1、使用標準庫urllib爬取“http://news.pdsu.edu.cn/info/1005/31269.htm”平頂山學院新聞網上的圖片,要求:保存到F盤pic目錄中,文件名稱命名規則為“本人姓名”+ “_圖片編號”,如姓名為張三的第一張圖片命名為“張三_1.jpg”。
from re import findall
from urllib.request import urlopenurl = 'http://news.pdsu.edu.cn/info/1005/31269.htm'
with urlopen(url) as fp:content=fp.read().decode('utf-8')pattern = '<img width="500" src="(.+?)"'
#查找所有圖片鏈接地址
result = findall(pattern, content) #捕獲分組
#逐個讀取圖片數據,并寫入本地文件
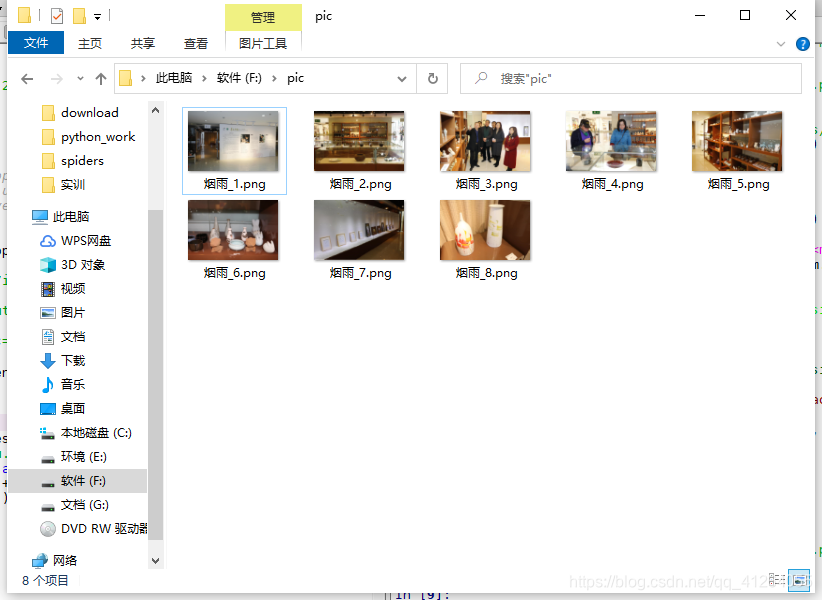
path='f:/pic/'
name="煙雨"
for index, item in enumerate(result):picture = 'http://news.pdsu.edu.cn/' + itemwith urlopen(str(picture)) as fp:with open(path+name+'_'+str(index+1)+'.png','wb') as fp1: #這里因為是從1開始,這里注意下fp1.write(fp.read())
效果圖如下:
2、采用scrapy爬蟲框架,抓取平頂山學院新聞網(http://news.pdsu.edu.cn/)站上的內容,具體要求:抓取新聞欄目,將結果寫入lm.txt。
cmd打開之后就別關了
scrapy startproject wsqwsq為項目名
cd wsq
scrapy genspider lm news.pdsu.edu.cnlm為爬蟲名稱,pdsu.edu.cn為爬取起始位置
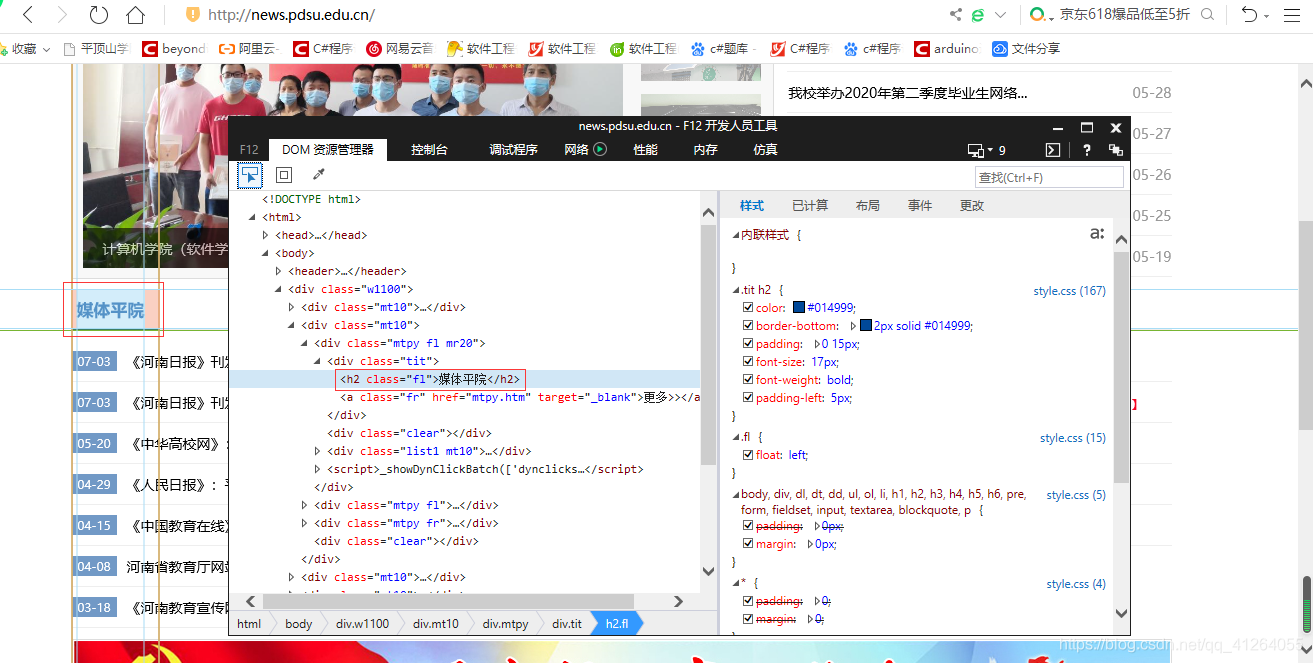
分析:編寫正確的正則表達式篩選信息
由關鍵信息:<h2 class="fl">媒體平院</h2>
篩選其正則表達式如下:soup.find_all('h2', class_='fl')
找到lm.py也就是上面創建的爬蟲
編輯:將下面代碼負責粘貼下
pip install beautifulsoup4
pip install scrapy
倆第三方庫要安裝下
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
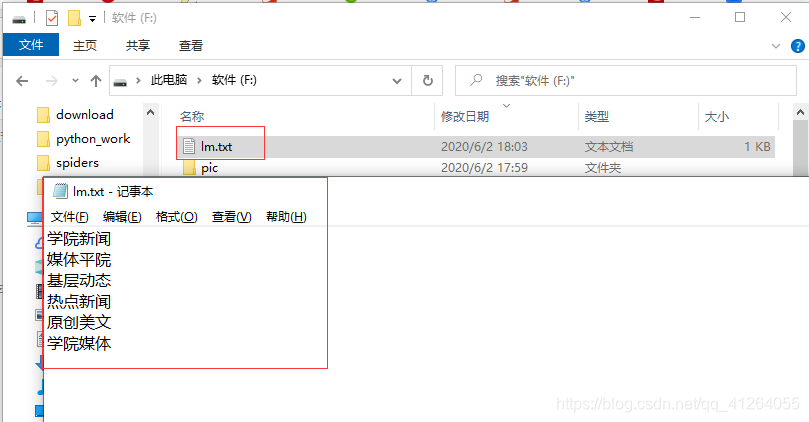
import re class LmmSpider(scrapy.Spider):name = 'lmm'allowed_domains = ['pdsu.cn']start_urls = ['http://news.pdsu.edu.cn/']def parse(self, response):html_doc=response.textsoup= BeautifulSoup(html_doc, 'html.parser') re=soup.find_all('h2', class_='fl')content=''for lm in re:print(lm.text)content+=lm.text+'\n'with open('f:\\lm.txt', 'a+') as fp:fp.writelines(content)#保存路徑可變
scrapy crawl lmlm為爬蟲名稱
效果圖如下:
3、采用request爬蟲模塊,抓取平頂山學院網絡教學平臺上的Python語言及應用課程上的每一章標題(http://mooc1.chaoxing.com/course/206046270.html)。
cmd打開之后就別關了
scrapy startproject yyyy為項目名
cd yy
scrapy genspider beyond news.mooc1.chaoxing.com/course/206046270.htmlbeyond為爬蟲名稱,mooc1.chaoxing.com/course/206046270.html為爬取起始位置
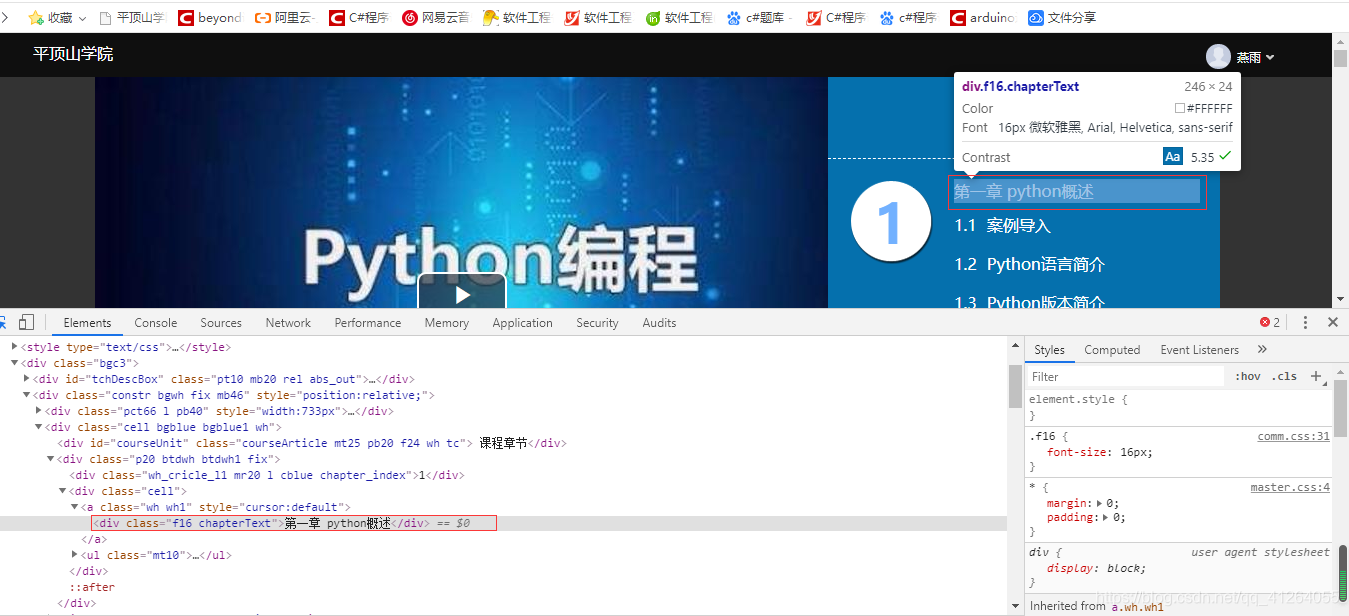
分析:編寫正確的正則表達式篩選信息
由關鍵信息:<div class="f16 chapterText">第一章 python概述</div>
篩選其正則表達式如下:soup.findAll('div',class_='f16 chapterText')
找到beyond.py也就是上面創建的爬蟲
編輯:將下面代碼負責粘貼下
# -*- coding: utf-8 -*-
import scrapy
import re
import requests
import bs4headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}url='http://mooc1.chaoxing.com/course/206046270.html'
response = requests.get(url,headers=headers).text
soup = bs4.BeautifulSoup(response,'html.parser')
t=soup.findAll('div',class_='f16 chapterText')
for ml in t:print (ml.text)效果圖如下:

)

![[轉載]FPGA/CPLD重要設計思想及工程應用(時序及同步設計)](http://pic.xiahunao.cn/[轉載]FPGA/CPLD重要設計思想及工程應用(時序及同步設計))
方法與示例)





——Linux分區和目錄結構)

、crop filter(裁剪)、vflip filter(垂直向上的翻轉)、overlay filter(合成))




函數的sep參數)
)

