文章目錄
- ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
- 摘要
- 本文方法
- 實驗結果
- DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
- 摘要
- 本文方法
- 實驗結果
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
摘要
本文介紹了一種快速高效的卷積神經網絡ESPNet,用于資源約束下的高分辨率圖像的語義分割。ESPNet基于一種新的卷積模塊——高效空間金字塔(ESP),它在計算、內存和功耗方面都是高效的。ESPNet比最先進的語義分割網絡PSPNet快22倍(在標準GPU上),小180倍[1],而其分類準確率僅低8%。我們在多種語義分割數據集上對ESPNet進行了評估,包括cityscape、PASCAL VOC和乳腺活檢整張幻燈片圖像數據集。
代碼地址
本文方法
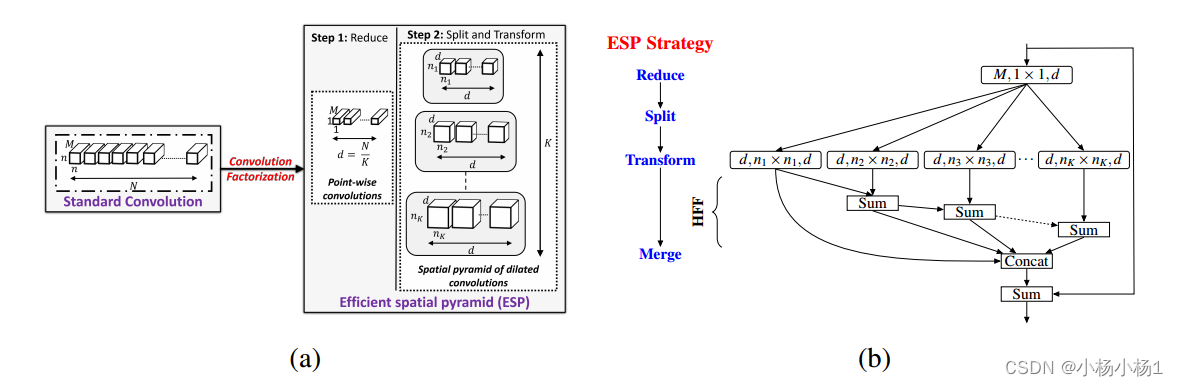
(a)將標準卷積層分解為擴展卷積的點向卷積和空間金字塔,構建高效的空間金字塔(ESP)模塊。
(b) ESP模塊框圖。ESP模塊的大有效接受場引入了網格偽影,使用分層特征融合(HFF)去除這些偽影。在輸入和輸出之間增加了跳躍式連接,以改善信息流。參見第3節了解更多細節。擴展卷積層表示為(#輸入通道,有效核大小,#輸出通道)。
擴展卷積核的有效空間維數為nk × nk,其中nk = (n?1)2k?1 + 1;k = 1;···注意,只有n × n個像素參與擴展卷積核。
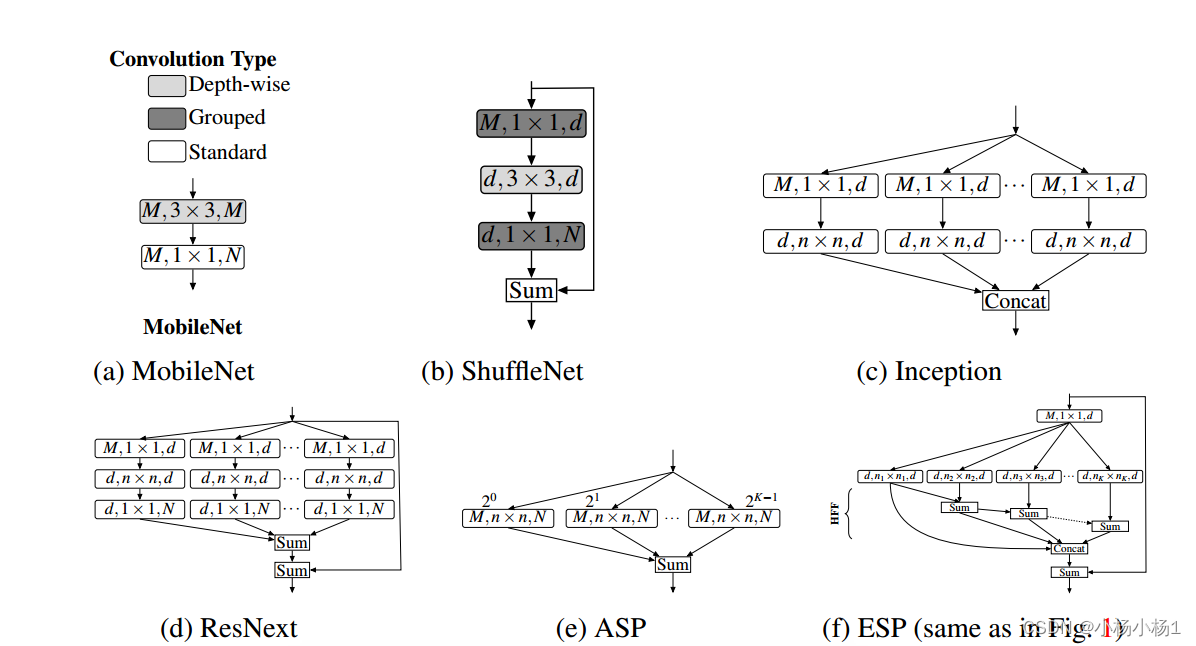
模型比較基礎
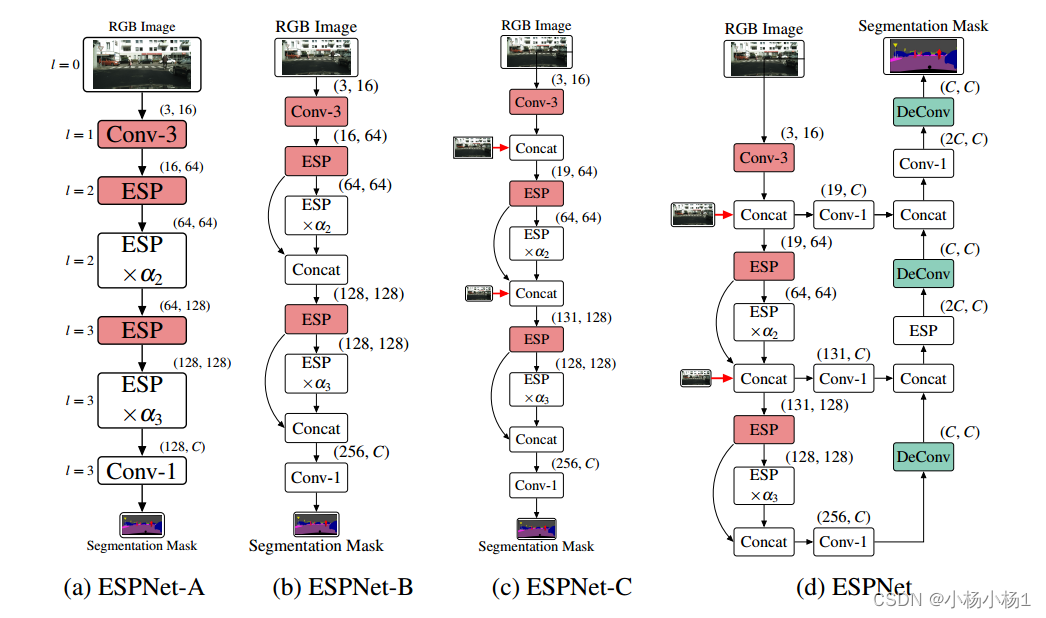
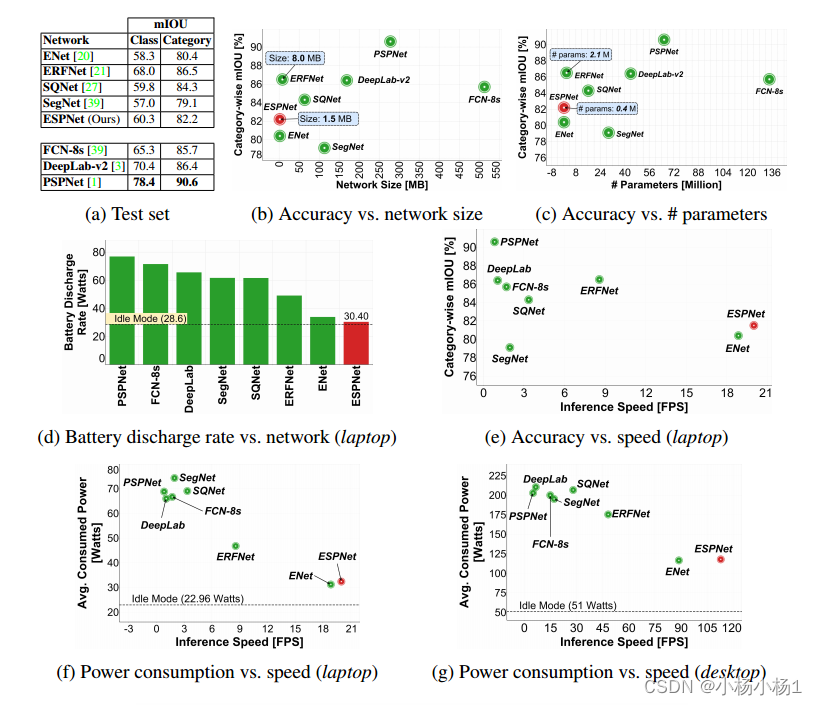
實驗結果

DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
摘要
Lidars和攝像頭是自動駕駛中為三維檢測提供補充信息的關鍵傳感器。雖然流行的多模態方法[34,36]只是簡單地用相機特征裝飾原始激光雷達點云,并將其直接提供給現有的3D檢測模型,但我們的研究表明,將相機特征與深度激光雷達特征融合,而不是將原始點融合,可以帶來更好的性能。然而,由于這些特征經常被增強和聚合,融合中的一個關鍵挑戰是如何有效地對齊從兩種模式轉換的特征。
提出了兩種新技術:InverseAug,它可以逆幾何相關的增強,例如旋轉,以實現激光雷達點和圖像像素之間的精確幾何對齊
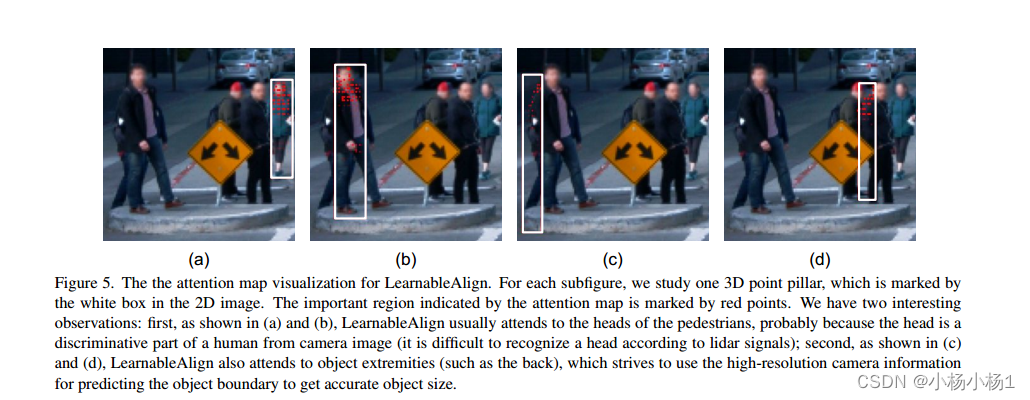
LearnableAlign,它利用交叉注意在融合過程中動態捕獲圖像和激光雷達特征之間的相關性。
基于InverseAug和LearnableAlign,我們開發了一系列通用的多模態3D檢測模型,稱為DeepFusion,比以前的方法更準確。
代碼地址
本文方法
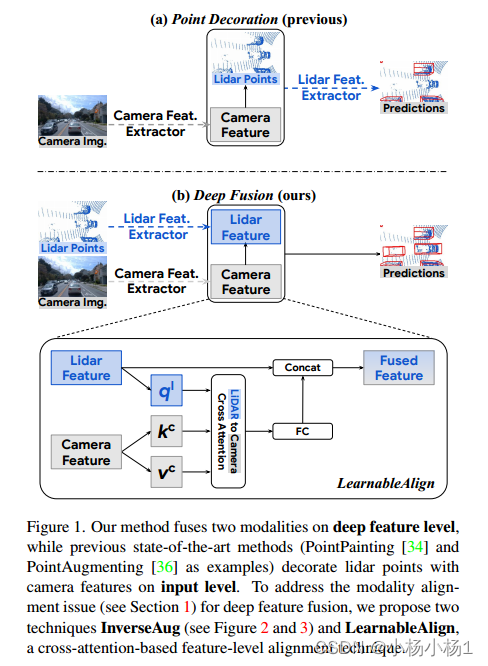
鑒于深度特征對齊的重要性,我們提出了InverseAug和LearnableAlign兩種技術,從兩種模式有效對齊深度特征。
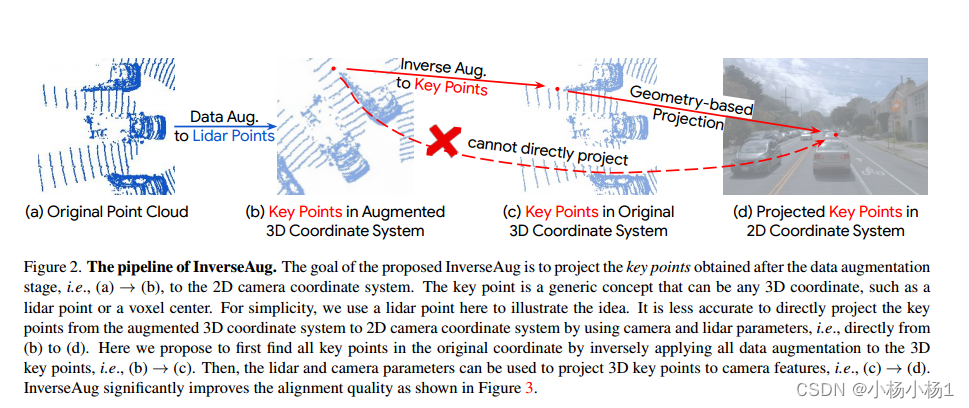
InverseAug。為了在現有基準測試中獲得最佳性能,大多數方法需要強大的數據增強,因為訓練通常會陷入過擬合場景。從表1可以看出數據增強的重要性,其中單模態模型的精度可以提高到5.0。然而,數據增強的必要性給我們的DeepFusion管道帶來了不小的挑戰。具體來說,來自兩種模式的數據通常使用不同的增強策略進行增強(例如,3D點云沿z軸旋轉,2D圖像隨機翻轉),這使得對齊具有挑戰性。
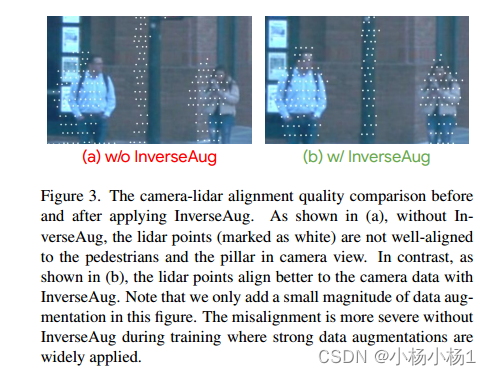
為了解決由幾何相關數據增強引起的對齊問題,我們提出了InverseAug。
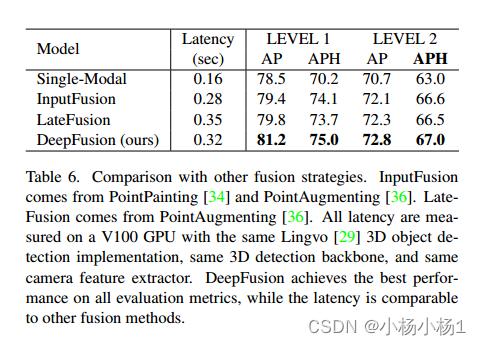
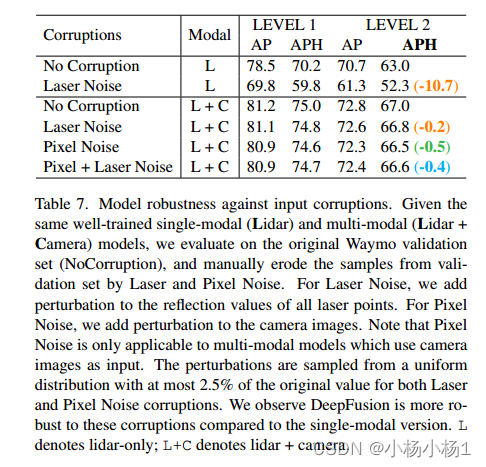
實驗結果












)



)


