神經網絡推理
Measuring the inference time of a trained deep neural model on different hardware devices is a critical task when making deployment decisions. Should you deploy your inference on 8 Nvidia V100s, on 12 P100s, or perhaps you can use 64 CPU cores?
在制定部署決策時,測量經過訓練的深度神經模型在不同硬件設備上的推理時間是一項關鍵任務。 您應該在8個Nvidia V100、12個P100上部署推理,還是可以使用64個CPU內核?
When it comes to inference timing, apple-to-apple comparisons among devices do not require rocket-science. Nevertheless, the process is a true time consuming burden that is prone to errors and requires expertise to perform correctly.
當涉及到推理時間時,設備之間的蘋果對蘋果比較不需要火箭科學。 然而,該過程是一個真正耗時的負擔,容易出錯,并且需要專業知識才能正確執行。
Fortunately, DeciAI released a free service that does it for you. The Deci Inference Performance Simulator (DIPS) can help practitioners analyze their inference performance. DIPS can measure model throughput, latency, cloud cost, model memory usage, and other important performance metrics. It provides a full analysis on how your model will behave and perform across various production environments — at no cost.
幸運的是,DeciAI發布了一項免費服務,可以為您完成這項工作。 Deci推理性能模擬器(DIPS)可以幫助從業人員分析其推理性能。 DIPS可以測量模型吞吐量,延遲,云成本,模型內存使用情況以及其他重要的性能指標。 它免費提供了有關模型在各種生產環境中的行為和性能的完整分析。
為什么測量運行時性能很痛苦? (Why is measuring run-time performance painful?)
In how to measure deep learning performance, we provide practical guidelines for inference evaluation that include the following steps: (1) Write a latency measurement script (2) Write a script to compute the optimal batch size for inference (3) Write a throughput measurement script (4) Launch several machines on the cloud to run the all these scripts and (5) Summarize the obtained metrics and analyze the results.
在如何衡量深度學習性能方面 ,我們提供了用于推理評估的實用指南,包括以下步驟:(1)編寫延遲測量腳本(2)編寫腳本以計算推理的最佳批處理大小(3)編寫吞吐量度量腳本(4)在云上啟動多臺計算機以運行所有這些腳本,以及(5)匯總獲得的指標并分析結果。
Performing these steps is not only time consuming, it is also highly error prone. For example, issues may arise when it comes to timing on the CPU, measuring the transfer of data to and from the acceleration device, measuring preprocessing, and so on.
執行這些步驟不僅耗時,而且極易出錯。 例如,當涉及到CPU上的計時,測量與加速設備之間的數據傳輸,測量預處理等等時,可能會出現問題。
The DIPS platform deals with all the above details, and more, making it possible for you to obtain accurate inference timing. At Deci AI, our business is about accelerating inference and we created DIPS for our own internal use. When we saw that even practitioners face challenges with timing inference principles, we realized that everyone would benefit if we released DIPS to the community. We firmly believe that helping others tackle this technical challenge will go a long way towards promoting unified timing calculations.
DIPS平臺處理上述所有細節,并提供更多信息,使您可以獲取準確的推理時間。 在Deci AI,我們的業務是加速推理,我們創建了DIPS供內部使用。 當我們看到從業人員甚至在時序推理原則上也面臨挑戰時,我們意識到,如果我們向社區發布DIPS,每個人都會從中受益。 我們堅信,幫助他人應對這一技術挑戰將大大有助于促進統一的時序計算。
DIPS報告 (The DIPS Report)
The DIPS service platform receives as input a neural model and returns a comprehensive report on the model’s inference performance.
DIPS服務平臺接收神經模型作為輸入,并返回有關模型推理性能的綜合報告。
The model can be completely untrained, because DIPS is only concerned with timing and costs.
該模型可以完全不受訓練,因為DIPS只考慮時間和成本。
In the next section, we describe how to input your own model. But first, let’s see what makes this tool so attractive. Below you can see the Results Summary taken from a typical DIPS report.
在下一節中,我們描述如何輸入您自己的模型。 但是首先,讓我們看看是什么使該工具如此吸引人。 您可以在下面看到來自典型DIPS報告的結果摘要。
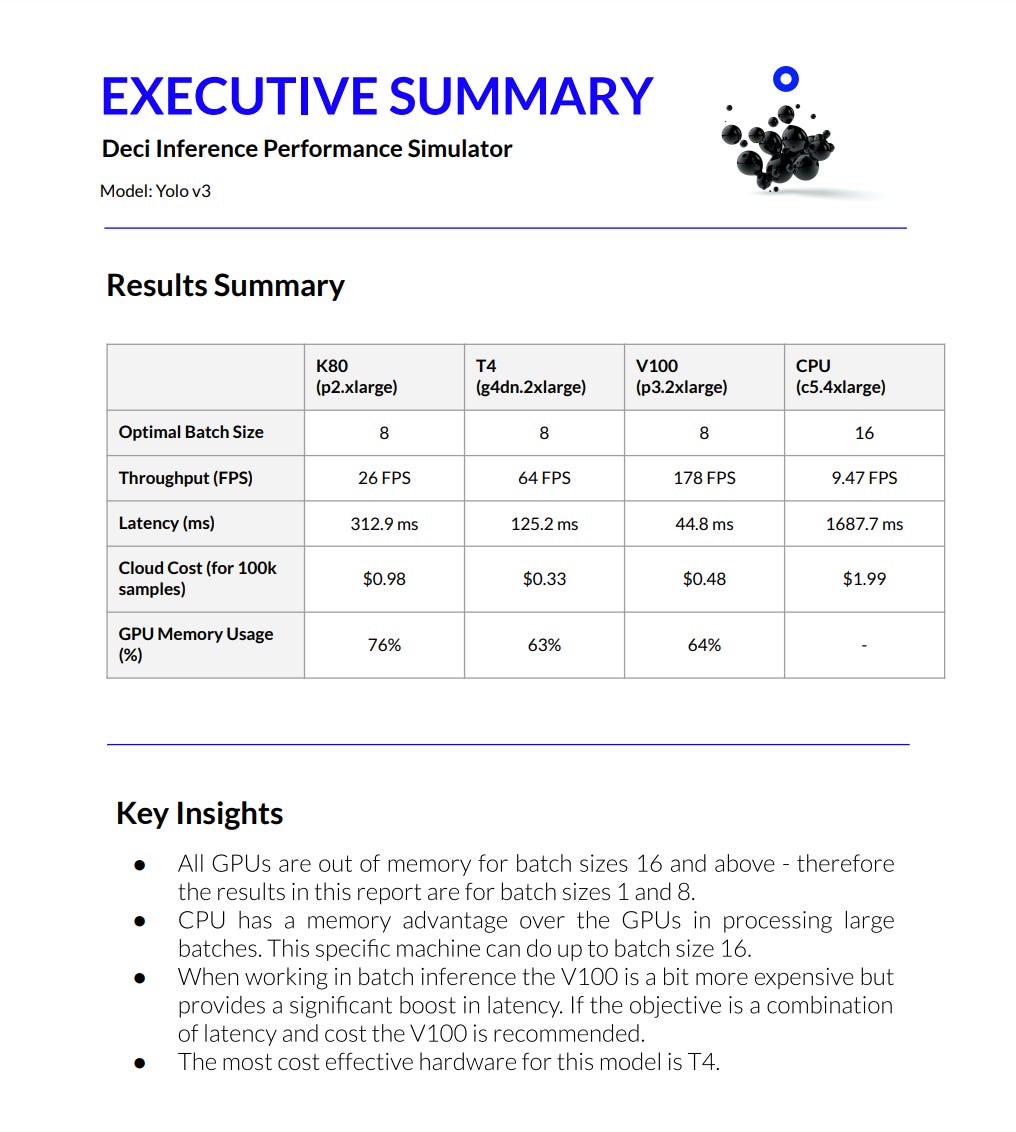
The model that gave rise to this report is Yolo v3, implemented in ONNX. (DIPS also supports PyTorch and TensorFlow.) As you can see, the report includes 5 categories and a list of key insights. For example, one conclusion is that using Tesla-V100 will yield the highest throughput and lowest latency. Another non-trivial conclusion is that T-4 will yield the best price for the inference of 100K images. Other insights note the capacity of each model on the different hardware (optimal batch size), the tradeoff between cost and performance for each hardware, memory usage, and much more.
產生此報告的模型是在ONNX中實現的Yolo v3。 (DIPS還支持PyTorch和TensorFlow。)如您所見,該報告包含5個類別和關鍵見解列表。 例如,一個結論是,使用Tesla-V100將產生最高的吞吐量和最低的延遲。 另一個不平凡的結論是,T-4將為推斷100K圖像提供最佳價格。 其他見解指出,每種模型在不同硬件上的容量(最佳批處理大小),每種硬件的成本和性能之間的權衡,內存使用情況等等。
Even experienced programmers might need several days of code writing to produce this kind of study and a similar report encompassing all these hardware devices. With DIPS, it will take you at most a few minutes!
即使是經驗豐富的程序員,也可能需要幾天的代碼編寫來進行此類研究,并且需要涵蓋所有這些硬件設備的類似報告。 使用DIPS,最多只需要幾分鐘!
DIPS also offers a deeper look into each of the sections of the report. For example, anyone interested in computation cost can look at the report page that specifies the cost aspects for each of the hardwares. For the scenario above, the model cloud cost section of the report looks like this:
DIPS還對報告的每個部分進行了更深入的研究。 例如,任何對計算成本感興趣的人都可以查看報告頁面,該頁面指定了每種硬件的成本方面。 對于上述情況,報告的模型云成本部分如下所示:
Using the information provided, you can optimize your cloud costs depending on the desired input batch sizes — and even compare the cost of several models on a specific hardware.
使用提供的信息,您可以根據所需的輸入批處理大小來優化您的云成本,甚至可以比較特定硬件上幾種型號的成本。
如何使用DIPS (How to Use DIPS)
EMBED: https://www.youtube.com/watch?v=cC9nMFS1e_c
嵌入: https : //www.youtube.com/watch?v = cC9nMFS1e_c
Let’s take a quick walk-through on how to use the DIPS. You can find DIPS on Deci’s website. After inserting some initial details (Step 1) you will land on the following page (Step 2):
讓我們快速瀏覽一下如何使用DIPS。 您可以在Deci 網站上找到DIPS。 插入一些初始詳細信息(步驟1)后,您將進入以下頁面(步驟2):
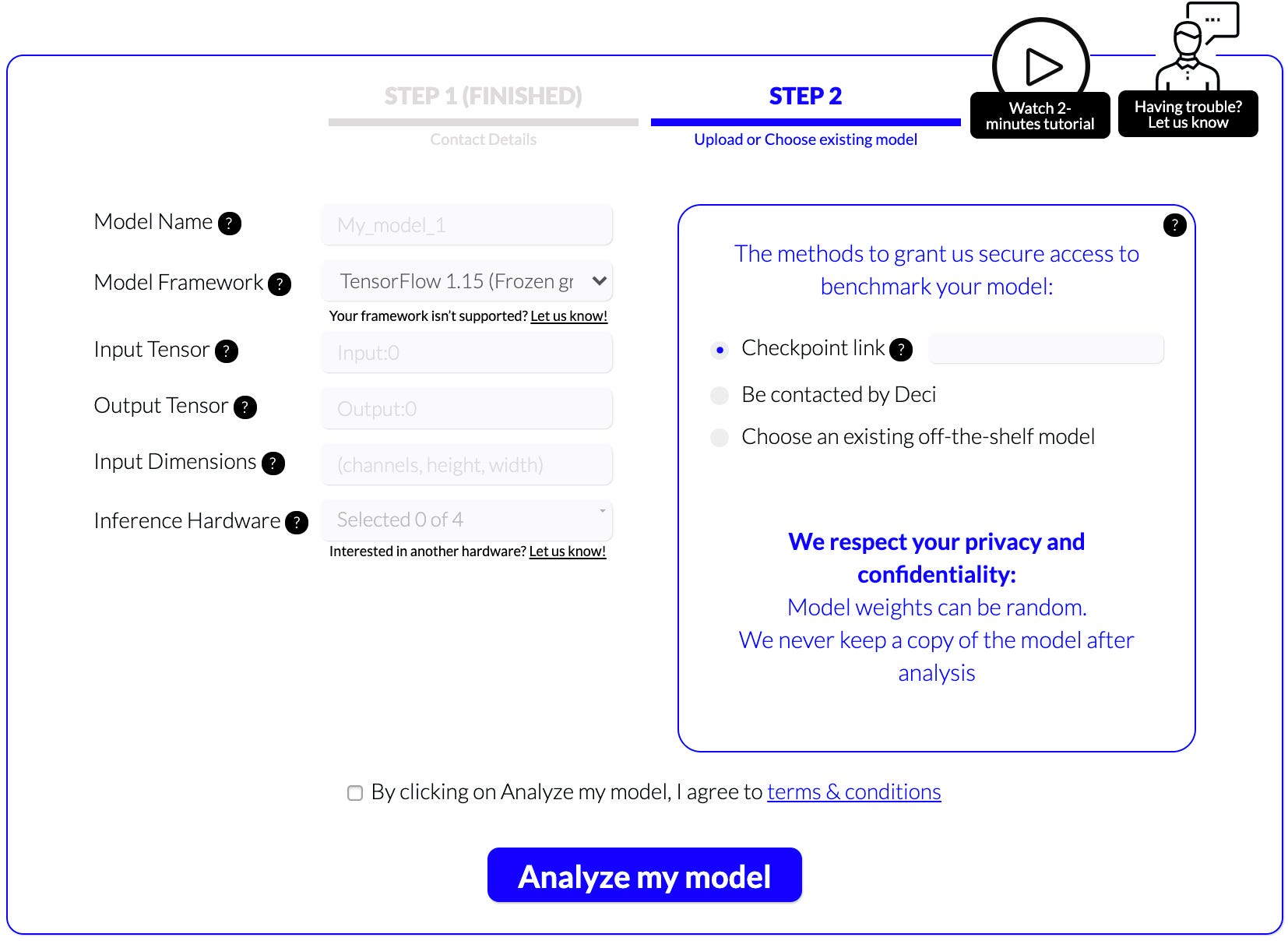
This page allows you to provide the minimal details needed for us to analyze your model. Fill in the following basic information:
該頁面允許您提供我們分析模型所需的最少詳細信息。 填寫以下基本信息:
Model name — The name of the model you would like to analyze (any string is OK).
模型名稱 -您要分析的模型的名稱(任何字符串都可以)。
Model framework — Choose one of the given frameworks. The minimal requirement for testing each framework is written in blue.
模型框架 -選擇給定的框架之一。 測試每個框架的最低要求用藍色表示。
Input dimension — The dimension of the tensor that should be used for the network. For example, if you work on ImageNet and PyTorch this will be (3,224,224).
輸入維數 -網絡應使用的張量的維數。 例如,如果您使用ImageNet和PyTorch,則為(3,224,224)。
Inference hardware — The hardware you wish to test. You can choose up to 4 hardware types: Intel CPU, Nvidia V100, Nvidia T4, Nvidia K80.
推理硬件 —您要測試的硬件。 您最多可以選擇4種硬件類型:英特爾CPU,Nvidia V100,Nvidia T4,Nvidia K80。
- Choose how you want to give us access to the model. 選擇您希望我們如何訪問模型的方式。
- Checkpoint link — Share the model via a public link. When you select the framework, you’ll find specific instructions in blue under the framework field. 檢查點鏈接—通過公共鏈接共享模型。 選擇框架后,您會在“框架”字段下以藍色找到特定的說明。
- Be contacted by Deci — Deci’s expert will contact you to get the model. Deci與您聯系-Deci的專家將與您聯系以獲取模型。
- Use an existing off-the-shelf model — You have the option of choosing one of several off-the-shelf models (e.g., ResNet 18/50, EfficientNet, MobileNet, and Yolo). 使用現有的現成模型-您可以選擇幾種現成模型(例如ResNet 18/50,EfficientNet,MobileNet和Yolo)之一。
As mentioned above, you don’t need to supply a trained model in order to use DIPS. An untrained model will give rise to the same inference timing (and cost) metrics.
如上所述,您無需提供經過訓練的模型即可使用DIPS。 未經訓練的模型將產生相同的推理時間(和成本)指標。
為什么在隱私方面可以放松一下 (Why you can relax when it comes to privacy)
It’s natural that most users will be concerned about sharing models, weights, or data. For this reason, we built DIPS as a fully secure and private application, where all the data and model weights remain confidential. We also allow you to choose an off-the-shelf model from our model repository, so we use our own existing models for analysis. After analyzing the model, we immediately delete your model from our servers. We never save a copy of your model. Moreover, DIPS uses a secure transfer protocol with the highest encryption standards available. At Deci, we are committed to ensuring that no one will use or distribute any of the input models. If you still have privacy concerns, you can upload an open source model that has the same characteristics, or alter your own model.
大多數用戶自然會擔心共享模型,權重或數據。 因此,我們將DIPS構建為完全安全的私有應用程序,其中所有數據和模型權重均保持機密。 我們還允許您從模型存儲庫中選擇現成的模型,因此我們使用自己的現有模型進行分析。 分析模型后,我們立即從服務器中刪除您的模型。 我們絕不會保存您的模型的副本。 而且,DIPS使用具有最高可用加密標準的安全傳輸協議。 在Deci,我們致力于確保沒有人會使用或分發任何輸入模型。 如果仍然有隱私問題,可以上傳具有相同特征的開源模型,或更改自己的模型。
節省時間并防止在測??量模型性能時出錯 (Save time and prevent errors in measuring your model performance)
DIPS is a new tool, available free of charge, for measuring the inference performance of deep learning architectures on different hardware platforms. It provides a unified approach to evaluating your model’s metrics with the simple click of a button. DIPS is openly available to the deep learning community to help save time and prevent errors in latency/throughput measurements.
DIPS是免費提供的新工具,用于測量不同硬件平臺上的深度學習架構的推理性能。 只需單擊一個按鈕,它便提供了一種統一的方法來評估模型的指標。 DIPS向深度學習社區開放,以幫助節省時間并防止延遲/吞吐量測量中的錯誤。
Deci is committed to keeping any models evaluated using DIPS completely secure and private. So all that remains is for you to try DIPS from the following link and tell us what you think.
Deci致力于使使用DIPS評估的任何模型都完全安全和私密。 因此,剩下的就是讓您嘗試以下鏈接中的 DIPS,并告訴我們您的想法。
翻譯自: https://towardsdatascience.com/a-new-tool-for-analysing-neural-network-inference-performance-13cc21d2efea
神經網絡推理
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/391140.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/391140.shtml 英文地址,請注明出處:http://en.pswp.cn/news/391140.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Eclipse斷點調試

react部署在node_如何在沒有命令行的情況下在3分鐘內將React + Node應用程序部署到Heroku
—系統表空間)
深入理解InnoDB(7)—系統表空間

CodeForces - 869B The Eternal Immortality

如何在24行JavaScript中實現Redux

卡方檢驗 原理_什么是卡方檢驗及其工作原理?
命名規范)
Web UI 設計(網頁設計)命名規范
)
leetcode 1486. 數組異或操作(位運算)

27個機器學習圖表翻譯_使用機器學習的信息圖表信息組織
)
在HTML中使用javascript (js高級程序設計)

大數據新手之路二:安裝Flume
)
leetcode 1723. 完成所有工作的最短時間(二分+剪枝+回溯)

異步解耦_如何使用異步生成器解耦業務邏輯

函數的定義,語法,二維數組,幾個練習題
)
leetcode 1482. 制作 m 束花所需的最少天數(二分查找)

算法訓練營 重編碼_編碼訓練營手冊:沉浸式工程程序介紹
)
面向Tableau開發人員的Python簡要介紹(第4部分)
![bzoj 4552: [Tjoi2016Heoi2016]排序](http://pic.xiahunao.cn/bzoj 4552: [Tjoi2016Heoi2016]排序)
bzoj 4552: [Tjoi2016Heoi2016]排序

oracle之 手動創建 emp 表 與 dept 表
—單表訪問)