文章目錄
- 前言
- Diffusion模型
- 推理過程
- 訓練過程
- Stable Diffusion模型
- 參考
前言
前面一篇文章主要講了擴散模型的理論基礎,還沒看過上篇的小伙伴可以點擊查看:DDPM理論基礎。這篇我們主要講一下一經推出,就火爆全網的Stable Diffusion模型。Stable Diffusion因其免費,開源,生成圖像質量高等優點,一經推出,就火爆全網,后面stable-diffusion-webui的推出,更是降低了使用Stable Diffusion模型作畫的門檻,一時刷爆了整個社區。今天筆者詳細的帶大家看一下Stable Diffusion背后的原理。
Diffusion模型
這里為了讓大家更好的理解Stable Diffusion模型,我們先來簡單介紹一下Diffusion模型。下圖展示了diffusion模型在訓練和推理的過程。從圖中可以看出,擴散過程主要包括幾個主要的模型,分別是text encoder(文本編碼器),unet,image decoder(圖像解碼器)。其中,text encoder的作用主要是將輸入的文本,即prompt,編碼為token embeddings,這個token embeddings就是代表文本的一個個向量。這一個個文本向量會通過某種方式注入到unet中,用來控制unet生成符合文本描述的圖像。

推理過程
在推理階段,擴散過程是一個多步去噪的過程,主要就是一個unet網絡結構,其輸入和輸出具有相同的形狀,輸入為含噪聲的圖像和時間戳 t t t,輸出為圖像上添加的噪聲,進而得到去掉該噪聲的圖像。就這樣經過unet的一步步去噪,逐步生成一個不含噪聲的,符合文本描述的圖像。有很多人會問,為什么不直接一步預測出噪聲,然后直接將該噪聲去掉,生成不含噪聲的圖像呢?其實這樣的話,噪聲很大,網絡很難預測出準確的噪聲分布。上圖中的N即擴散過程執行的步數,該參數可以由我們自己指定,一般步數設置的越大,生成的圖像會越精細。經過擴散過程后會生成低分辨率的,不含噪聲的圖像,為了生成更高分辨率的圖像,這時就會在后面再接一個image decoder,用來擴大圖像的分辨率,image decoder輸出的圖像即為最后我們想要的高分辨率圖像。
文本特征主要是通過cross attention模塊加入的,我們來大致拆解一下unet內部的網絡結構。如下圖,unet內部主要是由多個resnet block和attention模塊組成的,兩者交替出現。每一個attention模塊接受resnet block輸出的圖像特征和文本特征向量作為輸入,將兩種特征進行融合,從而達到以文本為條件,控制圖像生成的目的。

attention內部的計算過程如下圖。圖像特征和文本特征分別通過三個參數矩陣映射到Q,K,V,然后Q與K的轉置點乘除以scale因子后經過softmax計算,最后點乘V,得到最后的特征。當然現在都是基于multi-head的多頭attention操作,multi-head只是多次執行下面的操作,得到多個 Z i Z^i Zi,最后再將 Z i Z^i Zi拼接在一起,經過最后一個參數矩陣映射得到最終的 Z Z Z。

訓練過程
diffusion模型的訓練過程主要涉及unet網絡的學習,需要讓unet具備能力:
給它輸入一張含噪圖像,unet能夠預測出含噪圖像上的噪聲。
這樣我們就可以去掉含噪圖像上的噪聲,得到一張干凈的、不含噪聲的圖像。訓練數據的構造如下圖:

首先第一步,選擇一張圖片;第二步,隨機生成一個基礎噪聲;第三步從0到 T T T的時間范圍內,隨機選擇一個時間戳 t t t,通過 t t t和基礎噪聲計算出最終要添加的噪聲,時間戳 t t t越大,代表噪聲添加的次數越多,也即添加噪聲的強度越大。第四步就是將第三步生成的噪聲加到圖像上,得到一個含噪聲的圖像。此時,步驟四中得到的含噪圖像作為unet網絡的輸入,步驟三生成的噪聲作為unet學習的目標,用來訓練unet網絡。
通過上面的1,2,3,4步,我們可以生成很多訓練數據,訓練過程中就是不斷將訓練數據喂給unet,讓其自主學習如何預測出含噪圖像上的噪聲,以達到去噪的目的。
Stable Diffusion模型
stable diffusion的最大貢獻就是沒有直接在像素空間進行圖像的加噪和去噪,而是先將圖像進行壓縮(下采樣),壓縮到一個圖像表征維度更低的隱空間(latent),然后在隱空間中進行擴散過程,這不僅加快了擴散過程的速度,同時減少了計算資源的消耗,而且在隱空間中操作依然能夠保證生成圖像的質量。舉個例子,如果原圖像的分辨率是256x256,現在將它下采樣8倍,到32x32,那么在32x32分辨率的圖像上操作肯定比直接在256x256分辨率的圖像上操作更快且節省資源。256x256分辨率的原圖即為像素空間特征,壓縮后的32x32分辨率的圖就是隱空間特征。

stable diffusion模型在推理和訓練階段的流程圖如上圖所示。與diffusion模型相比,最大的變化就是在推理階段,擴散過程的輸入由原來的隨機噪聲圖像image變成了隨機噪聲latent,其實兩者本質上都是純噪聲,只不過latent的分辨率比image的分辨率低,所以經過擴散過程生成的latent(Generated low resolution latent)也要比生成的image(Generated low resolution image)分辨率低,如果stable diffusion最終要生成與diffusion模型相同分辨率的圖像的話,這里image decoder的放大倍率就要更大。
那么在訓練階段,主要進行前向過程,也就是給圖像加噪聲。下圖就是stable diffusion生成訓練數據的過程。可見,和diffusion相比,只是多了一步將原圖壓縮到latent的過程,后面的添加噪聲都是在latent上進行的。

下面我們放一張stable diffusion論文中的原圖。
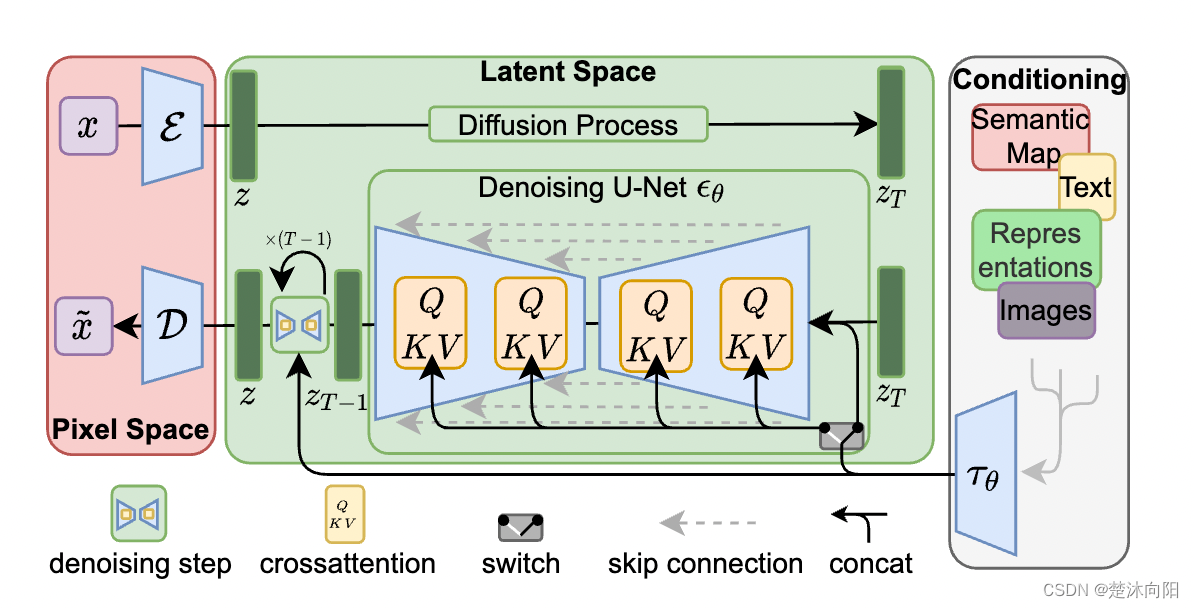
其中 E \mathcal E E為圖像編碼器,用來壓縮圖像尺寸, D \mathcal D D為圖像解碼器用來恢復圖像尺寸。圖中的Diffusion Process即為前向過程,原圖像 x x x經過編碼器 E \mathcal E E壓縮到隱空間 z z z后,在 z z z上進行加噪,生成 z T z_T zT?。生成過程為逆向過程,給定隱空間噪聲,經過多步去噪,生成不含噪聲的壓縮后的 z z z,再經過圖像解碼器恢復原始圖像的尺寸。
參考
https://www.cnblogs.com/gczr/p/14693829.html
https://jalammar.github.io/illustrated-stable-diffusion/
https://readpaper.com/pdf-annotate/note?pdfId=4665140328076951553¬eId=1834381375833065728











TCP并發服務器模型)





![[NLP]LLM 訓練時GPU顯存耗用量估計](http://pic.xiahunao.cn/[NLP]LLM 訓練時GPU顯存耗用量估計)

