一 多線程
1.1 進程和線程
- 進程: 就是一個程序,運行在系統之上,稱這個程序為一個運行進程,并分配進程ID方便系統管理。
- 線程:線程是歸屬于進程的,一個進程可以開啟多個線程,執行不同的工作,是進程的實際工作最小單位。
- 操作系統中可以運行多個進程,即多任務運行
- 一個進程內可以運行多個線程,即多線程運行
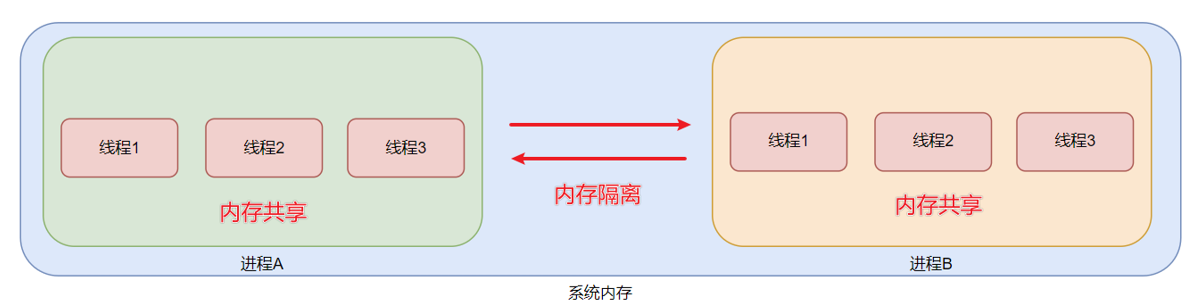
- 進程之間是內存隔離的, 即不同的進程擁有各自的內存空間。
- 線程之間是內存共享的,線程是屬于進程的,一個進程內的多個線程之間是共享這個進程所擁有的內存空間的。
1.2 并行、并發執行概念
-
在Python中,多線程用于實現并行和并發執行任務。雖然多線程可以讓你同時執行多個任務,但由于Python的全局解釋鎖(Global Interpreter Lock,GIL)的存在,多線程并不能實現真正的多核并行。然而,多線程仍然可以用于執行I/O密集型任務,因為在這些任務中,線程可能會在等待I/O操作完成時釋放GIL,從而允許其他線程運行。
-
并行執行:
- 并行執行是指多個任務在同一時刻同時運行,各自獨立地占用一個CPU核心。
- 在Python中,由于GIL的存在,多線程并不適合用于CPU密集型任務的并行執行。
- 多個進程同時在運行,即不同的程序同時運行,稱之為:多任務并行執行
- 一個進程內的多個線程同時在運行,稱之為:多線程并行執行
-
并發執行:
- 并發執行是指多個任務交替執行,通過快速切換執行任務的上下文來實現“同時”執行的錯覺。
- 這在處理I/O密集型任務時非常有效,因為線程可能會在等待I/O完成時讓出CPU資源給其他線程。
1.3 多線程編程
-
在Python中,可以使用
threading模塊來創建和管理多線程。 -
threading.Thread類可以創建一個線程對象,用于執行特定的任務函數。 -
threading.Thread類的一般語法和一些常用參數:thread_obj = threading.Thread(target=function_name, args=(), kwargs={}, daemon=False) # 啟動線程 thread_obj.start() -
target: 必需的參數,用于指定線程要執行的函數(任務)。函數會在新線程中運行。 -
args: 可選參數,用于傳遞給目標函數的位置參數,以元組形式提供。如果函數不需要參數,可以傳遞一個空元組或省略這個參數。 -
kwargs: 可選參數,用于傳遞給目標函數的關鍵字參數,以字典形式提供。如果函數不需要關鍵字參數,可以傳遞一個空字典或省略這個參數。 -
daemon: 可選參數,布爾值,用于指定線程是否為守護線程。守護線程會在主線程結束時被終止,而非守護線程會等待所有線程完成后再終止。 -
使用
threading.Thread類創建線程對象并啟動線程
import threading
import timedef print_numbers():for i in range(1, 6):print(f"Number: {i}")time.sleep(1)def print_letters():for letter in ['a', 'b', 'c', 'd', 'e']:print(f"Letter: {letter}")time.sleep(1)if __name__ == "__main__":thread1 = threading.Thread(target=print_numbers)thread2 = threading.Thread(target=print_letters)thread1.start() # Start the first threadthread2.start() # Start the second threadthread1.join() # 用于阻塞當前線程,直到被調用的線程完成其執行thread2.join() # 用于阻塞當前線程,直到被調用的線程完成其執行print("All threads completed")
-
在這個示例中,創建了兩個線程對象,每個線程對象都關聯一個不同的任務函數(
print_numbers和print_letters)。然后啟動這兩個線程,并等待它們完成。最后,我們輸出一個提示,表示所有線程都已完成。 -
thread1和thread2是兩個線程對象,而thread1.join()和thread2.join()是在主線程中調用的。當調用這些方法時,主線程會阻塞,直到對應的線程(thread1或thread2)完成了它們的執行。 -
thread1.join()和thread2.join()語句確保在兩個子線程執行完成后,主線程才會輸出 “All threads completed” 這條消息。如果不使用join(),主線程可能會在子線程還沒有完成時就繼續執行,導致輸出消息的時機不確定。
1.4 補充:join()方法
-
在多線程編程中,
join()方法用于阻塞當前線程,直到被調用的線程完成其執行。具體來說,thread1.join()表示當前線程(通常是主線程)會等待thread1線程完成后再繼續執行。 -
這種等待的機制可以確保主線程在所有子線程執行完成后再繼續執行,從而避免可能出現的線程之間的競爭條件和不確定性。這在需要等待所有線程完成后進行進一步操作或獲取線程執行結果時非常有用。
1.5 并行、并發實現演示
- 并行執行多個任務演示:
import threadingdef task1():print("Task 1 started")# ... some code ...print("Task 1 finished")def task2():print("Task 2 started")# ... some code ...print("Task 2 finished")if __name__ == "__main__":thread1 = threading.Thread(target=task1)thread2 = threading.Thread(target=task2)thread1.start()thread2.start()thread1.join()thread2.join()print("All tasks completed")
- 并發執行演示:
import threading
import timedef task1():print("Task 1 started")time.sleep(2) # Simulate I/O operationprint("Task 1 finished")def task2():print("Task 2 started")time.sleep(1) # Simulate I/O operationprint("Task 2 finished")if __name__ == "__main__":thread1 = threading.Thread(target=task1)thread2 = threading.Thread(target=task2)thread1.start()thread2.start()thread1.join()thread2.join()print("All tasks completed")
1.6 Thread參數傳遞使用演示
- 當使用
threading.Thread創建線程對象時,可以通過args、kwargs和daemon參數傳遞不同類型的信息給線程。 - 以下是針對每種參數的示例:
- 使用
args參數傳遞位置參數:
import threadingdef print_numbers(start, end):for i in range(start, end + 1):print(f"Number: {i}")if __name__ == "__main__":thread1 = threading.Thread(target=print_numbers, args=(1, 5))thread2 = threading.Thread(target=print_numbers, args=(6, 10))thread1.start()thread2.start()thread1.join()thread2.join()print("All threads completed")
- 使用
kwargs參數傳遞關鍵字參數:
import threadingdef greet(name, message):print(f"Hello, {name}! {message}")if __name__ == "__main__":thread1 = threading.Thread(target=greet, kwargs={"name": "Alice", "message": "How are you?"})thread2 = threading.Thread(target=greet, kwargs={"name": "Bob", "message": "Nice to meet you!"})thread1.start()thread2.start()thread1.join()thread2.join()print("All threads completed")
- 使用
daemon參數設置守護線程:
import threading
import timedef count_seconds():for i in range(5):print(f"Elapsed: {i} seconds")time.sleep(1)if __name__ == "__main__":thread = threading.Thread(target=count_seconds)thread.daemon = True # 設置線程為守護線程thread.start()# No need to join daemon threads, they will be terminated when the main thread endsprint("Main thread completed")
- 將線程
thread設置為守護線程(daemon = True)。這意味著當主線程結束時,守護線程也會被終止,而無需使用join()等待它完成。
二 網絡編程
2.1 Socket初識
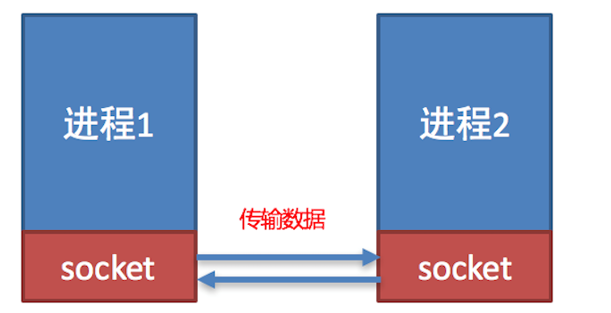
- Python的套接字(Socket)編程是一種基本的網絡編程技術,它可以在網絡上建立連接并進行數據傳輸。
- socket (簡稱 套接字) 是進程之間通信一個工具,進程之間想要進行網絡通信需要socket。Socket負責進程之間的網絡數據傳輸,是數據的搬運工。
2.2 客戶端和服務端
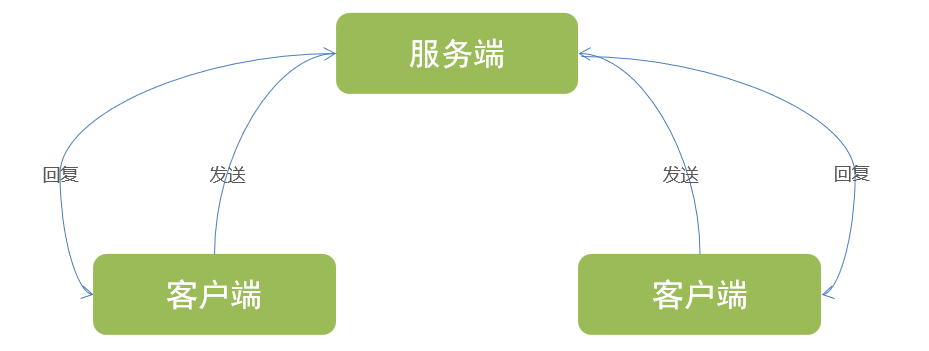
- 2個進程之間通過Socket進行相互通訊,就必須有服務端和客戶端
- Socket服務端:等待其它進程的連接、可接受發來的消息、可以回復消息
- Socket客戶端:主動連接服務端、可以發送消息、可以接收回復
2.3 創建socket對象詳解
-
在創建套接字對象時,通常是可以不指定參數的。如果沒有指定參數,將會使用默認的參數,這些參數在
socket模塊中預先定義。默認情況下,socket函數將創建一個 IPv4 的流式套接字。 -
例如,以下代碼將創建一個默認的 IPv4 TCP 套接字:
import socket# 創建一個默認的 IPv4 TCP 套接字 default_socket = socket.socket()# 后續代碼中可以使用 default_socket 進行操作 -
這種方式在很多情況下都是適用的,特別是當你只需要一個簡單的 IPv4 TCP 套接字時。
socket.socket(socket.AF_INET, socket.SOCK_STREAM)socket:Python 的內置套接字模塊,它提供了在網絡上進行通信的基本功能。socket.AF_INET:表示套接字地址簇(Address Family),用于指定套接字使用的地址類型。AF_INET表示使用 IPv4 地址。還可以使用AF_INET6來表示 IPv6 地址。socket.SOCK_STREAM:表示套接字的類型。SOCK_STREAM表示這是一個流式套接字,它基于 TCP 協議提供了可靠的、面向連接的、雙向的數據流傳輸。
-
綜合起來,
socket.socket(socket.AF_INET, socket.SOCK_STREAM)創建了一個基于 IPv4 地址和 TCP 協議的流式套接字對象,你可以使用這個套接字對象來建立連接、發送和接收數據。 -
如果需要創建基于 UDP 協議的套接字,可以使用
socket.SOCK_DGRAM,例如:udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
2.4 accept()方法詳解
-
accept()方法是在服務器端套接字上調用的方法,用于接受客戶端的連接請求。它會阻塞程序,直到有客戶端嘗試連接到服務器,然后返回一個新的套接字用于與該客戶端進行通信,以及客戶端的地址信息。client_socket, client_address = server_socket.accept()accept():接受客戶端的連接請求。當調用這個方法時,它會阻塞程序,直到有客戶端連接到服務器。一旦有連接請求到達,該方法將返回兩個值:一個是表示與客戶端通信的新套接字對象,另一個是客戶端的地址信息。client_socket:新創建的套接字對象,用于與連接的客戶端進行通信(可以使用這個套接字來接收和發送數據)client_address:元組類型,包含客戶端的 IP 地址和端口號。例如,('192.168.1.100', 54321)。
-
一般來說,服務器在一個循環中使用
accept()方法,以便能夠接受多個客戶端的連接。每當有新的客戶端連接到服務器時,accept()方法會返回一個新的套接字和客戶端的地址,然后服務器可以將新套接字添加到連接池,與客戶端進行通信。 -
注意:
accept()方法在沒有連接請求時會一直阻塞程序。如果你希望設置超時或者非阻塞的連接等待,你可以在創建服務器套接字后設置相應的選項。這樣,在沒有連接請求時調用accept()方法將立即返回,不會阻塞程序的執行。 -
例如,在創建服務器套接字后可以使用以下代碼將其設置為非阻塞模式:
server_socket.setblocking(False)
2.5 發送信息方法詳解
send()方法和sendall()方法都用于在套接字上發送數據,但它們有一些不同之處。
send(data) 方法:
send()方法是用于發送數據的基本方法,它接受一個字節流(bytes)作為參數,并嘗試將數據發送到連接的對方。- 如果成功發送全部數據,該方法將返回發送的字節數。如果沒有發送完全部數據,可能返回一個小于請求發送數據的字節數。
- 如果在發送過程中出現問題(例如連接中斷),
send()方法可能會引發異常。
sendall(data) 方法:
-
sendall()方法也用于發送數據,但它更加健壯,會自動處理數據分片和重試。 -
無論數據有多大,
sendall()方法會盡力將所有數據都發送出去,直到全部數據都被發送成功或發生錯誤。 -
方法不會立即返回,而是在所有數據都發送成功后才返回
None。如果發生錯誤,它可能引發異常。 -
sendall()方法在發送數據時會自動處理數據的分片,確保數據都被正確發送。 -
在大多數情況下,如果想要簡單地發送一小段數據,可以使用
send()方法。然而,如果需要發送大量數據或者確保數據被完整、可靠地發送,那么使用sendall()方法會更好,因為它會自動處理數據分片和錯誤處理。 -
使用
send()方法:client_socket.send(b"Hello, server!") -
使用
sendall()方法:data = b"Hello, server!" client_socket.sendall(data)
2.6 Socket編程演示
-
服務器端代碼:
import socket# 1. 創建Socket對象 server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2. 綁定服務器地址和端口 server_address = ('127.0.0.1', 12345) server_socket.bind(server_address)# 3. 開始監聽端口 backlog=5 標識允許的連接數量,超出的會等待,可以不填,不填自動設置一個合理的值 server_socket.listen(5)print("Waiting for a connection...") # 4. 接收客戶端連接,獲得連接對象 client_socket, client_address = server_socket.accept() print(f"Connected to {client_address}")# 5. 客戶端連接后,通過recv方法 接收并發送數據 while True:data = client_socket.recv(1024).decode('utf-8')# recv接受的參數是緩沖區大小,一般給1024即可# recv方法的返回值是一個字節數組也就是bytes對象,不是字符串,可以通過decode方法通過UTF-8編碼,將字節數組轉換為字符串對象if not data:breakprint(f"Received: {data}")# 6. 通過client_socket對象(客戶端再次連接對象),調用方法,發送回復消息msg = input("請輸入你要和客戶端回復的消息:")if msg == 'exit':breakclient_socket.sendall(msg.eccode("UTF-8"))# 7.關閉連接 client_socket.close() server_socket.close()
- 客戶端代碼:
import socket# 1.創建socket對象 client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2.連接服務器地址和端口 server_address = ('127.0.0.1', 12345) client_socket.connect(server_address)# 3.發送數據 while True:# 發送消息msg = input("請輸入要給服務端發送的消息:")if msg == 'exit':breakclient_socket.sendall(msg.encode("UTF-8"))# 4.接收返回消息recv_data = client_socket.recv(1024) # 1024是緩沖區的大小,一般1024即可。 同樣recv方法是阻塞的 print(f"服務端回復的消息是:{recv_data.decode('UTF-8')}")# 5.關閉連接 client_socket.close()
三 正則表達式
3.1 正則表達式概述
- 正則表達式,又稱規則表達式(Regular Expression),是使用單個字符串來描述、匹配某個句法規則的字符串,常被用來檢索、替換那些符合某個模式(規則)的文本。
- 正則表達式就是使用:字符串定義規則,并通過規則去驗證字符串是否匹配。
- 比如,驗證一個字符串是否是符合條件的電子郵箱地址,只需要配置好正則規則,即可匹配任意郵箱。通過正則規則:
(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)即可匹配一個字符串是否是標準郵箱格式
3.2 Python正則表達式使用步驟
- 使用正則表達式的一些基本步驟和示例:
- 導入
re模塊:
import re
- 使用
re.compile()編譯正則表達式:
# `pattern_here`應該替換為實際正則表達式
pattern = re.compile(r'pattern_here')
- 使用編譯后的正則表達式進行匹配:
text = "This is an example text for pattern matching."
result = pattern.search(text)
if result:print("Pattern found:", result.group())
else:print("Pattern not found.")
3.3 正則的基礎方法
-
Python正則表達式,使用re模塊,并基于re模塊中基礎方法來做正則匹配。
-
匹配(Match):使用
match()來從字符串的開頭開始匹配。匹配成功返回匹配對象(包含匹配的信息),匹配不成功返回空
result = pattern.match(text)
- 搜索(Search):使用
search()來查找文本中的第一個匹配項。整個字符串都找不到,返回None
result = pattern.search(text)
- 查找所有(Find All):使用
findall()來找到所有匹配項,并返回一個列表。找不到返回空list: []
results = pattern.findall(text)
- 替換(Replace):使用
sub()來替換匹配項。
# `replacement`應該是希望替換匹配項的內容
new_text = pattern.sub(replacement, text)
- 分割(Split):使用
split()來根據匹配項分割字符串。
parts = pattern.split(text)
-
在正則表達式中,你可以使用不同的元字符(例如
.、*、+、?、[]、()等)來構建復雜的模式,以便進行更精確的匹配。 -
演示使用正則表達式從文本中提取所有的電子郵件地址
import retext = "Contact us at: john@example.com or jane@example.org for more information."pattern = re.compile(r'\b[\w.-]+@[\w.-]+\.\w+\b')
email_addresses = pattern.findall(text)for email in email_addresses:print(email)
3.4 元字符匹配
- 單字符匹配
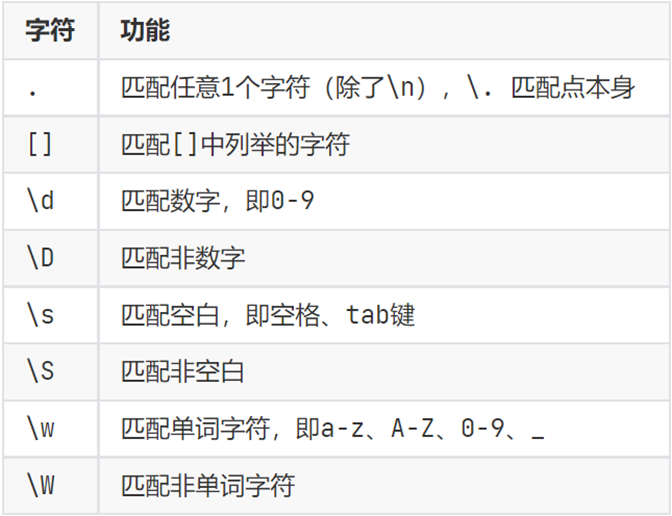
示例:
字符串s = "itheima1 @@python2 !!666 ##itcast3" - 找出全部數字:
re.findall(r '\d', s)
- 字符串的r標記,表示當前字符串是原始字符串,即內部的轉義字符無效而是普通字符
- 找出特殊字符:
re.findall(r '\W', s) - 找出全部英文字母:
re.findall(r '[a-zA-Z]', s) []內可以寫:[a-zA-Z0-9]這三種范圍組合或指定單個字符如[aceDFG135]
- 數量匹配

- 邊界匹配
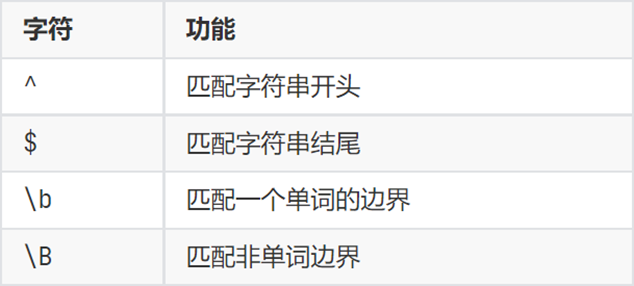
- 分組匹配

四 遞歸
-
遞歸是一種編程技術(算法),即方法(函數)自己調用自己的一種特殊編程寫法。在Python中,可以使用遞歸來解決許多問題,特別是那些可以被分解為相同或類似子問題的問題。
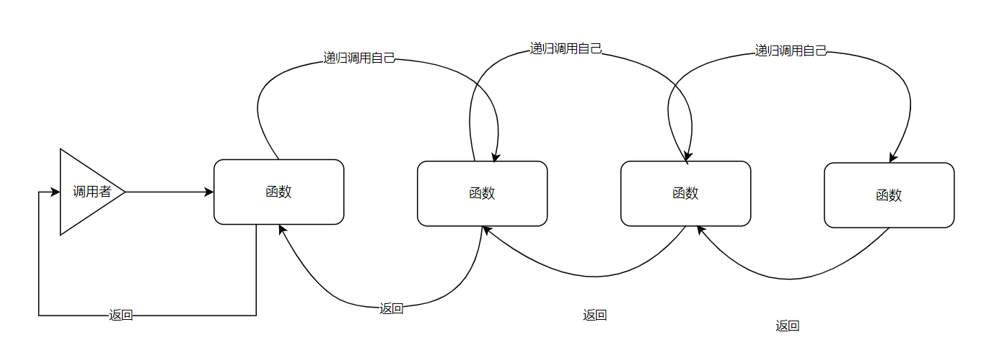
-
在使用遞歸時,需要確保定義遞歸基(base case),這是遞歸結束的條件,以避免無限循環。每次遞歸調用都應該將問題規模減小,使其朝著遞歸基的條件靠近。
-
使用遞歸計算階乘:
def factorial(n):if n == 0:return 1 # 遞歸基else:return n * factorial(n - 1) # 遞歸調用num = 5 result = factorial(num) print(f"The factorial of {num} is {result}")factorial函數通過不斷地調用自身來計算階乘。當n達到遞歸基條件n == 0時,遞歸結束,不再調用自身。
-
然而,遞歸并不總是最有效的解決方法,因為它可能會導致函數調用的嵌套層數過深,從而消耗大量的內存和處理時間。在一些情況下,使用循環或其他方法可能更有效。
-
在編寫遞歸函數時,要確保遞歸調用朝著遞歸基靠近,避免陷入無限循環,同時考慮性能方面的問題。
)



)










 P2P方式(對等方式))



