文章目錄
- TCP為何不適用于實時音視頻
- UDP->RTP
- RTP協議結構
- Jittbuffer
- RTP擴展頭
- RTP填充數據
- 參考
TCP為何不適用于實時音視頻
可靠性是以犧牲實時性為代價的。按照TCP原理,當出現極端網絡情況時,理論上每個包的時延可達到秒級以上,而且這種時延是不斷疊加的。這對于音視頻實時通信來說是不可接受的。
TCP為了實現數據傳輸的可靠性,采用的是“發送→確認→丟包→重傳”這樣一套機制。而且為了增加網絡的吞吐量,還采用了延遲確認和Nagle算法(將多個小包組成一個大包發送,組合包的大小不超過網絡最大傳輸單元)
為了增加網絡的吞吐量,接收端不必每收到一個包就確認一次,而是對一段時間內收到的所有數據集體確認一次即可。為了實現該功能,TCP通常會在接收端啟動一個定時器。定時器的時間間隔一般設置為200ms,即每隔200ms確認一次接收到的數據。這就是延遲確認機制。‘
除此之外,TCP在發送端也啟動了一個定時器,不過該定時器的功能不是發送確認消息,而是用來判別是否有丟包的情況。發送端定時器的時長為一個RTO(RTO(Retransmission Timeout),重傳超時時長。其值約等于RTT的平均值,每次超時后以指數級增長。RTT表示一個數據包從發送端到接收端,然后再回到發送端所用的時長)如果在定時器超時后仍然沒有收到包的確認消息,則認為包丟失了,需要發送端重發丟失的包。這就是TCP的丟包重傳機制。
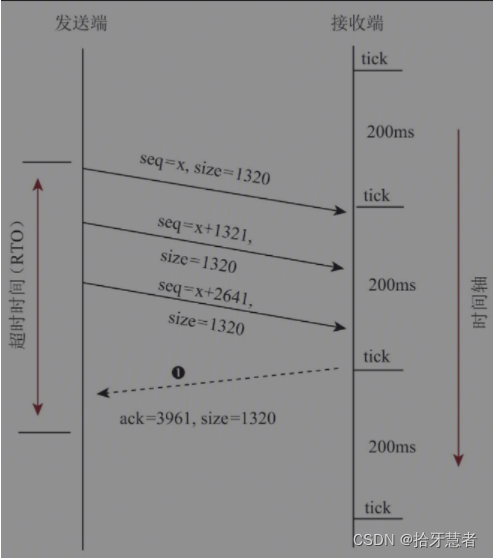
假如接收端發送的確認消息丟失了,按TCP的協議規則,通信雙方會怎么做呢?首先,發送端只有等到定時器超時后,才能發現該包丟失了。確認丟包后,發送端會將前面所有未確認的包重發一遍。如果在收到數據后,接收端發送的確認消息又丟失了,那么發送端還要等到定時器超時后才能知道包丟失了。因此,在遇到這種極端網絡的情況下,TCP傳輸的時延要累加很多,這種時延是不可控的。
UDP->RTP
UDP沒有這套邏輯,所以實時性最高。WebRTC通過NACK、FEC、Jitter Bufer以及NetEQ技術既可以解決丟包和抖動問題,又不會產生影響服務質量的時延。
UDP傳輸一些有前后邏輯關系的數據時有缺陷,所以在UDP之上的應用層上使用RTP傳輸音視頻數據
RTP協議結構
保持有序:Sequence Number
我們希望在使用RTP傳輸音視頻數據時,一旦有數據丟失,可以快速定位是哪個數據包丟失了。
如果給每個發送的數據包都打上一個編號,并且編號是連續的,那么,接收端就可以很容易地判斷出哪些包丟失了。在RTP頭中,有一個專門記錄該編號的字段,稱作Sequence Number。在發送端,每產生一個RTP包,其Sequence Number字段中的值就被自動加1,以保證每個包的編號唯一且連續。當接收端收到RTP包時,會對Sequence Number字段進行檢查,如果發現Sequence Number不連續了,就說明有包丟失或亂序了。
區分不同類型數據:PayloadType
我們在做網絡應用開發時,通常會使用同一個端口傳輸不同類型的數據,如音視頻數據。但接收端是如何區分出不同類型的數據的?RTP在其協議頭中設置了PT(PayloadType)字段.比如VP8的PT一般為96,而Opus的PT一般為111
區分不同源數據包:SSRC
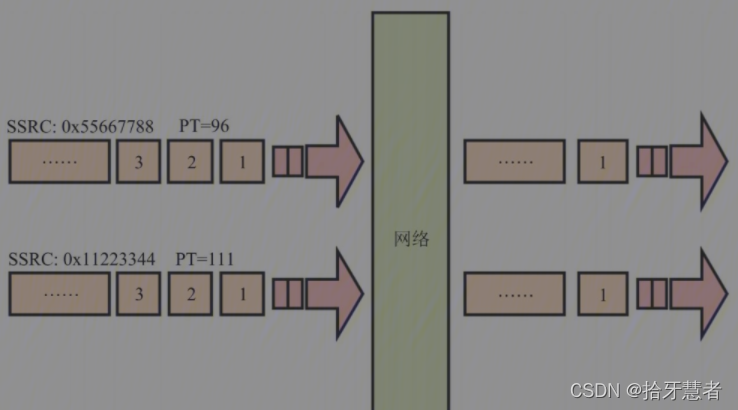
同一個端口不僅可以同時傳輸不同類型的數據包,還可以傳輸同一類型但不同源的數據包。
流媒體服務就可以將多個不同源(參與人)的視頻通過同一個端口發送給客戶端。那么客戶端(接收端)又是如何將不同源的數據區分出來的呢?這就要說到RTP中另一個字段SSRC了。
RTP要求所有不同的源的數據流之間可以通過SSRC字段進行區分,且每個源的SSRC必須唯一。
每個SSRC所代表的數據流的Sequence Number都是單獨計數的,如下圖:
完整的協議格式如下:
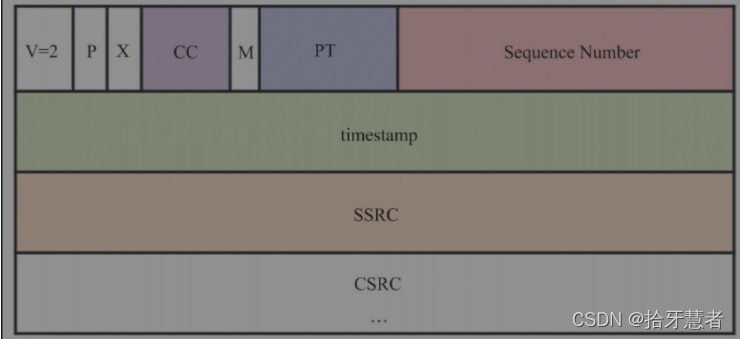
V(Version)字段,占2位,表示RTP的版本號,現在使用的都是第2個版本,所以該域固定為2。
P(Padding)字段,占1位,表示RTP包是否有填充值。為1時表示有填充,填充以字節為單位。一般數據加密時需要固定大小的數據塊,此時需要將該位置1。
X(eXtension)字段,占1位,表示是否有擴展頭。如果有擴展頭,擴展頭會放在CSRC之后。擴展頭主要用于攜帶一些附加信息。
CC(CSRCCount)字段,占4位,記錄了CSRS標識符的個數。每個CSRC占4字節,如果CC=2,則表示有兩個CSRC,共占8字節。
M(Marker)字段,其含義是由配置文件決定的,一般情況下用于標識邊界。比如一幀H264被分成多個包發送,那么最后一個包的M位就會被置位,表示這一幀數據結束了。
timestamp字段,占4字節,用于記錄該包產生的時間,主要用于組包和音視頻同步。
CSRC字段,指該RTP包中的數據是由哪些源貢獻的。比如混音數據是由三個音頻混成的,那么這三個音頻源都會被記錄在CSRS列表中。
Jittbuffer
介紹一下使用RTP消除包抖動的一個簡要過程:
對于WebRTC而言,其在接收RTP包時,會為之創建一個接收隊列來消除包抖動。一開始,隊列中只收到了100、101、102和104號包。由于103號包還沒到,所以無法將100~104號包組成一幀數據。103號包沒有到有兩種可能的原因:一種原因是103號包丟失了;另一種原因是網絡抖動導致包亂序了。判斷緩沖隊列有沒有滿。如果緩沖隊列滿了,就說明包真的丟失了。對于103號包來說,由于現在緩沖隊列還不滿,因此該包處于待定狀態。同理,當107號包到達時,105號包和106號包也處于待定狀態。
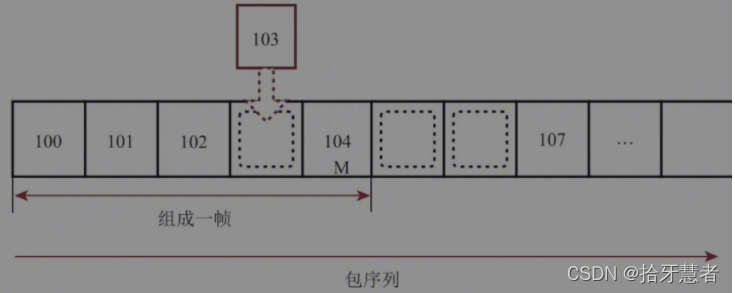
很快103號包來了,通過對其RTP頭中Sequence Number字段的計算,它會被插到隊列中對應的空缺位置,此時100~104號包連成了一串。又由于104號包上有M標記,因此可以將這幾個RTP包組成一個完整的幀。接下來,100~104號包將從緩沖隊列中彈出,交由組幀模塊處理,空出的位置可以繼續接收新包。WebRTC也是通過類似的方法從網絡上將一個個RTP包接收下來。
WebRTC中解決RTP包抖動的緩沖隊列就是我們通常所說的JitterBufer。
RTP擴展頭
當X被置位1,說明有擴展頭
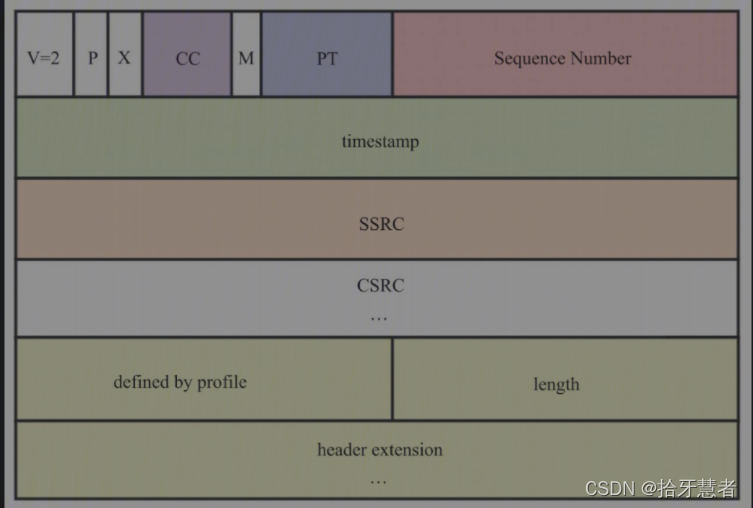
RTP擴展頭由三部分組成,分別為profile、length以及headerex tension。
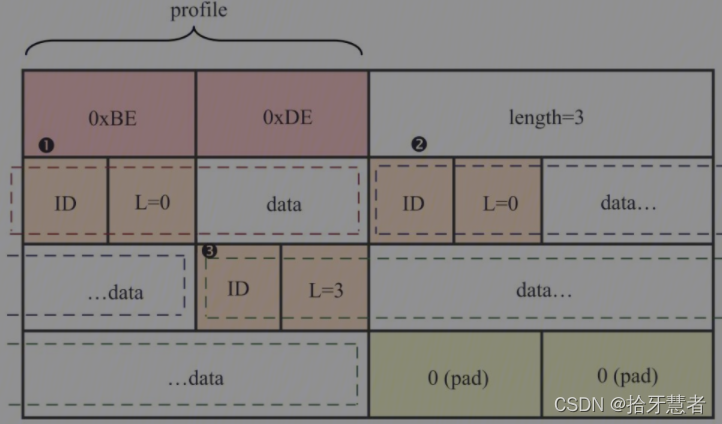
在RFC5285中定義了兩種profile,分別是**{0xBE,0xDE}和{0x10,0x0X}**(分別代表存放在headerextension中的兩種不同的數據格式,即one-byte-header和two-byte-header)
接收端解析RTP擴展頭時,通過profile來區分header extension中的內容該如何解析。
length字段表示擴展頭所攜帶的header extension的個數。如果length為4,表示有4個headerextension;
header extension字段是擴展頭信息,以4字節為單位,其具體含義由profile決定。
one-byte-header格式:
存放在擴展頭header extension字段中的數據,由一個字節的Header和N字節的Body組成,而Header又由4位的ID和4位的len組成。注意,length的值為跟在Header后面的數據(以字節為單位)長度減1。
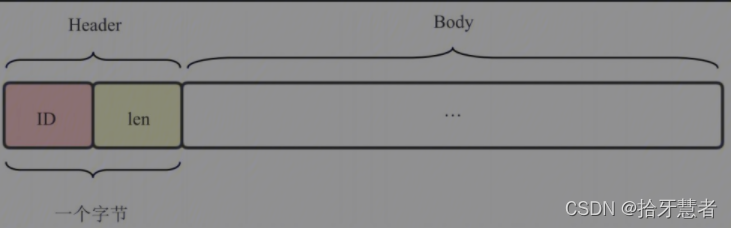
第一個one-byte-header的length值為0,其數據長度為(0+1)=1字節;第二個one-byte-header(的length值為1,其數據占(1+1)=2字節;第三個one-byte-header的length值為3,其數據占(3+1)=4字節。此外,由于擴展頭要保持4字節對齊,所以最后兩個字節是填充字節,設置為0。
two-byte-header格式:
Header部分由兩個字節組成,第一個字節表示ID,第二個字節表示長度,two-byte-header中length存放的是實際長度。

通過上面的介紹我們知道RTP擴展頭有三個要點。一是RTP標準頭中的X位,該位置1時,RTP中才會有擴展頭。二是擴展頭中的profile字段指明了擴展頭中數據的格式。如果profile為0xBEDE,則說明使用的擴展頭格式為one-byte-header;如果profile為0x100X(X表示任意值),則說明使用的擴展頭格式為two-byte-header。三是one-byte-header與two-byte-header的區別。如果ID和len放在一個字節中,說明它是one-byte-header格式;如果ID和len放在兩個字節中,說明它是two-byte-header格式。
RTP填充數據
RTP頭中的P位用于標識RTP包中是否有填充數據。如果P位為1,說明RTP包中含有填充數據。
當RTP包中包含有填充數據時,其數據包的最后一個字節記錄著包中填充字節的個數,即圖中的Padding Size部分。
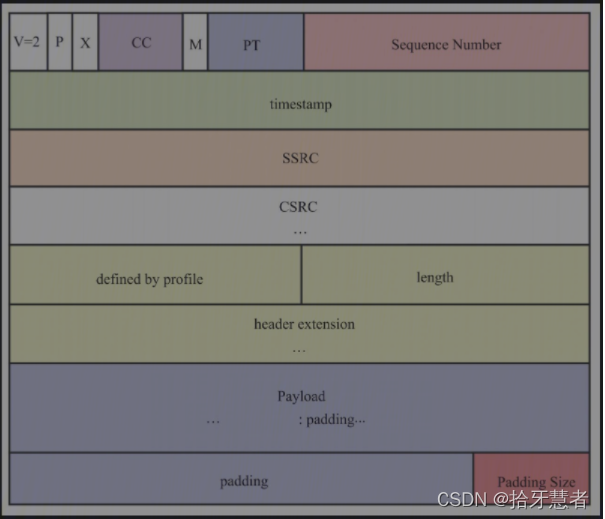
如果Padding Size為5,說明RTP包中共有5個填充字節,其中包括它自己。在解析RTP Payload部分之前,應將填充部分去掉。去掉填充字節的算法也非常簡單,首先讀取RTP包的最后一個字節,取出填充字節數,然后從最后一個字節算起,將其前面的Padding Size個字節丟掉即可。
參考
李超《WebRTC音視頻實時互動技術:原理、實戰與源碼分析》
https://weread.qq.com/web/reader/377320f07260a55337761c1kc81322c012c81e728d9d180



















