lambda函數,函數符
兩個Lambda用戶的故事 (A Tale of Two Lambda Users)
故事1:業余 (Tale #1: The Amateur)
One moment everything is fine, then … Bam! Your Lambda function raises an exception, you get alerted and everything changes instantly.
一會兒一切都好,然后……Bam! 您的Lambda函數引發異常,您將收到警報,并且所有內容都會立即更改。
Critical systems could be impacted, so it’s important that you understand the root cause quickly.
關鍵系統可能會受到影響,因此快速了解根本原因非常重要。
Now, this isn’t some low-volume Lambda where you can scroll through CloudWatch Logs and find the error in purely manual fashion. So instead you head to CloudWatch Insights to run a query on the log group, filtering for the error:
現在,這不是小批量的Lambda,您可以在其中滾動瀏覽CloudWatch Logs并以純手工方式查找錯誤。 因此,您轉而使用CloudWatch Insights在日志組上運行查詢,以過濾錯誤:
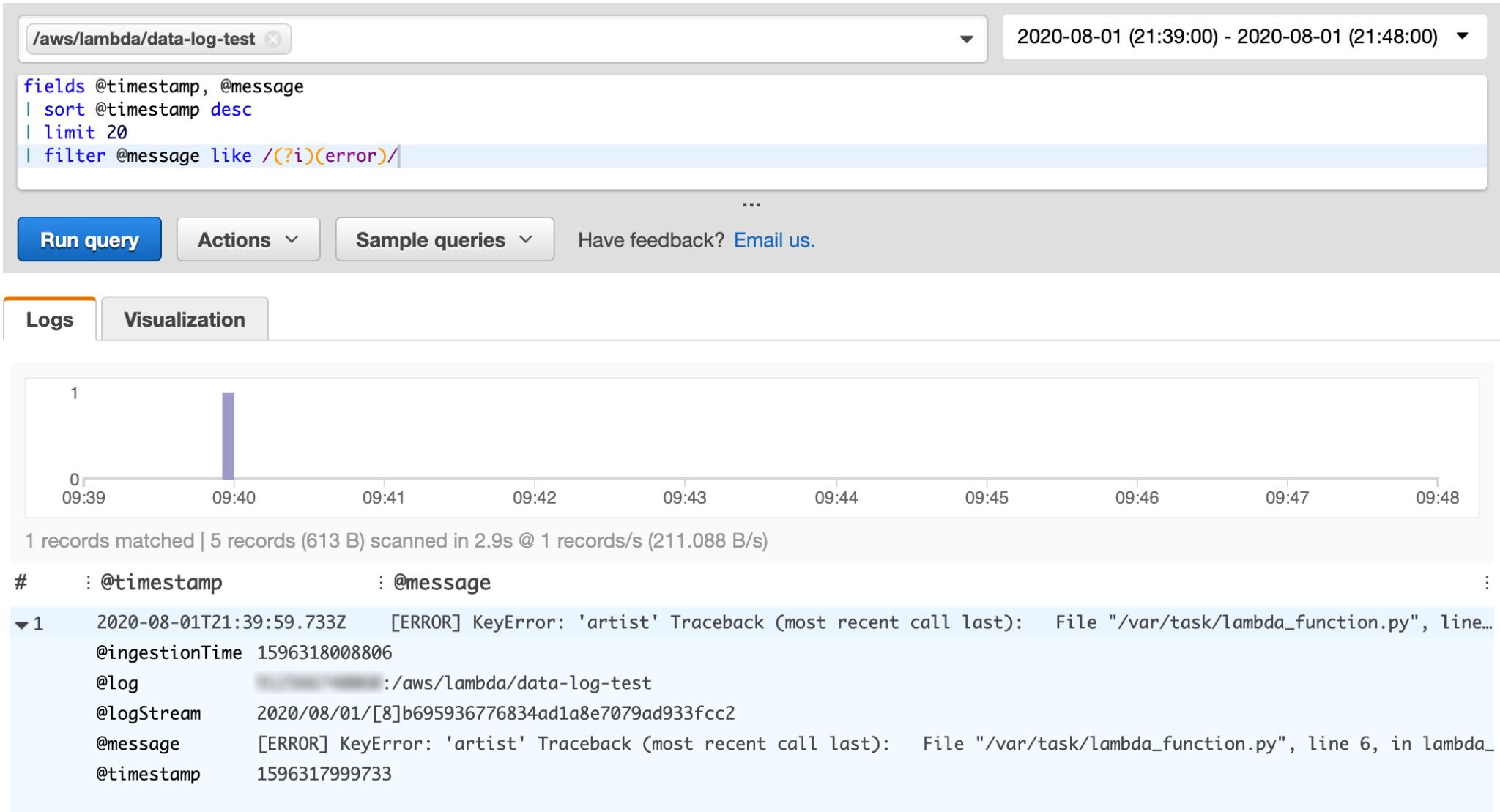
Looks like we found our error! While helpful, unfortunately it omits any other log messages associated with the failed invocation.
看起來我們發現了錯誤! 雖然有用,但不幸的是,它忽略了與失敗的調用相關的任何其他日志消息。
With just the information shown above maybe — just maybe — you can figure out what the root cause is. But more likely than not, you won’t be confident.
僅通過上面顯示的信息,也許-也許-您就可以找出根本原因了。 但是您很有可能不會自信。
Do you tell people you aren’t sure what happened and that you’ll spend more time investigating if the issue happens again? As if!
您是否告訴人們您不確定發生了什么,并且您將花費更多的時間調查問題是否再次發生? 仿佛!
So instead you head to the CloudWatch Logs Log Stream, filter records down to the relevant timestamp, and begin manually scrolling through log messages to find the full details on the specific errored invocation.
因此,您可以轉至CloudWatch Logs日志流,過濾記錄到相關時間戳,然后開始手動滾動日志消息以查找有關特定錯誤調用的完整詳細信息。
Resolution Time: 1–2 hoursLambda Enjoyment Usage Index: Low
解決時間: 1-2小時Lambda享受使用率指數:低
故事2:專業人士 (Tale #2: The Professional)
Same Lambda function, same error. But this time the logging and error handling are improved. As the title implies, this involves replacing print() statements with something a ‘lil better.
相同的Lambda函數,相同的錯誤。 但是這次日志和錯誤處理得到了改善。 顧名思義,這涉及用更好的東西代替print()語句。
What is that something and what does this Lambda function look like anyway? Let’s first go through what error debugging looks like for the professional, then take a look at code. Fair?
那是什么東西,這個Lambda函數到底是什么樣的? 讓我們首先了解一下專業人員的錯誤調試,然后看一下代碼。 公平?
Again, we start with an Insights query:
同樣,我們從一個Insights查詢開始:
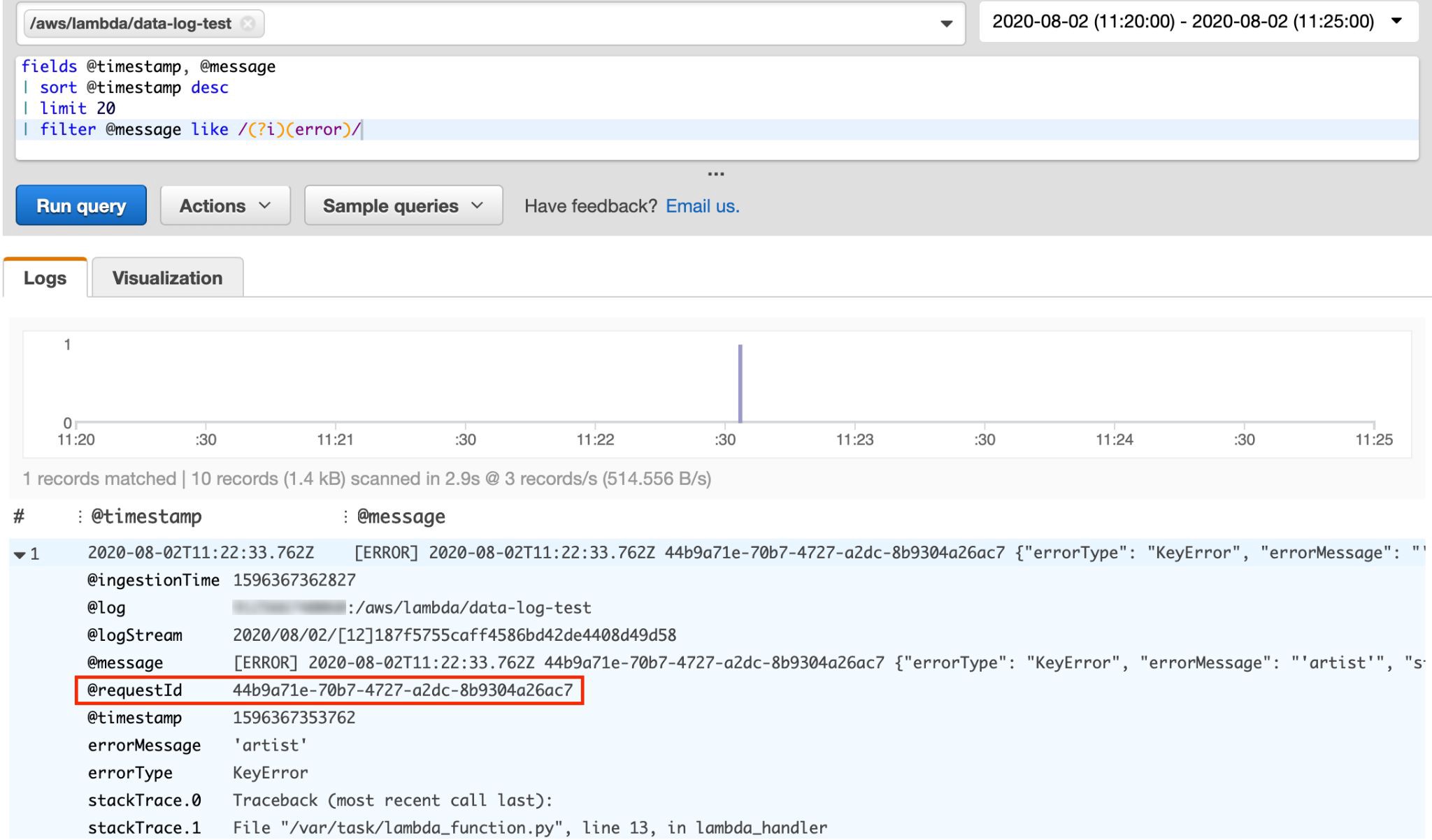
And again we find the error in the logs, but unlike last time, the log event now includes the @requestId from the Lambda invocation. What this allows us to do is run a second Insights query, filtered on that requestId to see the full set of logs for the exact invocation we are interested in!
我們再次在日志中找到錯誤,但是與上次不同,該日志事件現在包括來自Lambda調用的@requestId 。 這使我們能夠執行的是運行第二個Insights查詢,該查詢根據該requestId進行過濾,以查看我們感興趣的確切調用的完整日志集!
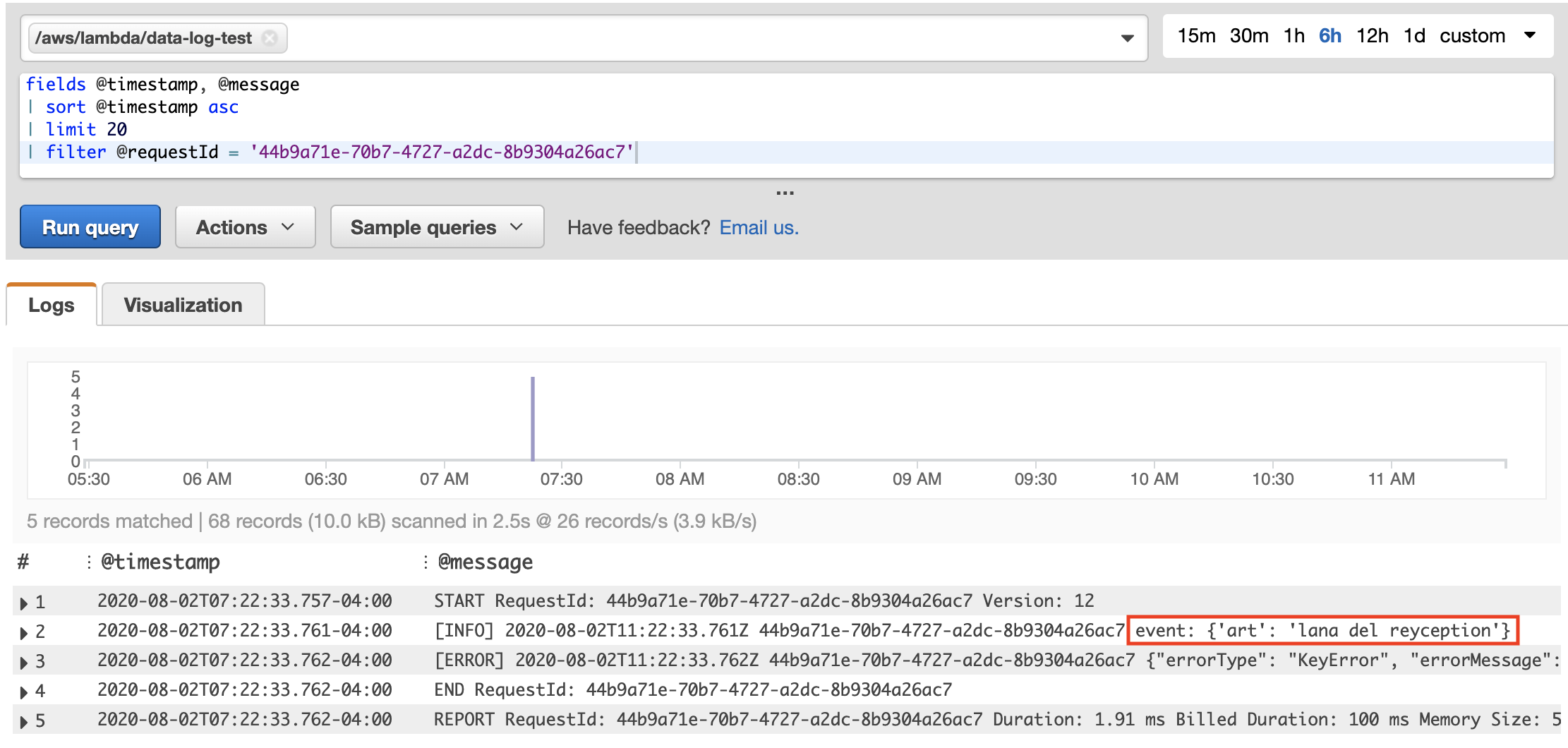
Now we get 5 results, which together paint the full crime scene picture of what happened for this request. Most helpfully, we immediately see the exact input passed to trigger the Lambda. From this we can either deduce what happened mentally, or run the Lambda code locally with the exact same input event to debug.
現在我們得到5個結果,這些結果共同描繪了此請求發生的全部犯罪現場圖片。 最有用的是,我們立即看到傳遞來觸發Lambda的確切輸入。 由此,我們可以推斷出發生的事情,或者使用完全相同的輸入事件在本地運行Lambda代碼進行調試。
Resolution Time: 10–20 minutesLambda Enjoyment Usage Index: High!
解決時間: 10–20分鐘Lambda享受使用率指數:高!
守則揭示 (The Code Reveal)
I’d like to imagine my readers are on the edge of their seats, begging to know the difference between the Amateur and the Pro’s code from the tale above.
我想想象我的讀者坐在座位上,乞求從上面的故事中了解Amateur和Pro的代碼之間的區別。
Whether that’s true or not, here is the Amateur Lambda:
不管是不是真的,這是Amateur Lambda:
It is, of course, intentionally simple for illustrative purposes. Errors were generated by simply passing an event dictionary without artist as a key, for example: event = {'artisans': 'Leonardo Da Vinci'}.
當然,出于說明目的,它是故意簡單的。 只需通過不帶artist作為關鍵字的事件字典即可生成錯誤,例如: event = {'artisans': 'Leonardo Da Vinci'} 。
Now for the Professional Lambda, which performs the same basic function but improves upon the print() statements and error handling.
現在是Professional Lambda,它執行相同的基本功能,但改進了print()語句和錯誤處理。
Interesting! So why are we using the logging module and formatting exception tracebacks?
有趣! 那么,為什么我們要使用日志記錄模塊并對異常回溯進行格式化?
可愛的Lambda記錄 (Lovely Lambda Logging)
First, the Lambda runtime environment for python includes a customized logger that is smart to take advantage of.
首先,適用于python的Lambda運行時環境包括一個自定義的記錄器 ,可以很好地利用它。
It features a formatter that, by default, includes the aws_request_id in every log message. This is the critical feature that allows for an Insights query, like the one shown above that filters on an individual @requestId, to show the full details of one Lambda invocation.
它具有一個格式化程序 ,默認情況下,每個日志消息中都包含aws_request_id 。 這是允許Insights查詢的關鍵功能,就像上面顯示的對單個@requestId過濾的顯示@requestId ,以顯示一個Lambda調用的完整詳細信息。
異常處理 (Exceptional Exception Handling)
Next, you are probably noticing the fancy error handling. Although intimidating looking, using sys.exec_info is the standard way to retrieve information about an exception in python.
接下來,您可能會注意到奇特的錯誤處理。 盡管令人生畏,但使用sys.exec_info是檢索有關python中異常的信息的標準方法 。
After retrieving the exception name, value, and stacktrace , we format it into a json-dumped string so all three appear in one log message, with the keys automatically parsed into fields. This also makes it easy to create custom metrics based off specific errors without requiring complex string parsing.
檢索到異常的名稱,值和stacktrace之后,我們將其格式化為json轉儲的字符串,以便所有三個都出現在一條日志消息中,并且鍵自動解析為字段。 這也使基于特定錯誤創建自定義指標變得容易,而無需復雜的字符串解析。
Lastly, it is worth noting that in contrast, logging an exception with the default Lambda logger without any formatting results in an unfortunate multi-line traceback looks something like this:
最后,值得注意的是,相比之下,使用默認的Lambda記錄器記錄異常而未進行任何格式化會導致不幸的多行回溯,如下所示:
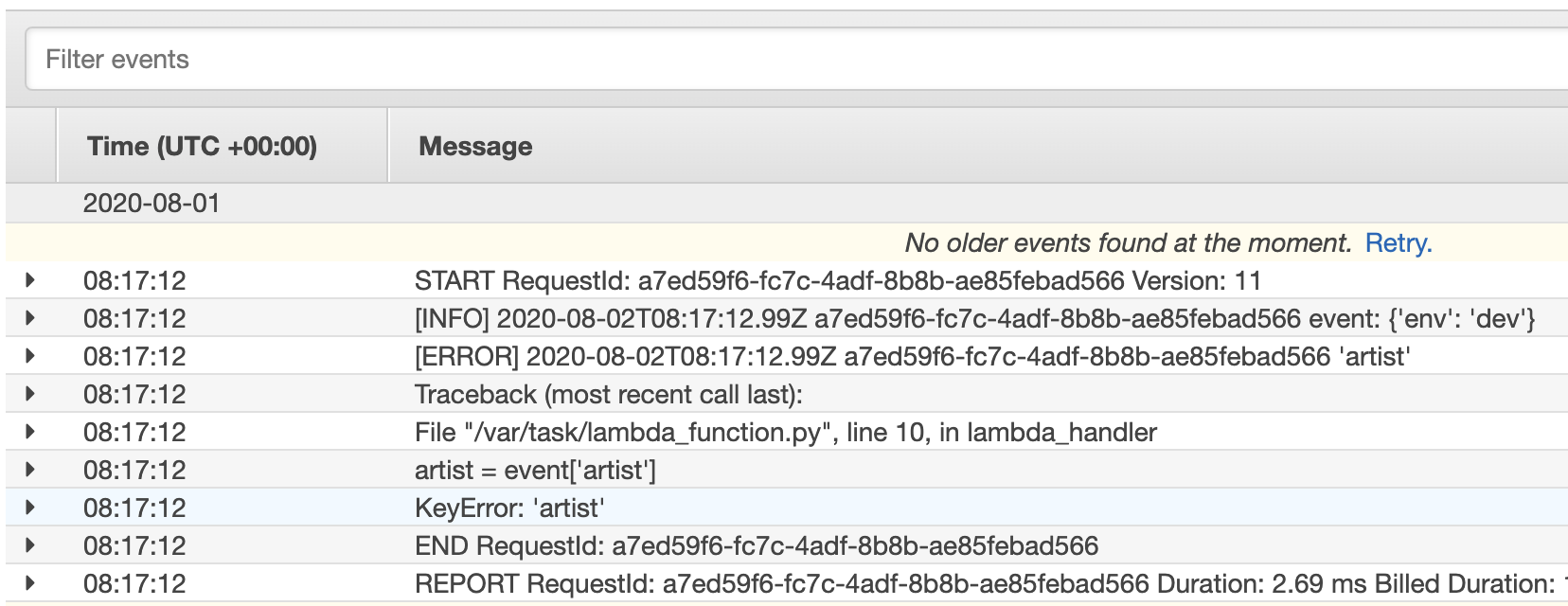
結語 (Wrapping Up)
I hope if your Lambda functions look more like the Amateur Lambda at the moment, this article inspires you to upgrade your dance and go Pro!
我希望目前您的Lambda函數看起來更像是業余Lambda,這篇文章可以激發您升級舞蹈并升級為Pro!
Before I let you go, I should warn that the downside to replacing print statements with proper logging is that you lose any terminal output generated from local executions of your Lambda.
在我放手之前,我應該警告說,用正確的日志記錄替換打印語句的弊端是,您會丟失Lambda的本地執行所生成的任何終端輸出。
There are clever ways around this involving either environment variables or some setup code in a lambda_invoke_local.py type of file. If interested, let me know and I’ll be happy to go over the details in a future article.
有許多解決方法,其中包括環境變量或lambda_invoke_local.py類型的文件中的某些設置代碼。 如果有興趣,請告訴我,我將很樂意在以后的文章中詳細介紹。
Lastly, as a final bit of inspiration, instead of needing to run Cloudwatch Insights queries to debug yourself, it should be possible to set up an Alarm against the Lambda Errors metric that notifies an SNS topic when in state “In Alarm”. Another Lambda could then trigger off that SNS topic to run the same debugging Insights queries as the Pro automatically, and return the relevant logs in Slack or something.
最后,作為最后的啟發,無需運行Cloudwatch Insights查詢來調試自己,應該可以針對Lambda錯誤度量標準設置警報,該警報在處于“ In Alarm”狀態時通知SNS主題。 然后,另一個Lambda可以觸發該SNS主題,以自動運行與Pro相同的調試Insights查詢,并以Slack或其他形式返回相關日志。
Would be cool, no?
會很酷,不是嗎?
翻譯自: https://towardsdatascience.com/why-you-should-never-ever-print-in-a-lambda-function-f997d684a705
lambda函數,函數符
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388304.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388304.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388304.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![[ BZOJ 4668 ] 冷戰](http://pic.xiahunao.cn/[ BZOJ 4668 ] 冷戰)
[ BZOJ 4668 ] 冷戰

使用容器和數據庫克隆進行數據庫遷移

C++獲取PE文件的入口點
)
ai 中 統計_AI統計(第2部分)

如何修改瀏覽器的默認滾動條樣式


python入門系列:對象引用、垃圾回收、可變性

twitter數據分析_Twitter上最受歡迎的數據科學文章主題
)
JAVA遇見HTML——JSP篇(JSP狀態管理)


easyui 布局之window和panel一起使用時,拉動window寬高時panel不跟隨一起變化

是什么使波西米亞狂想曲成為杰作-數據科學視角

PE文件感染和內存駐留

Python函數積累

流行編程語言_編程語言的流行度排名

Attributes.Add用途與用法

使用UIWebView加載網頁
)
Java 開源庫精選(持續更新)

corba的興衰_數據科學薪酬的興衰
