(MaxSegment Size)。
MSS = MTU - IP header頭大小 - TCP 頭大小
這樣一個 MSS 的數據恰好能裝進一個 MTU 而不用分片。
TCP在建立連接時進行三次握手,前兩個握手包中雙方互相聲明自己的MSS,客戶端聲明MSS=8960,服務器端聲明了MSS=1460。三次握手之后,客戶端的MTU值比服務器端大,如果發送一個9000字節的包過去可能被分片或丟棄。因此客戶端會把自己的MSS也降到1460字節。
6. 為什么有時候抓包看到的單個數據包大于 MTU
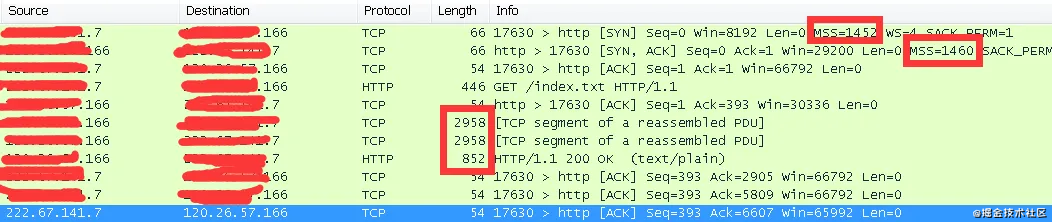
原因是這個分片不是發生在IP協議上,而是在TCP協議上,有個東西叫tso(tcp segment offload),意思是如果網卡支持tso,操作系統發送大的tcp包時,不需要消耗CPU來計算分片,而是將整個包發送到網卡,由網卡的NPU來進行分片處理。而抓包軟件抓的僅僅是CPU處理后的信息,也就是說在發送方抓的時候還沒到網卡就被CPU抓了,而真正的分片是由后面的網卡才分片
參考資料
《深入理解 TCP 協議:從原理到實戰》







 三次握手)
![[設計模式]State模式](http://pic.xiahunao.cn/[設計模式]State模式)
java的數組HashMap、ConcurrentHashMap、ArrayList、LinkedList)


)



虛擬化和容器)


