目錄
- binlog寫入機制
- redo log寫入機制
- 組提交機制實現大量的TPS
- 理解WAL機制
- 如何提升IO性能瓶頸
WAL機制告訴我們:只要redo log與binlog保證持久化到磁盤里,就能確保MySQL異常重啟后,數據可以恢復。
下面主要記錄一下MySQL寫入binlog和redo log的流程。
binlog寫入機制
1、事務執行過程中,先把日志寫到binlog cache,事務提交的時候,再把binlog cache寫到binlog文件中。
2、binlog cache,系統為每個線程分配了一片binlog cache內存,參數binlog_cache_size控制單個線程內binlog cache大小。如果超過了這個大小就要暫存磁盤
3、事務提交的時候,執行器把binlog cache里完整的事務寫入binlog中。并清空binlog cache
4、每個線程都有自己的binlog cache,共用一份binlog文件
5、write,是把日志寫入到文件系統的page cache,內存中,沒有持久化到磁盤,所以速度比較快,圖中的fsync是將數據持久化到磁盤,占用磁盤的IOPS
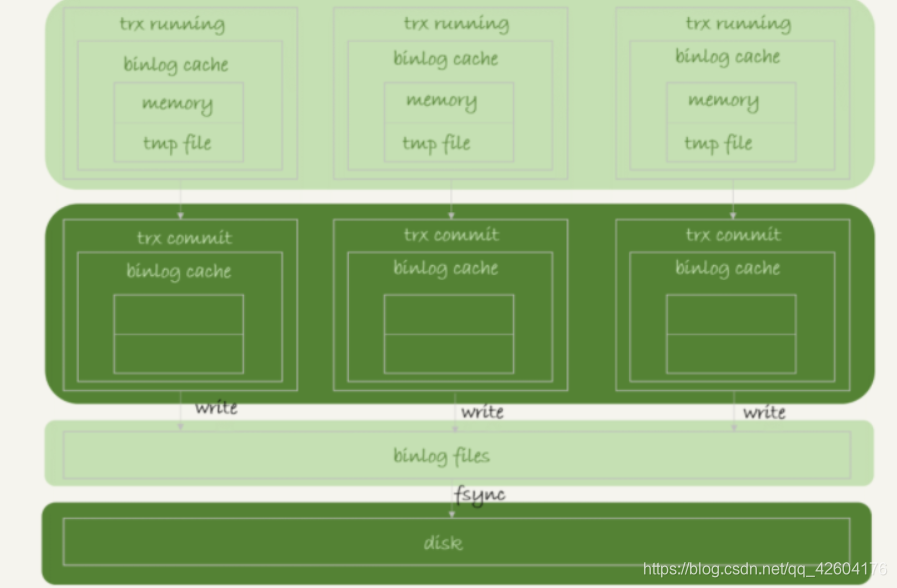
關于何時write、fsync是由參數sync_binlog控制的:
1、sync_binlog = 0時,每次提交事務都只write,不fsync;
2、sync_binlog = 1時,每次提交事務都會執行fsync;
3、sync_binlog = N(N>1)時,表示每次提交事務都write,但累積N個事務后才fsync。
sync_binlog控制binlog真正刷盤的頻率,對于一個IO非常大的情景,這個數字調大可以提高性能,但是如果容錯率非常低的情況下,必須設為1.(sync_binlog設置為N對應的風險是:如果主機發生異常重啟,會丟失最近N個事務的binlog日志)
redo log寫入機制
事務在執行過程中,生成的redo log是要先寫到redo log buffer的。
redo log buffer里面的內容并不需要每次生成后都要持久化到磁盤中。
如果事務執行期間MySQL發生異常重啟,那么這部分日志就丟了。由于事務并沒有提交,所以這時日志丟了也不會有損失。
事務沒提交的時候,redo log buffer部分日志也是有可能被持久化到磁盤中的。

上面三個顏色表征了redo log可能的三種狀態:
1、存在redo log buffer中,物理上是在MySQL進程內存中,即紅色部分;
2、寫到磁盤(write),但是沒有持久化(fsync),物理上實在文件系統的page cache里面,即黃色部分;
3、持久化到磁盤,對應的是hard disk,也就是圖中的綠色部分;
前兩步是寫內存,最后一步是磁盤IO,所以要在page cache夠大且不影響寫入page cache前將redo log 持久化到磁盤 。
為了控制redo log 的寫入策略,InnoDB提供了innodb_flush_log_at_trx_commit參數,他有三種可能取值:
1、設置為0,每次事務提交的時候都只是把redo log留在redo log buffer中;
2、設置為1,每次事務提交的時候都只是把redo log直接持久化到磁盤;
3、設置為2,每次事務提交時都只是把redo log寫到page cache;
與binlog不同,binlog是每個線程都有一個binlog cache,而redo log是多個線程共用一個redo log buffer。
InnoDB有一個后臺線程,每隔1s,就會把redo log buffer中的日志,調用write寫到文件系統的page cache,然后調用fsync持久化到磁盤,事務執行過程中的redo log也是直接寫在redo log buffer上的,所以,未提交的事務的redolog也可能被持久化到磁盤。
還有兩種場景也會導致沒有提交的事務的redo log寫入到磁盤中:
情形1:
redo log buffer占用的空間即將達到innodb_log_buffer_size一半的時候,后臺線程會主動寫盤。
(這里只是write,沒有fsync)
情形2:
并行的事務提交的時候,順帶將這個事務的redo log buffer持久化到磁盤。
(事務A執行一半,部分redo log到buffer中;事務B提交,且 innodb_flush_log_at_trx_commit ,會把redo log buffer里的log全部持久化到磁盤中)
補充說明
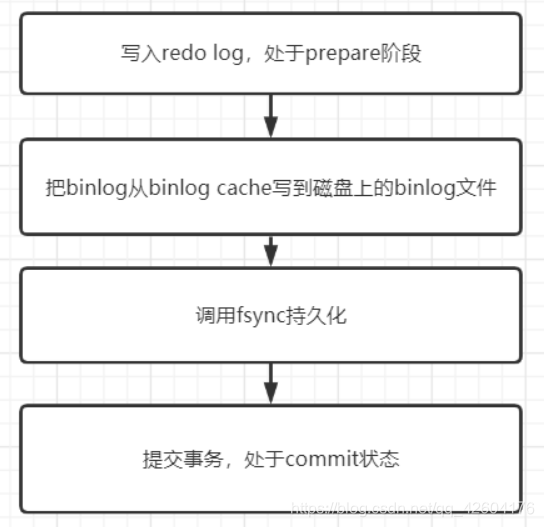
兩階段提交在時序上redo log先prepare 再寫binlog,最后再把redo log commit;
innodb_flush_log_at_trx_commit 設置成 1,prepare階段redo log就已經落盤。所以redo log再commit的時候就不需要fsync了,只會write到文件系統的page cache中就夠了。
sync_binlog 和 innodb_flush_log_at_trx_commit都設置為1,即一個事務完整提交前,需要等待兩次刷盤,一次是redo log(prepare階段),一次是binlog。
組提交機制實現大量的TPS
首先介紹日志邏輯序列號(log sequence number,LSN)的概念。LSN是單調遞增的,每次寫入長度length的redo log,LSN的值就會加上length。
三個并發事務(trx1,trx2,trx3)在prepare階段,都寫完redo buffer,并持久化到磁盤。
對應的LSN為50、120、160.
對應流程:
1、trx1第一個到達,被選為這組的leader;
2、等trx1要開始寫盤的時候,這個組里面已經有三個事務,這時候LSN也變成了160;
3、trx1去寫盤的時候,LSN=160;trx1返回時,所有LSN<= 160的redo log都被持久化到磁盤中;
4、trx2與trx3直接返回。
總結:
一次組提交中,組員越多,節約磁盤IOPS的效果越好。如果是單線程,就只能一個事務對應一次持久化操作
 兩階段提交 兩階段提交 |  兩階段提交細化 兩階段提交細化 |
這樣保證binlog也可以組提交了。由于step3速度快,所以集合到一起的binlog比較少,所以binlog的組提交效果不如redo log組提交。
提升binlog效果:
--1.binlog_group_commit_sync_delay :b表示延遲多少微秒后才調用fsync;
--2.binlog_group_commit_sync_no_delay_count :表示累積多少次以后才調用fsync;
理解WAL機制
WAL機制是減少磁盤寫,可是每次提交事務都要寫redo log和binlog ,磁盤讀寫次數沒有變少。
所以WAL機制主要得益于兩個方面:
--1、redo log和binlog都是順序寫,磁盤的順序寫比隨機寫速度要快
--2、組提交機制,可以降低磁盤IOPS消耗
如何提升IO性能瓶頸
1、設置binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count參數,減少binlog的寫盤次數。這個方法是基于“額外故意等待”來實現的,可能會增加語句的響應時間,但是不會丟失數據
2、將sync_binlog設置為大于1的值(100~1000)。不過會有主機掉電時丟binlog日志的風險
3、將 innodb_flush_log_at_trx_commit 設置為2。會有主機掉電丟數據的風險



















