一、RDB
1.1 RDB持久化流程
fork子進程是阻塞的,如果同時開啟RDB和AOF,默認使用AOF。
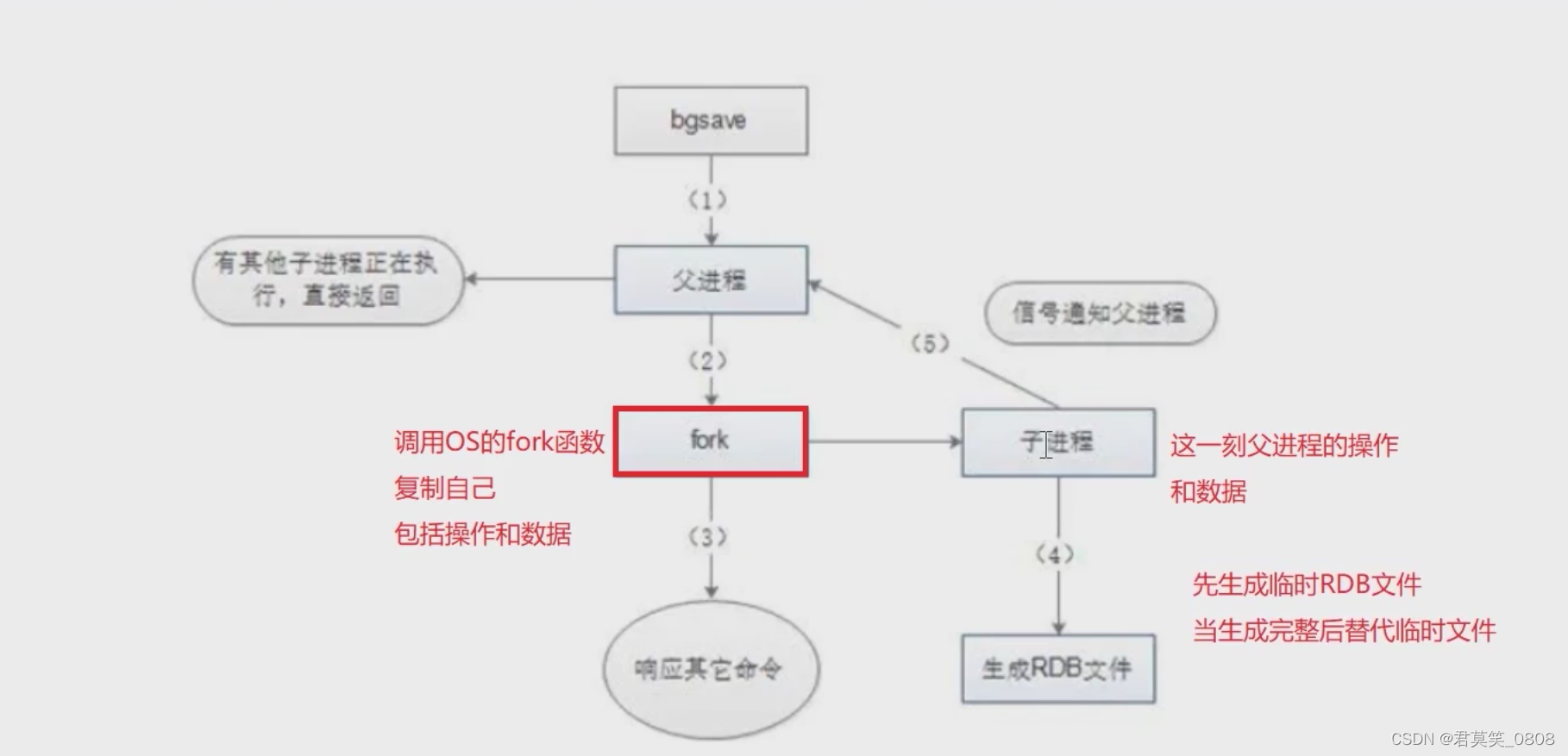
?1、Redis父進程首先判斷: 當前是否在執行save,或bgsave/bgrewriteaof (aof文件重寫命令)的子進程,如果在執行則bgsave命令直接返回。
2、父進程執行fork(調用OS函數復制主進程)操作創建子進程,這個復制過程中父進程是阻塞的,Redis不能執行來自客戶端的任何命令。
3、父進程fork后,bgsave命令返回”Bacground saving started"信息并不再阻塞父進程,并可以響應其他命令。
4、子進程創建RDB文件,根據父進程內存快照生成臨時快照文件,完成后對原有文件進行原子替換。 (RDB始終完整)。
5、子進程發送信號給父進程表示完成,父進程更新統計信息。
6、父進程fork子進程后,繼續工作。
1.2 redis配置
#1. 下面配置為默認配置,默認就是開啟的,在一定的間隔時間中,檢測key的變化情況,然后持久化數據
save 900 1 #900s后至少1個key發生變化則進行存儲
save 300 10 #300s后至少10個key發生變化則進行存儲
save 60 10000 #60s后至少10000個key發生變化則進行存儲
#2. rdb文件的存儲路徑(默認當前目錄下,文件名為dump.rdb)
dbfilename dump.rdb1.3? RDB優缺點
優點
RDB是二進制壓縮文件,占用空間小,便于傳輸 (傳給slaver)主進程fork子進程,可以最大化Redis性能,主進程不能太大,復制過程中主進程阻塞。
缺點
不保證數據完整性,會丟失最后一次快照以后更改的所有數據。
二、AOF
2.1 AOF介紹
????????AOF (append only file) 是Redis的另一種持久化方式。Redis默認情況下是不開啟的。開啟AOF持久化后Redis 將所有對數據庫進行過寫入的命令(及其參數) (RESP)記錄到 AOF 文件,以此達到記錄數據庫狀態的目的,這樣當Redis重啟后只要按順序回放這些命令就會恢復到原始狀態了。AOF會記錄過程,RDB只管結果。
2.2?AOF持久化實現
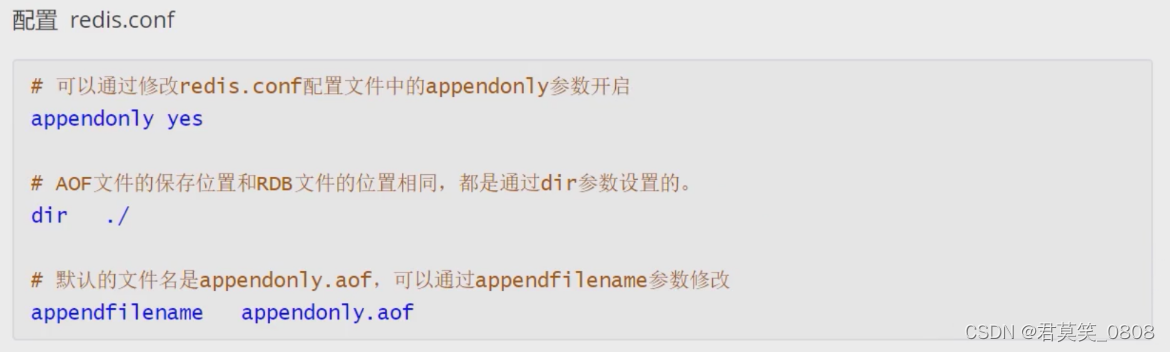
?文件內容示例:
2.3 AOF寫入過程?
????????AOF文件中存儲的是redis的命令,同步命令到 AOF 文件的整個過程可以分為三個階段:
1、命令傳播: Redis 將執行完的命令、命令的參數、命令的參數個數等信息發送到 AOF 程序中。
2、緩存追加: AOF 程序根據接收到的命令數據,將命令轉換為網絡通訊協議的格式,然后將協議內容追加到服務器的 AOF 緩存中。
3、文件寫入和保存: AOF緩存中的內被寫入到AOF文件末尾,如果設定的 AOF 保存條件被滿足的話,fsync函數或者fdatasync函數會被調用,將寫入的內容真正地保存到磁盤中。
2.4 AOF寫入頻率
AOF有這樣幾種配置用來控制讀寫的頻率:
(1)appendfsync always:每次一收到寫命令就立即強制寫入磁盤,保證完全的持久化。
(2)appendfsync no:由操作系統決定何時同步數據。
(3)appendfsync everysec:每秒鐘強制寫入磁盤一次。
2.5 AOF重寫
AOF重寫的實現
為了減小aof文件的體量,可以手動發送“bgrewriteaof”指令,通過子進程生成更小體積的aof,然后替換掉舊的、大體量的aof文件。
AOF重寫的工作原理

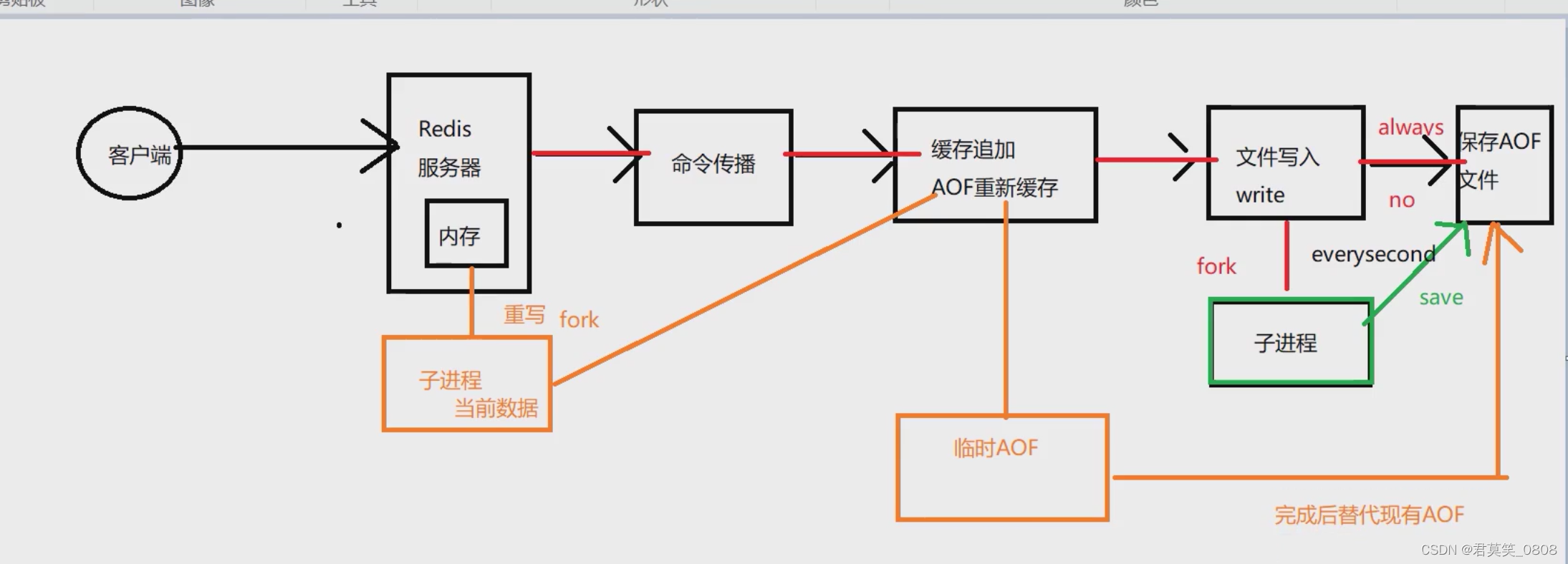
?????????需要注意的是,在這里子進程把數據轉為寫指令存入新的AOF文件時,記錄的只是每個數據的最后一次寫指令,也就是最新的數據,不會記錄之前冗余的操作,所以這樣會很大程度的縮小AOF的體量,同時,該操作是產生新的AOF文件進行寫入,而不是在原有文件上的修改,通過上圖也可以看出來。而緩存中疊加到新的aof的操作仍是新增的全部操作,但是這些數據已經很有限,相比之前的全部添加,這種機制很好的解決的AOF文件不斷增大的問題。?
2.6 AOF重寫的相關配置
1)auto-aof-rewrite-percentage 100
2)auto-aof-rewrite-min-size 64mb
在aof文件體量超過64mb,且比上次重寫后的體量增加了100%時自動觸發重寫。
2.7 AOF服務重啟恢復數據
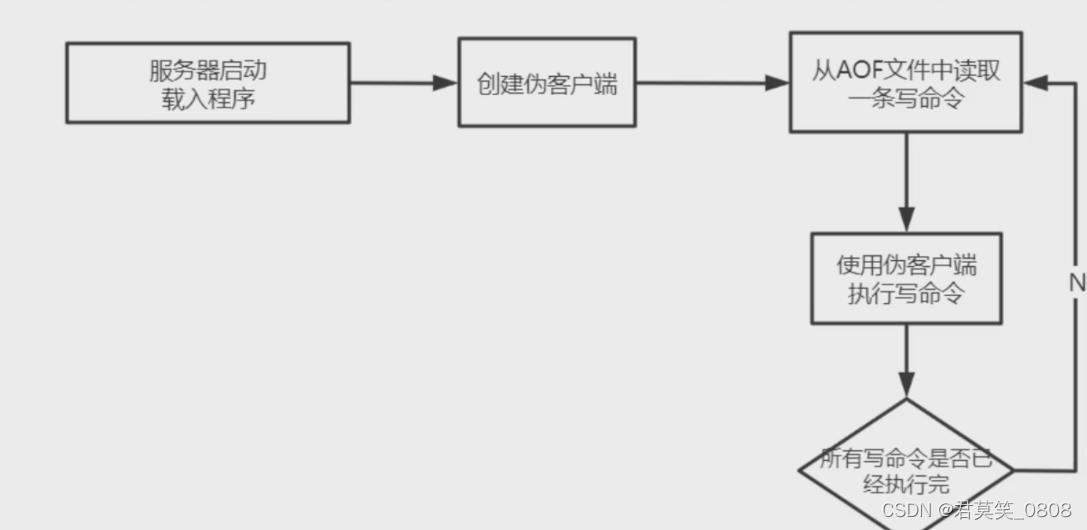
????????AOF文件里面包含了重建數據庫狀態所需的所有寫命令,所以服務器只要讀入并重新執行一遍AOF文件里面保存的寫命令,就可以還原服務器關閉之前的數據庫狀態,步驟如下:
1、創建一個不帶網絡連接的偽客戶端 (fake client)[因為Redis的命令只能在客戶端上下文中執行,而載入AOF文件時所使用的命令直接來源于AOF文件而不是網絡連接,所以服 務器使用了一個沒有網絡連接的偽客戶端來執行AOF文件保存的寫命令,偽客戶端執行命令的效果和帶網絡連接的客戶端執行命令的效果完全一樣。
2、從AOF文件中分析并讀取出一條寫命令。
3、使用偽客戶端執行被讀出的寫命令,一直執行步驟2和步驟3,直到AOF文件中的所有寫命令都被處理完畢為止。
4、當完成以上步驟之后,AOF文件所保存的數據庫狀態就會被完整地還原出來,整個過程如下圖所示:
2.8 AOF配置
#二. AOF存儲
#1.默認是關閉的,日志記錄的方式,可以記錄每一條命令的操作。可以每一次命令操作后,持久化數據,啟用的話通常使用每隔一秒持久化一次的策略appendonly no(默認no) --> appendonly yes (開啟aof)
# appendfsync always #每一次操作都進行持久化appendfsync everysec #每隔一秒進行一次持久化
# appendfsync no # 不進行持久化
#2. aof文件路徑 (默認為當前目錄下,文件名為 appendonly.aof)
appendfilename "appendonly.aof"
dir ./ (同上)
#3. 控制觸發自動重寫機制頻率
# auto-aof-rewrite-min-size 64mb //aof文件至少要達到64M才會自動重寫,文件太小恢復速度本來就很快,重寫的意義不大
# auto-aof-rewrite-percentage 100 //aof文件自上一次重寫后文件大小增長了100%則再次觸發重寫 三、混合持久化
3.1 混合持久化介紹及配置
?????????RDB和AOF各有優缺點,Redis 4.0 開始支持 rdb 和 aof 的混合持久化,5.0以后默認開啟。如果把混合持久化打開,AOF Rewrite 的時候就直接把 RDB 的內容寫到 aof 文件開頭。(RDB的頭+AOF的身體---->appendonly.aof)
開啟混合持久化
#三. 混合持久化
#1. 開啟混合持久化配置 (5.0版本默認就是yes)
aof-use-rdb-preamble yes
#2. rdb和aof自身的配置也都需要開啟3.2 混合持久化原理?
????????開啟了混合持久化,AOF在重寫時,不再是單純將內存數據轉換為RESP命令寫入AOF文件。
1、重寫這一刻之前的內存做RDB快照處理(重寫期間執行的指令和之后的指令仍然是轉換成resp指令吸入aof文件)。
2、將RDB快照內容和增量的AOF修改內存數據的命令存在一起,都寫入新的AOF文件,新的文件一開始不叫appendonly.aof,等到重寫完新的AOF文件才會進行改名,會覆蓋原有的AOF文件,完成新舊兩個AOF文件的替換。
3、Redis重啟的時候,可以先加載RDB的內容,然后再重放增量AOF日志就可以完全替代之前的AOF全量文件重放,因此重啟效率大幅得到提升。
3.3 演示
(3). 演示
A. 開啟混合持久化機制 【aof-use-rdb-preamble yes】
B. 運行指令【bgrewriteaof】手動進行aof重寫(前提內存中有內容),此時查看aof文件中的內容,類似亂碼的東西,就是rdb快照處理。

C. 再任意執行幾個set指令,然后查看aof文件中內容。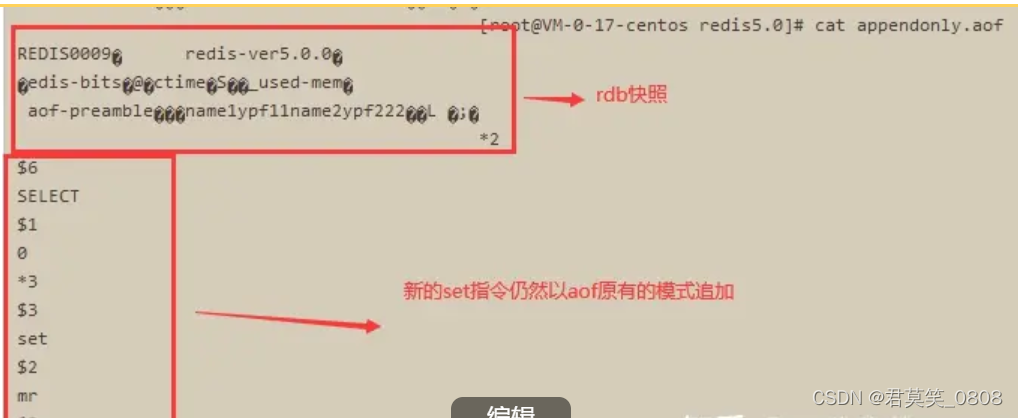
四、應用場景
1、內存數據庫 rdb+aof 數據不容易丟。
2、有原始數據源: 每次啟動時都從原始數據源中初始化 ,則不用開啟持久化(數據量較小)
3、緩存服務器一般性能高rdb
4、在數據還原時:
?? ?有rdb+aof 則還原aof,因為RDB會造成文件的丟失,AOF相對數據要完整。
?? ?只有rdb,則還原rdb。
五、實際場景?
1、追求高性能: 都不開redis宕機從數據源恢復。
2、字典庫:不驅逐,保證數據完整性,不開持久化。
3、用作DB不能主從 數據量小。
4、做緩存 較高性能: 開rdb。
5、Redis數據量存儲過大,性能突然下降:?fork 時間過長 阻塞主進程,則只開啟AOF。





TCP并發服務器模型)





![[NLP]LLM 訓練時GPU顯存耗用量估計](http://pic.xiahunao.cn/[NLP]LLM 訓練時GPU顯存耗用量估計)




)


