 ??Java大聯盟
??Java大聯盟? 致力于最高效的Java學習
關注
作者 | 田小波
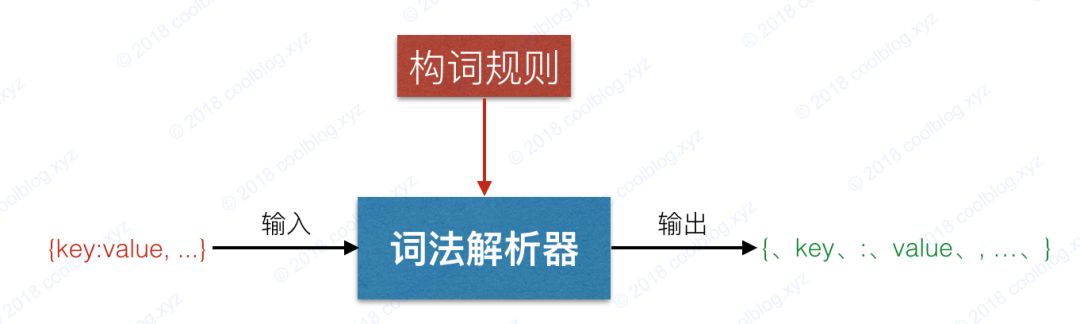
cnblogs.com/nullllun/p/8358146.html1、背景JSON(JavaScript Object Notation) 是一種輕量級的數據交換格式。相對于另一種數據交換格式 XML,JSON 有著諸多優點。比如易讀性更好,占用空間更少等。在 web 應用開發領域內,得益于 JavaScript 對 JSON 提供的良好支持,JSON 要比 XML 更受開發人員青睞。所以作為開發人員,如果有興趣的話,還是應該深入了解一下 JSON 相關的知識。本著探究 JSON 原理的目的,我將會在這篇文章中詳細向大家介紹一個簡單的JSON解析器的解析流程和實現細節。由于 JSON 本身比較簡單,解析起來也并不復雜。所以如果大家感興趣的話,在看完本文后,不妨自己動手實現一個 JSON 解析器。好了,其他的話就不多說了,接下來讓我們移步到重點章節吧。2. JSON 解析器實現原理JSON 解析器從本質上來說就是根據 JSON 文法規則創建的狀態機,輸入是一個 JSON 字符串,輸出是一個 JSON 對象。一般來說,解析過程包括詞法分析和語法分析兩個階段。詞法分析階段的目標是按照構詞規則將 JSON 字符串解析成 Token 流,比如有如下的 JSON 字符串:{
????"name"?:?"小明",
????"age":?18
}
{、 name、 :、 小明、 ,、 age、 :、 18、 }
{
????"name",?"小明"
}
當詞法分析器讀取的詞是上面類型中的一種時,即可將其解析成一個 Token。我們可以定義一個枚舉類來表示上面的數據類型,如下:
BEGIN_OBJECT({)
END_OBJECT(})
BEGIN_ARRAY([)
END_ARRAY(])
NULL(null)
NUMBER(數字)
STRING(字符串)
BOOLEAN(true/false)
SEP_COLON(:)
SEP_COMMA(,)
public?enum?TokenType?{
????BEGIN_OBJECT(1),
????END_OBJECT(2),
????BEGIN_ARRAY(4),
????END_ARRAY(8),
????NULL(16),
????NUMBER(32),
????STRING(64),
????BOOLEAN(128),
????SEP_COLON(256),
????SEP_COMMA(512),
????END_DOCUMENT(1024);
????TokenType(int?code)?{
????????this.code?=?code;
????}
????private?int?code;
????public?int?getTokenCode()?{
????????return?code;
????}
}public?class?Token?{
????private?TokenType?tokenType;
????private?String?value;
????//?省略不重要的代碼
}public?CharReader(Reader?reader)?{
????????this.reader?=?reader;
????????buffer?=?new?char[BUFFER_SIZE];
????}
????/**
?????*?返回?pos?下標處的字符,并返回
?????*?@return?
?????*?@throws?IOException
?????*/
????public?char?peek()?throws?IOException?{
????????if?(pos?-?1?>=?size)?{
????????????return?(char)?-1;
????????}
????????return?buffer[Math.max(0,?pos?-?1)];
????}
????/**
?????*?返回?pos?下標處的字符,并將?pos?+?1,最后返回字符
?????*?@return?
?????*?@throws?IOException
?????*/
????public?char?next()?throws?IOException?{
????????if?(!hasMore())?{
????????????return?(char)?-1;
????????}
????????return?buffer[pos++];
????}
????public?void?back()?{
????????pos?=?Math.max(0,?--pos);
????}
????public?boolean?hasMore()?throws?IOException?{
????????if?(pos?????????????return?true;
????????}
????????fillBuffer();
????????return?pos?????}
????void?fillBuffer()?throws?IOException?{
????????int?n?=?reader.read(buffer);
????????if?(n?==?-1)?{
????????????return;
????????}
????????pos?=?0;
????????size?=?n;
????}
public?class?Tokenizer?{
????private?CharReader?charReader;
????private?TokenList?tokens;
????public?TokenList?tokenize(CharReader?charReader)?throws?IOException?{
????????this.charReader?=?charReader;
????????tokens?=?new?TokenList();
????????tokenize();
????????return?tokens;
????}
????private?void?tokenize()?throws?IOException?{
????????//?使用do-while處理空文件
????????Token?token;
????????do?{
????????????token?=?start();
????????????tokens.add(token);
????????}?while?(token.getTokenType()?!=?TokenType.END_DOCUMENT);
????}
????private?Token?start()?throws?IOException?{
????????char?ch;
????????for(;;)?{
????????????if?(!charReader.hasMore())?{
????????????????return?new?Token(TokenType.END_DOCUMENT,?null);
????????????}
????????????ch?=?charReader.next();
????????????if?(!isWhiteSpace(ch))?{
????????????????break;
????????????}
????????}
????????switch?(ch)?{
????????????case?'{':
????????????????return?new?Token(TokenType.BEGIN_OBJECT,?String.valueOf(ch));
????????????case?'}':
????????????????return?new?Token(TokenType.END_OBJECT,?String.valueOf(ch));
????????????case?'[':
????????????????return?new?Token(TokenType.BEGIN_ARRAY,?String.valueOf(ch));
????????????case?']':
????????????????return?new?Token(TokenType.END_ARRAY,?String.valueOf(ch));
????????????case?',':
????????????????return?new?Token(TokenType.SEP_COMMA,?String.valueOf(ch));
????????????case?':':
????????????????return?new?Token(TokenType.SEP_COLON,?String.valueOf(ch));
????????????case?'n':
????????????????return?readNull();
????????????case?'t':
????????????case?'f':
????????????????return?readBoolean();
????????????case?'"':
????????????????return?readString();
????????????case?'-':
????????????????return?readNumber();
????????}
????????if?(isDigit(ch))?{
????????????return?readNumber();
????????}
????????throw?new?JsonParseException("Illegal?character");
????}
????private?Token?readNull()?{...}
????private?Token?readBoolean()?{...}
????private?Token?readString()?{...}
????private?Token?readNumber()?{...}
}
private?Token?readNull()?throws?IOException?{
????if?(!(charReader.next()?==?'u'?&&?charReader.next()?==?'l'?&&?charReader.next()?==?'l'))?{
????????throw?new?JsonParseException("Invalid?json?string");
????}
????return?new?Token(TokenType.NULL,?"null");
}private?Token?readString()?throws?IOException?{
????StringBuilder?sb?=?new?StringBuilder();
????for?(;;)?{
????????char?ch?=?charReader.next();
????????//?處理轉義字符
????????if?(ch?==?'\\')?{
????????????if?(!isEscape())?{
????????????????throw?new?JsonParseException("Invalid?escape?character");
????????????}
????????????sb.append('\\');
????????????ch?=?charReader.peek();
????????????sb.append(ch);
????????????//?處理 Unicode 編碼,形如?\u4e2d。且只支持?\u0000?~?\uFFFF 范圍內的編碼
????????????if?(ch?==?'u')?{
????????????????for?(int?i?=?0;?i?4;?i++)?{
????????????????????ch?=?charReader.next();
????????????????????if?(isHex(ch))?{
????????????????????????sb.append(ch);
????????????????????}?else?{
????????????????????????throw?new?JsonParseException("Invalid?character");
????????????????????}
????????????????}
????????????}
????????}?else?if?(ch?==?'"')?{????//?碰到另一個雙引號,則認為字符串解析結束,返回?Token
????????????return?new?Token(TokenType.STRING,?sb.toString());
????????}?else?if?(ch?==?'\r'?||?ch?==?'\n')?{????//?傳入的?JSON?字符串不允許換行
????????????throw?new?JsonParseException("Invalid?character");
????????}?else?{
????????????sb.append(ch);
????????}
????}
}
private?boolean?isEscape()?throws?IOException?{
????char?ch?=?charReader.next();
????return?(ch?==?'"'?||?ch?==?'\\'?||?ch?==?'u'?||?ch?==?'r'
????????????????||?ch?==?'n'?||?ch?==?'b'?||?ch?==?'t'?||?ch?==?'f');
}
private?boolean?isHex(char?ch)?{
????return?((ch?>=?'0'?&&?ch?<=?'9')?||?('a'?<=?ch?&&?ch?<=?'f')
????????????||?('A'?<=?ch?&&?ch?<=?'F'));
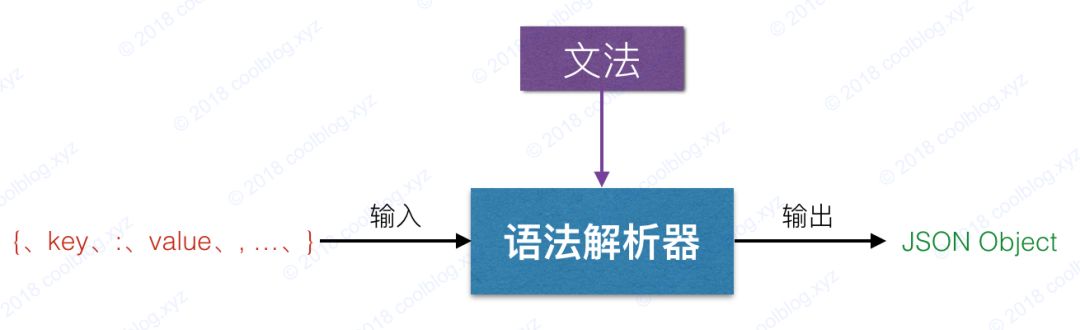
}最后一種特殊字符\/代碼中未做處理,其他字符均做了判斷,判斷邏輯在 isEscape 方法中。在傳入 JSON 字符串中,僅允許字符串包含上面所列的轉義字符。如果亂傳轉義字符,解析時會報錯。對于 STRING 類型的詞,解析過程始于字符",也終于"。所以在解析的過程中,當再次遇到字符",readString 方法會認為本次的字符串解析過程結束,并返回相應類型的 Token。上面說了 null 類型和 string 類型的數據解析過程,過程并不復雜,理解起來應該不難。至于 boolean 和 number 類型的數據解析過程,大家有興趣的話可以自己看源碼,這里就不在說了。2.2 語法分析當詞法分析結束后,且分析過程中沒有拋出錯誤,那么接下來就可以進行語法分析了。語法分析過程以詞法分析階段解析出的 Token 序列作為輸入,輸出 JSON Object 或 JSON Array。語法分析器的實現的文法如下:\"
\
\b
\f
\n
\r
\t
\u four-hex-digits
\/
object?=?{}?|?{?members?}
members?=?pair?|?pair?,?members
pair?=?string?:?value
array?=?[]?|?[?elements?]
elements?=?value??|?value?,?elements
value?=?string?|?number?|?object?|?array?|?true?|?false?|?nullpublic?class?JsonObject?{
????private?Map?map?=?new?HashMap();public?void?put(String?key,?Object?value)?{map.put(key,?value);
????}public?Object?get(String?key)?{return?map.get(key);
????}public?List>?getAllKeyValue()?{return?new?ArrayList<>(map.entrySet());
????}public?JsonObject?getJsonObject(String?key)?{if?(!map.containsKey(key))?{throw?new?IllegalArgumentException("Invalid?key");
????????}
????????Object?obj?=?map.get(key);if?(!(obj?instanceof?JsonObject))?{throw?new?JsonTypeException("Type?of?value?is?not?JsonObject");
????????}return?(JsonObject)?obj;
????}public?JsonArray?getJsonArray(String?key)?{if?(!map.containsKey(key))?{throw?new?IllegalArgumentException("Invalid?key");
????????}
????????Object?obj?=?map.get(key);if?(!(obj?instanceof?JsonArray))?{throw?new?JsonTypeException("Type?of?value?is?not?JsonArray");
????????}return?(JsonArray)?obj;
????}
????@Overridepublic?String?toString()?{return?BeautifyJsonUtils.beautify(this);
????}
}public?class?JsonArray?implements?Iterable?{private?List?list?=?new?ArrayList();public?void?add(Object?obj)?{list.add(obj);
????}public?Object?get(int?index)?{return?list.get(index);
????}public?int?size()?{return?list.size();
????}public?JsonObject?getJsonObject(int?index)?{
????????Object?obj?=?list.get(index);if?(!(obj?instanceof?JsonObject))?{throw?new?JsonTypeException("Type?of?value?is?not?JsonObject");
????????}return?(JsonObject)?obj;
????}public?JsonArray?getJsonArray(int?index)?{
????????Object?obj?=?list.get(index);if?(!(obj?instanceof?JsonArray))?{throw?new?JsonTypeException("Type?of?value?is?not?JsonArray");
????????}return?(JsonArray)?obj;
????}
????@Overridepublic?String?toString()?{return?BeautifyJsonUtils.beautify(this);
????}public?Iterator?iterator()?{return?list.iterator();
????}
}private?JsonObject?parseJsonObject()?{
????JsonObject?jsonObject?=?new?JsonObject();
????int?expectToken?=?STRING_TOKEN?|?END_OBJECT_TOKEN;
????String?key?=?null;
????Object?value?=?null;
????while?(tokens.hasMore())?{
????????Token?token?=?tokens.next();
????????TokenType?tokenType?=?token.getTokenType();
????????String?tokenValue?=?token.getValue();
????????switch?(tokenType)?{
????????case?BEGIN_OBJECT:
????????????checkExpectToken(tokenType,?expectToken);
????????????jsonObject.put(key,?parseJsonObject());????//?遞歸解析?json?object
????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????break;
????????case?END_OBJECT:
????????????checkExpectToken(tokenType,?expectToken);
????????????return?jsonObject;
????????case?BEGIN_ARRAY:????//?解析?json?array
????????????checkExpectToken(tokenType,?expectToken);
????????????jsonObject.put(key,?parseJsonArray());
????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????break;
????????case?NULL:
????????????checkExpectToken(tokenType,?expectToken);
????????????jsonObject.put(key,?null);
????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????break;
????????case?NUMBER:
????????????checkExpectToken(tokenType,?expectToken);
????????????if?(tokenValue.contains(".")?||?tokenValue.contains("e")?||?tokenValue.contains("E"))?{
????????????????jsonObject.put(key,?Double.valueOf(tokenValue));
????????????}?else?{
????????????????Long?num?=?Long.valueOf(tokenValue);
????????????????if?(num?>?Integer.MAX_VALUE?||?num?????????????????????jsonObject.put(key,?num);
????????????????}?else?{
????????????????????jsonObject.put(key,?num.intValue());
????????????????}
????????????}
????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????break;
????????case?BOOLEAN:
????????????checkExpectToken(tokenType,?expectToken);
????????????jsonObject.put(key,?Boolean.valueOf(token.getValue()));
????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????break;
????????case?STRING:
????????????checkExpectToken(tokenType,?expectToken);
????????????Token?preToken?=?tokens.peekPrevious();
????????????/*
?????????????*?在 JSON 中,字符串既可以作為鍵,也可作為值。
?????????????*?作為鍵時,只期待下一個 Token 類型為 SEP_COLON。
?????????????*?作為值時,期待下一個?Token?類型為?SEP_COMMA?或?END_OBJECT
?????????????*/
????????????if?(preToken.getTokenType()?==?TokenType.SEP_COLON)?{
????????????????value?=?token.getValue();
????????????????jsonObject.put(key,?value);
????????????????expectToken?=?SEP_COMMA_TOKEN?|?END_OBJECT_TOKEN;
????????????}?else?{
????????????????key?=?token.getValue();
????????????????expectToken?=?SEP_COLON_TOKEN;
????????????}
????????????break;
????????case?SEP_COLON:
????????????checkExpectToken(tokenType,?expectToken);
????????????expectToken?=?NULL_TOKEN?|?NUMBER_TOKEN?|?BOOLEAN_TOKEN?|?STRING_TOKEN
????????????????????|?BEGIN_OBJECT_TOKEN?|?BEGIN_ARRAY_TOKEN;
????????????break;
????????case?SEP_COMMA:
????????????checkExpectToken(tokenType,?expectToken);
????????????expectToken?=?STRING_TOKEN;
????????????break;
????????case?END_DOCUMENT:
????????????checkExpectToken(tokenType,?expectToken);
????????????return?jsonObject;
????????default:
????????????throw?new?JsonParseException("Unexpected?Token.");
????????}
????}
????throw?new?JsonParseException("Parse?error,?invalid?Token.");
}
private?void?checkExpectToken(TokenType?tokenType,?int?expectToken)?{
????if?((tokenType.getTokenCode()?&?expectToken)?==?0)?{
????????throw?new?JsonParseException("Parse?error,?invalid?Token.");
????}
}
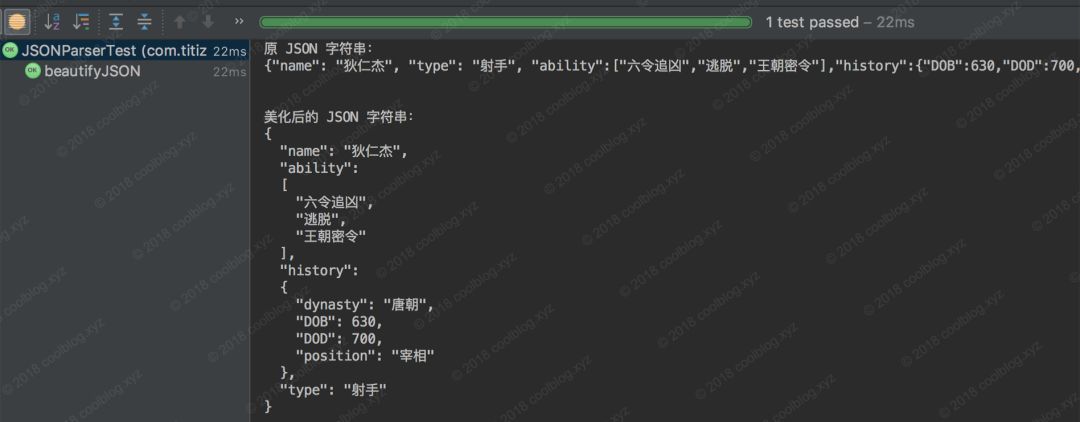
parseJsonObject 解析完?{ Token 后,接下來它將期待 STRING 類型的 Token 或者 END_OBJECT 類型的 Token 出現。于是 parseJsonObject 讀取了一個新的 Token,發現這個 Token 的類型是 STRING 類型,滿足期望。于是 parseJsonObject 更新期望Token 類型為 SEL_COLON,即:。如此循環下去,直至 Token 序列解析結束或者拋出異常退出。上面的解析流程雖然不是很復雜,但在具體實現的過程中,還是需要注意一些細節問題。比如:在 JSON 中,字符串既可以作為鍵,也可以作為值。作為鍵時,語法分析器期待下一個 Token 類型為 SEP_COLON。而作為值時,則期待下一個 Token 類型為 SEP_COMMA 或 END_OBJECT。所以這里要判斷該字符串是作為鍵還是作為值,判斷方法也比較簡單,即判斷上一個 Token 的類型即可。如果上一個 Token 是 SEP_COLON,即:,那么此處的字符串只能作為值了。否則,則只能做為鍵。對于整數類型的 Token 進行解析時,簡單點處理,可以直接將該整數解析成 Long 類型。但考慮到空間占用問題,對于?[Integer.MIN_VALUE, Integer.MAX_VALUE]范圍內的整數來說,解析成 Integer 更為合適,所以解析的過程中也需要注意一下。3. 測試及效果展示為了驗證代碼的正確性,這里對代碼進行了簡單的測試。測試數據來自網易音樂,大約有4.5W個字符。為了避免每次下載數據,因數據發生變化而導致測試不通過的問題。我將某一次下載的數據保存在了 music.json 文件中,后面每次測試都會從文件中讀取數據。關于測試部分,這里就不貼代碼和截圖了。大家有興趣的話,可以自己下載源碼測試玩玩。測試就不多說了,接下來看看 JSON 美化效果展示。這里隨便模擬點數據,就模擬王者榮耀里的狄仁杰英雄信息吧(對,這個英雄我經常用)。如下圖:{、 id、 :、 1、 }
這里需要聲明一下,本文對應的代碼實現了一個比較簡陋的 JSON 解析器,實現的目的是探究 JSON 的解析原理。JSONParser 只算是一個練習性質的項目,代碼實現的并不優美,而且缺乏充足的測試。同時,限于本人的能力(編譯原理基礎基本可以忽略),我并無法保證本文以及對應的代碼中不出現錯誤。如果大家在閱讀代碼的過程中,發現了一些錯誤,或者寫的不好的地方,可以提出來,我來修改。如果這些錯誤對你造成了困擾,這里先說一聲很抱歉。最后,本文及實現主要參考了一起寫一個JSON解析器和如何編寫一個JSON解析器兩篇文章及兩篇文章對應的實現代碼,在這里向著兩篇博文的作者表示感謝。傳送門:https://github.com/code4wt/JSONParser
推薦閱讀
1、一次性把JVM講清楚,別再被面試官問住了
2、axios異步請求數據的12種操作
3、一文搞懂前后端分離
4、快速上手Spring Boot+Vue前后端分離

![[一]設計模式初探](http://pic.xiahunao.cn/[一]設計模式初探)

方法與示例)

)
)


)



方法與示例)



)

函數以及C ++ STL中的示例)
)