目錄
- CPU使用率
- 查看CPU使用率(top、pidstat解釋)
- CPU使用率過高
- perf top
- perf record 和 perf report
CPU使用率
Linux通過/proc虛擬文件系統,向用戶空間提供了系統內部狀態的信息。
/proc/stat提供的就是系統的CPU和任務統計信息。
執行命令cat /proc/stat | grep ^cpu,表示只保留各個CPU的數據,結果如下:
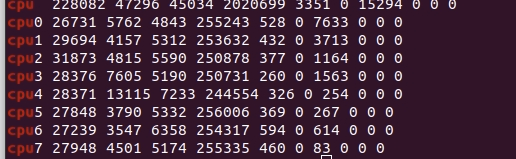
輸出表示:
第一行表示所有CPU的不同場景下的累加節拍數。
Tips:為了維護 CPU 時間,Linux 通過事先定義的節拍率(內核中表示為 HZ),觸發時間中斷,并使用全局變量 Jiffies 記錄了開機以來的節拍數。每發生一次時間中斷,Jiffies 的值就加 1。通過命令grep 'CONFIG_HZ=' /boot/config-$(uname -r)可以查看系統配置的節拍率,即每秒鐘觸發多少次時間中斷。
第一列:CPU編號
接下來的幾列:
usr(縮寫為us),代表用戶態CPU時間。不包含nice時間,包括guest時間
nice(縮寫ni),代表低優先級用戶態CPU時間。nice可取范圍為-20~19,數值越大,優先級越低。
system(縮寫為sys),代表內核態CPU時間。
idle(縮寫為id),代表空閑時間。不包括等待I/O的時間(iowait)
iowait(縮寫為wa),代表等待I/O的CPU時間
irq(縮寫為hi),代表處理硬中斷的CPU時間
softirq(縮寫為si),代表處理軟中斷的CPU時間
steal(縮寫為st),代表當系統運行在虛擬機中時,被其他虛擬機占用的CPU時間
guest,代表虛擬化運行其他操作系統的時間,也就是運行虛擬機的CPU時間
guest_nice(縮寫為gnice),代表以低優先級運行虛擬機的時間。
CPU使用率的定義則是:

/proc/stat 的數據記錄的是開機以來的節拍累積值,所以算出來的是平均CPU使用率。
一般來說,性能工具回取間隔一段時間(如3s)的兩次值,作差后,再計算這段時間內的平均CPU使用率:

查看CPU使用率(top、pidstat解釋)
關于top與ps:
top 顯示了系統總體的 CPU 和內存使用情況,以及各個進程的資源使用情況。
ps 則只顯示了每個進程的資源使用情況。
top命令中的第三行%cpu即系統CPU使用率,默認顯示的是平均值
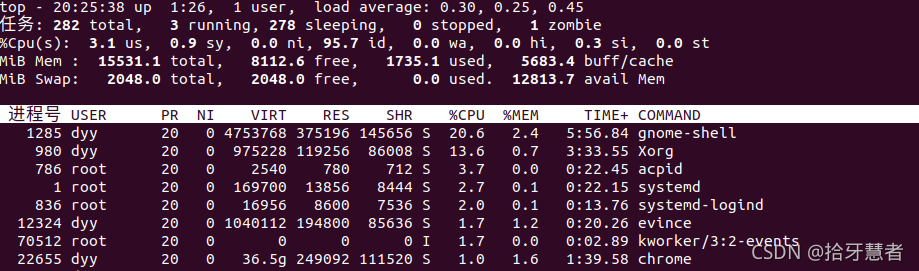
空白行之后是進程實時信息,每個進程都有一個%CPU列,表示進程的CPU使用率。該使用率 = 用戶態 + 內核態CPU使用率的總和,包括進程用戶空間使用的CPU、通過系統調用執行的內核空間CPU、就緒隊列等待運行的CPU。
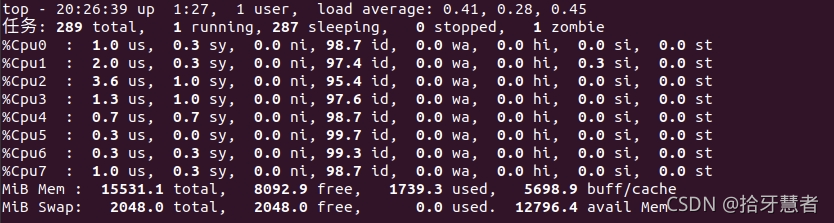
再按1,切換顯示每個CPU使用率。
接下來使用pidstat:
包括了:
用戶態CPU使用率(%usr)
內核態CPU使用率(%system)
運行虛擬機CPU使用率(%guest)
等待CPU使用率(%wait)
總的CPU使用率(%CPU)
最后輸出平均值
# 隔 1 秒 輸出一組數據, 共輸出5組
pidstat 1 5
21時55分30秒 UID PID %usr %system %guest %wait %CPU CPU Command
21時55分31秒 0 54 0.00 1.00 0.00 0.00 1.00 7 ksoftirqd/7
21時55分31秒 1000 1311 1.00 0.00 0.00 0.00 1.00 4 gnome-shell
21時55分31秒 1000 3170 0.00 1.00 0.00 0.00 1.00 1 pidstat
...
平均時間: UID PID %usr %system %guest %wait %CPU CPU Command
平均時間: 0 54 0.00 0.25 0.00 0.00 0.25 - ksoftirqd/7
平均時間: 0 135 0.00 0.25 0.00 0.00 0.25 - kworker/u16:2-phy0
平均時間: 1000 998 0.25 0.25 0.00 0.00 0.50 - Xorg
平均時間: 1000 1311 1.25 0.50 0.00 0.00 1.75 - gnome-shell
平均時間: 1000 2370 0.25 0.00 0.00 0.00 0.25 - chrome
平均時間: 1000 2712 0.75 0.00 0.00 0.00 0.75 - chrome
平均時間: 1000 3157 0.50 0.00 0.00 0.00 0.50 - gnome-terminal-
平均時間: 1000 3170 0.25 0.75 0.00 0.00 1.00 - pidstat
CPU使用率過高
使用perf,它以性能事件采樣為基礎,可以分析系統的各種事件和內核性能,也可以分析指定應用程序的性能問題。
perf top
類似于top,它能夠實時顯示占用CPU時鐘最多的函數或者指令,因此可以用來查找熱點函數。如:
$ perf top
2 Samples: 833
3 Overhead
of event 'cpu-clock', Event count (approx.): 97742399
Shared Object Symbol
4 7.28% perf [.] 0x00000000001f78a4
5 4.72% [kernel] [k] vsnprintf
6 4.32% [kernel] [k] module_get_kallsym
7 3.65% [kernel] [k] _raw_spin_unlock_irqrestore
輸出結果解釋:
第一行,包含三個數據: 采樣數(Samples)、事件類型(event)和事件總數量(Event count)。
下面的表格數據包含四列:
第一列: Overhead,該符號的性能事件在所有采樣中的比率
第二列:Shared,該函數或指令所在的動態共享對象,如內核、進程名、動態鏈接庫名、內核模塊等
第三列:Object,是動態共享對象的類型,比如[.]表示用戶空間的可執行程序,或者動態鏈接庫,[k]表示內核空間。
第四列:Symbol,符號名,即函數名。當函數名未知時,用16進制的地址表示
perf record 和 perf report
perf top 能夠實時展示系統性能,但是不能保存數據,也就無法用于離線或者后續的分析。
而perf record 提供了保存數據的功能,保存后的數據,需要使用perf report 來解析展示:
perf record # 按下 ctrl + c 終止采樣
[perf record: Woken up 1 times to write data]
[perf record: Captured and wrote 0.452 MB perf.data(6093 samples) ]perf report # 展示類似于perf top的報告
在實際使用中經常為perf top 和 perf record 加上 -g 參數,開啟調用關系的采樣,方便根據調用鏈來分析性能。





)

-用地圖塊拼成大地圖 初探lufylegend)
)


)





頁游安全攻與防,SWF加密和隱藏密匙)

