Raft算法是強領導模型,集群中只能有一個領導。
下面是raft的視頻講解:
raft
raft的三種角色及其概念
服務器節點狀態一共有三種:領導者(Leader)、跟隨著(Follower)、候選人(Candidate)
跟隨者:接受和處理來自領導者的消息,當等待領導者心跳信息超時時,推薦自己當候選人
候選人:向其他節點發送請求投票的RPC消息,通知其他節點來投票,如果贏得了大多數選票,就晉升當領導者
領導者:處理寫請求、管理日志復制、不斷發送心跳信息,表示自己還活著,不要發起新的選舉
選舉領導者的過程
初始狀態:所有節點都是跟隨者
Raft算法特性時隨機超時時間,每個節點等待領導者節點心跳信息的超時時間間隔是隨機的。
集群中沒有領導者時,等待超時時間最小的節點會因為沒有等到領導者心跳信息,發生超時。
超時自薦
此時該節點就會增加自己的任期編號,并推舉自己為候選人,先給自己投一張選票,然后向其他節點發送請求投票RPC消息,請它們選舉自己為領導者。
選舉投票
其他節點接受到候選人的RPC消息時,并且在編號為1的任期內,沒有投過票,那么就把選票投給該候選人,然后增加自己的任期編號。
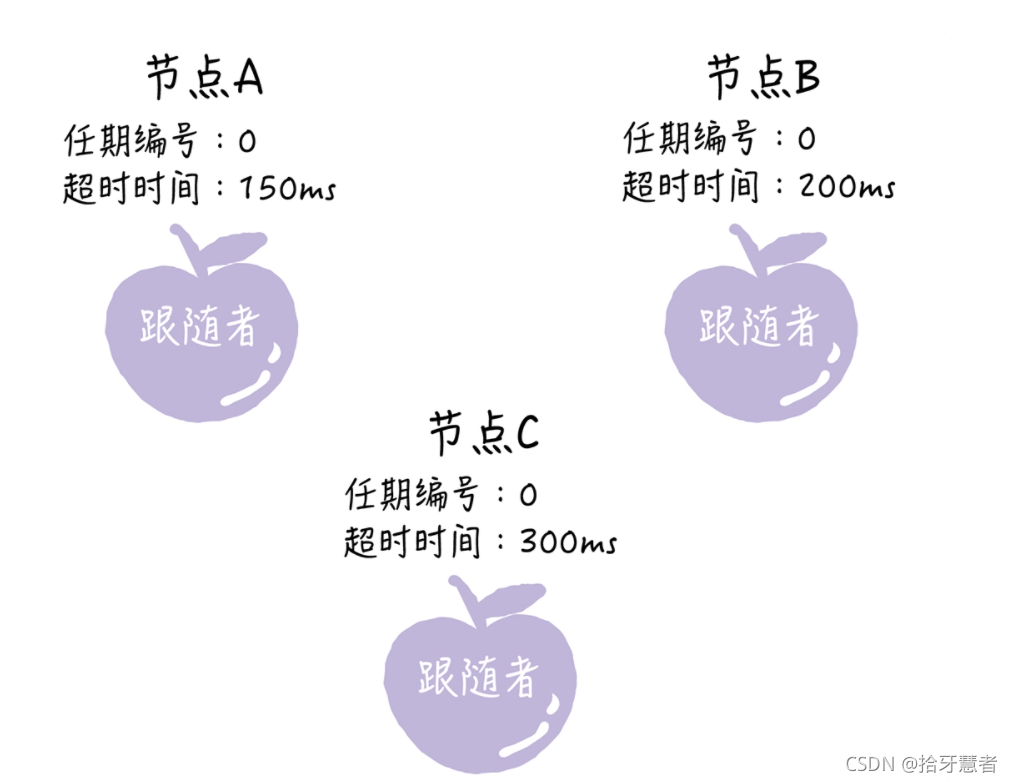 圖1 初始狀態 圖1 初始狀態 |  圖2 超時自薦 圖2 超時自薦 |  圖3 選舉投票 圖3 選舉投票 |
新領導產生
候選人在選舉超時時間內贏得了大多數的選票,那么它就會成為本屆任期內新的領導者。
新領導威懾維權
領導者將周期性地發送心跳消息,通知其他服務器我是領導者,阻止跟隨者發起新的選舉,篡權。
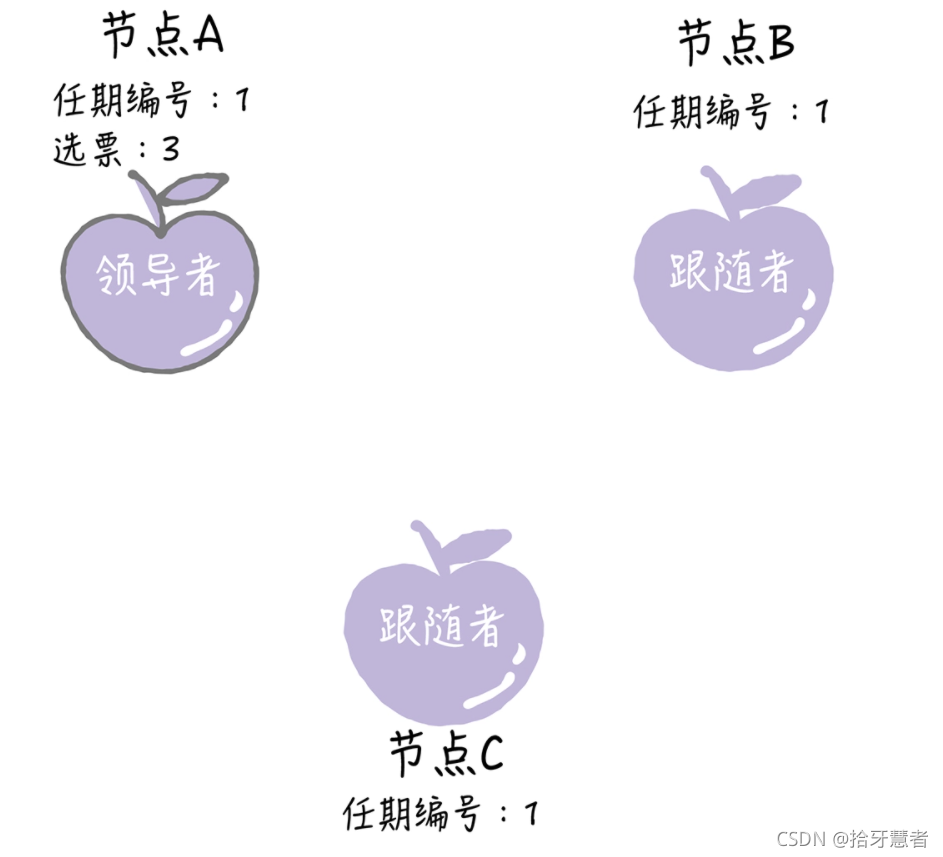 圖1 初始狀態 圖1 初始狀態 | 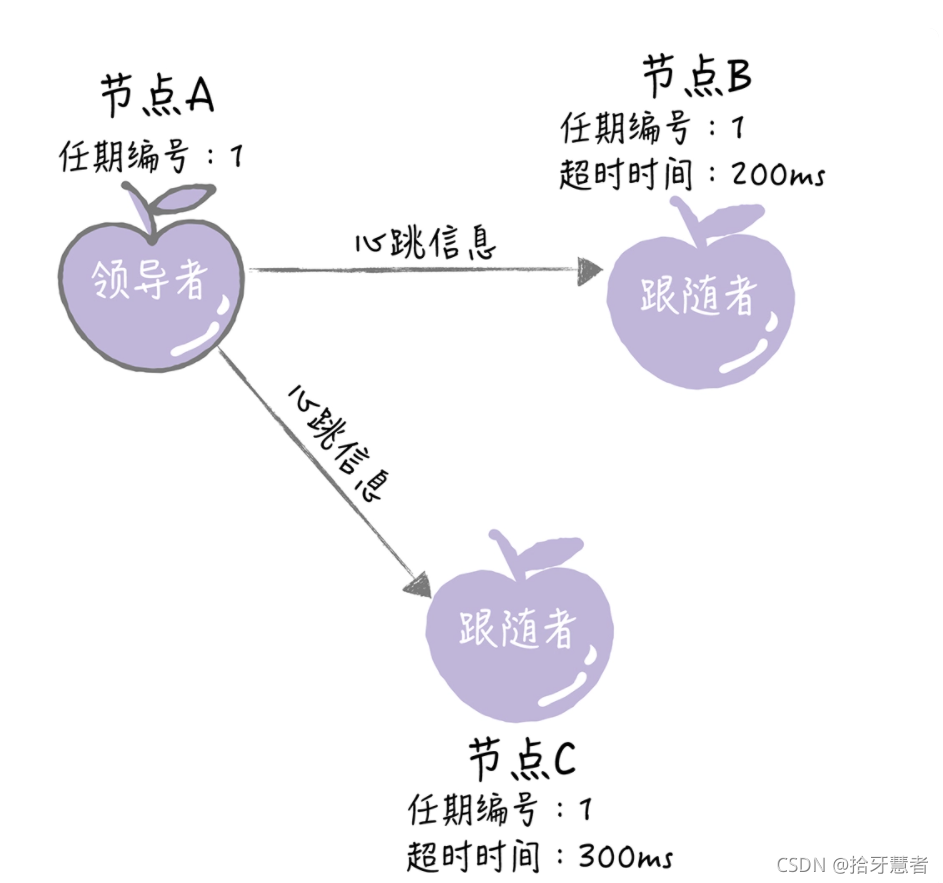 圖2 超時自薦 圖2 超時自薦 |
選舉細節
1、節點間通訊方式
Raft里,服務器節點間溝通聯絡采用的是遠程過程調用(RPC),在領導選舉中,需要用到兩類RPC:
1、請求投票(RequestVote)RPC,由候選人在選舉期間發起,通知各個節點進行投票
2、日志復制(AppendEntries)RPC,由領導者發起,用來復制日志和提供心跳信息
2、關于任期的rules
Raft算法中的領導者是有任期的,每個任期由單調遞增的數字(任期編號)標識。任期編號會隨著選舉的進行而變化。
Raft 算法中的任期不只是時間段,而且任期編號的大小,會影響領導者選舉和請求的處理。
1、跟隨者在等待領導者心跳信息超時后,推舉自己為候選人,會增加自己的任期號。(在推舉自己的時候就會++了)
2、一個服務器節點若檢測到自己任期編號比其他節點小,更新自己的編號到較大的編號值
3、若一個候選人或者領導者檢測到自己任期編號比其他節點小,會將自己恢復成跟隨著狀態。所以,raft 不兼容作惡節點。 只要有一個作惡節點發送“任期編號更大“的心跳消息,立馬就能讓這個集群變成無 leader 的,進而無法工作
4、如果一個節點接收到一個包含較小的任期編號值的請求,那么它會直接拒絕這個請求。
3、關于選舉的rules
1、領導者周期性向所有跟隨者發送心跳信息(不包含日志復制RPC消息)
2、如果在指定時間內,跟隨者沒有結收到領導者的消息,那么就自薦,發起領導者選舉
3、在一次選舉中,贏得大多數選票的候選人,將晉升為領導者
4、一個任期內,領導者會一直是領導者,直到它自身出現宕機等問題。當然如果出現網絡延遲,也會出現重新選舉的情況‘
5、在一次選舉中,每一個服務器節點最多會對一個任期編號投出一張選票,并且按照“先來先服務”的原則進行投票。
如下圖:

6、日志完整性高的跟隨者拒絕投票給日志完整性低的候選人,即如果日志不完整的請求當主節點,如果當前的節點日志比他完整,那么就會拒絕給他投票

4、隨即超時解決選票瓜分現象
? 跟隨者等待領導者心跳信息超時的時間間隔,是隨機的
? 當沒有候選人贏得過半票數,選舉無效了,這時需要等待一個隨機時間間隔,也就是說,等待選舉超時的時間間隔,是隨機的
關于raft的領導者選舉限制和局限
1.讀寫請求和數據轉發壓力落在領導者節點,導致領導者壓力。
2.大規模跟隨者的集群,領導者需要承擔大量元數據維護和心跳通知的成本。
3.領導者單點問題,故障后直到新領導者選舉出來期間集群不可用。
4.隨著候選人規模增長,收集半數以上投票的成本更大。
;出錯問題)








)

![[轉]連接excel數據源時,首行包含列名稱選項在連接字符串中的設置。](http://pic.xiahunao.cn/[轉]連接excel數據源時,首行包含列名稱選項在連接字符串中的設置。)
:基本常用操作)


共享數據同步以及數據競爭)
,MX記錄,CNAME記錄)

:生產者消費者模型與條件變量使用)
