pytorch深度學習
The recommendation is a simple algorithm that works on the principle of data filtering. The algorithm finds a pattern between two users and recommends or provides additional relevant information to a user in choosing a product or services.
該建議是一種基于數據過濾原理的簡單算法。 該算法在兩個用戶之間找到一種模式,并在選擇產品或服務時向用戶推薦或提供其他相關信息。
TL;DR Please follow this link to directly jump into full source code required to prepare the dataset and to train the model.
TL; DR請單擊此鏈接直接跳至準備數據集和訓練模型所需的完整源代碼。
協同過濾 (Collaborative Filtering)
Whenever we go to Amazon or any online store, we get recommendations stating that “Customers who brought this item also bought”. These recommendations based on your preference is obtained by an algorithm which predicts based on the previous buying made, this algorithm is called Collaborative Filtering. The main idea or concept in this algorithm is that network learns the similarity between two products based on buying history for example a person bought bread mostly buys milk, whenever we buy bread algorithm suggest us to buy milk.
每當我們去亞馬遜或任何在線商店時,我們都會得到建議,說明“攜帶此商品的顧客也購買了”。 這些根據您的偏好提供的建議是通過一種算法進行的,該算法根據之前的購買進行預測,該算法稱為“ 協同過濾” 。 該算法的主要思想或概念是,網絡基于購買歷史來學習兩種產品之間的相似性,例如,每當我們購買面包算法建議我們購買牛奶時,一個人購買的面包主要是購買牛奶。
To implement this we are using a Movie dataset called MovieLens (https://grouplens.org/datasets/movielens/). This is an open-source dataset available in grouplens.org, The data set has 25000095 ratings and 1093360 tag applications across 62423 movies. These data are created by 162541 users between 09 January 1995 and 21 November 2019.
為了實現這一點,我們使用了一個名為MovieLens ( https://grouplens.org/datasets/movielens/ )的Movie數據集。 這是grouplens.org中可用的開源數據集。該數據集在62423個電影中具有25000095評級和1093360標簽應用程序。 這些數據由162541用戶在1995年1月9日至2019年11月21日期間創建。
Dataset has
數據集有
- User Ids 用戶編號
- Movie Ids 電影ID
- Rating data file Structure (ratings.csv) 評級數據文件結構(ratings.csv)
userId,movieId,rating,timestamp- Tags Data File Structure (tags.csv) 標簽數據文件結構(tags.csv)
userId,movieId,tag,timestamp- Movies Data File Structure (movies.csv) 電影數據文件結構(movies.csv)
movieId,title,genresWe will be analyzing two major data frames rating.csv and movies.csv. Below shows the image of sample head() from each data frame.
我們將分析兩個主要的數據幀rating.csv和movies.csv。 下面顯示了每個數據幀中的head()樣本圖像。

A machine learning algorithm accepts only an array of numerical values, we just can't send the above dataset directly. There are a lot of embedding approaches most widely used approach is one-hot encoding, next is word2vec. One hot encoding, the columns with categorical data are numbered based on the number of categories like 0/1. We have more than 1000 category data, so we created a Neural network-based embedding of data.
機器學習算法僅接受數值數組,我們無法直接發送上述數據集。 嵌入方法有很多,最廣泛使用的方法是單熱編碼,其次是word2vec。 一種熱編碼,具有類別數據的列是根據類別的數量(例如0/1)進行編號的。 我們有1000多個類別數據,因此我們創建了基于神經網絡的數據嵌入。
網絡 (Network)
With the PyTorch framework, we created an embedding network, which takes in the Number of users and Number of movies as input. The network takes the output of Movies embedding and User embeddings as inputs, which concatenate into a column (array). The network has 4 layers starting with dropout layers, then 3 fully connected layers with relu activation and a dropout. Drop out as added to randomize the network and increase the learning capability of the network. Finally, output layer with a sigmoid activation function.
使用PyTorch框架,我們創建了一個嵌入網絡,該網絡將用戶數和電影數作為輸入。 網絡將“電影”嵌入和“用戶”嵌入的輸出作為輸入,并連接到一列(數組)中。 該網絡具有4個層,其中第1個層是Dropout層,然后是3個完全連接的層,具有relu激活和一個dropout。 退出添加以使網絡隨機化并增加網絡的學習能力。 最后,輸出層具有S型激活功能。
Below snippet shows the network implementation with the PyTorch framework. (https://gist.github.com/9aec88bc33b50dbf9c6390bbeb42ba0b.git)
下面的代碼片段顯示了使用PyTorch框架的網絡實現。 ( https://gist.github.com/9aec88bc33b50dbf9c6390bbeb42ba0b.git )
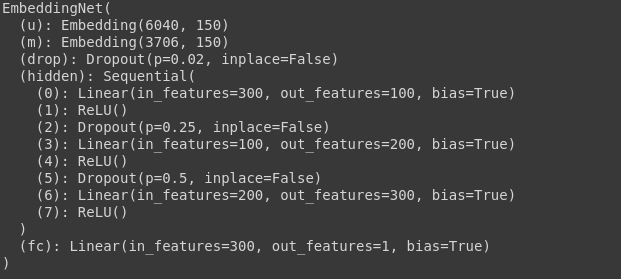
class EmbeddingNet(nn.Module):"""Creates a dense network with embedding layers.Args:n_users: Number of unique users in the dataset.n_movies: Number of unique movies in the dataset.n_factors: Number of columns in the embeddings matrix.embedding_dropout: Dropout rate to apply right after embeddings layer.hidden:A single integer or a list of integers defining the number of units in hidden layer(s).dropouts: A single integer or a list of integers defining the dropout layers rates applyied right after each of hidden layers."""def __init__(self, n_users, n_movies,n_factors=50, embedding_dropout=0.02, hidden=10, dropouts=0.2):super().__init__()hidden = get_list(hidden)dropouts = get_list(dropouts)n_last = hidden[-1]def gen_layers(n_in):"""A generator that yields a sequence of hidden layers and their activations/dropouts.Note that the function captures `hidden` and `dropouts` values from the outer scope."""nonlocal hidden, dropoutsassert len(dropouts) <= len(hidden)for n_out, rate in zip_longest(hidden, dropouts):yield nn.Linear(n_in, n_out)yield nn.ReLU()if rate is not None and rate > 0.:yield nn.Dropout(rate)n_in = n_outself.u = nn.Embedding(n_users, n_factors)self.m = nn.Embedding(n_movies, n_factors)self.drop = nn.Dropout(embedding_dropout)self.hidden = nn.Sequential(*list(gen_layers(n_factors * 2)))self.fc = nn.Linear(n_last, 1)self._init()def forward(self, users, movies, minmax=None):features = torch.cat([self.u(users), self.m(movies)], dim=1)x = self.drop(features)x = self.hidden(x)out = torch.sigmoid(self.fc(x))if minmax is not None:min_rating, max_rating = minmaxout = out*(max_rating - min_rating + 1) + min_rating - 0.5return outdef _init(self):"""Setup embeddings and hidden layers with reasonable initial values."""def init(m):if type(m) == nn.Linear:torch.nn.init.xavier_uniform_(m.weight)m.bias.data.fill_(0.01)self.u.weight.data.uniform_(-0.05, 0.05)self.m.weight.data.uniform_(-0.05, 0.05)self.hidden.apply(init)init(self.fc)def get_list(n):if isinstance(n, (int, float)):return [n]elif hasattr(n, '__iter__'):return list(n)raise TypeError('layers configuraiton should be a single number or a list of numbers')For example with a network with 100,200,300 as a number of hidden layers and dropouts. The output network with be as shown below.
例如,對于一個具有100,200,300的網絡,其中包含許多隱藏層和缺失。 輸出網絡如下所示。
EmbeddingNet(n, m, n_factors=150, hidden=[100, 200, 300], dropouts=[0.25, 0.5])
EmbeddingNet(n,m,n_factors = 150,隱藏= [100,200,300],輟學= [0.25,0.5])
訓練循環 (Training Loop)
Below is the snippet of the training loop with Mean Squared Loss as quality measurement metrics and Adam function are used as an optimizer. Training parameters are chosen based on my previous experience, you can change it according to your own style.
下面是訓練循環的代碼段,其中均方根損耗作為質量測量指標和Adam函數用作優化器。 訓練參數是根據我以前的經驗選擇的,您可以根據自己的風格進行更改。
# training loop parameters
lr = 1e-3
wd = 1e-5
bs = 2000
n_epochs = 100
patience = 10
no_improvements = 0
best_loss = np.inf
best_weights = None
history = []
lr_history = []# use GPU if available
identifier = 'cuda:0' if torch.cuda.is_available() else 'cpu'
device = torch.device(identifier)# setting up network, optimizer and learning rate scheduler
net.to(device)
criterion = nn.MSELoss(reduction='sum')
optimizer = optim.Adam(net.parameters(), lr=lr, weight_decay=wd)
iterations_per_epoch = int(math.ceil(dataset_sizes['train'] // bs))
sched_func = cosine(t_max=iterations_per_epoch * 2, eta_min=lr/10)
scheduler = CyclicLR(optimizer, sched_func)fmt = '[{epoch:03d}/{total:03d}] train: {train:.4f} - val: {val:.4f}'# start training
for epoch in range(n_epochs):stats = {'epoch': epoch + 1, 'total': n_epochs}for phase in ('train', 'val'):training = phase == 'train'running_loss = 0.0n_batches = 0iterator = batches(*datasets[phase], shuffle=training, bs=bs)for batch in iterator:x_batch, y_batch = [b.to(device) for b in batch]optimizer.zero_grad()with torch.set_grad_enabled(training):outputs = net(x_batch[:, 1], x_batch[:, 0], minmax)loss = criterion(outputs, y_batch)if training:scheduler.step()loss.backward()optimizer.step()lr_history.extend(scheduler.get_lr())running_loss += loss.item()epoch_loss = running_loss / dataset_sizes[phase]stats[phase] = epoch_lossif phase == 'val':if epoch_loss < best_loss:print('loss improvement on epoch: %d' % (epoch + 1))best_loss = epoch_lossbest_weights = copy.deepcopy(net.state_dict())no_improvements = 0else:no_improvements += 1history.append(stats)print(fmt.format(**stats))if no_improvements >= patience:breakPlease follow this link to see the full source code required to prepare the dataset and to train the model.
請點擊此鏈接查看準備數據集和訓練模型所需的完整源代碼。
結論 (Conclusion)
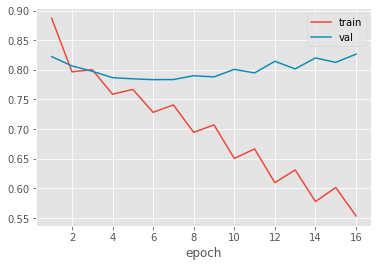
After 10–15mins of training the network resulted in an accuracy of 0.8853. The above graph shows the learning curve of the network during training and validation over 16 epochs. PyTorch is a powerful framework that has the potential to easily scaling it up large datasets. There is another data set available at Kaggle (https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system?) that would be great to try it.
經過10-15分鐘的培訓,網絡得出的精度為0.8853。 上圖顯示了在超過16個時期的訓練和驗證過程中網絡的學習曲線。 PyTorch是一個功能強大的框架,具有輕松擴展大型數據集的潛力。 Kaggle上還有另一個可用的數據集( https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system? ),可以嘗試一下。
Interested in learning and working with Python language, Machine Learning, Data science, even Robotics. Then probably you would be interested in my blog where I am talking about various programming topics and provide links to textbooks and guides I’ve found interesting.
對學習和使用Python語言,機器學習,數據科學甚至機器人技術感興趣。 然后,您可能會對 我 在 博客 中談論各種編程主題并提供指向我發現很有趣的教科書和指南的鏈接感興趣。
Please check out the Instagram page for updates https://www.instagram.com/rudraalabs/. As always, feel free to send us any questions or feedback you might have.
請查看 Instagram 頁面以獲取更新 https://www.instagram.com/rudraalabs/ 。 與往常一樣,隨時向我們發送您可能有的任何問題或反饋。
Thank you for reading the blog.
感謝您閱讀博客。
翻譯自: https://medium.com/swlh/recommendation-system-implementation-with-deep-learning-and-pytorch-a03ee84a96f4
pytorch深度學習
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/390965.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/390965.shtml 英文地址,請注明出處:http://en.pswp.cn/news/390965.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

什么是JavaScript中的回調函數?

Java 集合-集合介紹
;)
為什么Java不允許super.super.method();
)
Exchange 2016部署實施案例篇-04.Ex基礎配置篇(下)

數據庫課程設計結論_結論:

JavaScript數據類型:Typeof解釋

asp.net讀取用戶控件,自定義加載用戶控件

配置Java_Home,臨時環境變量信息

網頁縮放與窗口縮放_功能縮放—不同的Scikit-Learn縮放器的效果:深入研究

在構造器里調用可重寫的方法有什么問題?

創建hugo博客_如何創建您的第一個Hugo博客:實用指南

Python自動化開發01

記錄關于vs2008 和vs2015 的報錯問題

未越獄設備提取數據_從三星設備中提取健康數據

怎么樣用System.out.println在控制臺打印出顏色

sql注入語句示例大全_SQL Order By語句:示例語法
![[BZOJ2599][IOI2011]Race 點分治](http://pic.xiahunao.cn/[BZOJ2599][IOI2011]Race 點分治)
[BZOJ2599][IOI2011]Race 點分治

分詞消除歧義_角色標題消除歧義

北航教授李波:說AI會有低潮就是胡扯,這是人類長期的追求
