一面問題:MySQL+Redis+Kafka+線程+算法
- mysql知道哪些存儲引擎,它們的區別
- mysql索引在什么情況下會失效
- mysql在項目中的優化場景,慢查詢解決等
- mysql有什么索引,索引模型是什么
- B-樹與B+樹的區別?為什么不用紅黑樹
- mysql主從同步怎么做
- 樂觀鎖與悲觀鎖的區別?
- binlog日志
- redis 持久化有哪幾種方式,怎么選?
- redis 主從同步是怎樣的過程?
- redis 的 zset 怎么實現的?
- redis key 的過期策略
- hashmap 是怎樣實現的?為什么要用紅黑樹,而不用平衡二叉樹?為什么在1.8中鏈表大于8時會轉紅黑樹?HashMap為什么線程不安全的?
- 如何實現線程安全的hashmap?
- select 和 epoll的區別
- http與https的區別,加密怎么加的?
- raft算法詳細講解
- Kafka 選主怎么做的?
- kafka如何保證生產與消費都是同步的?
- kafka 怎么保證不丟消息的
- redis如何保證高可用
- 算法:剪繩子(貪心或遞歸解決)
- 算法:給前序和中序遍歷,重建二叉樹
二面(volatile+線程+并發+算法+設計模式)
- 自我介紹
- 講講項目(項目沒啥亮點,直接問基礎)
- volatile作用?底層實現?禁止重排序的場景?單例模式中volatile的作用?
- 如何構造線程池,它的參數,飽和策略?
- 公平鎖和非公平鎖區別?為什么公平鎖效率低?
- 線程都有哪些狀態?
- 線程、進程、協程的區別?
- 同步隊列器AQS思想,以及基于AQS實現的lock,。
- 并發工具類CountDownLatch、CyclicBarrier、Semaphore介紹
- Execuors類實現的幾種線程池類型,最后如何返回?
- 手寫單例模式
- 手寫消費者生產者模式
- 算法:反轉單鏈表
- 算法:給定一個只包含 ‘(’ 和 ‘)’ 的字符串,找出最長的包含有效括號的子串的長度。
三面
這一面,沒問啥東西,主要聊人生,和未來3年的規劃。。。。。。
第二個是字節跳動

一面:算法+數據庫+事務+網絡
- 自我介紹
- 項目介紹(沒亮點,還是問基礎)
- 堆排序的原理及時間復雜度,是否穩定,最壞及最壞場景。
- Object類都有哪些方法?
- DNS解析的過程/瀏覽器輸入一個url,敲下回車后網絡的全過程
- HTTP和HTTPS的區別
- UDP怎么實現可靠傳輸
- 介紹下https,是如何加密的,加密算法
- 數據庫索引的優缺點,以及什么時候數據庫索引失效
- 事務的隔離級別?
- 數據庫的臟讀,不可重復讀,幻讀
- 算法:接雨水:給定 n 個非負整數表示每個寬度為 1 的柱子的高度圖,計算按此排列的柱子,下雨之后能接多少雨水。
- 算法:N皇后
二面:Kafka+redis+算法
- Kafka的特性?
- Kafka中的分區器、序列化器、攔截器是否了解?它們之間的處理順序是什么?
- 消費者重平衡(高可用性、伸縮性)
- 哪些情景下會造成消息漏消費?
- 如何保證消息不被重復消費(冪等性)
- KafkaConsumer是非線程安全的,那么怎么樣實現多線程消費?
- Kafka生產者客戶端中使用了幾個線程來處理?分別是什么?
- 消費者與生產者的工作流程:
- topic的分區數可不可以增加?
- 算法:二叉樹中的最大路徑和
- 算法:給定單向鏈表的頭指針和一個要刪除的節點的值,定義一個函數刪除該節點。
三面:Redis+Spring+Dubbo+算法
- redis的Zset怎么實現的?
- sentinel和cluster區別和各自適用場景
- redis cluster集群同步過程
- redis單線程為什么快?
- mybatis一級緩存和二級緩存
- spring如何解決循環依賴?
- spring AOP的原理。
- spring的生命周期。
- Dubbo服務暴露和引用過程,負載均衡策略,容錯機制在哪里實現的源碼
- 項目中遇到了哪些問題。(抱歉,我的工作就是增刪改查,沒接觸過相關問題)
- 算法:二叉樹的鏡像
- 算法:從上到下打印二叉樹
最后瞄一眼騰訊
騰訊這三面下來問的也不少,自求多福吧。

一面
- 如何設計一個秒殺系統?
- 一天爬一千萬條文章,怎么做設計?怎么并行協調?100 臺服務器怎么盡可能負載均衡?
- 有用過短域名服務嗎,能說一下嗎?
- 微服務的特點,如何實現服務發現和負載均衡
- 如何排查線上問題?(背過,沒排過)
- 貝葉斯的概率學原理
- 負載均衡的加權輪詢算法怎么實現
- 如果用戶量大幅度上漲,如何優化?
- paxos算法(這個算法太難,學的時候就沒太理解)
- 平時都看什么博客,最近看什么書了
二面
- 自我介紹
- 項目介紹
- redis的5種類型,及其實現原理
- 如何使用redis的Zset實現延時隊列?
- redis如何實現高可用?
- redis緩存穿透、緩存擊穿、緩存雪崩
- 布隆過濾器的實現
- 如何保證mysql與redis的雙寫一致性?
- 負載均衡算法有哪些?
- 服務發現是怎么實現的?
- 熔斷是怎么實現的?
- 算法:連續子數組的最大和
- 講講分布式CAP和BASE?
- 什么是強一致性?
- 分布式事務的解決方案?
- TCC(兩階段型、補償型)
- id生成器如何實現?
- 如何判斷一個圖是否有環?
- 一致性Hash算法,及其應用
- 背包問題
三面
- 自我介紹
- 項目介紹
- redis的zSet如何實現?
- redis持久化機制。
- redis的Hash類型講解,漸進式rehash。
- HashMap原理,一個put操作,都有什么流程?
- nginx有自己配置過嗎(這個是我唯一手動操作過的,這個不是背的)
- nginx的使用場景。
- 什么是分布式,什么是集群,區別是什么?
- 在基于dubbo的分布式環境中,一般將超時timeout設置在provider還是consumer?
- dubbo中負載均衡的策略有哪些?
- 接口的異步調用?如何設置?運行效果?
- 談談基于dubbo的系統中consumer集群的解決方案?
- mysql是集群還是單節點?最大連接數,最大的表中數據量大約是多少?
- mysql主從復制主要有哪幾種模式?
- mysql索引,B+樹,為什么不用紅黑樹?
- 數據庫垂直與水平拆分怎么做。
- 分布式session設置
- IO、BIO、NIO,阻塞與非阻塞的區別?
- 分布式接口的冪等性設計(不能重復扣付款)
- 算法:二叉搜索數與雙向鏈表(這個懵了)
- 算法:最長不含重復字符的子字符串
- 算法:手寫快速排序、插入排序、冒泡排序,并分析時間復雜度和空間復雜度,它們的穩定性
最后,附一張自己面試前準備的腦圖:
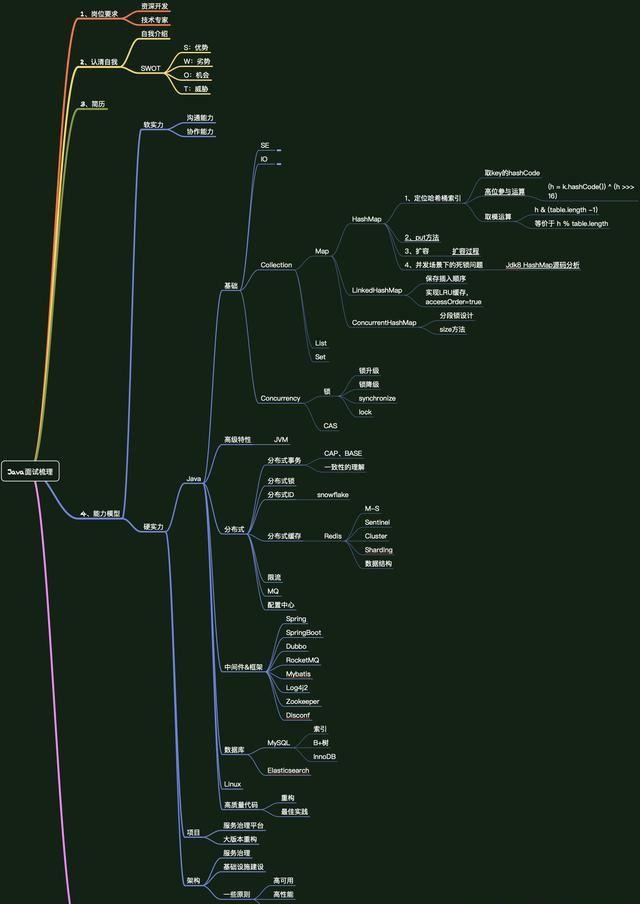
面試前一定少不了刷題,為了方便大家復習,我分享一波個人整理的面試大全寶典
- Java核心知識整理
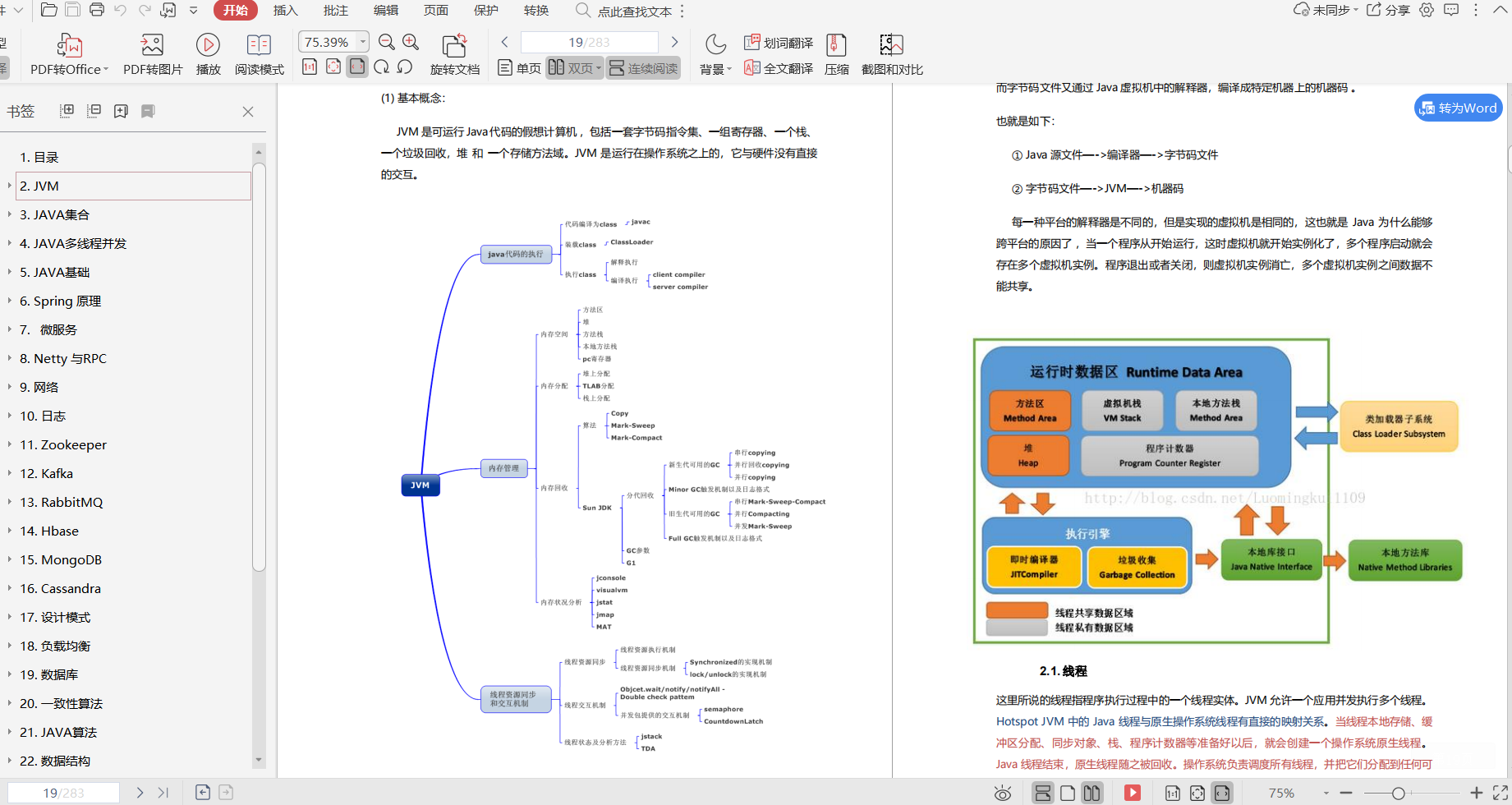
- Spring全家桶(實戰系列)
Step3:刷題
既然是要面試,那么就少不了刷題,實際上春節回家后,哪兒也去不了,我自己是刷了不少面試題的,所以在面試過程中才能夠做到心中有數,基本上會清楚面試過程中會問到哪些知識點,高頻題又有哪些,所以刷題是面試前期準備過程中非常重要的一點。
以下是我私藏的面試題庫:
很多人感嘆“學習無用”,實際上之所以產生無用論,是因為自己想要的與自己所學的匹配不上,這也就意味著自己學得遠遠不夠。無論是學習還是工作,都應該有主動性,所以如果擁有大廠夢,那么就要自己努力去實現它。
資料領取方式:Java全套學習手冊
mg-uicdurDl-1626863637899)]
很多人感嘆“學習無用”,實際上之所以產生無用論,是因為自己想要的與自己所學的匹配不上,這也就意味著自己學得遠遠不夠。無論是學習還是工作,都應該有主動性,所以如果擁有大廠夢,那么就要自己努力去實現它。
資料領取方式:Java全套學習手冊
以上學習資料均免費分享,最后祝愿各位身體健康,順利拿到心儀的offer!












)






