決策樹信息熵計算
A decision tree is a very important supervised learning technique. It is basically a classification problem. It is a tree-shaped diagram that is used to represent the course of action. It contains the nodes and leaf nodes. it uses these nodes and leaf nodes to draw the conclusion. Here we are going to talk about the entropy in the decision tree. Let’s have a look at what we are going to learn about the decision tree entropy.
決策樹是一種非常重要的監督學習技術。 這基本上是一個分類問題。 它是一個樹形圖,用于表示操作過程。 它包含節點和葉節點。 它使用這些節點和葉節點來得出結論。 在這里,我們將討論決策樹中的熵。 讓我們看一下我們將要學習的有關決策樹熵的知識。
- What is Entropy? 什么是熵?
- Importance of entropy. 熵的重要性。
- How to calculate entropy? 如何計算熵?
什么是熵? (What is Entropy?)
So let’s start with the definition of entropy. What is this entropy?
因此,讓我們從熵的定義開始。 這是什么熵?
“The entropy of a decision tree measures the purity of the splits.”
“決策樹的熵衡量了拆分的純度。”
Now let us understand the theory of this one-line definition. Let’s suppose that we have some attributes or features. Now between these features, you have to decides that which features you should use as the main node that is a parent node to start splitting your data. So for deciding which features you should use to split your tree we use the concept called entropy.
現在讓我們了解這一單行定義的理論。 假設我們有一些屬性或功能。 現在,在這些功能之間,您必須確定應使用哪些功能作為開始分裂數據的父節點的主節點。 因此,為了確定應使用哪些功能來分割樹,我們使用了稱為熵的概念。
熵的重要性 (Importance of Entropy)
- It measures the impurity and disorder. 它測量雜質和無序。
- It is very helpful in decision tree to make decisions. 在決策樹中進行決策非常有幫助。
- It helps to predict, which node is to split first on the basis of entropy values. 它有助于根據熵值預測哪個節點首先分裂。
如何計算熵? (How to calculate Entropy?)
Let’s first look at the formulas for calculating Entropy.
首先讓我們看一下計算熵的公式。
Here, p is the Probability of positive class and q is the Probability of negative class.
在此,p是肯定類別的概率, q是否定類別的概率。
Now low let’s understand this formula with the help of an example. consider some features. Let’s say E1, E2, E3 are some features. we need to make a tree using one of the appropriate features as the parent node. let’s suppose that E2 is the parent node and E1, E3 are leaf node. Now when we construct a decision tree by considering E2 as parent node then it will look like as shown below.
現在低點,讓我們借助示例來了解此公式。 考慮一些功能。 假設E1,E2,E3是一些功能。 我們需要使用適當的特征之一作為父節點來制作樹。 假設E2是父節點,而E1,E3是葉節點。 現在,當我們通過將E2作為父節點來構建決策樹時,其外觀將如下所示。
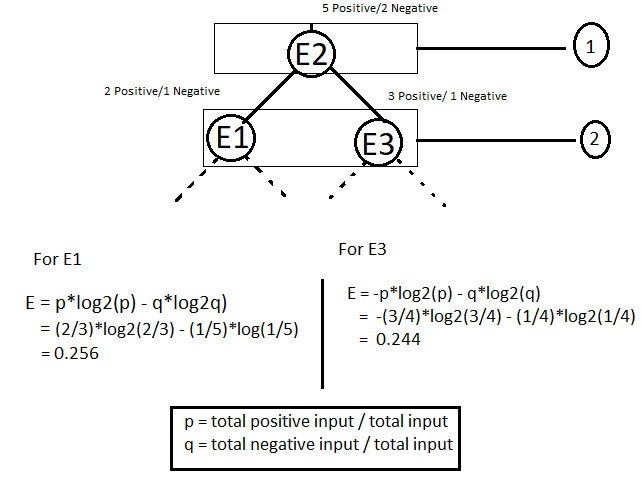
I have considered the E2 as a parent node which has 5 positive input and 2 negatives input. The E2 has been split into two leaf nodes (step 2). After the spilt, the data has divided in such a way that E1 contains 2 positive and1 negative and E3 contains 3 positive and 1 negative. Now in the next step, the entropy has been calculated for both the leaf E1 and E2 in order to find out that which one is to consider for next split. The node which has higher entropy value will be considered for the next split. The dashed line shows the further splits, meaning that the tree can be split with more leaf nodes.
我已經將E2視為具有5個正輸入和2個負輸入的父節點。 E2已被拆分為兩個葉節點(步驟2)。 進行拆分后,數據以E1包含2個正值和1個負值以及E3包含3個正值和1個負值的方式進行了劃分。 現在,在下一步中,已經為葉E1和E2都計算了熵,以找出下一步要考慮的熵。 具有較高熵值的節點將被考慮用于下一個分割。 虛線顯示了進一步的拆分,這意味著可以用更多的葉節點拆分樹。
N
?
NOTE 2: The value of entropy is always between 0 to 1.
注2:熵值始終在0到1之間。
So this was all about with respect to one node only. You should also know that for further splitting we required some more attribute to reach the leaf node. For this, there is a new concept called information gain.
因此,這僅涉及一個節點。 您還應該知道,為了進一步拆分,我們需要更多屬性才能到達葉節點。 為此,有一個稱為信息增益的新概念。
Worst Case:- If you are getting 50% of data as positive and 50% of the data as negative after the splitting, in that case the entropy value will be 1 and that will be considered as the worst case.
最壞的情況:-如果拆分后獲得50%的數據為正,而50%的數據為負,則熵值將為1,這將被視為最壞情況。
If you like this post then please drop the comments and also share this post.
如果您喜歡此帖子,請刪除評論并分享此帖子。
翻譯自: https://medium.com/swlh/decision-tree-entropy-entropy-calculation-7bdd394d4214
決策樹信息熵計算
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388617.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388617.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388617.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

多虧了這篇文章,我的開發效率遠遠領先于我的同事

Free SQLSever 2008的書

流式數據分析_流式大數據分析

oracle failover 區別,Oracle DG failover 實戰

Jenkins自動化CI CD流水線之8--流水線自動化發布Java項目

oracle數據泵導入很慢,impdp導入效率的問題
)
BZOJ2597 WC2007剪刀石頭布(費用流)

數據科學還是計算機科學_數據科學101
)
開機流程與主引導分區(MBR)

膚色檢測算法 - 基于二次多項式混合模型的膚色檢測。

oracle解析儒略日,利用to_char獲取當前日期準確的周數!


js有默認參數的函數加參數_函數參數:默認,關鍵字和任意


oracle raise_application_error,RAISE_ APPLICATION_ ERROR--之異常處理


2018大數據學習路線從入門到精通

相似鄰里算法_紐約市-鄰里之戰

![[poj 1364]King[差分約束詳解(續篇)][超級源點][SPFA][Bellman-Ford]](http://pic.xiahunao.cn/[poj 1364]King[差分約束詳解(續篇)][超級源點][SPFA][Bellman-Ford])