題目描述:
Given two strings A and B, whose alphabet consist only ‘0’ and ‘1’. Your task is only to tell how many times does A appear as a substring of B? For example, the text string B is ‘1001110110’ while the pattern string A is ‘11’, you should output 3, because the pattern A appeared at the posit
輸入描述:
The first line consist only one integer N, indicates N cases follows. In each case, there are two lines, the first line gives the string A, length (A) <= 10, and the second line gives the string B, length (B) <= 1000. And it is guaranteed that B is always longer than A.
輸出描述:
For each case, output a single line consist a single integer, tells how many times do B appears as a substring of A.
樣例輸入:
3
11
1001110110
101
110010010010001
1010
110100010101011
樣例輸出:
3
0
3
翻譯如下:
題目描述:
給定兩個字符串A和B,其字母表僅包含’0’和’1’。你的任務只是告訴A多少次出現在B的子串中?例如,文本字符串B是’1001110110’,而模式字符串A是’11’,你應該輸出3,因為模式A出現在文本字符串B里面三次
輸入描述:
第一行僅包含一個整數N,表示N個案例。在每種情況下,有兩行,第一行給出字符串A,長度(A)<= 10,第二行給出字符串B,長度(B)<= 1000.并保證B總是比A.更長
輸出描述:
對于每種情況,輸出一行包含一個整數,表示B作為A的子串出現的次數。
代碼如下:
#include<iostream>#include<string>using namespace std;int main(){int N;int t,i;string s,a,b;cin>>N;while(N--) {t=0;i=0;cin>>a>>b;while((i=b.find(a,i))!=(string::npos)) {t++;i++;}cout<<t<<endl;}return 0;}補充如下:
① i=b.find(a,i)
這個意思是,在字符串b中查找字符串a,從字符串b中的第i個元素開始查找,將返回的int型數值重新賦值給i。
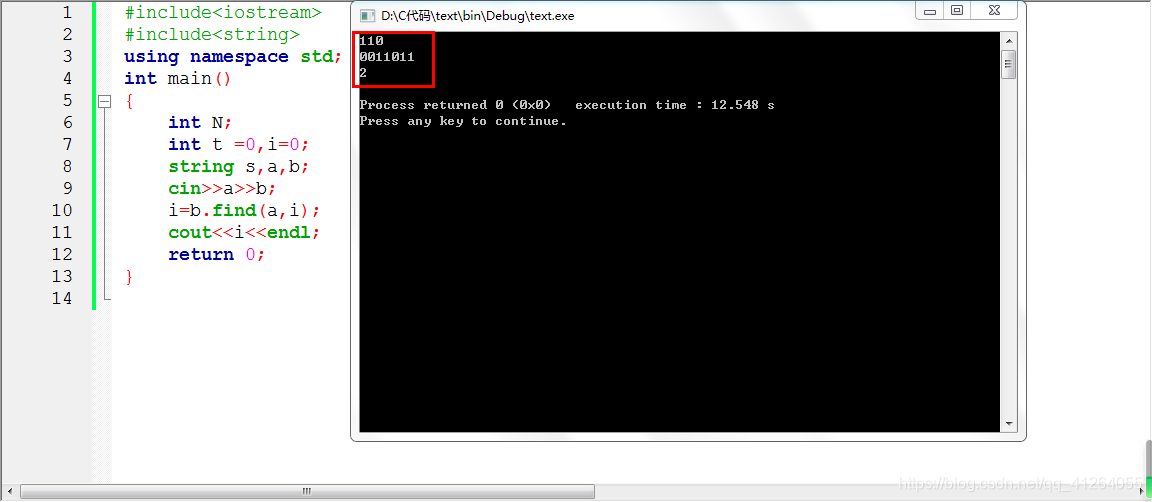
例如:
輸入
110
0011011
輸出
2
也就是說,如果b字符串里面包含a字符串,則輸出字符串a的第一個元素的下標

若字符串b里面沒有a這個字符串,則返回-1。
該函數在本程序算法中的作用在于:以次將字符串a從字符串b里面查找,若從字符串b里面找到字符串a,則返回字符串a的第一個字符的下標,接著從字符串b里面找。
②string::npos
string::npos 這個特殊值,說明查找沒有匹配。
string::npos 就是一個長度參數,表示直到字符串的結束
string 類將 npos 定義為保證大于任何有效下標的值
string::npos是string容器的一種屬性
整體來講就是說
i=b.find(a,i))!=(string::npos)
這行代碼的意思就是:從字符串b里面查找字符串a,若找到返回字符串a的第一個字符在字符串b里面的下標,直到字符串的結束為止。









 轉)
)


)





