Once in a while, when reading papers in the Reinforcement Learning domain, you may stumble across mysterious-sounding phrases such as ‘we deal with a filtered probability space’, ‘the expected value is conditional on a filtration’ or ‘the decision-making policy is ??-measurable’. Without formal training in measure theory [2,3], it may be difficult to grasp what exactly such a filtration entails. Formal definitions look something like this:
有時,在閱讀強化學習領域的論文時,您可能會偶然發現一些聽起來很神秘的短語,例如“我們處理過濾后的概率空間” ,“ 期望值取決于過濾條件 ”或“ 決策政策是“可 衡量的 ”。 沒有對度量理論的正式訓練[2,3],可能很難掌握這種過濾到底需要什么。 正式定義看起來像這樣:

Boilerplate language for those familiar with measure theory, no doubt, but hardly helpful otherwise. Googling for answers likely leads through a maze of σ-algebras, Borel sets, Lebesgue measures and Hausdorff spaces, again presuming that one already knows the basics. Fortunately, only a very basic understanding of a filtration is needed to grasp its implications within the RL domain. This article will provide far from a full discussion on the topic, but aims to give a brief and (hopefully) intuitive outline of the core concept.
毫無疑問,對于那些熟悉度量理論的人來說,這些樣板語言非常有用,但對于其他方面幾乎沒有幫助。 谷歌搜索答案可能是通過σ-代數,Borel集,Lebesgue測度和Hausdorff空間的迷宮而導致的,再次假設人們已經知道基礎知識。 幸運的是,只需要對過濾有一個非常基本的了解即可掌握其在RL域中的含義。 本文將不提供有關該主題的完整討論,而旨在給出核心概念的簡短(希望)直觀概述。
An example
一個例子
In RL, we typically define an outcome space Ω that contains all possible outcomes or samples that may occur, with ω being a specific sample path. For the sake of illustration, we will assume that our RL problem relates to a stock with price S? at day t . Of course we’d like to buy low and sell high (the precise decision-making problem is irrelevant here). We might denote the buying/selling decision as x?(ω), i.e., the decision is conditional on the price path. We start with price S? (a real number) and every day the price goes up or down according to some random process. We may simulate (or mathematically define) such a price path ω=[ω?,…,ω?] up front, before running the episode. However, that does not mean we should know stock price movements before they actually happen — even Warren Buffett could only dream of having such information! To claim we base our decisions on ω without being a clairvoyant, we may state the outcome space is ‘filtered’ (using the symbol ? ) meaning we can only observe the sample up to time t.
在RL中,我們通常定義一個結果空間Ω ,其中包含所有可能的結果或可能發生的樣本,其中ω是特定的樣本路徑。 為了便于說明,我們假設RL問題與在t天價格為S a的股票有關。 當然,我們想買低賣高(確切的決策問題在這里無關緊要)。 我們可以將買賣決策表示為x?(ω) , 即,決定取決于價格路徑。 我們從價格S? (一個實數)開始,然后每天價格都會根據某種隨機過程上升或下降。 在運行情節之前,我們可以預先模擬(或數學定義)這樣的價格路徑ω= [ω?,…,ω?] 。 但是,這并不意味著我們不應該在股價實際發生之前就知道它們的波動-甚至沃倫·巴菲特也只能夢想擁有這樣的信息! 為了聲明我們的決定基于ω而并非千篇一律 ,我們可以聲明結果空間已被“過濾”(使用符號?),這意味著我們只能觀察到時間t之前的樣本。
For most RL practitioners, this restriction must sound familiar. Don’t we usually base our decisions on the current state S?? Indeed, we do. In fact, as the Markov property implies that the stochastic process is memoryless — we only need the information embedded in the prevailing state S? — information from the past is irrelevant [5]. As we will shortly see, the filtration is richer and more generic than a state, yet for practical purposes their implications are similar.
對于大多數RL從業者來說,此限制必須聽起來很熟悉。 我們通常不是根據當前狀態S?做出決定嗎? 確實,我們做到了。 實際上,正如馬爾可夫性質所暗示的那樣,隨機過程是無記憶的-我們只需要嵌入盛行狀態S?中的信息-過去的信息就無關緊要[5]。 我們將很快看到,過濾比狀態更豐富,更通用,但是出于實際目的,它們的含義是相似的。
Let’s formalize our stock price problem a bit more. We start with a discrete problem setting, in which the price either goes up (u) or down (-d). Considering an episode horizon of three days, the outcome space Ω may be visualized by a binomial lattice [4]:
讓我們進一步規范一下股價問題。 我們從一個離散的問題設置開始,在該問題中,價格上漲( u )或下跌( -d )。 考慮到三天的發作期,結果空間Ω可以通過二項式格子[4]可視化:
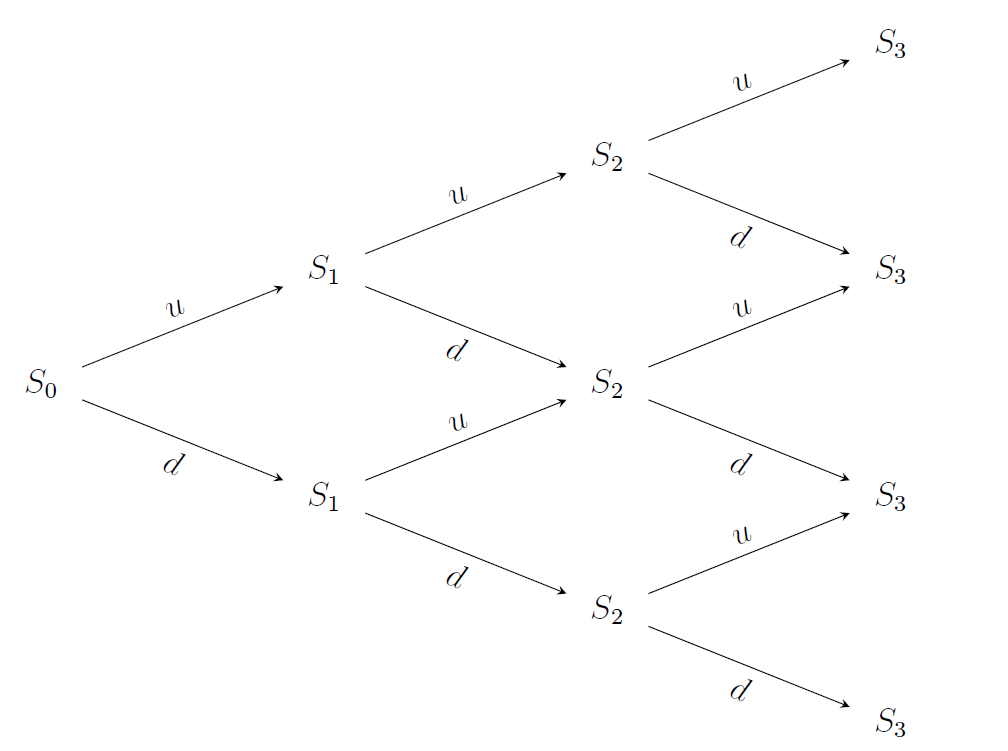
Definition of events and filtrations
事件和過濾的定義
At this point, we need to define the notion of an `event’ A ∈ Ω. Perhaps stated somewhat abstractly, an event is an element of the outcome space. Simply put, we can assign a probability to an event and assert whether it has happened or not. As we will soon show, it is not the same as a realization ω though.
此時,我們需要定義“事件” A∈Ω的概念。 一個事件可能是結果空間的一個元素,也許有些抽象地表述。 簡而言之,我們可以為事件分配概率并斷言事件是否發生。 正如我們將很快證明的那樣,它與實現ω不同 。
A filtration ? is a mathematical model that represents partial knowledge about the outcome. In essence, it tells us whether an event happened or not. The `filtration process’ may be visualized as a sequence of filters, with each filter providing us a more detailed view . Concretely, in an RL context the filtration provides us with the information needed to compute the current state S?, without giving any indication of future changes in the process [2]. Indeed, just like the Markov property.
過濾?是一個數學模型,代表關于結果的部分知識。 從本質上講,它告訴我們事件是否發生。 “過濾過程”可以可視化為一系列過濾器,每個過濾器為我們提供更詳細的視圖。 具體而言,在RL上下文中,過濾為我們提供了計算當前狀態S?所需的信息,而沒有提供任何對過程未來變化的指示[2]。 確實,就像馬爾可夫財產一樣。
Formally, a filtration is a σ-algebra, and although you don’t need to know the ins and outs some background is useful. Loosely defined, a σ-algebra is a collection of subsets of the outcome space, containing a countable number of events as well as all their complements and unions. In measure theory this concept has major implications, for the purpose of this article you only need to remember that the σ-algebra is a collection of events.
形式上,過濾是一個σ-代數,盡管您不需要了解來龍去脈,但有些背景是有用的。 松散定義的σ-代數是結果空間子集的集合,其中包含可數的事件以及它們的所有互補和并集。 在量度理論中,此概念具有重要意義,對于本文而言,您只需要記住σ-代數是事件的集合。
Example revisited — discrete case
再看示例-離散情況
Back to the example, because the filtration only comes alive when seeing it into action. We first need to define the events, using sequences such as ‘udu’ to describe price movements over time. At t=0 we basically don’t know anything — all paths are still possible. Thus, the event set A={uuu, uud, udu, udd, ddd, ddu, dud, duu} contains all possible paths ω ∈ Ω. At t=1, we know a little more: the stock price went either up or down. The corresponding events are defined by A?={uuu,uud,udu,udd} and A?={ddd,ddu,dud,duu}. If the stock price went up, we can surmise that our sample path ω will be in A? and not in A? (and vice versa, of course). At t=2, we have four event sets: A??={uuu,uud}, A??={udu,udd}, A??={duu,dud}, and A??={ddu,ddd}. Observe that the information is getting increasingly fine-grained; the sets to which ω might belong are becoming smaller and more numerous. At t=3, we obviously know the exact price path that has been followed.
回到示例,因為過濾只有在生效時才會生效。 我們首先需要定義事件,使用諸如“ udu”之類的序列來描述價格隨時間的變化。 在t = 0時,我們基本上什么都不知道-所有路徑仍然可行。 因此,事件集A = {uuu,uud,udu,udd,ddd,ddu,dud,duu}包含所有可能的路徑ω∈Ω 。 在t = 1時 ,我們知道的更多:股票價格上漲或下跌。 相應的事件由A?= { u uu, u ud, u du, u dd}和A?= { d dd, d du, d ud, d uu}定義 。 如果股價上漲,我們可以推測樣本路徑ω將在A?中 ,而不在A?中 (當然,反之亦然)。 在t = 2時 ,我們有四個事件集: A??= {uuu,uud} , A??= { ud u, ud d} , A??= { du u, du d}和A??= { dd u, dd d} 。 觀察到信息越來越細化; ω可能屬于的集合越來越小。 在t = 3時 ,我們顯然知道遵循的確切價格路徑。
Having defined the events, we can define the corresponding filtrations for t=0,1,2,3:
定義事件后,我們可以為t = 0,1,2,3定義相應的過濾:

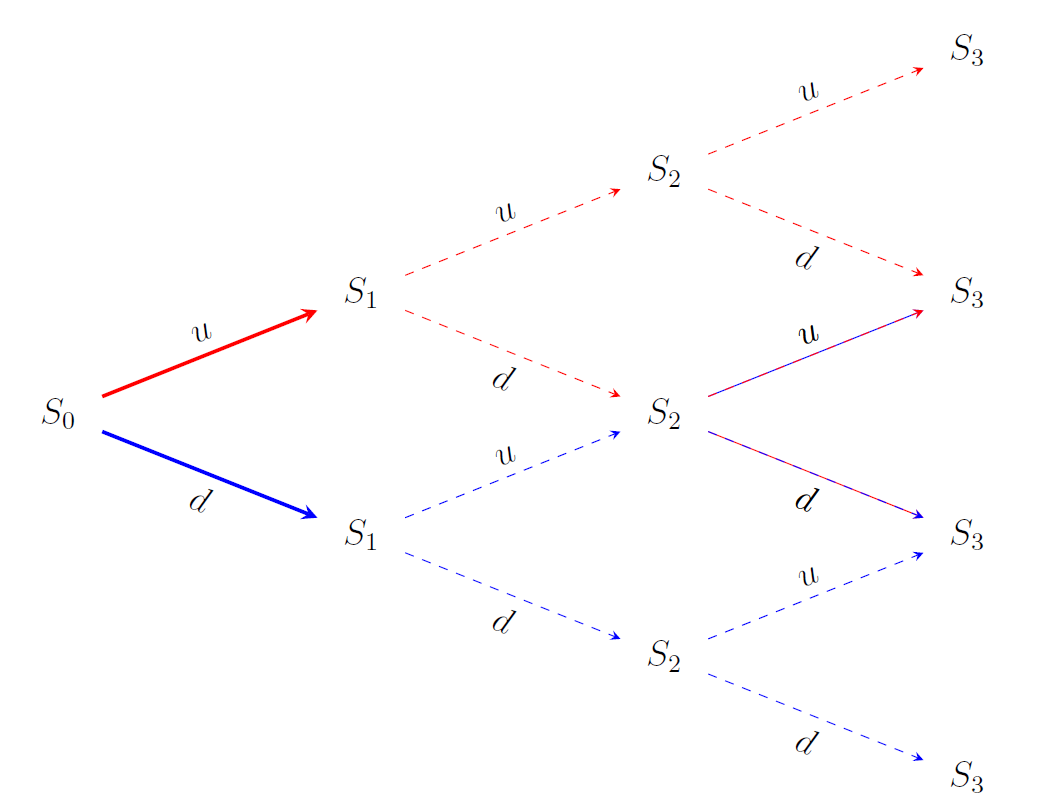
At t=0, every outcome is possible. We initialize the filtration with the empty set ? and outcome space Ω, also known as a trivial σ-algebra.
在t = 0時 ,所有結果都是可能的。 我們用空集?和結果空間Ω(也稱為平凡 σ-代數)初始化過濾。
At t=1, we can simply add A? and A? to ?? to obtain ??; recall from the definition that each filtration always includes all elements of its predecessor. We can use the freshly revealed information to compute S?. We also get a peek into the future (without actually revealing future information!): if the price went up, we cannot reach the lowest possible price at t=3 anymore. The event sets are illustrated below
在t = 1時 ,我們可以簡單地將A?和A?加到?以獲得obtain 。 從定義中回想起,每次過濾總是包含其前身的所有元素。 我們可以使用最新顯示的信息來計算S? 。 我們還會窺視未來(實際上并不會透露未來的信息!):如果價格上漲,我們將無法再達到t = 3時的最低價格。 事件集如下所示
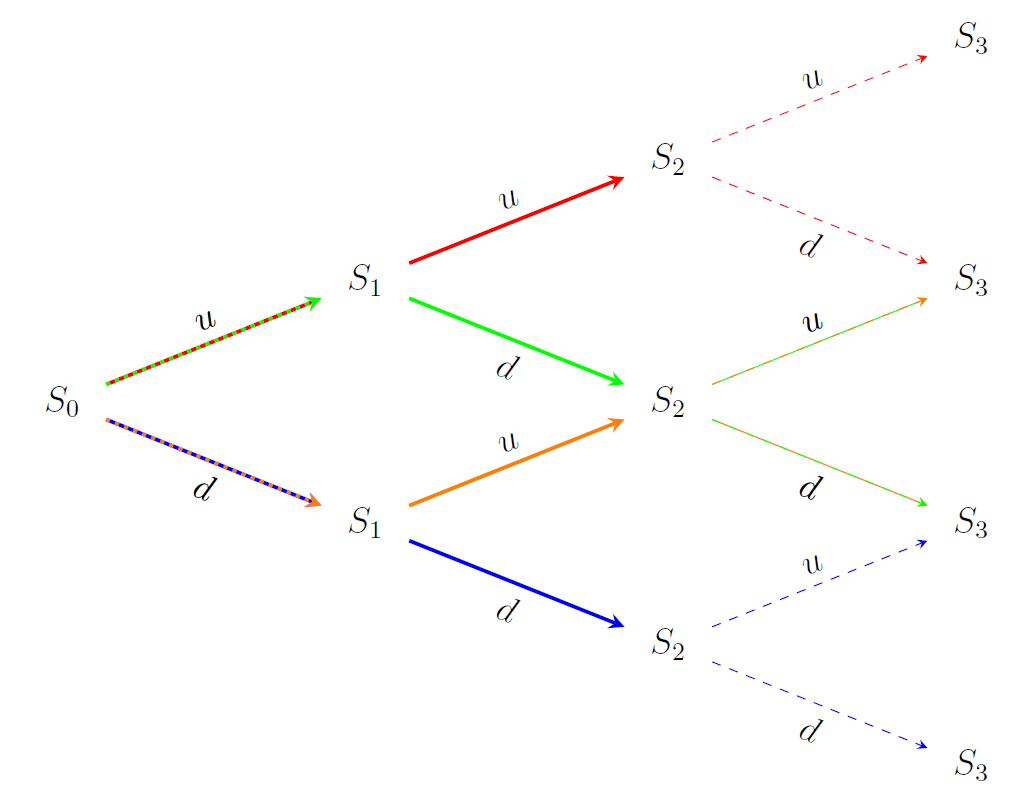
At t=2, we may distinguish between four events depending on the price paths revealed so far. Here things get a bit more involved, as we also need to add the unions and complements (in line with the requirements of the σ-algebra). This was not necessary for ??, as the union of A? and A? equals the outcome space and A? is the complement of A?. From an RL perspective, you might note that we have more information than strictly needed. For instance, an up-movement followed by a down-movement yields the same price as the reverse. In RL applications we would typically not store such redundant information, yet you can probably recognize the mathematical appeal.
在t = 2時 ,我們可以根據到目前為止揭示的價格路徑來區分四個事件。 這里的事情涉及更多,因為我們還需要添加并集和補碼(符合σ-代數的要求)。 ??不需要 ,因為A necessary和A?的并集等于結果空間,而A?是A?的補碼 。 從RL角度來看,您可能會注意到,我們掌握的信息超出了嚴格需要的信息。 例如,向上運動然后向下運動會產生與反向運動相同的價格。 在RL應用程序中,我們通常不會存儲此類冗余信息,但您可能會認識到數學上的吸引力。
At t=3, we already have 256 sets, using the same procedure as before. You can see that filtrations quickly become extremely large. A filtration always contains all elements of the preceding step — our filtration gets richer and more fine-grained with the passing of time. All this means is that we can more precisely pinpoint the events to which our sample price path may or may not belong.
在t = 3處 ,我們已經有256套,使用與以前相同的過程。 您會看到過濾很快變得非常大。 過濾始終包含上一步的所有元素-隨著時間的流逝,我們的過濾會變得越來越豐富,而且粒度越來越細。 這一切意味著我們可以更精確地查明樣本價格路徑可能或可能不屬于的事件。
A continuous example
一個連續的例子
We are almost there, but we would be remiss if we only treat discrete problems. In reality, stock prices do not only go ‘up’ or ‘down’; they will change within a continuous domain. The same holds for many other RL problems. Although conceptually the same as for the discrete case, providing explicit descriptions for filtrations in continuous settings is difficult. Again, some illustrations might help more than formal definitions.
我們快到了,但是如果我們只處理離散的問題,我們將被解雇。 實際上,股票價格不僅會上漲或下跌。 他們將在一個連續的領域內變化。 許多其他RL問題也是如此。 盡管從概念上講與離散情況相同,但是很難提供連續設置中過濾的明確描述。 同樣,一些插圖可能比正式定義更有幫助。
Suppose that at every time step, we simulate a return from the real domain [-d,u]. Depending on the time we look ahead, we may then define an interval in which the future stock price will fall, say [329,335] at a given point in time. We can then define intervals within this domain. Any arbitrary interval may constitute an event, for instance:
假設在每個時間步上,我們都模擬來自實域[-d,u]的收益。 根據我們的展望時間,我們可以定義一個時間間隔,即在給定的時間點,未來股價將下跌,例如[329,335] 。 然后,我們可以在此域內定義間隔。 任何任意間隔都可能構成一個事件,例如:
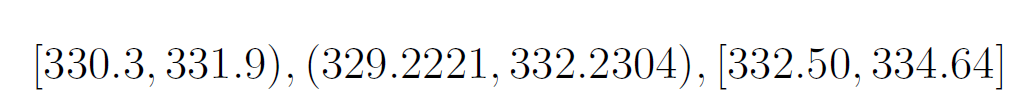
The complement of an interval could look like
間隔的補碼可能看起來像
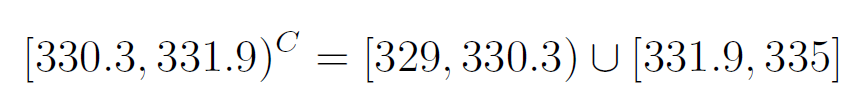
Furthermore, a plethora of unions may be defined, such as
此外,可以定義過多的聯合,例如
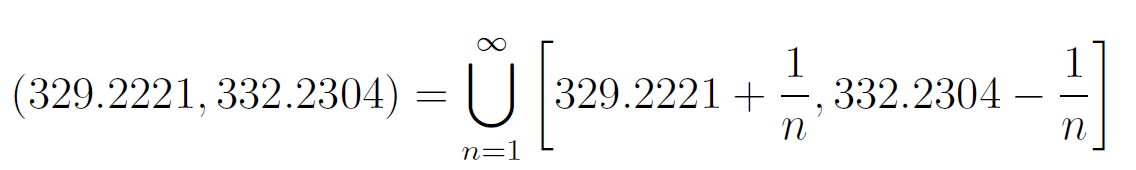
As you may have guessed, there are infinitely many of such events in all shapes and sizes, yet they are still countable and we can assign a probability to each of them [2,3].
正如您可能已經猜到的那樣,各種形狀和大小的事件有無數種,但它們仍然是可數的,我們可以為每個事件分配一個概率[2,3]。
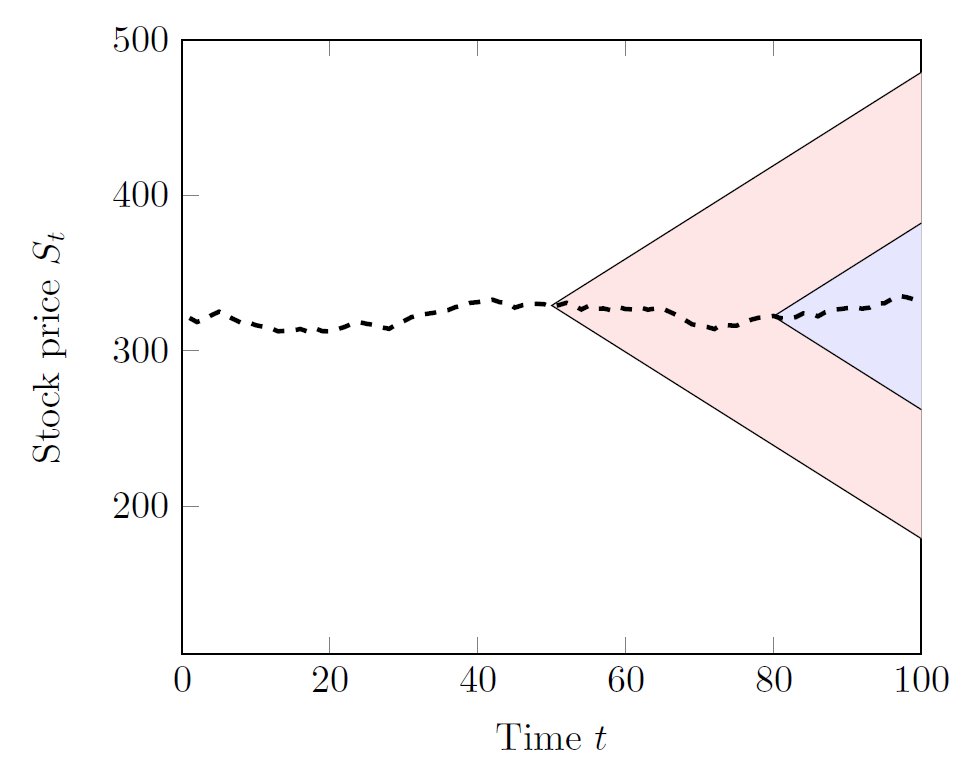
The further we look into the future, the more we can deviate from our current stock price. We might visualize this with a cone shape that expands over time (displayed below for t=50 and t=80). Within the cone, we can define infinitely many intervals. As before, we acquire a more detailed view once more time has passed.
我們對未來的展望越深,與當前股價的偏差就越大。 我們可以用隨時間擴展的圓錐形形象化(在下面顯示t = 50和t = 80 )。 在圓錐內,我們可以定義無限多個間隔。 和以前一樣,一旦時間過去,我們將獲得更詳細的視圖。
Wrapping things up
整理東西
When encountering filtrations in any RL paper, the basics treated in this article should suffice. Essentially, the only purpose of introducing filtrations ?? is to ensure that decisions x?(ω) do not utilize information that has not yet been revealed. When the Markov property holds, a decision x?(S?) that operates on the current state serves the same purpose. The filtration provides a rich description of the past, yet we do not need this information in memoryless problems. Nevertheless, from a mathematical perspective it is an elegant solution with many interesting applications. The reinforcement learning community consists of many researchers and engineers from different backgrounds working in a variety of domains, not everyone speaks the same language. Sometimes it goes a long way to learn another language, even if only a few words.
當在任何RL紙中遇到過濾時,本文所處理的基本知識就足夠了。 從本質上講,引入的過濾??的唯一目的是確保決策x?(ω)不利用還未被透露的信息。 當馬爾可夫屬性成立時,在當前狀態下運行的決策x?(S?)具有相同的目的。 篩選提供了對過去的豐富描述,但是在無記憶問題中我們不需要此信息。 但是,從數學角度來看,它是一種優雅的解決方案,具有許多有趣的應用程序。 強化學習社區由來自不同背景的許多研究人員和工程師組成,這些研究人員和工程師在不同的領域工作,并不是每個人都講相同的語言。 有時候,即使只有幾個單詞,學習另一種語言也會走很長的路。
[This article is partially based on my ArXiv article ‘A Gentle Lecture Note on Filtrations in Reinforcement Learning’]
[本文部分基于我的ArXiv文章“關于強化學習中的過濾的溫和講義”]
[1] Van Heeswijk, W.J.A. (2020). A Gentle Lecture Note on Filtrations in Reinforcement Learning. arXiv preprint arXiv:2008.02622
[1] Van Heeswijk,WJA(2020)。 關于強化學習中的過濾的溫和的講義。 arXiv預印本arXiv:2008.02622
[2] Shreve, S. E. (2004). Stochastic Calculus for Finance II: Continuous-Time Models, Volume 11. Springer Science & Business Media.
[2] Shreve,SE(2004)。 金融隨機算術II:連續時間模型,第11卷。Springer科學與商業媒體。
[3] Shiryaev, A. N. (1996). Probability. Springer New York-Heidelberg.
[3] Shiryaev,AN(1996)。 可能性。 施普林格紐約-海德堡。
[4] Luenberger, D. G. (1997). Investment Science. Oxford University Press.
[4] Luenberger,DG(1997)。 投資科學。 牛津大學出版社。
[5] Powell, W. B. (2020). On State Variables, Bandit Problems and POMDPs. arXiv preprint arXiv:2002.06238
[5]鮑威爾,世界銀行(2020)。 關于狀態變量,強盜問題和POMDP。 arXiv預印本arXiv:2002.06238
翻譯自: https://towardsdatascience.com/filtrations-in-reinforcement-learning-what-they-are-and-why-we-dont-need-them-463c93a170d4
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388500.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388500.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388500.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

LoadRunner8.1破解漢化過程
)
TCP/IP網絡編程之基于TCP的服務端/客戶端(二)

談談iOS獲取調用鏈

python 移動平均線_Python中的移動平均線

Ireport制作過程
)
2018.09.16 loj#10243. 移棋子游戲(博弈論)

html5字體的格式轉換,font字體

紅星美凱龍牽手新潮傳媒搶奪社區消費市場

機器學習 啤酒數據集_啤酒數據集上的神經網絡

實例演示oracle注入獲取cmdshell的全過程

html視頻位置控制器,html5中返回音視頻的當前媒體控制器的屬性controller

ER TO SQL語句

dede 5.7 任意用戶重置密碼前臺

nasa數據庫cm1數據集_獲取下一個地理項目的NASA數據

注入代碼oracle

html5包含inc文件,HTML中include file標簽的用法

r語言處理數據集編碼_在強調編碼語言或工具之前,請學習這3個基本數據概念
服務的注冊與發現(Eureka))
springboot微服務 java b2b2c電子商務系統(一)服務的注冊與發現(Eureka)

linux部署服務器常用命令
