NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage
伊利諾伊大學芝加哥分校
Hassan W U, Guo S, Li D, et al. Nodoze: Combatting threat alert fatigue with automated provenance triage[C]//network and distributed systems security symposium. 2019.
目錄
- 0. 摘要
- 1. 引言
- 2. 背景和動機
- A. 攻擊實例
- B. 現有工具的局限性
- C. 目標
- 3. NODOZE 概述和方法
- 4. 威脅模型和假設
- 5. 問題定義
- A. 定義
- B. 問題描述
- 6. 算法
- A. 道路地圖
- B. 異常分數傳播
- C. IN 和 OUT 分數計算
- D. 異常評分歸一化
- E. 路徑融合
- F. 決策
- G. 時間復雜度
- 7. 實現
- A. 事件頻率庫
- B. 警報分類和圖構建
- C. 可視化模塊
- 8. 評估
0. 摘要
??威脅警報疲勞”或信息過載問題:網絡分析師會在大量錯誤警報的噪音中錯過真正的攻擊警報。
??NODOZE 首先生成警報事件的因果關系圖。然后,它根據相關事件在企業中之前發生的頻率,為依賴圖中的每條邊分配一個異常分數。然后使用一種新穎的網絡擴散算法沿著圖的相鄰邊緣傳播這些分數,并生成用于分類的聚合異常分數。
??在美國 NEC 實驗室部署并評估了 NODOZE,根據聚合異常分數始終將真實警報排名高于虛假警報,過引入異常分數的截止閾值,我們估計我們的系統將誤報數量減少了 84%,每周為分析師節省 90 多個小時的調查時間。
??生成的警報依賴關系圖比傳統工具生成的警報依賴關系圖小兩個數量級,而不會犧牲調查所需的重要信息。系統平均運行時開銷較低,可以與任何威脅檢測軟件一起部署。
1. 引言
??在許多情況下,如果調查人員只檢查單個事件,則錯誤警報可能看起來與真實警報非常相似。例如,由于勒索軟件和 ZIP 程序都在短時間內讀寫許多文件,因此僅檢查單個進程行為的簡單勒索軟件檢測器可以輕松地將 ZIP 歸類為勒索軟件。現有的 TDS 通常不會提供足夠的有關警報的上下文信息。
??數據來源分析是威脅警報疲勞問題的一種可能補救措施。數據來源可以通過重建導致警報的事件(向后跟蹤)和警報事件的后果(前向跟蹤)鏈來提供有關生成的警報的上下文信息,以更好地將良性系統事件與惡意事件區分開來。但利用數據來源對警報進行分類有兩個關鍵限制:1) 勞動密集——使用現有技術仍然需要網絡分析師手動評估每個警報的來源數據,以消除誤報,以及2) 依賴爆炸問題——由于現代系統的復雜性,當前的來源跟蹤技術將包括錯誤的依賴,因為輸出事件被假定為因果依賴于所有先前的輸入事件。
??NODOZE 利用歷史背景自動降低現有 TDS 的誤報率。 NODOZE 通過解決上述現有起源分析技術的兩個局限性來實現這一點:它是完全自動化的,并且可以在保持真實攻擊場景的同時大大減少依賴圖的大小。
??起源圖中每個事件的可疑性應根據圖中相鄰事件的可疑性進行調整。由另一個可疑進程創建的進程比由良性進程創建的進程更可疑。
??我們的異常分數分配算法是一種沒有訓練階段的無監督算法。為了給事件分配異常分數,NODOZE 構建了一個事件頻率數據庫,其中存儲了企業中之前發生的所有事件的頻率。在分配異常分數后,NODOZE 使用一種新穎的網絡擴散算法來有效地傳播和聚合警報依賴圖的相鄰邊(事件)上的分數。最后,它為用于分類的候選警報生成一個聚合異常分數。
??為了解決警報調查過程中的依賴爆炸問題,我們提出了行為執行分區的概念。這個想法是根據正常和異常行為對程序執行進行分區,并生成真實警報的最異常依賴圖。
??我們分別在 9K 和 4K 行 Java 代碼中實現了 NODOZE 和事件頻率數據庫。在美國 NEC 實驗室部署并評估了我們的系統。跨越 5 天的 10 億個系統事件,生成了 364 個警報,包括 10 個 APT 攻擊案例和 40 個最近的惡意軟件模擬。NODOZE 通過將誤報減少 84% 來提高現有 TDS 的準確性。
2. 背景和動機
??使用一個攻擊示例來說明 NODOZE 作為警報分類系統的有效性和實用性,包括兩個方面:1)過濾掉誤報以減少警報疲勞,以及 2)使用依賴圖簡明地解釋真實警報加快警報調查過程。
A. 攻擊實例
??無知的工作人員下載了惡意軟件,網絡分析師下載診斷工具。二者皆產生了警報且無法區分。
??略……,作者旨在說明單從警報來看,真實惡意行為的警報和誤報沒有區別。
網絡分析師為什么要從網上下載診斷工具?不都是跑現場嗎?
B. 現有工具的局限性
??現有的來源追蹤器與 TDS 結合用于警報分類和調查過程時會受到以下限制:
- 警報爆炸和依賴人工:
- 依賴爆炸:依賴性不準確主要是由長時間運行的進程引起的,這些進程在其生命周期內與許多主體/對象進行交互。現有方法將整個進程執行視為單個節點,以便所有輸入/輸出交互成為流程節點的邊。這會導致相當大且不準確的圖。
??考慮我們示例依賴圖中的 Internet Explorer IExplorer.exe 頂點,如圖 2a 所示。當網絡分析師試圖找到下載的惡意軟件文件 (springs.7zip) 和診斷工具文件 (collect-info.ps1) 的祖先時,他們將無法確定哪個傳入 IP/套接字連接頂點與惡意軟件文件相關,以及哪個屬于診斷工具文件。
 ??依賴爆炸問題的先前解決方案建議將長時間運行的流程的執行劃分為自治“單元”,以便在輸入和輸出事件之間提供更精確的因果依賴關系。但是,這些系統需要最終用戶參與和通過源代碼檢測、使用典型工作負載訓練應用程序運行以及修改內核來更改系統。由于專有軟件和許可協議,代碼檢測在企業中通常是不可能的。此外,這些系統僅針對 Linux 實現,它們的設計不適用于像 Microsoft Windows 這樣的商用現成操作系統。最后,獲取異構大型企業中的典型應用程序工作負載實際上是不可行的。
??依賴爆炸問題的先前解決方案建議將長時間運行的流程的執行劃分為自治“單元”,以便在輸入和輸出事件之間提供更精確的因果依賴關系。但是,這些系統需要最終用戶參與和通過源代碼檢測、使用典型工作負載訓練應用程序運行以及修改內核來更改系統。由于專有軟件和許可協議,代碼檢測在企業中通常是不可能的。此外,這些系統僅針對 Linux 實現,它們的設計不適用于像 Microsoft Windows 這樣的商用現成操作系統。最后,獲取異構大型企業中的典型應用程序工作負載實際上是不可行的。
C. 目標
- 警報減少:減少誤報、漏報和不可操作的項目。
- 簡潔的上下文警報:生成的威脅警報依賴圖應該簡潔完整。
- 通用性:應該獨立于底層平臺(例如 OS、VM 等)、應用程序和 TDS。
- 實用性:應該不需要任何終端系統更改,并且應該可以部署在任何現有的 TDS 上。
3. NODOZE 概述和方法

??NODOZE 充當現有 TDS 的附加組件,以減少誤報并提供生成的威脅警報的上下文解釋。為了對警報進行分類,NODOZE 首先為生成的警報來源圖中的每個事件分配一個異常分數。然后使用一種新穎的網絡擴散算法來傳播和聚合沿相鄰事件的異常分數。最后,它為生成的警報生成一個聚合異常分數,用于分類。
??在圖 2a 中,有兩個威脅警報事件由 E1 和 E2 注釋,并用虛線箭頭顯示。單獨查看這些警報事件,它們看起來很相似(都與重要的內部主機建立套接字連接)。然而,當我們使用后向和前向追蹤來考慮每個警報事件的祖先和后代時,我們可以看到每個警報事件的行為都明顯不同。
??為了確定威脅警報是真正的攻擊還是誤報,NODOZE 使用異常分數來量化過去發生的相關事件的“罕見性”或轉移概率。例如,警報事件 E1 的后代,即 dropper.exe → y.y.y.y:445 由幾個更罕見的事件組成,即具有較低的轉換概率。警報事件 E2 的祖先包含診斷事件,例如定期執行的 Tasklist 和 Ipconfig,以檢查企業中計算機的健康狀況。因此,E2 的總異常分數將大大低于 E2 的異常分數。
??一旦 NODOZE 為警報事件分配了威脅分數,它從具有最高異常分數的依賴圖中提取子圖,真實警報 E1 的依賴圖如圖 2b 所示。雖然 IExplorer.exe 收到了多個套接字連接,但 NODOZE 只選擇了罕見的 IP 地址 a.a.a.a(從中下載惡意軟件的惡意網站)和 b.b.b.b,因為它們的異常分數高于其他正常套接字連接。
4. 威脅模型和假設
- 假設攻擊者無法操縱或刪除出處記錄,即始終保持日志完整性
- 不考慮使用不通過系統調用接口的隱式流(側通道)執行的攻擊
- 不跟蹤利用內核漏洞的攻擊
- 假設底層 TDS 的檢測率是完整的
- 假設至少有一個事件在 alert 的祖先或后代中是異常的,將其歸類為真正的攻擊
- 不考慮模仿攻擊
5. 問題定義
A. 定義
- 依賴事件:經典三元組,主體客體和關系
- 依賴路徑:依賴事件 Ea 的依賴路徑 P 表示導致 Ea 的事件鏈和由 Ea 引發的事件鏈(即事件本身及其前后因果事件)。分為數據依賴和控制依賴


- 依賴圖:
- 真正的警報依賴關系圖:進行執行分區劃分后的圖,剔除掉了錯誤依賴。
B. 問題描述
??給定 n 個警報事件列表 E 1 , E 2 , . . . , E n {E_1, E_2, ..., E_n} E1?,E2?,...,En? 和用戶指定的閾值參數 τ l τ_l τl? 和 τ d τ_d τd?,我們的目標是根據它們的異常分數對這些警報進行排名,并過濾掉所有異常分數小于 τ d τ_d τd? 的警報作為誤報。
6. 算法
A. 道路地圖
??分配異常分數的一種簡單方法是使用過去發生的系統事件的頻率,這樣組織中罕見的事件被認為更異常。然而,有時這種假設可能不成立,因為攻擊可能涉及經常發生的事件。因此,我們的目標是定義異常分數,而不是僅基于依賴路徑中的單個事件,而是基于整個路徑。
B. 異常分數傳播
??給定警報事件 E α E_α Eα? 的完整依賴圖 G,我們找到 E α E_α Eα? 的所有長度為 τ l τ_l τl? 的依賴路徑。為此,我們從警報事件開始以前后方式運行深度優先遍歷,然后將這些后向和前向路徑組合起來生成統一路徑,以便每個統一路徑都包含警報的祖先和后代因果事件。
??為了計算異常分數,我們首先為給定的警報事件依賴圖 G 構造一個 N × N 轉移概率矩陣 M,其中 N 是 G 中的頂點總數。每個矩陣條目 Mε 由以下等式計算: M ε = p r o b a b i l i t y ( ε ) = ∣ F r e q ( ε ) ∣ ∣ F r e q s r c r e l ( ε ) ∣ M_{\varepsilon}=probability(\varepsilon)=\frac{|Freq(\varepsilon)|}{|Freqsrc_rel(\varepsilon)|} Mε?=probability(ε)=∣Freqsrcr?el(ε)∣∣Freq(ε)∣?,其中 F r e q Freq Freq 為發生次數。為了統計過去發生的事件的頻率,我們建立了一個事件頻率數據庫,定期存儲和更新整個企業的事件頻率。
??給定事件的轉移概率告訴我們特定來源流向特定目的地的概率;然而,我們最終將通過圖傳播這個值,但是當我們這樣做時,我們想要考慮從源流出的數據總量,以及流入目的地的數據總量。我們計算依賴圖 G 中每個實體的 IN 和 OUT 分數向量。
最后,正則性得分 R S ( P ) RS(P) RS(P) 計算如下: R S ( P ) = ∏ i = 1 l I N ( S R C i ) × M ( ε i ) × O U T ( D S T i ) RS(P)=\prod\limits_{i=1}^{l}IN(SRC_i)\times M(\varepsilon_i)\times OUT(DST_i) RS(P)=i=1∏l?IN(SRCi?)×M(εi?)×OUT(DSTi?)異常分數為: A S ( P ) = 1 ? R S ( P ) AS(P)=1-RS(P) AS(P)=1?RS(P)

C. IN 和 OUT 分數計算
??我們根據每個實體的類型為每個實體填充 IN 和 OUT 分數。
- 進程實體:劃分很多個時間窗口,如果時間窗口內沒有新邊加入,則視為穩定窗口,一個實體的IN分數和OUT分數均為穩定窗口與窗口總數之比。
I N ( v ) = ∣ T t o ′ ∣ ∣ T ∣ O U T ( v ) = ∣ T f r o m ′ ∣ ∣ T ∣ IN(v)=\frac{|T_{to}^{\prime}|}{|T|}\quad\quad OUT(v)=\frac{|T_{from}^{\prime}|}{|T|}\quad IN(v)=∣T∣∣Tto′?∣?OUT(v)=∣T∣∣Tfrom′?∣? - 數據實體:數據實體主要是文件和網絡鏈接。進一步細分為三類:臨時文件、可執行文件和已知的惡意擴展。臨時文件給很高的分,用先驗知識給可執行文件、惡意擴展、惡意ip低分,其余實體0.5分
D. 異常評分歸一化
由于單純的疊加會導致長路徑的分數高于短路徑,所以引入一個衰減因子用以歸一化。
R S ( P ) = ∏ i = 1 l I N ( S R C i ) × M ( ε i ) × O U T ( D S T i ) × α RS(P)=\prod\limits_{i=1}^lIN(SRC_i)\times M(\varepsilon_i)\times OUT(DST_i)\times\alpha RS(P)=i=1∏l?IN(SRCi?)×M(εi?)×OUT(DSTi?)×α
E. 路徑融合
該步驟試圖通過只包含具有高異常分數的依賴路徑來構建一個準確的真正警報依賴圖,通過合并,盡量減少路徑的數量,進一步保證靠前的路徑構建出來的子圖包含大部分惡意行為。

F. 決策
NODOZE的主要目標是對給定時間線中的所有警報進行排序。然而,我們也可以計算一個決策或截斷閾值τd,它可以用來確定候選威脅警報是真攻擊還是高置信度的假警報。
G. 時間復雜度
每次根據給定警報進行兩次固定深度的DFS,一次向前一次向后。時間復雜度為 O ( ∣ b D ∣ \mathcal{O}(|b^{D}| O(∣bD∣,取決于節點的分支數和搜索的深度。
7. 實現
Windows ETW + Linux Auditd、PostgreSQL database
a)事件頻率數據庫生成器,b)警報分類和圖形生成器,以及c)可視化模塊
A. 事件頻率庫
- 進程實體:進程路徑、命令行參數、組標識gid
- 文件實體:抽象文件路徑(刪除特定用戶信息)
- socket實體:保留外部地址,抽象內部地址
B. 警報分類和圖構建
- 合并瞬時進程:有些進程的存在意義僅為喚起另一進程,這種情況將二者合并
- 合并相同套接字:由同一進程發起的相同地址的套接字合并
C. 可視化模塊
使用GraphViz生成點格式的因果圖,然后將點文件轉換為html格式
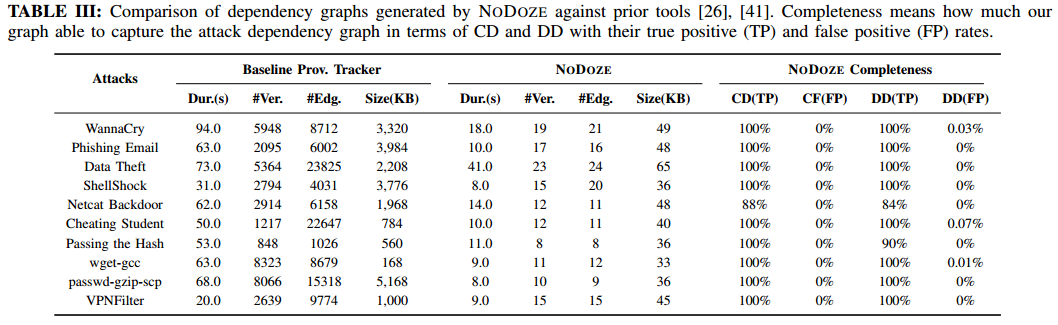
8. 評估
準確率:設定當設置閾值使得決策為100%檢測真陽性時,假陽性為16%。換句話說,誤報減少84%。


依賴圖減少程度:減少兩個數量級
節省多少人工時間:假設每個假警報花20分鐘,過濾掉84%,約90個小時。
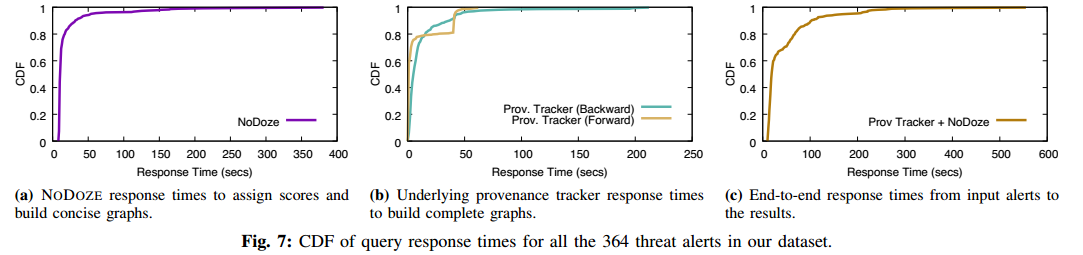
運行開銷:

用戶列表查詢接口(上))

)





)
視頻介紹)








