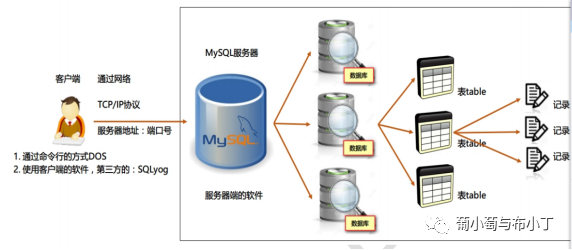
基本概念
1.數據庫DataBase簡稱:DB
2.什么數據庫?——用于存儲和管理數據的倉庫。存儲過程是一個預編譯的SQL語句,優點是允許模塊化的設計,就是說只需創建一次,以后在該程序中就可以調用多次。
3.數據庫的特點:持久化存儲數據。數據庫就是一個文件夾系統
MySQL服務啟動
1.?手動:管理——服務——手動關閉和開啟。
2.cmd-->services.msc打開服務的窗口
3.使用管理員打開cmd
net start mysql:啟動mysql的服務
net stop mysql:關閉mysql服務
MySQL登錄
1.mysql-uroot-p密碼
2.mysql-hip-uroot-p連接目標的密碼
MySQL退出
1.exit(退出)
2.quit(辭職、退出)
索引的作用?它的優點缺點是什么?
索引在數據庫的搜索時可以加速對數據的檢索。類似與現實生活中書的目錄,缺點是它減慢了數據錄入的速度,同時也增加了數據庫的尺寸大小。
在數據庫中查詢語句速度很慢,如何優化?
1.建索引2.減少表之間的關聯 3.優化sql,盡量用PreparedStatement來查詢,不要用Statement
索引類型有哪些?B-tree :b+樹、b-樹——葉子節點中的數據索引、二叉樹,紅黑樹、Hash表
什么是事務?
事務就是被綁定在一起的SQL語句分組,有原子性,一致性,隔離性和持久性。
怎么驗證MySQL的索引是否滿足需求
explain語法:explain select*from table where type=1。
數據庫的事務隔離
MySQL的事務隔離是在MySQL.ini配置文件最后添加:transaction-isolation=REPEATABLE-READ
可用的配置值:READ-UNCOMMITTED、READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE。
Read-uncommitted:未提交讀,最低隔離級別、事務未提交前,就可被其他事務?生了幻覺。發生幻讀的原因也是另外一個事務新增或者刪除或者修改了第一個事務結果集里面的數據,同一個記錄的數據內容被修改了,所有數據行的記錄就變多或者變少了。
視圖:是一種虛擬的表,具有和物理表相同的功能。優點:對數據庫的訪問,因為視圖可以有選擇性的選取數據庫里的一部分。
Oracle和Mysql的區別?
1)庫函數不同。
2)Oracle是用表空間來管理的,Mysql不是。
Oracle語句分三類:DDL、DML、DCL。DDL(Data Definition Language)數據定義語言,包括:Create語句:可以創建數據庫和數據庫的一些對象。Drop語句:可以刪除數據表、索引、觸發程序、條件約束以及數據表的權限等。Alter語句:修改數據表定義及屬性。Truncate語句:刪除表中的所有記錄,包括所有空間分配的記錄被刪除。DML(Data Manipulation Language)數據操控語言,包括:Insert語句:向數據表張插入一條記錄。Delete語句:刪除數據表中的一條或多條記錄,也可以刪除數據表中的所有記錄,但是它的操作對象仍是記錄。Update語句:用于修改已存在表中的記錄的內容。DCL(Data Control Language)數據庫控制語言,包括:Grant語句:允許對象的創建者給某用戶或某組或所有用戶(PUBLIC)某些特定的權限。Revoke語句:可以廢除某用戶或某組或所有用戶訪問權限
數據庫三范式是什么?
第一范式:列不可再分第二范式:行可以唯一區分,主鍵約束第三范式:三大范式是一級一級依賴的
什么是SQL?
Structured Query Language:結構化查詢語言,定義了操作所有關系型數據庫的規則。每一種數據庫操作的方式存在不一樣的地方,稱為“方言”。Mysql,oracle,SQLserver, DB2
都是關系型數據庫。
SQL語句單行或多行書寫,以分號結尾。MySQL數據庫的SQL語句不區分大小寫,關鍵字建議使用大寫。單行注釋:--??注釋內容或#注釋內容(mysql特有),多行注釋:/*注釋*/
SQL分類
1) Data Definition Language (DDL 數據定義語言) 如:建庫,建表 關鍵字:create,drop,alter等
2) Data Manipulation Language(DML 數據操縱語言),如:對表中的記錄操作增刪改 關鍵字:insert,delete,update等
3) Data Query Language(DQL 數據查詢語言),如:對表中的查詢操作 關鍵字:select,where等
4) Data Control Language(DCL 數據控制語言),如:對用戶權限的設置。關鍵字:GRANT,REVOKE等
DDL:操作數據庫、表——CRUD
1.C(Create):創建
創建數據庫:
create database數據庫名稱;
創建數據庫,判斷不存在,再創建:
create database if not exists數據庫名稱;
創建數據庫,并指定字符集
create database數據庫名稱character set字符集名;
練習:創建db4數據庫,判斷是否存在,并制定字符集為gbk
create database if not exists db4 character set gbk;
2.R(Retrieve):查詢
*查詢所有數據庫的名稱:
show databases;
*查詢某個數據庫的字符集:查詢某個數據庫的創建語句
show create database數據庫名稱;
3.U(Update):修改
*修改數據庫的字符集
alter database數據庫名稱character set字符集名稱;
4.D(Delete):刪除
刪除數據庫
drop database數據庫名稱;
判斷數據庫存在,存在再刪除
drop database if exists數據庫名稱;
5.使用數據庫
*查詢當前正在使用的數據庫名稱
*select database();
*使用數據庫
*use數據庫名稱;
2.DCL操作表
1.C(Create):創建
1.語法:
create table表名(
列名1數據類型1,
列名2數據類型2,
列名n數據類型n
);
*注意:最后一列,不需要加逗號(,)
*數據庫類型:
1.int:整數類型
age int,
2.double:小數類型
score double(5,2)
3.date:日期,只包含年月日,yyyy-MM-dd
4.datetime:日期,包含年月日時分秒yyyy-MM-dd HH:mm:ss
5.timestamp:時間錯類型包含年月日時分秒yyyy-MM-dd HH:mm:ss
如果將來不給這個字段賦值,或賦值為null,則默認使用當前的系統時間,來自動賦值
6.varchar:字符串
*name varchar(20):姓名最大20個字符
*zhangsan 8個字符張三2個字符
*創建表
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);
*復制表:
*create table表名like被復制的表名;
2.R(Retrieve):查詢
*查詢某個數據庫中所有的表名稱
*show tables;
*查詢表結構
*desc表名;
3.U(Update):修改
1.修改表名
alter table表名rename to新的表名;
2.修改表的字符集
alter table表名character set字符集名稱;
3.添加一列
alter table表名add列名數據類型;
4.修改列名稱類型
alter table表名change列名新列別新數據類型;
alter table表名modify列名新數據類型;
5.刪除列
alter table表名drop列名;
4.D(Delete):刪除
*drop table表名;
*drop table if exists表名;
*客戶端圖形化工具:SQLYog
DML:增刪改表中數據
1.添加數據:
*語法:
*insert into表名(列名1,列名2,...列名n)values(值1,值2,...值n);
*注意:
1.列名和值要一一對應。
2.如果表名后,不定義列名,則默認給所有列添加值
insert into表名values(值1,值2,...值n);
3.除了數字類型,其他類型需要使用引號(單雙都可以)引起來
2.刪除數據:
*語法:
*delete from表名[where條件]
*注意:
1.如果不加條件,則刪除表中所有記錄。
2.如果要刪除所有記錄
1.delete from表名;--不推薦使用。有多少條記錄就會執行多少次刪除操作
2.TRUNCATE TABLE表名;--推薦使用,效率更高先刪除表,然后再創建一張一樣的表。
3.修改數據:
*語法:
*update表名set列名1=值1,列名2=值2,...[where條件];
*注意:
1.如果不加任何條件,則會將表中所有記錄全部修改。
##DQL:查詢表中的記錄
*select*from表名;
1.語法:
select
字段列表
from
表名列表
where
條件列表
group by
分組字段
having
分組之后的條件
order by
排序
limit
分頁限定
2.基礎查詢
1.多個字段的查詢
select字段名1,字段名2...from表名;
*注意:
*如果查詢所有字段,則可以使用*來替代字段列表。
2.去除重復:
*distinct
3.計算列
*一般可以使用四則運算計算一些列的值。(一般只會進行數值型的計算)
*ifnull(表達式1,表達式2):null參與的運算,計算結果都為null
*表達式1:哪個字段需要判斷是否為null
*如果該字段為null后的替換值。
4.起別名:
*as:as也可以省略
3.條件查詢
1.where子句后跟條件
2.運算符
*>、=、=、<>
*BETWEEN...AND
*IN(集合)
*LIKE:模糊查詢
*占位符:
*_:單個任意字符
*%:多個任意字符
*IS NULL
*and或&&
*or或||
*not或!
--查詢年齡大于20歲
SELECT*FROM student WHERE age>20;
SELECT*FROM student WHERE age>=20;
--查詢年齡等于20歲
SELECT*FROM student WHERE age=20;
--查詢年齡不等于20歲
SELECT*FROM student WHERE age!=20;
SELECT*FROM student WHERE age<>20;
--查詢年齡大于等于20小于等于30
SELECT*FROM student WHERE age>=20&&age<=30;
SELECT*FROM student WHERE age>=20 AND age<=30;
SELECT*FROM student WHERE age BETWEEN 20 AND 30;
--查詢年齡22歲,18歲,25歲的信息
SELECT*FROM student WHERE age=22 OR age=18 OR age=25
SELECT*FROM student WHERE age IN(22,18,25);
--查詢英語成績為null
SELECT*FROM student WHERE english=NULL;--不對的。null值不能使用=(!=)判斷
SELECT*FROM student WHERE english IS NULL;
--查詢英語成績不為null
SELECT*FROM student WHERE english IS NOT NULL;
--查詢姓馬的有哪些?like
SELECT*FROM student WHERE NAME LIKE'馬%';
--查詢姓名第二個字是化的人
SELECT*FROM student WHERE NAME LIKE"_化%";
--查詢姓名是3個字的人
SELECT*FROM student WHERE NAME LIKE'___';
--查詢姓名中包含德的人
SELECT*FROM student WHERE NAME LIKE'%德%';
查詢緩存(了解):MySQL拿到一個查詢請求后→會先到查詢緩存看看之前是不是執行過這條語句→命中就返回緩存的value。【他跟Redis一樣,只要是你之前執行過的語句,都會在內存里面用key-value形式存儲著。緩存在MySQL8.0之后就取消了——查詢的緩存容易被清空消失(原因)】?
MySQL的內連接、左連接、右連接有什么區別?
內連接:inner join;左連接:left join;右連接:right join。
內連接是把匹配的關聯數據顯示出來;左連接是把表全部顯示出來,右邊的表顯示出符合條件的數據
MySQL索引是怎么實現的?
索引是滿足某種特定查找算法的數據結構,而這些數據結構會以某種方式指向數據,從而實現高效查找數據。不同的數據引擎實現有所不同。
MySQL中的索引是B+樹實現的,B+樹的搜索效率,可以到達二分法的性能,找到數據區域之后就找到了完整的數據結構了,所有索引的性能也是更好的。
MySQL常用的引擎?
InnoDB引擎:InnoDB引擎提供了對數據庫acid事務的支持,并且還提供了行級鎖和外鍵的約束,它的設計的目標就是處理大數據容量的數據庫系統。MySQL運行的時候,InnoDB會在內存中建立緩沖池,用于緩沖數據和索引。但是該引擎是不支持全文搜索,同時啟動也比較的慢,它是不會保存表的行數的,所以當進行select count(*)from table指令的時候,需要進行掃描全表。由于鎖的粒度小,寫操作是不會鎖定全表的,所以在并發度較高的場景下使用會提升效率的。
MyIASM引擎:MySQL的默認引擎,但不提供事務的支持,也不支持行級鎖和外鍵。因此當執行插入和更新語句時,即執行寫操作的時候需要鎖定這個表,所以會導致效率會降低。不過和InnoDB不同的是,MyIASM引擎是保存了表的行數,于是當進行select count(*)from table語句時,可以直接的讀取已經保存的值而不需要進行掃描全表。所以,如果表的讀操作遠遠多于寫操作時,并且不需要事務的支持的,可以將MyIASM作為數據庫引擎的首選。
什么是鎖?
鎖:在所以的DBMS中,鎖是實現事務的關鍵,鎖可以保證事務的完整性和并發性。
MySQL的行鎖和表鎖、樂觀鎖和悲觀鎖
MyISAM只支持表鎖,InnoDB支持表鎖和行鎖,默認為行鎖。
表級鎖:開銷小,加鎖快,不會出現死鎖。鎖定粒度大,發生鎖沖突的概率最高,并發量最低。
行級鎖:開銷大,加鎖慢,會出現死鎖。鎖力度小,發生鎖沖突的概率小,并發度最高。
樂觀鎖:每次去拿數據的時候都認為別人不會修改,所以不會上鎖,但是在提交更新的時候會判斷一下在此期間別人有沒有去更新這個數據。
悲觀鎖:每次去拿數據的時候都認為別人會修改,所以每次在拿數據的時候都會上鎖,這樣別人想拿這個數據就會阻止,直到這個鎖被釋放。
數據庫的樂觀鎖需要自己實現,在表里面添加一個version字段,每次修改成功值加1,這樣每次修改的時候先對比一下,自己擁有的version和數據庫現在的version是否一致,如果不一致就不修改,這樣就實現了樂觀鎖。
MySQL問題排查都有哪些手段
使用show processlist命令查看當前所有連接信息。
使用explain命令查詢SQL語句執行計劃。
開啟慢查詢日志,查看慢查詢的SQL。

時鐘)
)



通用定時器)







PWM)




ADC)