計量經濟學模型是從統計學模型中衍生出來的,故將它們一并放在此處進行說明。
實際上,很多人在很久之前就督促我寫一篇統計學和計量經濟學模型的文章,但我太懶惰,一直拖到現在,也是十分汗顏。
先講一些統計學上的基礎故事,主要以豬重估計與沉船搜索為例吧。某個地區每年舉辦一次豬的重量的競猜活動,與真實重量最接近的人獲得獎金。數學家將這些五花八門的競猜數據進行統計,發現其平均值與真實值幾乎相等。第二個例子說的是打撈沉船的事情,讓多個團隊進行設想,并估計船只沉的過程及沉落地,然后將所有的結果進行統計,所得的地點與沉船實際地點很近。
可以看出,統計學還是有一定的意義的。上述的兩個事例僅僅說明了單變量比較準確。實際上,多個變量之間也存在著一定的因果關系。這種情況下,統計學描述這一問題準確嗎。
統計學在這個問題上借鑒了映射的概念,而其中最重要的是函數/方程關系,最簡單的莫過于線性。比如假定一個變量x是另一個變量y的原因,在線性思維的基礎上,這兩個隨機變量大致滿足下列的形式
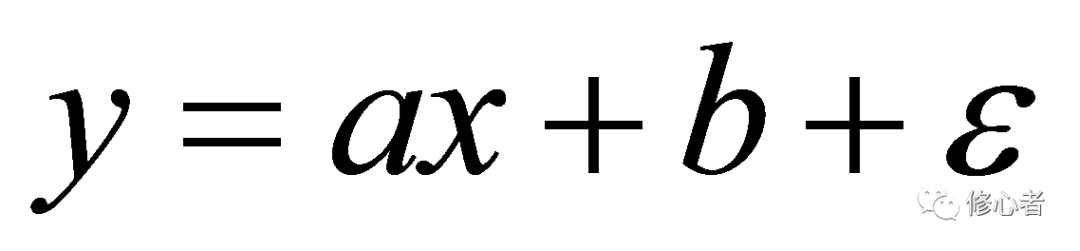 (1)
(1)
由于y與x均是隨機變量,實際測定的數組(x,y)總不落在直線y=ax+b上,而是圍繞著這個直線上下波動。
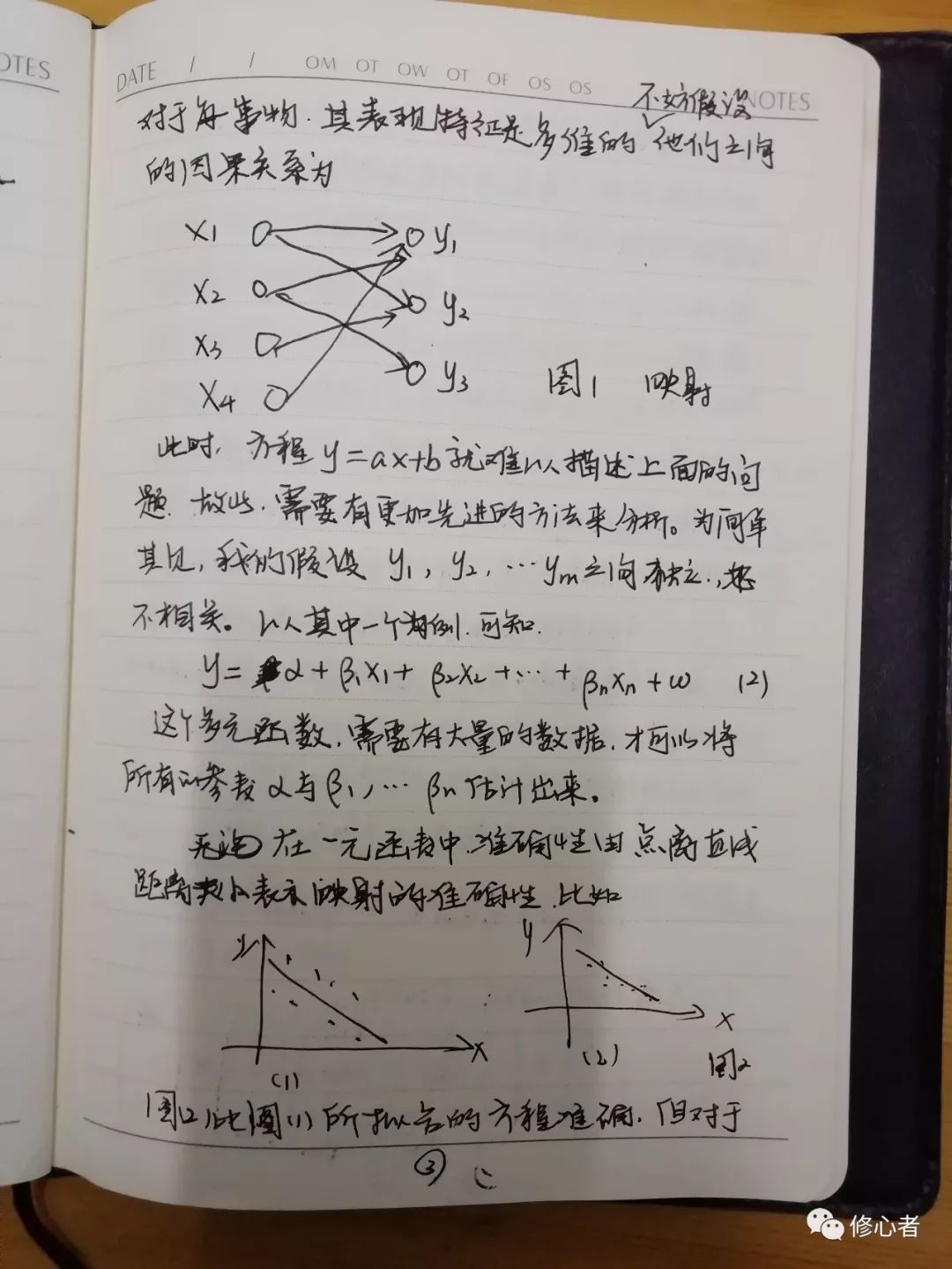
當然,線性化假設不能描述事物的本質,我們往往處在一個非線性的社會之中,非線性現象比比皆是。另外,經濟與管理中,存在著大量的非函數映射關系,這個顯然是y=ax+b無法解釋的。更進一步的,經濟與管理中不是兩個變量所決定的,而是由多個變量所決定,對于每一事物,其表現特征是多維的,不妨假設它們之間的因果關系為
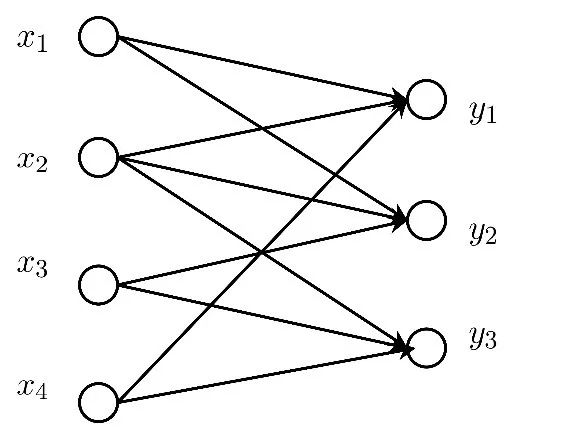
圖1映射
此時,方程y=ax+b就難以描述上面的問題。故此,需要有更加先進的方法來分析。為簡單起見,我們假設y1,y2,……ym之間獨立,互不相關。以其中一個為例,可知
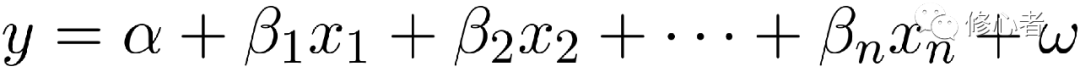 ? ?(2)
? ?(2)
這個多元函數,需要有大量的數據,才可以將所有的參數?與,……估計出來。
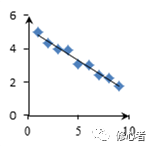
在一元函數中,由點離直線距離表示映射的準確性。比如
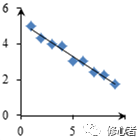
? ? ? ? ?(1)????????????????????(2)
? ? ? ? ? ? ? ? ? 圖2
圖(2)比圖(1)所擬合的方程準確。但對于多元函數來說,這個參數在什么情況下是正確的,則成為統計學家與計量經濟學家所關注的重點問題之一。一種叫最小二乘法的估計方法——當然是最簡單的、最粗糙的方法,確定參數的大小——參數的準確性決定了方程的準確性。計量經濟學或多元統計學中對于最小二乘法的講解異常晦澀,很少有人能理解。今天,我們一改之前的文風,在此處花一點點筆墨,講一下這個最小二乘法。
不妨假定獲取了m個樣本的數據,假定每個樣本基本上服從
則有
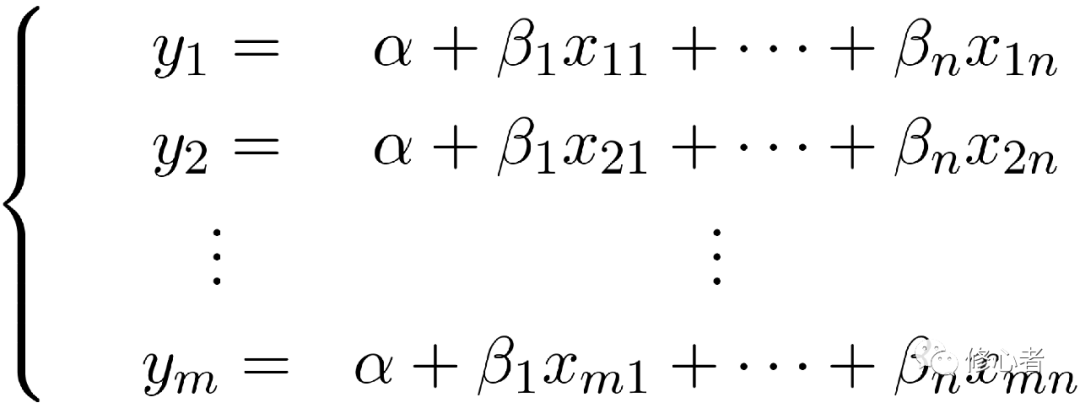 ? ? (3)
? ? (3)
寫成矩陣的形式,可知
 ? ? (4)
? ? (4)
假定ω服從N(0,1),則有
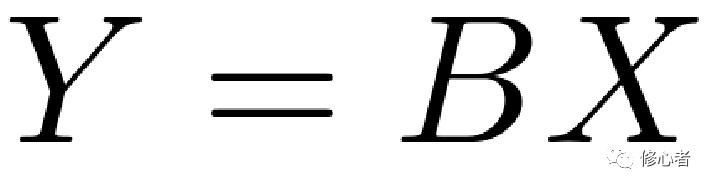 (5)
(5)
現在已知X與Y、B未知,故做以下的變換,便可得到B的值
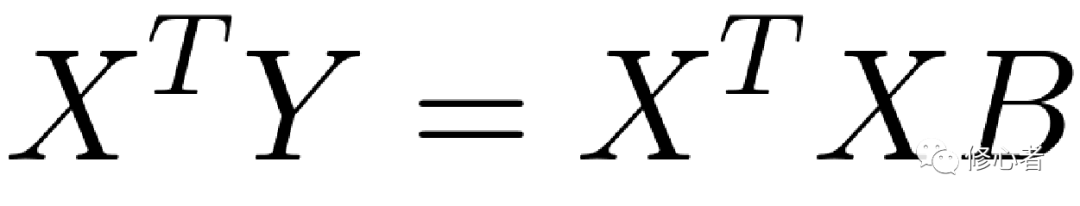 (6)
(6)
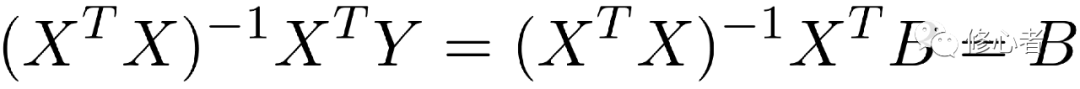 ? ?(7)
? ?(7)
?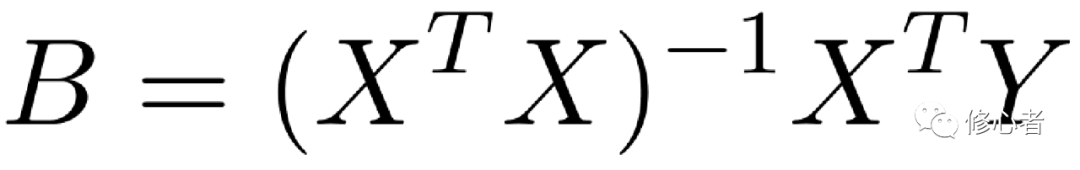 是最小二乘法的本質,其余的,如加權最小二乘法,便是在此基礎上的拓展。在好的估計方法之下,方程的準確性便會增加。
是最小二乘法的本質,其余的,如加權最小二乘法,便是在此基礎上的拓展。在好的估計方法之下,方程的準確性便會增加。
正如前文所述,還有更多的非線性關系,那么這種關系的多樣性與復雜性決定了統計或計量的多樣性與復雜性,我們關注線性關系的主要原因并不是線性分析的簡單性,還是因為很多事物可以轉化成線性的,以著名的生產函數為例,
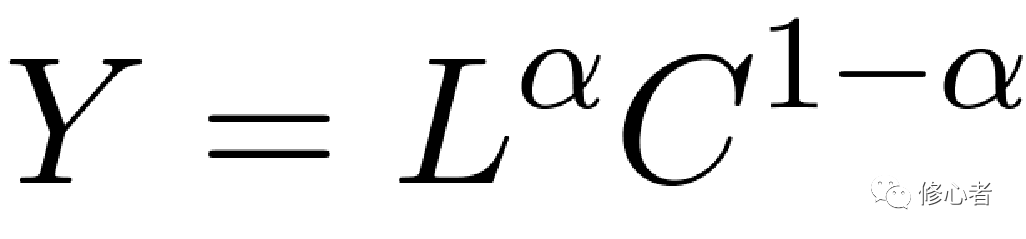 (8)
(8)
就可以轉化成線性方程
 ? ?(9)
? ?(9)
我們稱之為無標度性,或冪律分布。無標度是一個經濟與管理中非常著名的特征。正如在《規模》中所述的,世界萬物都可以歸結為這種屬性。不過最關鍵的是要找到這些變量,一旦發現了這些變量以及這個對應的關系,就有重大的發現。然而,最困難的是發現這些變量,一般情況下這種變量很難找到,不僅需要對所研究對象非常熟悉,而且需要大量的探索。唯有不斷地探索、不斷的失敗,才能找到合適的變量。這種線性關系不僅在數學上成立,更應該在實際中找到對應的因果關系。
無標度性,也稱標度不變性,指的是對自變量坐標進行任意的拉伸或壓縮后,函數的表達形式不變,即
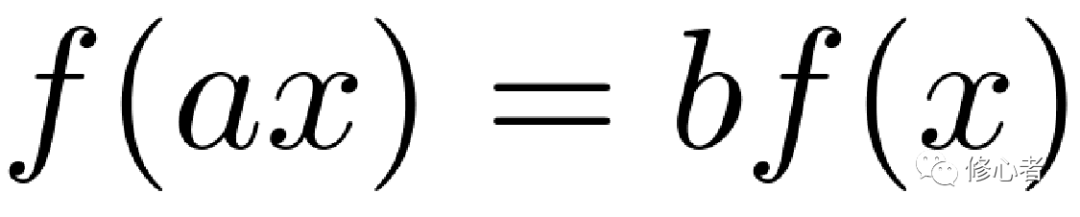 (10)
(10)
而這種形式,僅有冪函數滿足它。不妨令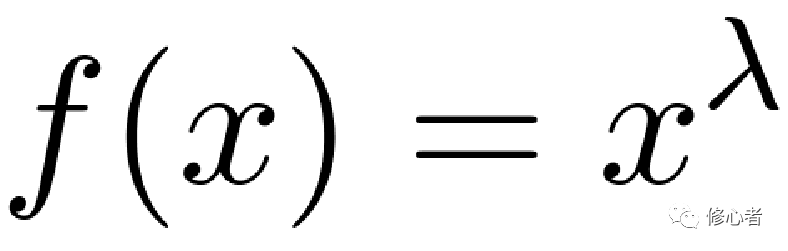 ,則有
,則有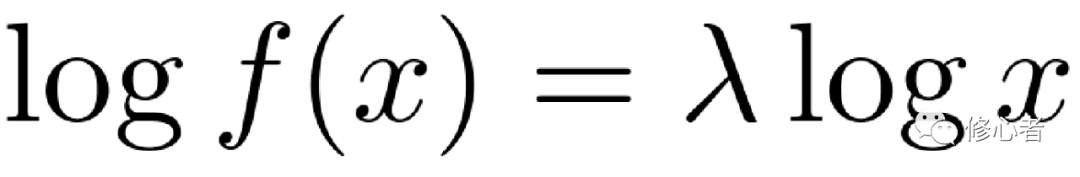 ,恰好滿足這個直線關系。
,恰好滿足這個直線關系。
然而在統計學或計量經濟學的模型中,也并非僅僅有這一種映射(函數)關系,還有更多的模型等著我們去探索。讓我們以生命周期理論為主,分析一下經濟組織的一般發展機制,在事物發展變化過程中,我們一般認為可以分成若干個階段。不同階段中,它的影響因素不同——此處的不同不僅僅局限于量的不同,而且還會包括因素種類的不同。在事物剛剛發展(比如初建企業)之時,它能否成長的原因在于產品本身以及企業努力,此時關注了企業的經營,但當事物成熟之后,對其發展起決定作用的則在于管理,尤其是在發展的制度。可見它的因素會不斷變化。如果新研究的問題恰好處于成長與成熟的中間狀態——我們稱之為“接續態”,則因素的變化非常明顯,模型會變成
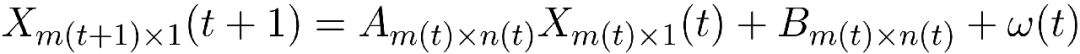 ? ??(11)
? ??(11)
這其中就描述了影響因素的變化性。如果碰到此類問題,就需知道哪個狀態變化(拐點)的時間,以及在切換過程中因素的變化情況,如下圖所示:
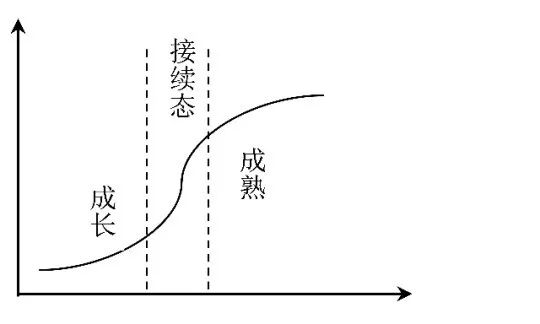
圖3
如上圖所示,在接續態有一個下限與上限,在此區域中,關鍵因素的切換非常快,也許在前一時刻還是主要的影響因素,在下一刻就會成為次要的因素,反之亦然。
這個過程中的統計模型實際上非常難構建。為了方便分析,在接續狀態一般會考慮所有的因素,即使次要因素的影響不顯著,也不應在意,也許在下一個時刻就顯著了呢。在這個“接續態”中,方程在不斷的變化,主要體現在參數不斷的變化。這個變化一般有三種:j圍繞一個數值上下隨機波動,但不能超過某一個界。k是一個隨機變量,但受到近期影響力度強于遠期的影響,也就是說,每個時間點的系統特征對后續都有影響。離得越近的系統對其影響越大,如股市屬于此類。③參數是一個隨機過程,且參數之間構成一個鞅差序列—這種情況最為復雜。在混沌狀態下,經濟與管理系統就具備這種性質。那么,對于這個系統的統計意義上的模型,最有效的估計方法有LMS與卡爾曼濾波。這種時變隨機結構的系統更能體現經濟系統的復雜性與隨機性。
讓我們退回來,回到統計模型的多樣性上。多元統計除此之外,還有大量的其他模型。計量經濟學在此基礎上更是推出了形形色色的模型,這些所謂的一個又一個的模型,讓分析者的選擇難度變得更大。
首先,在這一類模型中,除了連續性變量,也有分類變量、序類變量。不妨假設我們考慮他們,一般的做法是加入一個虛擬變量——啞變量作為參考值,而當與另一種情況進行比較,值得注意的是,一旦建立一個參考——參照物,我們必須弄清這個分類變量的性質—既有無“序”的出現——此處的“序”很關鍵。進一步來說,當各個類型之間屬于平等時,用虛擬變量會讓模型變得有意義。但如果不平等,有一些等級關系時,情況則變得更復雜。事實上,當分類變量作為解釋變量、控制變量時,我們在做統計模型的時候,相當于提前對總體行為分類,針對每一類型來說,做出的一個對應模型。一般講,對于關系“平等”的分類變量來說,其最終效用的差異主要體現在類型的差異上,與其他連續型變量關系不大。如果這其中有一些序關系的存在,則在其他連續型變量的影響會截然不同。
舉例來說,如果我們的分類變量有一個是“貧富”,而資源獲取能力、社會關系的強弱影響會差異很大。對于窮人來說,顯然錢比關系重要,但對于富人來說,關系比錢重要。他們獲利能力的差異性就很強。如果用經典意義上的分類變量處理方法建模,必將得到一個錯誤的結果。
當這些分類變量變成被解釋變量時,就會衍生出幾個模型、Logistic模型、Probit模型、Multi-Logistic模型,這種概率選擇模型在近幾年被大量的應用,甚至是錯誤的應用。一般的,某種形式被選擇需依賴于一些因素。如果知道某一經濟體這些因素的特征,就可以測算出選擇特定狀態的被選的概率大小。而Probit模型與其他兩者最大的區別在于,Probit的被解釋變量屬于有序分類變量,而Logistic與Multi-Logistic的被解釋變量屬于無序分類變量。對于Probit模型的分析,難度遠遠大于其他兩者。
無論是Logistic,還是Probit模型,我們都稱之為非線性模型。不過這種非線性模型是比較簡單的非線性模型,而不是真正的非線性模型,并且這個模型是確定的,而非隨機的。
當然,還有一些非線性統計模型,鑒于篇幅原因,不作釋解,僅僅提下。
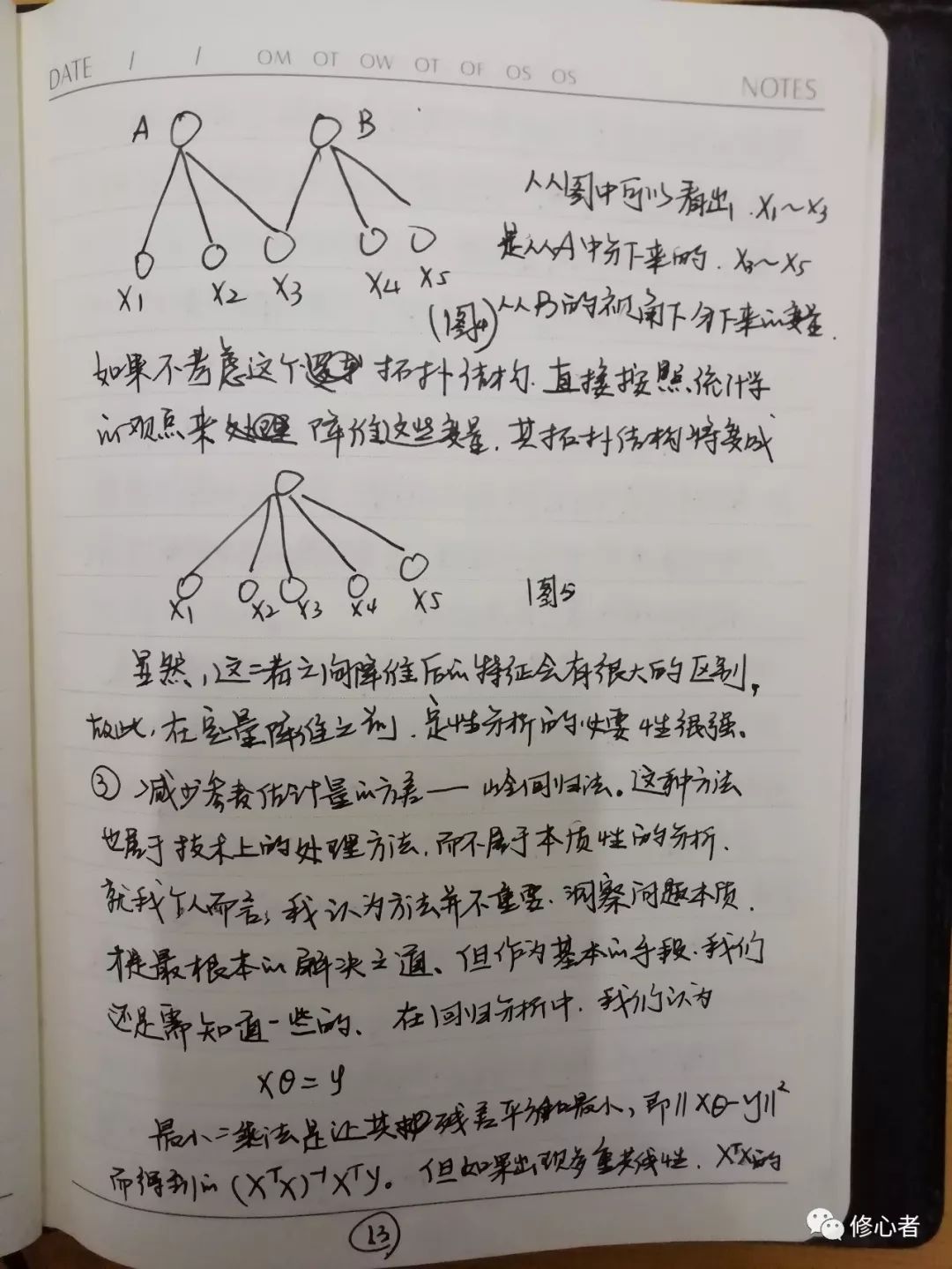
統計學與計量經濟學中的基本條件中有一個非常重要,叫多重共線性。多重共線性的本質原因是對管理與經濟系統的性質不清。這時只好把所有能考慮的因素都考慮上。一般的做法有幾種:①降維:用逐步回歸的做法,將不重要的變量逐個刪掉,觀測結果的準確性,直到刪一個變量之后模型的結果發生顯著變化為止,這個工作量極其大。在功利主義盛行的今天,“浮躁”與“學術造假”之風不斷的幾天,很少有人認真的做研究,也不會有人認真的選擇了。②主成分分析/因子分析,將二者放在一起說明,其實也不是很恰當,畢竟這是統計學中一種比較偷懶的方法。然而,在數學上有道理,在經濟與管理中不一定行得通,這主要是因為,在經濟與管理中,不同類型的變量可以再細分,但他們屬于同一個“父輩”,如果能找到這種邏輯關系,主成份分析/因子分析才有意義。見下圖
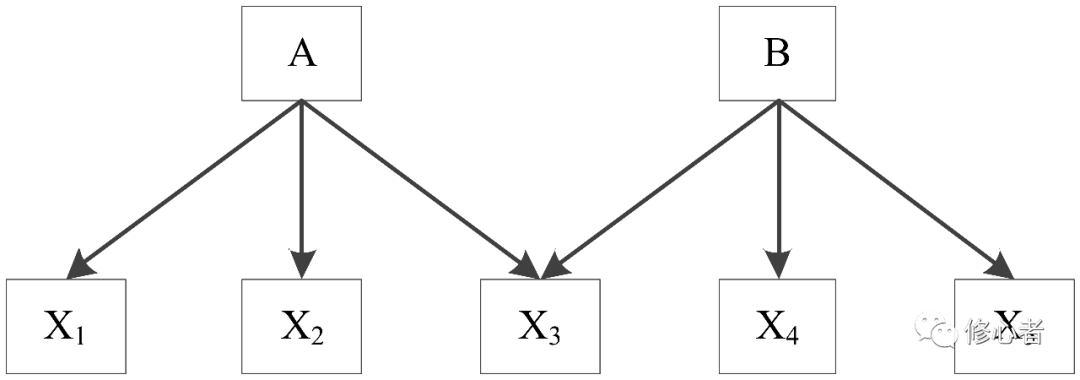
圖4
從圖中可以看出x1~x3是從A中分下來的? x3~x5從B的視角下分下來的變量。如果不考慮這個拓撲結構,直接按照統計學的觀點來降維這些變量,其拓撲結構將變成
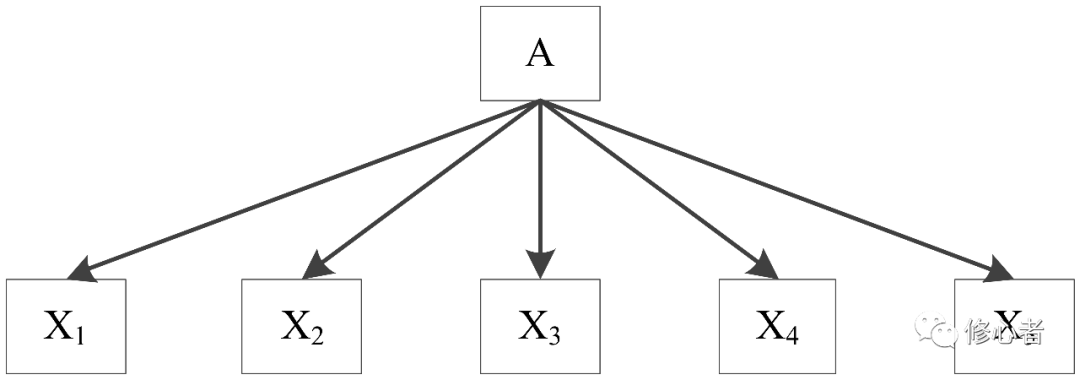
圖5
雖然,這二者之間降維后的特征會有很大的區別,故此,在定量降維之前,定性分析的必要性很強。③減少參數估計量的方差——嶺回歸法。這種方法屬于技術上的處理方法,而不屬于本質性的分析。就我個人而言,我認為方法并不重要,洞察問題本質才是最根本的解決之道,但作為基本的手段,我們還是需知道一些的,在回歸分析中我們認為
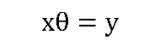
? 最小二乘法是讓其殘差平方和最小,即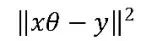 而得到的
而得到的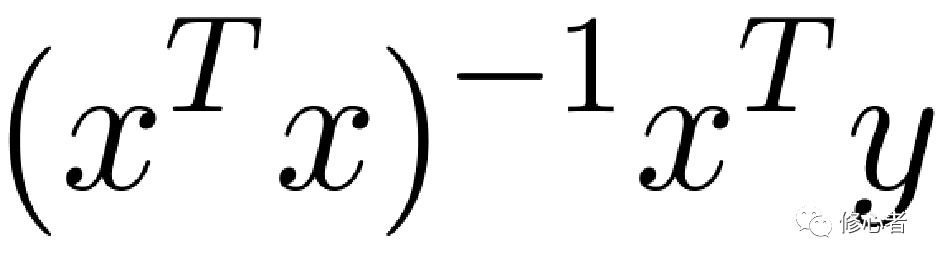 。但如果出現多重共線性,
。但如果出現多重共線性,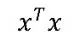 的行列式接近于0,則為一個不適定問題。嶺回歸的做法就是將這個“不適定”問題轉換成“適定”問題:為損失函數加上一個正則化項。
的行列式接近于0,則為一個不適定問題。嶺回歸的做法就是將這個“不適定”問題轉換成“適定”問題:為損失函數加上一個正則化項。
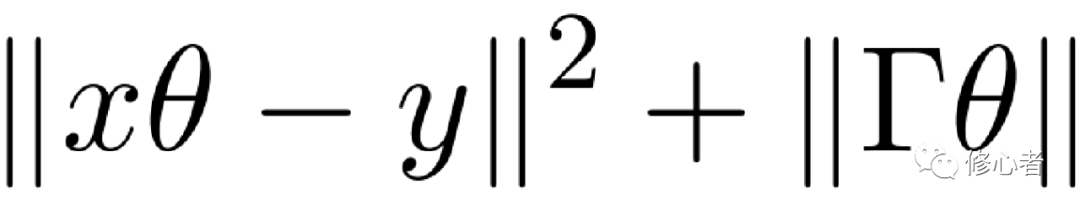 ,?????其中?
,?????其中?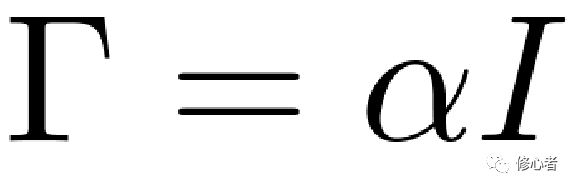 ? (12)
? (12)
?? 故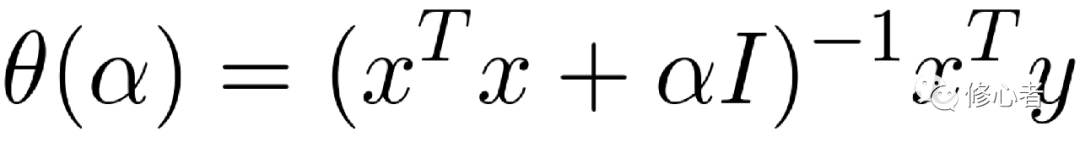 ,其中
,其中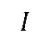 為單位矩陣。從上面可以看出,嶺回歸從本質上并沒有解決解釋變量相互解釋的現象,反之是從數學手段上對其進行了一定的處理。當系統屬性不明確時,我們可以用此類方法來處理。
為單位矩陣。從上面可以看出,嶺回歸從本質上并沒有解決解釋變量相互解釋的現象,反之是從數學手段上對其進行了一定的處理。當系統屬性不明確時,我們可以用此類方法來處理。
? 當然,變量之間相互解釋的觀察并不一定要死守看經典的模型。我們可以選擇SEM(結構方程模型)來處理這一問題。不過需注意的是,SEM模型對定性分析的要求非常高。
? 統計學或計量經濟學都要求有足夠的樣本做支撐。如果樣本量較少怎么辦?科學家構成了一個SVMC(支持向量機)模型,這個模型可以解決對應的問題。
? 總之,由于得到充分的發展,統計學的計量經濟學中還有大量的靜態模型,由于篇幅有限,我們不做一一介紹。我們主要是介紹這一類模型的思想、思維,并不局限于方法的說明。如有興趣,不妨去查閱專業的資料。
? 其實,要準確刻畫事物的特征,就應加入時間的因素,讓這些個靜態的模型“動”起來。在統計學或計量經濟學時,時間這一因素已被重視,尤其是單一變量的時間序列過程。已得到非常全面的描述,在本文中不再啰嗦。在下文中,我們將提出“時滯”的思想。
假設經濟與管理的問題可由一組變量所描述,這種描述可以分成兩種情況。一是刻畫特征。二是描述內在機制。無論哪種,都將面臨著以下三種類型的變量。①即時刻畫/影響經濟與管理系統狀態屬性的變量,我們稱之為一致性指標/因素②提前一段時間就可以刻畫/影響經濟與管理系統狀態屬性的變量。我們稱之為先行性指標/因素。這類具有預兆性的變量往往在事物發展之前就會影響管理系統的特征③滯后一段時間才會刻畫影響經濟與管理系統的屬性,我們稱之為滯后指標/因素,這句話似乎有問題,但你沒聽錯,的確是這樣的。比如說,我們要評價某個科學家的科研實力,用一致性指標所得的結果遠沒有利用滯后性所得的結果的準確。因為科學研究結果是真是假需要實踐來驗證。同樣的,未來可能的因素會影響該經濟/管理系統的屬性。比如說,中國在20年之后的人口結構(以年齡為參考點)將嚴重影響目前消費產品與服務結構的決策。故此,該模型將變成下面的形式。
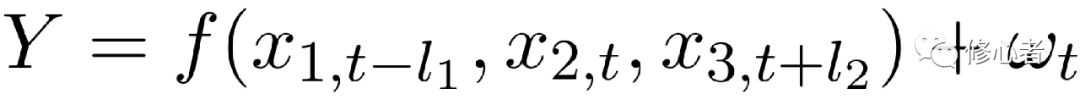 (13)
(13)
?其中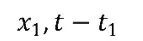 、
、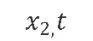 、
、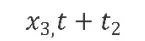 分別表示,先行型指標/變量、一致指標/變量、滯后型指標變量。l1? 和l2分別表示先行周期與滯后周期、l1? 與l2是一個正數,故此對x1、 x2與x3的識別與構造,以及l1?與l2的確定則顯得尤為重要。對于前者,我們在前文中的很多篇幅中有提過。但對于l1? 與l2的確定。則需要進一步的定性定量分析。事實上,也有成形的相關理論對此進行分析,建議有興趣的讀者自行查閱。
分別表示,先行型指標/變量、一致指標/變量、滯后型指標變量。l1? 和l2分別表示先行周期與滯后周期、l1? 與l2是一個正數,故此對x1、 x2與x3的識別與構造,以及l1?與l2的確定則顯得尤為重要。對于前者,我們在前文中的很多篇幅中有提過。但對于l1? 與l2的確定。則需要進一步的定性定量分析。事實上,也有成形的相關理論對此進行分析,建議有興趣的讀者自行查閱。
如果方程(13)具有參數隨機時變的特征,則用最小二乘法、加權最小二乘法等經典的算法難以對此進行估算。此時LMS算法及Kalmman濾波大有作為了,甚至是更加先進的啟發式算法。比如蟻群算法。
在前面的內容中,我們的變量都是結構性的變量,那么,如果這些變量是圖片、音頻、視頻和文字,我們則想知道,統計學模型還適用嗎?答案是肯定的,多維統計學習則是一種有效的工具,比如深度神經網絡模型,其中的變量就可以是非結構化的數據,關于深度神經網絡,我們將在后文中進行闡述,此處不再多說。
上面的分析,主要針對的是函數和方程,然而在經濟與管理的問題中,更多的是映射。即圖1所述,這種情況下,問題會更加復雜,對于這一問題,結構方程,深度神經網絡都是一個比較有效的工具。對于神經網絡所存在的梯度消失或梯度爆炸、訓練太慢、過擬合等三大缺陷,引入無監督學習算法大大提高了效率,從而使得神經網絡應用非常普遍。它是對映射解決的一種較為有效的模型,通過對大量的案例(樣本)的學習,我們就可以得到各個節點中的權重,這個權重描述由輸入到多輸出之間的映射屬性,然后在訓練成功的基礎上,對未知的事件進行分析,以便得到未知事件的性質。
在多維統計學習中,還有一些其他的方法。都會在經濟與管理的科學研究中發揮巨大的功能,比如人工智能。正如我們在《大數據是思想,是思維還是方法?》一文中所講的,目前最關鍵的是對各種算法進行嚴密的證明,如果能突破若干個基本問題,則會大大推動這一領域的發展。
鑒于篇幅有限以及本文的目的,我們不再花大量的筆墨分析各個模型,在這里我們將重點討論如何使用這些模型,以及如何正確使用模型。換句話說,我們不應該為了模型而模型,以及不應該被模型綁架。首先我們必須關注統計學和計量經濟學的使用條件,不是所有的問題都可以用它來解決,比如優化、博弈、動力學、復雜網絡、概率,都無法用統計學和計量經濟學去解釋。其次,統計學的回歸分析中——目前計量經濟學也在關注這一塊兒,其解釋變量必須滿足的幾大條件,比如樣本的隨機性,變量的獨立同分布性,噪聲也有要求。然而在我們日常的研究例子中,很少有人完全做到這三大要求。比如樣本的隨機性在研究中就很難實現,因為我們數據的可獲得性較差所致。畢竟這個不等同于隨機實驗,無法隨心所欲的得到數據,故此很多科學家便依賴于統計年鑒和問卷調查。而依賴于某種數據時,本身便失去了隨機性。比如,有人研究中國的企業創新問題,但只能獲取A股企業的數據,沒有未上市的企業以及眾多的未上市的中小企業。那么,對于技術創新本身來講,到底是中小企業創新的多,還是上市企業創新得多,這本身就需要論證。如果僅僅采用上市企業的數據,那么未上市企業則被排除,這個悖論應該是一個很好的切入點。一旦選擇A股企業,那么選擇企業時,很多人都會選擇競爭力在前百分之X的企業。顯然,這個選擇并不是隨機選擇,而是典型分析,不符合統計分析與計量經濟學的思想,所得的結論也會有所偏差。現在分析第二個條件:在分析時大都要求變量滿足獨立同分布的條件。在這點上,大家做的都不太好。下面舉幾個例子,首先變量的類型不一致,在其中有效益變量,也有成本性變量,還有居中型變量。在分析的過程中都應該把變量化成效益型變量。成本型和居中型變量的轉化方法分別如下:
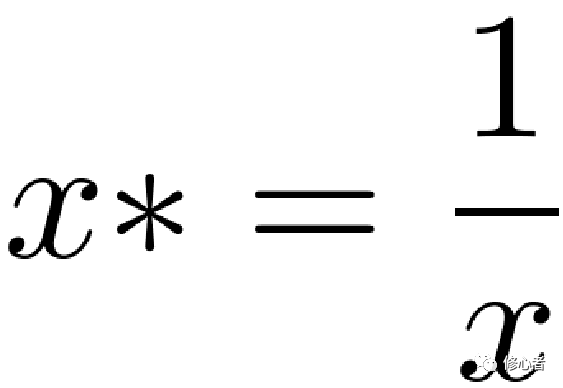
 (14)
(14)
這里,假定居中型變量的曲線如圖6:
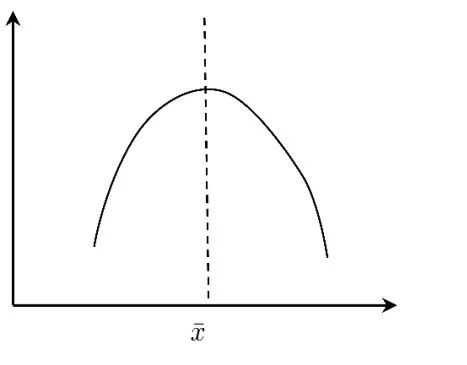
圖6
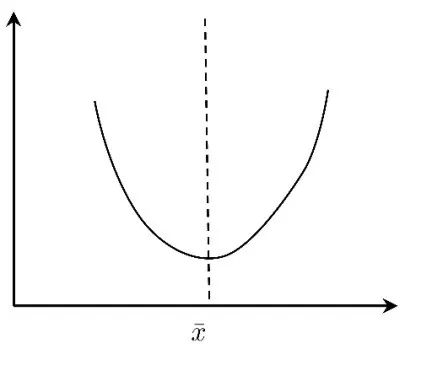
圖7
對于圖7的情況則恰好相反,其中很多科研工作者都不對變量進行無量綱化處理,而這個更為重要,當且僅當量綱去掉之后,統計模型才準確可靠。再次,他們也沒有進行標準化處理,將所有的變量變成0-1之間的一個數。第四,所有很多經濟與管理學家在做研究時喜歡采用問卷調查的方法,而在問卷調查中會涉及到很多分類變量,并且有一定的無序分類變量,比如性別,民族,地域,然后很多人就用這些數據進行回歸分析。顯然這是一種錯誤的做法,舉例來說,設0=男,1=女,那么他們只能以分類變量進入回歸模型中,而不能直接放入。畢竟1>0,但女男。
即使對于有序分類變量,我們也不能隨便的采用直接回歸,而應當進行適當的處理。再進一步來說,在分析中,自變量必須有且至少有一個連續變量才可以得到正確的結論。因為有序分類變量的組內方差、組間平方差以及總平方差都無法找到。這些科學家混淆了回歸分析中的那個最小二乘法的內涵,它只能針對連續變量,對于離散變量則不會如此處理。
在統計學中,噪聲一般都假設為一個白噪聲,因為所有的變量都假設是一個服從特定分布如正態分布的隨機變量,所以多個變量的聯合分布也服從正態分布的假設。然而,在實際中,這個噪聲并不是白噪聲,而是一個彩噪聲,我們對于其分析也有類似的處理。詳情可查閱對應的資料。
我應該關注每一個模型的適用條件,這一點非常關鍵,知道每個模型的前因后果才能把我們的問題抽象成和對應的模型,這些在前文已已有涉及,在此不再累贅。其實我們知道每一個模型都蘊含著一種思想,模型本身的思想思維過程的重要性遠遠大于形式以及其參數估計方法。
關于統計與計量經濟學中的一些問題,我們先談到這里,文章不能將所有的內容都一一詳述,只能從其思想,思維及模型自身做一點點見解,試圖達到拋磚引玉的效果。望對讀者有所啟示,最后祝在此領域中的各位研究學者出來更多的優秀成果。





























public、protect、private繼承方式 C++)

)


)

)
(轉))


