Python變量和數據類型
1 數據類型
計算機,顧名思義就是可以做數學計算的機器,因此,計算機程序理所當然也可以處理各種數值。
但是,計算機能處理的遠不止數值,還可以處理文本、圖形、音頻、視頻、網頁等各種各樣的數據,不同的數據需要定義不同的數據類型。
在Python中,能夠直接處理的數據類型有一下幾種:
(1)整數? ?十六進制用0x前綴0-9,a-f表示,如0xff00
(2)浮點數? 1.24 1.23e9? 1.2e-5
(3)字符串? 'abc'? "abc"
(4)布爾值? True False??? 可以用and、or、not進行運算? 短路運算
(5)空值? None
?
0、空字符串、None為false
其他數值、非空字符串為true
2 print語句
print可以向屏幕上輸出指定的文字。
>>> print 'hello, world'
用逗號隔開時,每個逗號輸出一個空格
>>> print 'The quick brown fox', 'jumps over', 'the lazy dog'
The quick brown fox jumps over the lazy dog
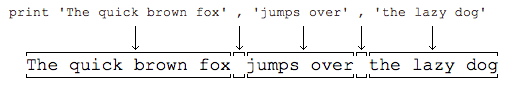
>>> print '100 + 200 = ', 100 + 200
100 + 200 = 300
?
3 注釋
一行之中,#之后的都為注釋
?
4 變量
變量用一個變量名表示,變量名必須是大小寫英文、數字和下劃線的組合,且不能用數字開頭。
等號=是賦值語句,可以把任意數據類型賦值給變量,同一個變量可以反復賦值,而且可以是不同類型的變量。
這種變量本身類型不固定的語言稱為動態語言,與之對應的是靜態語言。
靜態語言在定義變量時必須制定變量類型,如果賦值的時候類型不匹配,就會報錯,如java。
所以動態語言更加靈活。
?
變量在計算機內存中的表示:
a='ABC'? 計算機干了兩件事:
(1)在內存中創建了一個'ABC'的字符串;
(2)在內存中創建了一個名為a的變量,并把它指向'ABC'
?
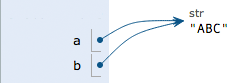
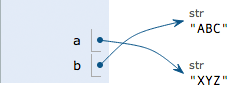
a='ABC'
b=a
a='XYZ'
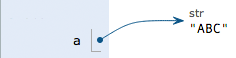
?
5 定義字符串
如果字符串本身包含引號,可以用另一種引號括起來:
"I'm OK"
'Learn "Python" in mooc'
如果既含單引號,又含雙引號,可用\進行轉義:
'Bob said\"I\'m OK\".'
常用轉義字符:
\n?換行
\t? 制表符
\\? 表示\本身
?
6 raw字符串與多行字符串
在字符串前面加個前綴r,表示這是一個raw字符串,里面字符無需轉義。
r'\(~~)/\(~~)/'
但是其不能表示多行字符串,也不能表示包含單引號和雙引號的字符串。
?
如果要表示多行字符串,用三引號:
'''Line1
Line2
Line3'''
等同于'Line1\nLine2\nLine3'
?
還可以在多行字符串前添加r,變成多行raw字符串。
r'''Python is created by "Guido".
It is free and easy to learn.'''
?
7 Unicode字符串
字符串還有一個編碼問題。
因為計算機智能處理數字,如果要處理文本,就必須把文本轉換為數字才能處理。
最早的計算機在設計時采用8個比特(bit)作為一個字節(byte),所以,一個字節能表示的最大整數就是255(二進制11111111=十進制255),0-255被用來表示大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A的編碼是65,小寫字母z的編碼是122。
如果要表示中文,顯然一個字節是不夠的,至少需要兩個字節,而且還不能和ASCII碼沖突,所以,中國制定了GB2312編碼,把中文編進去。類似的,日文和韓文等其他語言也有這個問題。為了統一所有文字的編碼,Unicode應運而生。Unicode把所有語言都統一到一套編碼里,以解決亂碼問題。
Unicode通常用兩個字節表示一個字符,原有的英文編碼從單字節變成雙字節,只需要把高字節全部填為0就可以了。
因為Python誕生的時間比Unicode標準發布的時間早,所以最早的Python只支持ASCII碼,普通的字符串'ABC'在Python內部都是ASCII編碼的。
Python在后來添加了對Unicode的支持,用u'...'表示,如
print u'中文'
?
如果中文字符串遇到UnicodeDecodeError,這是因為.py文件保存的格式有問題。
需要在第一行加注釋:
# -*- coding: utf-8 -*-
目的是告訴Python解釋器,用UTF-8編碼讀取源代碼,然后另存為UTF-8格式。
?
?
?











)







